






学习笔记(第一周)
《吴恩达机器学习》
1.1机器学习的应用
第一节课程主要介绍机器学习当前的应用领域,并且列举了应用实例:
1. **推荐系统**:例如,Netflix和Amazon使用机器学习算法来推荐电影或产品。
2. **自动驾驶**:例如,Tesla和Waymo使用机器学习来理解环境并做出驾驶决策。
3. **医疗诊断**:例如,Google的DeepMind使用机器学习进行眼病诊断。
4. **语音识别**:例如,Apple的Siri和Amazon的Alexa使用机器学习来理解和响应语音命令。
5. **图像识别**:例如,Facebook使用机器学习进行面部识别。
6. **自然语言处理**:例如,OpenAI的GPT-3使用机器学习进行文本生成和理解。
7. **欺诈检测**:例如,银行和信用卡公司使用机器学习来检测异常交易。
8. **股票市场预测**:例如,投资公司使用机器学习来预测股价走势。
9. **广告定向**:例如,Google AdSense使用机器学习来定向投放广告。
10. **游戏**:例如,DeepMind的AlphaGo使用机器学习打败了世界围棋冠军。
总结:机器学习已经广泛应用在各个领域,从提供个性化推荐,到驾驶汽车,再到医疗诊断和语音识别,它正在改变我们的生活。机器学习不仅能处理大量数据,还能从中学习和提取有价值的信息,帮助我们做出更好的决策。随着技术的发展,机器学习的应用将更加广泛,其潜力无穷。
2.1 什么是机器学习
机器学习是人工智能的一个重要分支,其核心是让计算机系统从数据中学习并改进。在这个过程中,不需要进行显式编程,而是通过算法让机器自我学习和提升。机器学习算法通常可以分为三种类型:监督学习、无监督学习和强化学习。
**监督学习**是最常见的机器学习类型。在监督学习中,我们使用标记过的训练数据(即,每个样本都有对应的输出或标签)来训练模型。通过学习输入和输出之间的关系,模型可以预测新的、未标记的数据。常见的监督学习任务包括分类(如猫狗图片分类)和回归(如房价预测)。
**无监督学习**不依赖于标记过的训练数据,而是通过识别输入数据的内在结构和模式来学习。这种类型的学习可以用于聚类(如客户细分)、异常检测(如欺诈检测)和降维(如主成分分析)等任务。
**强化学习**是一种通过与环境的交互来学习的机器学习方法。在这种设置中,智能体(agent)会根据其当前状态和可能的行动来选择最佳的行动,以便获得最大的长期奖励。强化学习已经在游戏(如AlphaGo)、机器人技术和自动驾驶等领域取得了显著的成果。
机器学习的主要目标是通过学习和理解数据的模式和结构,对新的、未知的数据做出有效的预测或决策。为了实现这一目标,它依赖于统计学、概率论、计算理论、优化理论和其他相关领域的理论和方法。
机器学习的应用非常广泛,包括但不限于自然语言处理、计算机视觉、音频和语音处理、社交网络分析、医疗诊断、金融市场分析等。随着大数据的发展和计算能力的提升,机器学习的潜力正在被越来越多的领域所发掘和利用。
总的来说,机器学习是一种强大的工具,它能够从数据中学习和提取有价值的信息,帮助我们理解世界并做出更好的决策。然而,与此同时,我们也需要注意到机器学习的挑战和限制,比如过拟合、欠拟合、数据偏差、模型解释性等问题,这些都需要我们在实践中认真对待和解决。
2.2 监督学习
目前为止,由神经网络模型创造的价值基本上都是基于监督式学习(Supervised Learning)的。
监督式学习与非监督式学习本质区别就是是否已知训练样本的输出y。
在实际应用中,机器学习解决的大部分问题都属于监督式学习,神经网络模型也大都属于监督式学习。
下面是几个监督式学习在神经网络中应用的例子。
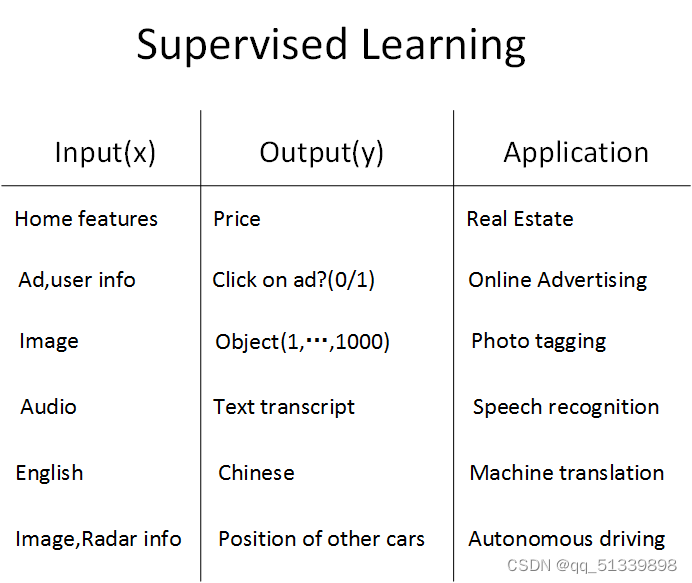
首先,第一个例子是房屋价格预测,这也是第一章的引例。根据训练样本的输入x和输出y,训练神经网络模型,预测房价。
