






 本文讲述了作者在格式化并启动Hadoop过程中遇到DataNode不启动的问题,经过排查发现是由于datanode日志权限问题导致。通过检查log文件和调整文件权限,最终解决了问题并能正常访问HadoopUI.
本文讲述了作者在格式化并启动Hadoop过程中遇到DataNode不启动的问题,经过排查发现是由于datanode日志权限问题导致。通过检查log文件和调整文件权限,最终解决了问题并能正常访问HadoopUI.
问题描述
刚格式化完Hadoop,使用start-dfs.sh启动,中途命令行没有打印错误,但jps后发现没有datanode:
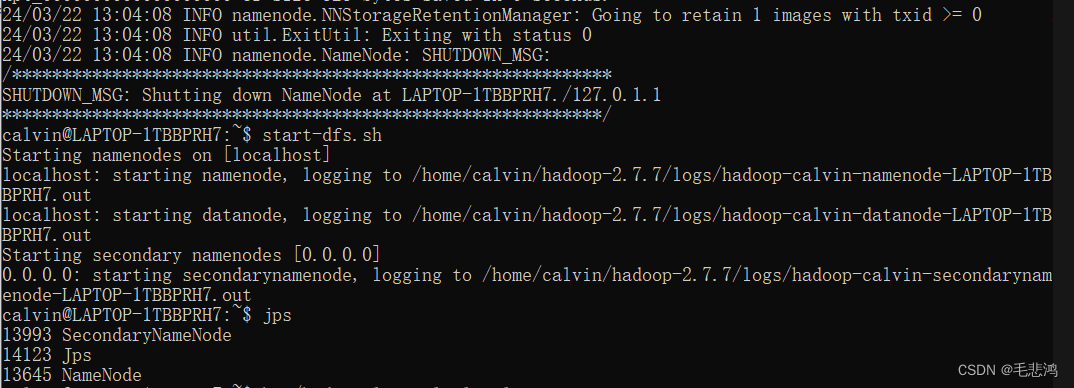
排查过程
看到网上有人说可能是重复使用hadoop的命令格式化的时候,namenode的clusterID会重新生成,而datanode的clusterID会保持不变:执行start-dfs.sh后,DataNode未启动 - 简书
我的hdfs-site.xml配置如下:
