






 本文详细介绍了在使用R语言进行数据分析时,如何识别和处理原始数据中的缺失值和异常值,包括单变量和多变量方法,如删除缺失值、鲁棒方法(如robustzscore和IQR)、Mahalanobis_robust以及利用孤立森林和KNN进行异常值检测。
本文详细介绍了在使用R语言进行数据分析时,如何识别和处理原始数据中的缺失值和异常值,包括单变量和多变量方法,如删除缺失值、鲁棒方法(如robustzscore和IQR)、Mahalanobis_robust以及利用孤立森林和KNN进行异常值检测。
正确的数据分析结果有赖于有效的数据。实际获取得到的原始数据,往往可能存在缺失值、异常值、重复值等问题数据,为了保证数据的质量需要进行数据清洗操作对问题数据进行识别,具体如何操作我们以r语言为例进行探讨。
首先针对已有数据进行缺失值的识别,绘图如下
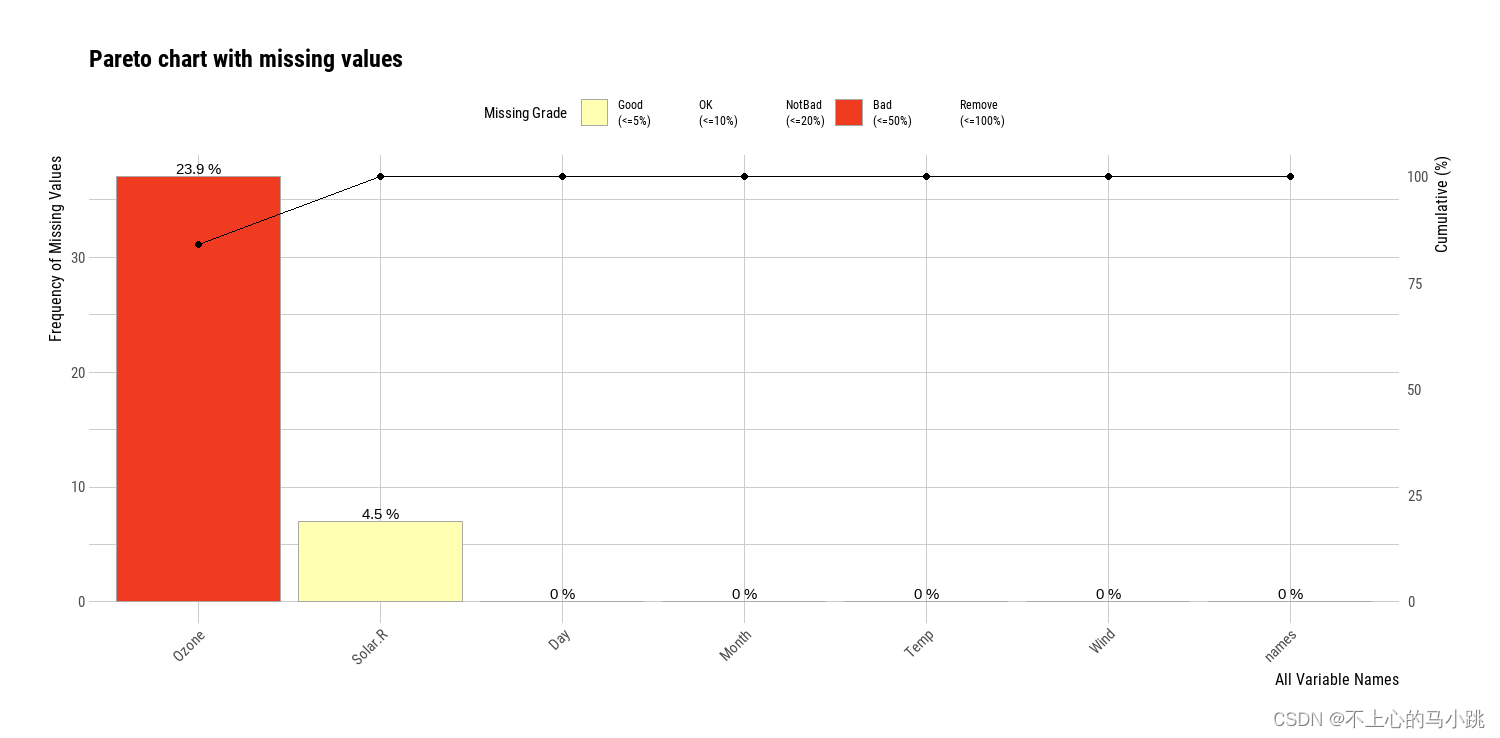