第二个例子是线上广告,这是深度学习最广泛、最赚钱的应用之一。其中,输入x是广告和用户个人信息,输出y是用户是否对广告进行点击。神经网络模型经过训练,能够根据广告类型和用户信息对用户的点击行为进行预测,从而向用户提供用户自己可能感兴趣的广告。
第三个例子是机器视觉(computer vision)。机器视觉是近些年来越来越火的课题,而机器视觉发展迅速的原因很大程度上是得益于深度学习。其中,输入x是图片像素值,输出是图片所属的不同类别。
第四个例子是语音识别(speech recognition)。深度学习可以将一段语音信号辨识为相应的文字信息。
第五个例子是智能翻译,例如通过神经网络输入英文,然后直接输出中文。
至此,神经网络配合监督式学习,其应用是非常广泛的。
结论
神经网络模型主要利用监督式学习产生价值,其核心在于已知训练样本的输入和输出。实际应用中,神经网络模型主要解决的是监督式学习的问题。例如,房屋价格预测模型通过训练样本学习并预测房价;线上广告模型利用用户信息和广告类型预测用户点击行为;机器视觉通过图片像素值输入,输出图片类别;语音识别模型将语音信号转化为文字信息;智能翻译模型可以将一种语言的输入转化为另一种语言的输出。因此,神经网络配合监督式学习在各领域有广泛应用。
3.1神经网络基础之逻辑回归
3.1.1 二分类
① 我们知道逻辑回归模型一般用来解决二分类(Binary Classification)问题。
② 二分类就是输出y只有{0,1}两个离散值(也有{-1,1}的情况)。
③ 我们以一个图像识别问题为例,判断图片中是否有猫存在,0代表noncat,1代表cat。
④ 主要是通过这个例子简要介绍神经网络模型中一些标准化的、有效率的处理方法和notations。

① 如上图所示,这是一个典型的二分类问题。
② 一般来说,彩色图片包含RGB三个通道。例如该cat图片的尺寸为(64,64,3)。
③ 在神经网络模型中,我们首先要将图片输入x(维度是(64,64,3))转化为一维的特征向量(feature vector)。
④ 方法是每个通道一行一行取,再连接起来。
⑤ 由于64x64x3=12288,则转化后的输入特征向量维度为(12288,1)。此特征向量X是列向量,维度一般记为𝑛𝑥𝑛𝑥。
① 如果训练样本共有m张图片,那么整个训练样本X组成了矩阵,维度是(𝑛𝑥𝑛𝑥,m)。注意,这里矩阵X的行𝑛𝑥𝑛𝑥代表了每个样本x(i)特征个数,列m代表了样本个数。
② 这里,Andrew解释了X的维度之所以是(𝑛𝑥𝑛𝑥,m)而不是(m,𝑛𝑥𝑛𝑥)的原因是为了之后矩阵运算的方便。算是Andrew给我们的一个小小的经验吧。
③ 而所有训练样本的输出Y也组成了一维的行向量,写成矩阵的形式后,它的维度就是(1,m)。
3.1.2 逻辑回归预测值
① 接下来我们就来介绍如何使用逻辑回归来解决二分类问题。
② 逻辑回归中,预测值h^=P(y=1 | x)表示为1的概率,取值范围在[0,1]之间。
③ 这是其与二分类模型不同的地方。逻辑回归的预测值为一个连续的概率。
④ 使用线性模型,引入参数w和b。权重w的维度是(𝑛𝑥𝑛𝑥,1),b是一个常数项。这样,逻辑回归的线性预测输出可以写成:
![]()
① 值得注意的是,很多其它机器学习资料中,可能把常数b当做𝑤0𝑤0处理,并引入𝑥0=1𝑥0=1。
② 这样从维度上来看,x和w都会增加一维。
③ 但在本课程中,为了简化计算和便于理解,Andrew建议还是使用上式这种形式将w和b分开比较好。
① 上式的线性输出区间为整个实数范围,而逻辑回归要求输出范围在[0,1]之间,所以还需要对上式的线性函数输出进行处理。
② 方法是引入Sigmoid函数,让输出限定在[0,1]之间。这样,逻辑回归的预测输出就可以完整写成:
![]()
① Sigmoid函数是一种非线性的S型函数,输出被限定在[0,1]之间,通常被用在神经网络中当作激活函数(Activation function)使用。
② Sigmoid函数的表达式和曲线如下所示:
