







在当今数据驱动的世界中,MySQL数据库作为一种广泛使用的关系型数据库管理系统,扮演着至关重要的角色。然而,随着数据规模和工作负载的增长,我们常常面临性能瓶颈和查询效率降低的挑战。那么,如何优化MySQL数据库以提高其性能和响应能力呢?
慢查询优化
MySQL的慢查询指的是执行时间较长或者响应时间较慢的SQL查询语句。当一个查询语句花费的时间超过预设的阈值,就会被认定为慢查询。通常,执行时间超过几秒钟的查询会被定义为慢查询,具体的阈值可以通过配置文件或者参数进行设置。
通常情况下,慢查询出现的情况有这几种:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
慢查询这样的表现形式为:页面加载过慢,通过接口测试的时间过长(比如超过1s)
如何定位慢查询
如果业务的接口响应很慢,我们如何能够确定是SQL的问题呢?就算是,我们该如何找出这个执行慢的SQL呢?
通常情况下,我们定位慢查询有两种方式:
使用开源工具
我们可以使用一些开源的工具进行监听或调试。
- 调试工具:Arthas 可以使用命令的方式去监控已经上线的项目,可以跟踪执行比较慢的方法,然后查看方法的执行时间。
- 运维工具:Prometheus,Skywalking 等
MySQL自带慢日志
MySQL可以把一些执行慢的SQL记录到日志文件中,这样就可以快速知道哪些SQL执行的比较慢,MySQL默认是没有开启慢查询日志的,需要在MySQL配置文件中配置以下信息:
# 开启MySQL慢日志查咨询开关
slow_query_log=1
# 设置慢日志的时间是两秒,SQL语句执行时间超过两秒,就会视为慢查询,记录慢查询日志
long_query_time=2配置完毕会,重启MySQL服务器进行测试,就可以去/var/lib/mysql/localhost-slow.log
注意:慢日志一般都是在调试阶段开启,生产阶段是不会开启的,因为会损耗MySQL性能。
如何分析慢查询
如果我们已经发现某条SQL执行的很慢,我们应该如何分析呢?
如果发现了聚合查询或者多表查询的话,我们就可以去优化SQL语句,比如聚合查询就可以通过新增一个临时表来解决。
如果是多表查询,就需要试着优化SQL语句的结构。
如果是表数据量过大,我们可以选择添加索引。然而有些时候我们明明已经添加了索引,SQL执行依然很慢,这该怎么办呢?
上面的三种情况,我们都可以通过SQL执行计划来分析具体原因。
在MySQL在我们可以通过EXPLAIN和DESC命令获取MySQL如何执行SELECT语句的信息。
具体语法如下:
直接在select语句之前加上关键字explain/desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;此时MySQL返回的就不是表中数据了,而是这条SQL的执行情况:

- possible_keys :这条SQL在执行的时候可能使用到的索引 ,是否真的使用到了不能确定
- key:表示实际命中的索引
- key_len:当前使用到的索引实际占用的大小
- Extra:额外的优化建议,有的时候可以通过这个字段来获得信息,比如某条SQL在使用索引的过程中是否进行了回表
- type:SQL的连接类型,性能由好到差为NULL,system,const,eq_ref,ref,range,index,all
我们可以通过key和key_len字段来确认是否用到了索引。
在MySQL的执行计划输出中,type字段表示该执行计划步骤的访问类型,主要有以下几种:
- system:这个表只有一行数据(系统表)。
- const:根据主键查询
- eq_ref:住家索引查询或唯一索引查询。
- ref:索引查询。
- range:索引范围扫描,走的是索引,但是是范围查询。
- index:全索引扫描。
- ALL:全表扫描,遍历全表找到匹配的行。
一般来说,type值为const、eq_ref、ref更好,ALL、index则较差。
通过分析type字段可以判断查询是否使用了索引,何种索引访问方法,是追求速度还是全量精确。
如果我们在执行计划中看到某条SQL的连接类型是index或者all,那么这条SQL就需要优化了。
分页优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。比如:

之所以第二条查询的效率这么低,是因为在我们进行分页查询时,如果执行limit 9000000,10,此时需要MySQL排序前9000010条记录,仅仅返回最后10条,其他记录丢弃,查询代价非常大。
要解决这个问题,我们可以通过覆盖索引+子查询来进行优化,具体SQL如下:
SELECT *
FROM tb_sku t,
(SELECT id FROM tb_sku ORDER BY id LIMIT 9000000,10) a
WHERE t.id=a.id在这段SQL中我们先根据id排序,再截取10条数据。注意,我们在根据id排序和返回id的时候走的是覆盖索引,这样就可以再索引中直接找到,这样性能相对就比较高了。然后我们在跟之前的表做关联,做一个等价查询,性能就有所提升了。
表设计优化
关于表设计优化我们可以参考《阿里开发手册》,其中有很多好的代码规范,比如:
- 设置合适的数值(yinyint,bigint,int),要根据实际情况选择,
- 比如设置合适的字符串类型(char和varchar)char定长效率高,varchar可变长度,效率稍低
SQL语句优化
- SELECT语句务必指明字段名称(避免直接使用select*)
- SQL语句要避免造成索引失效的写法
- 尽量用union all代替union,因为union会多过滤一次,效率低
- 避免在where子句中对字段进行表达式操作
- join优化,能用inner join就不要用right join,left join,如必须使用一定要以小表为驱动,内连接会对两个表进行优化,优先把小表放到外边,大表放到里边,但是right join,left join,不会调整顺序
主从复制,读写分离
如果手机壳使用场景读的操作比较多的时候,为了避免写的操作所造成的影响,可以采用读写分离架构。读写分离解决的是数据库的写入,影响了查询效率。
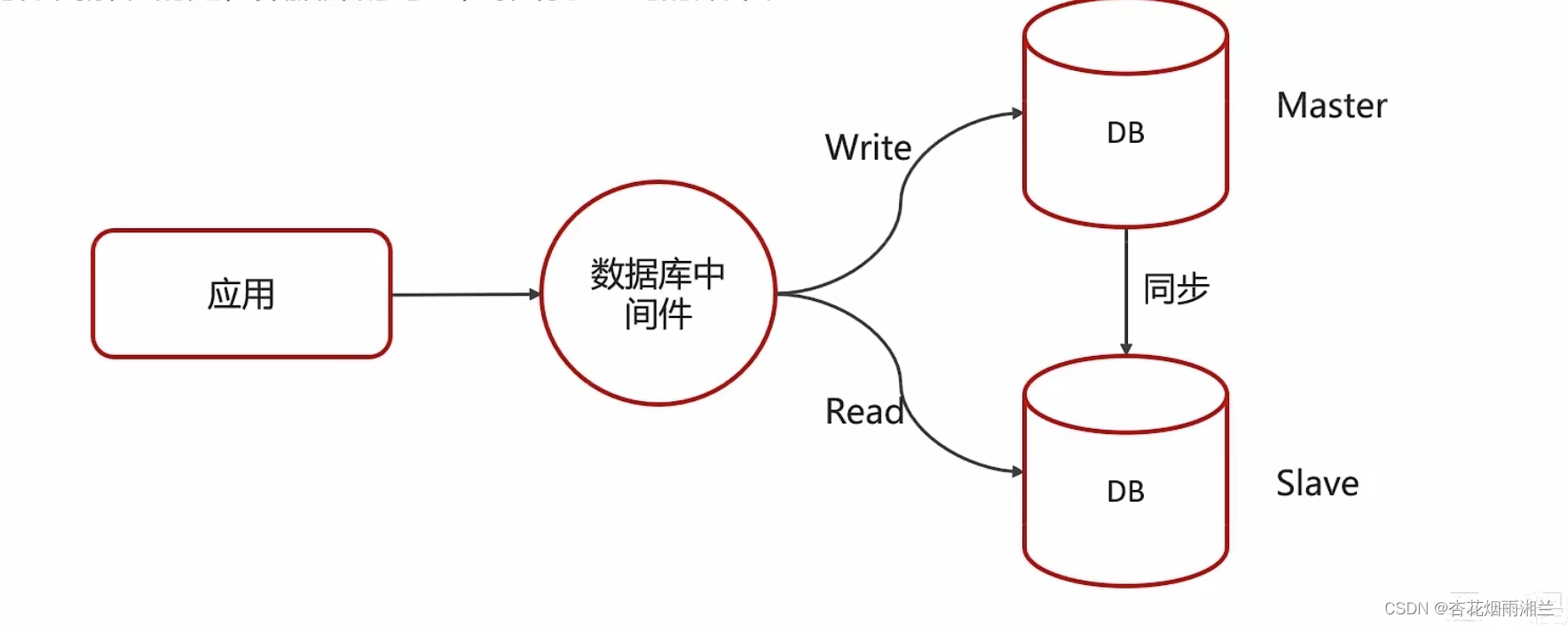
这一点其实和redis殊途同归的,master负责写,slave负责读,同时master将数据同步给slave。















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









