







目录
JVM的运行时数据区

为什么要划分区域?区域是干什么的?
逻辑上划分区域,便于为不同区域指定专门的用途方便人类理解。
方法区
存放方法,主要是指令数据,以字节码为代表的指令数据。线程共享区。也会有部分附属的方法基本信息。扩展起来认为,就是保存类的信息。逻辑上,认为类的相关数据存放在这,静态属性放在方法区。方法区以类为单位,类中还能以方法为基本单位。
堆
一个JVM实例只有一个堆内存,堆也是Java内存管理的核心区域。堆在JVM启动的时候创建,其空间大小也被创建,是JVM中最大的一块内存空间,所有线程共享堆,物理上不连续但逻辑上连续的内存空间,几乎所有的实例都在这里分配内存,在方法结束后,堆中的对象不会马上删除,仅仅在垃圾收集的时候被删除,堆是GC(垃圾收集器)执行垃圾回收的重点区域。属性空间是随着对象走的,所以逻辑上认为,属性是保存在堆区的。
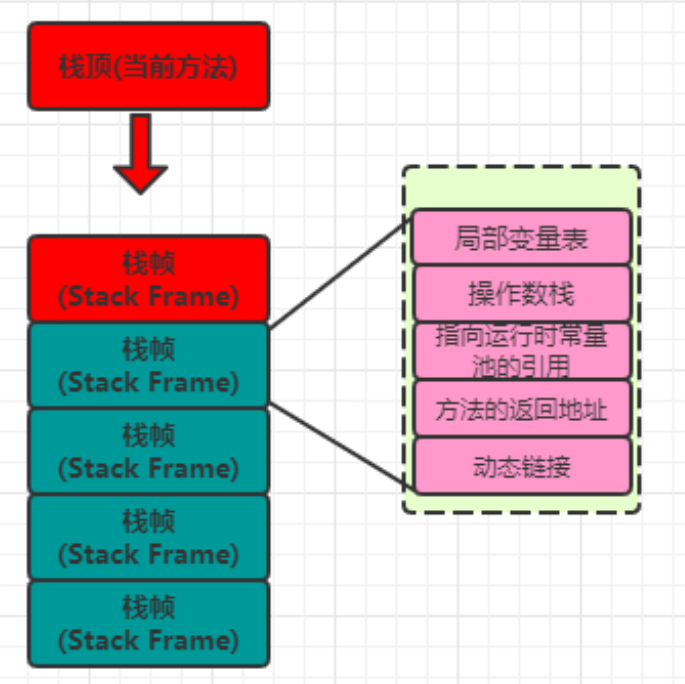
栈
以栈帧为基本单位。栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构,它是虚拟机运行时数据区中的虚拟机栈(Virtual Machine Stack)的栈元素。
一个方法要执行的时候分配给属于这个方法本次执行的栈帧(至于栈帧分配多少内存空间,不会受运行期间变量数量的影响,而是取决于具体虚拟机的实现),方法执行结束之后,栈帧空间被回收。
栈帧中保存的就是该方法本次执行需要的数据。栈帧随着方法本次执行出现,本次执行结束消亡。
程序计数器(PC)
保存下一条要执行的指令的位置。详细的说PC寄存器是用来存储指向下一条指令的地址,也就是即将将要执行的指令代码。由执行引擎读取下一条指令。
执行引擎
就是对CPU的模拟。执行引擎在执行的过程中究竟需要执行什么样的字节码指令完全依赖于PC寄存器。每当执行一项指令操作后,PC寄存器就会更新下一条需要被执行的指令的地址。
当然方法在执行过程中,执行引擎有可能会通过存储在局部变量表中的对象引用准确定位到存储在Java堆区中的对象实例信息,以及通过对象头中的元数据执行定位到目标对象的类型信息。
即时编译JIT Complier
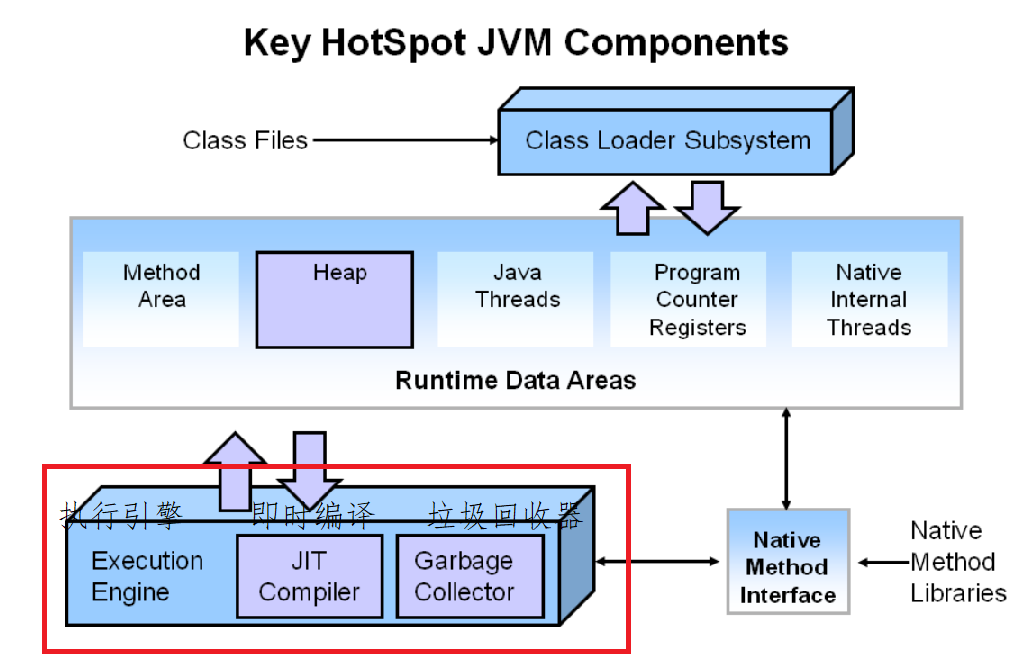
JIT(Just in time ):即时编译,提高执行效率的一套机制。
JVM在执行过程中,有些字节码执行的比其他字节码执行更频繁,所以如果都按照字节码翻译的模式,效率就低了,因此,会在运行期间,即时地把这些热点字节码直接编译成本地的机器码(就像C语言一样),速度就能提升。
JVM的执行,有个预热阶段,就像运动前热身一样,让自己的状态达到最好,效率才最高。
JVM的大体启动过程
(控制权是如何交到我们手里的(main方法的第一条语句(字节码)是如何被执行起来的))?
运行java代码是:Java.exe -classpath指定类加载路径 -启动类名称;比如 java.exe -com.demo.Main -以这个类的main方法作为程序的启动入口:
- OS收集要启动的进程的信息:程序是C:/program Files/java/jdk/bin/java.exe,参数是com.demo.Main
- OS根据程序,启动进程,执行java.exe当时写的程序入口(C语言里的main函数)
- JVM读取参数,找OS申请必要的内存,创建必要的执行引用和类加载器
- JVM执行引擎,要求类加载器进行com.demo.Main类的加载
- JVM创建主线程,把PC的值设置成com.demo.Main类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