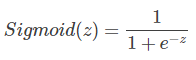
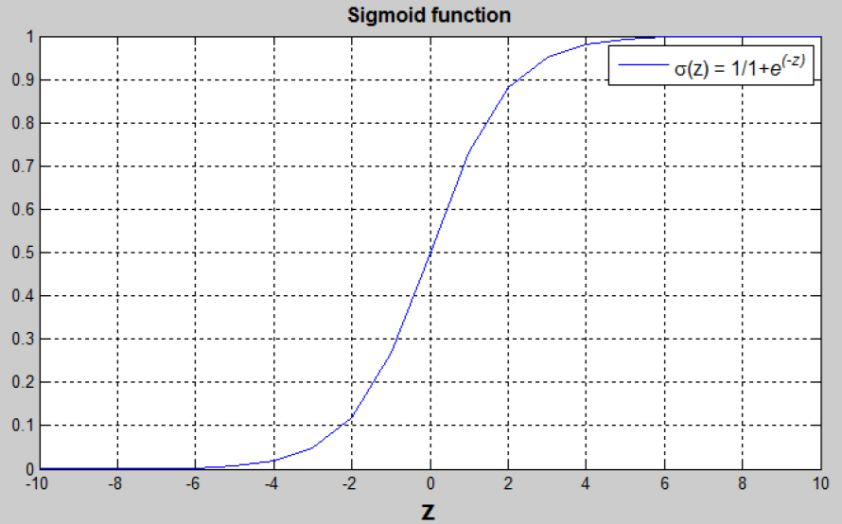
① 从Sigmoid函数曲线可以看出,当z值很大时,函数值趋向于1。
② 当z值很小时,函数值趋向于0。
③ 且当z=0时,函数值为0.5。
④ 还有一点值得注意的是,Sigmoid函数的一阶导数可以用其自身表示:
![]()
⑤ 这样,通过Sigmoid函数,就能够将逻辑回归的输出限定在[0,1]之间了。
3.1.3逻辑回归损失函数
① 逻辑回归中,w和b都是未知参数,需要反复训练优化得到。
② 因此,我们需要定义一个cost function,包含了参数w和b。
③ 通过优化cost function,当cost function取值最小时,得到对应的w和b。
![]()

① 如何定义所有m个样本的cost function呢?先从单个样本出发,我们希望该样本的预测值y^与真实值越相似越好。
② 我们把单个样本的cost function用Loss function来表示,根据以往经验,使用平方误差(squared error)来衡量,如下所示:
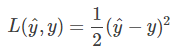
① 但是,对于逻辑回归,我们一般不使用平方误差来作为Loss function。原因是这种Loss function一般是non-convex的。
② non-convex函数在使用梯度下降算法时,容易得到局部最小值(local minumum),即局部最优化。
③ 而我们最优化的目标是计算得到全局最优化(Global optimization)。
④ 因此,我们一般选择的Loss function应该是convex的。
① Loss function的原则和目的就是要衡量预测输出y^与真实样本输出y的接近程度。
② 平方损失其实也可以,只是它是non-convex的,不利于使用梯度下降算法来进行全局优化。
③ 因此,我们可以构建另外一种Loss function,且是convex的,如下所示:
![]()
① 我们来分析一下这个Loss function,它是衡量错误大小的,Loss function越小越好。

② y=1,输入特征向量X可以获得它的预测值y^,若它的预测值与1越接近,则损失越小。y=0,同理。
① 因此,这个Loss function能够很好地反映预测输出y^与真实样本输出y的接近程度,越接近的话,其Loss function值越小。而且这个函数是convex的。
② 上面我们只是简要地分析为什么要使用这个Loss function,后面的课程中,我们将详细推导该Loss function是如何得到的。并不是凭空捏造的哦。
① 还要提一点的是,上面介绍的Loss function是针对单个样本的。那对于m个样本,我们定义Cost function,Cost function是m个样本的Loss function的平均值,反映了m个样本的预测输出y^与真实样本输出y的平均接近程度。Cost function可表示为:
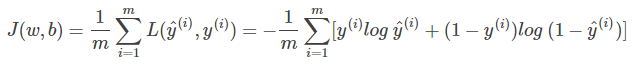
② Cost function已经推导出来了,Cost function是关于待求系数w和b的函数。
③ 我们的目标就是迭代计算出最佳的w和b值,最小化Cost function,让Cost function尽可能地接近于零。
④ 其实逻辑回归问题可以看成是一个简单的神经网络,只包含一个神经元。这也是我们这里先介绍逻辑回归的原因。
总结
第一周主要了解了一些机器学习相关的基本概念,比如什么是监督学习,什么是非监督学习,以及机器学习当前的一些主要应用领域,对机器学习有了初步的了解和基本的认识。以及逻辑回归的部分内容。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