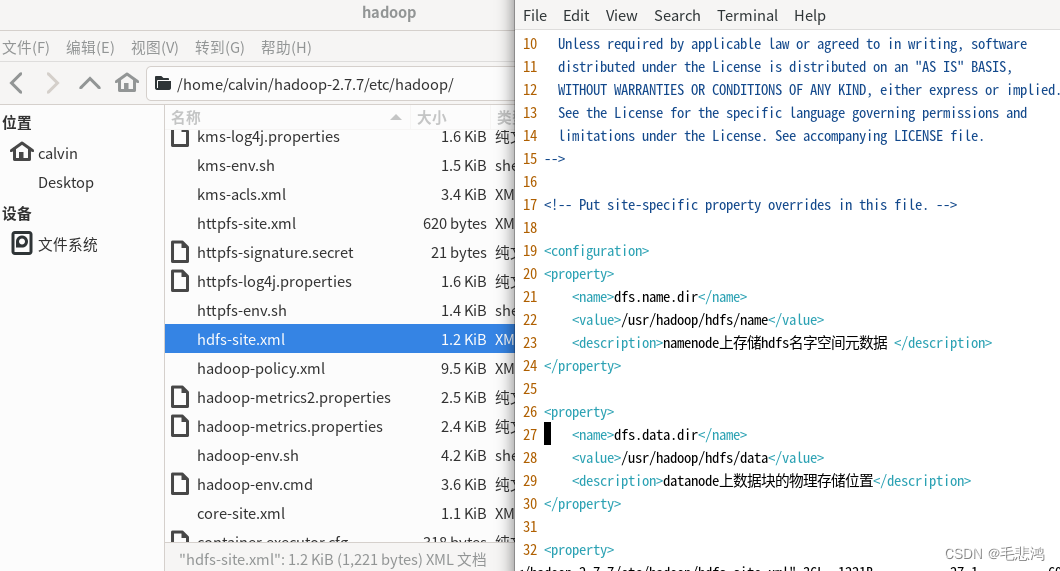
打开usr/hadoop/hdfs/name,发现里面有current文件夹,但usr/hadoop/hdfs/data下空空如也。
还好也有人碰到了类似的问题:Hadoop下jps没有datanode,且data文件夹没有current_格式化后找不到current-CSDN博客,但当我在命令行中输入
vim hadoop-hadoop-datanode-ubuntu.log却出现了以下场景:
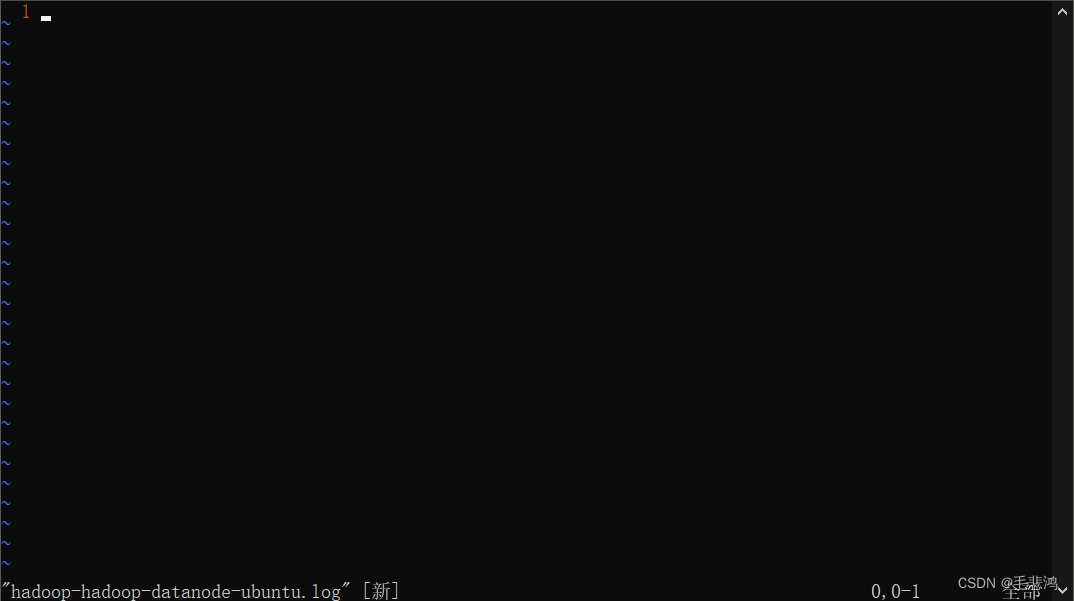
意思是我的datanode根本没有生成日志。
我换成网上搜到的另一个命令
cat hadoop-root-datanode-localhost.localdomain.log继续打印日志,结果告诉我No such file or directory:
![]()
我又不死心地切换到Hadoop安装目录下,使用
bin/hadoop logs -loglevel WARN尝试打印warn级别以上的日志,居然告诉我找不到或无法加载主类log:
![]()
我又想到是不是SSH的问题,我使用的是免密登录,检查一番之后发现也并无异常。
于是我打算把Hadoop数据都删了重新格式化。首先输入stop-dfs.sh关闭Hadoop服务,然后打开core-site.xml,找到临时文件夹 :
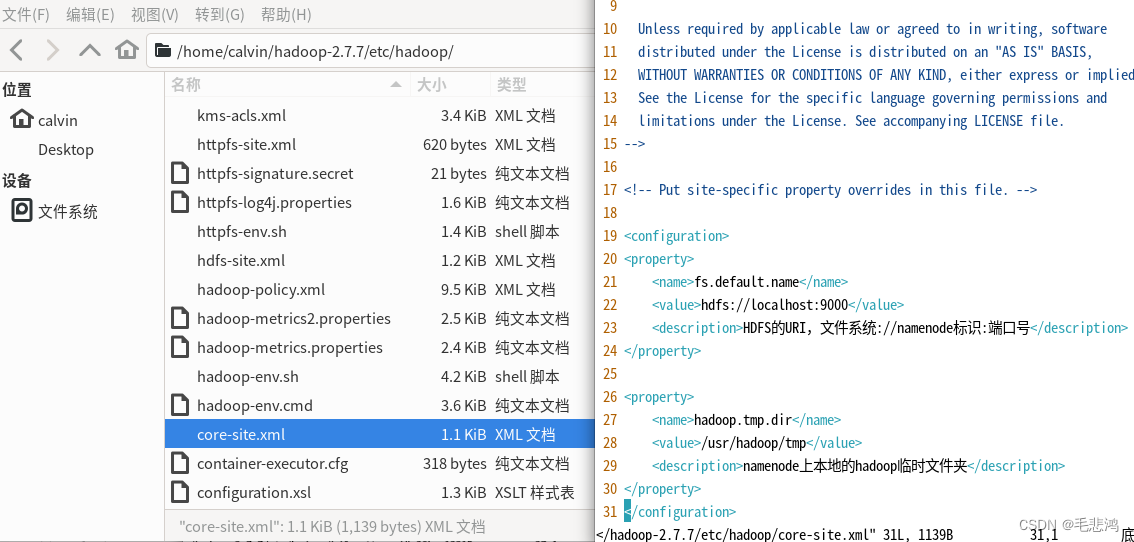
把usr/hadoop/tmp整个文件夹删除,再把usr/hadoop/hdfs/name下的文件也全部删除,再次运行
hadoop namenode -format期间并无报错,然后用start-dfs.sh再次启动Hadoop,也没有报错,但用jps一看,datanode还是没启动起来。
再尝试在Linux系统内的浏览器中输入http://localhost:9000/,居然打不开:

解决方法
我觉得再这么跟无头苍蝇似的乱转也不是个事,还是得找到错误日志。打印不出来就到文件系统里面找,在安装目录里还真找到了一个log文件夹,点进去看看:
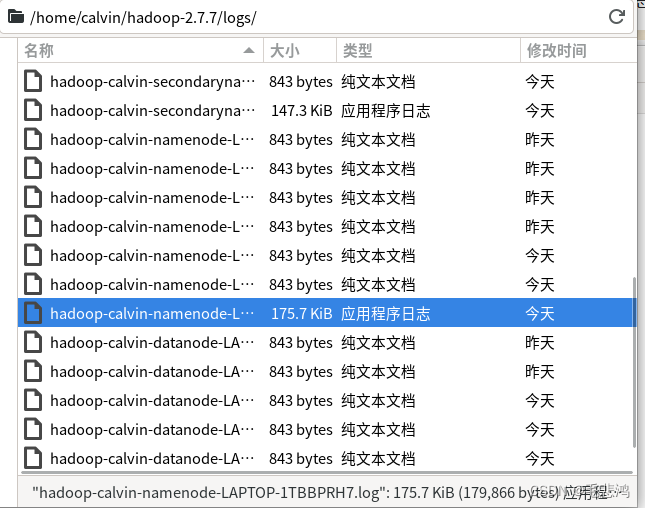
终于找到了datanode的log文件,里面的报错信息如下:
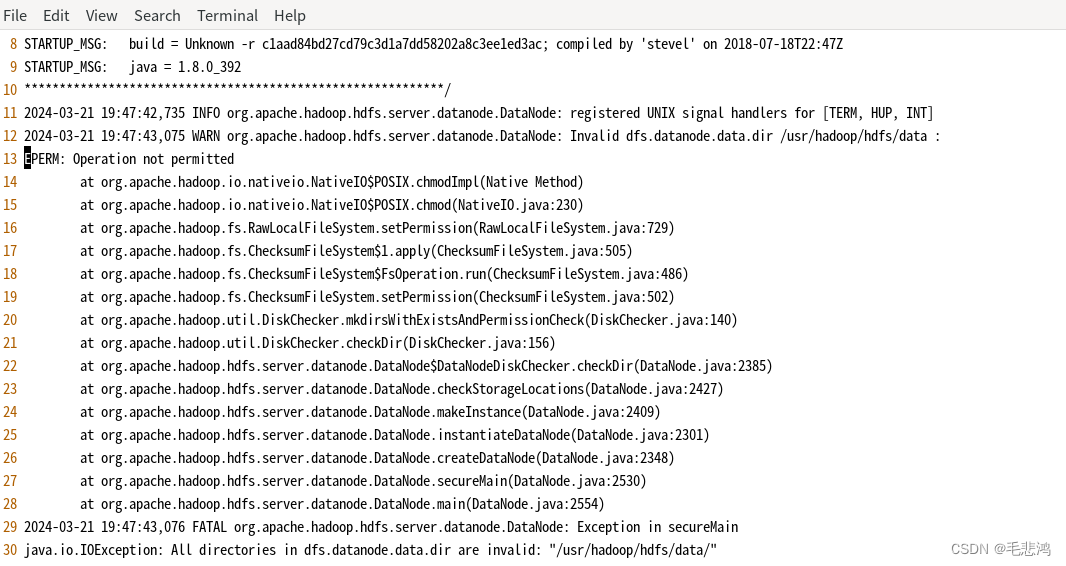
原来是权限不够,猜想是由于建立文件夹时是在文件系统中而非命令行中,把我的身份默认为root用户了。于是修改权限,将usr/hadoop/hdfs/data的所有者改为我运行Hadoop的用户calvin:
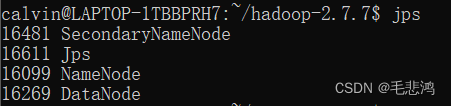
sudo chown -R calvin /usr/hadoop/hdfs/data而后再度格式化并启动Hadoop,大功告成:
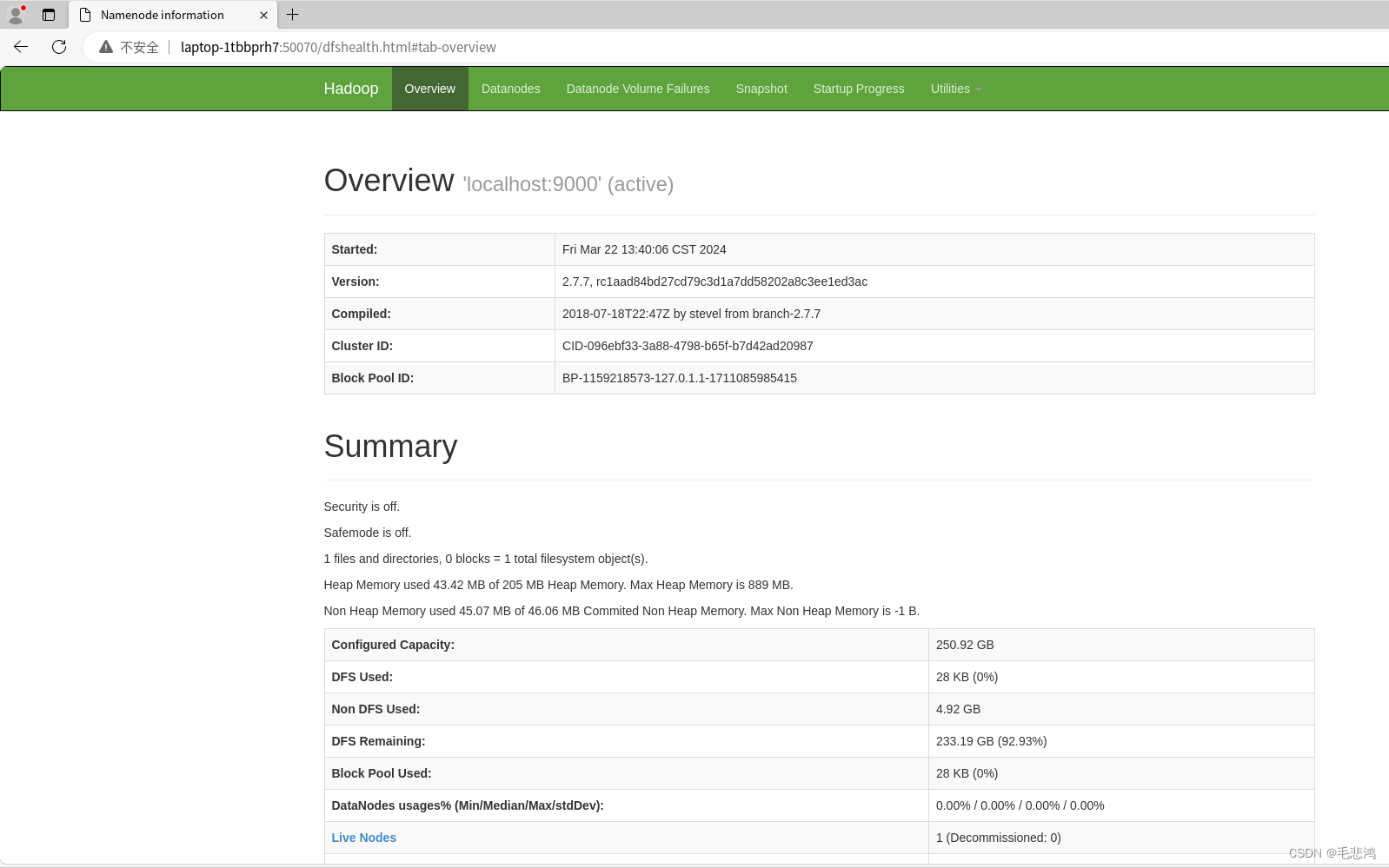
对了,打不开localhost:9000那个事,改成主机名:50070就打开了:

















 9680
9680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