对识别得到的缺失值进行处理,这里直接进行删除。
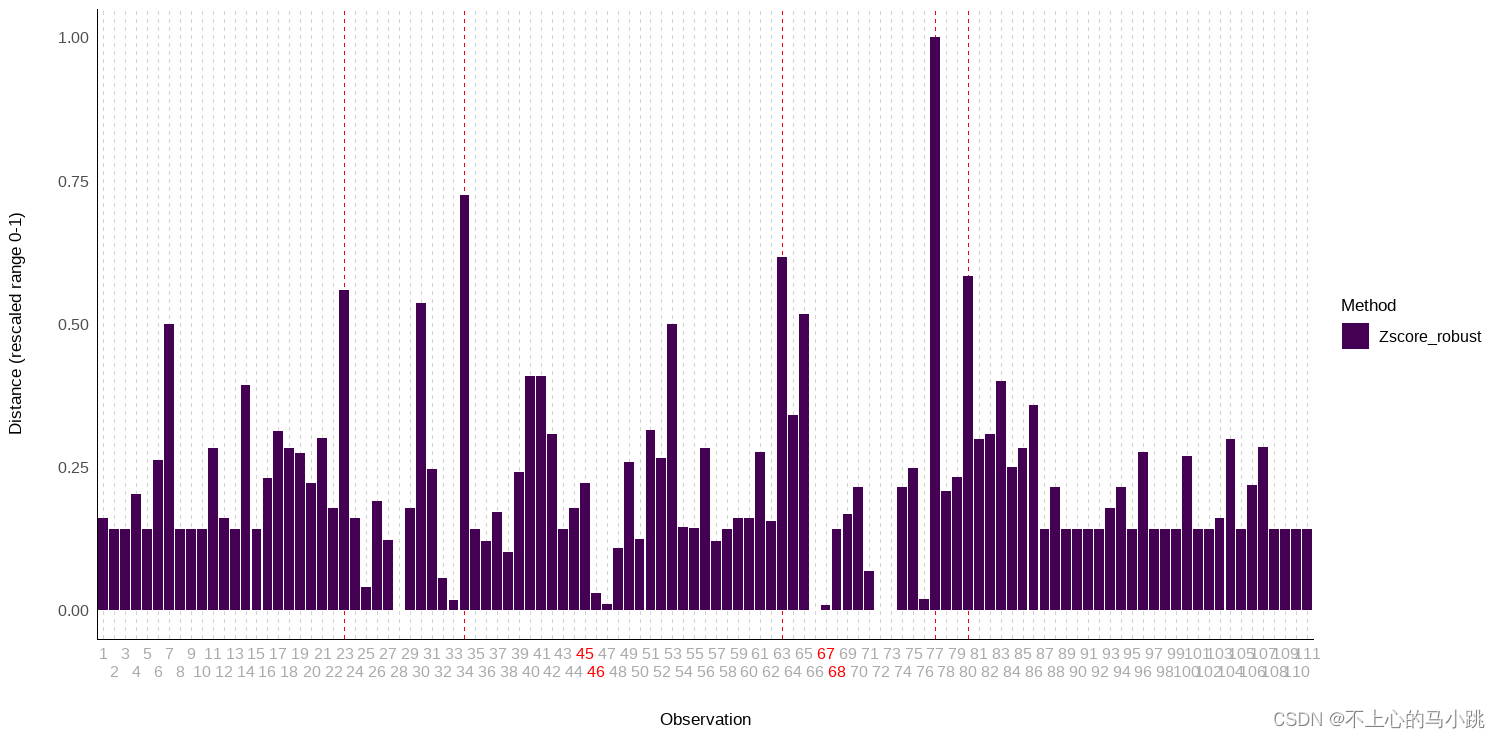
采用单变量识别的方法识别异常值,目前处理异常值的单变量相关指南往往推荐鲁棒方法,可采用robust z score (基于中位数绝对偏差)、iqr(箱线图)以及置信区间相关方法
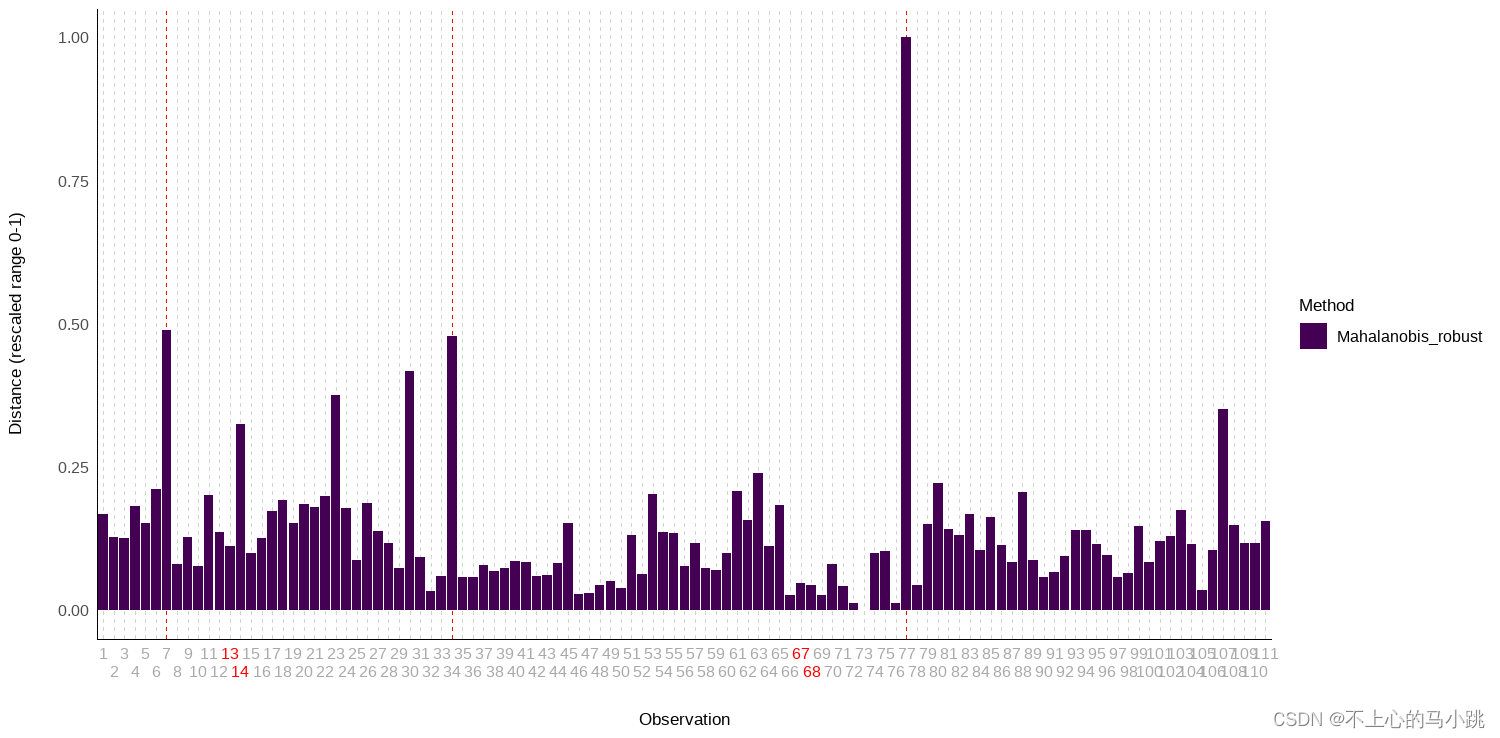
采用多变量识别方法,如mcd,lof 等等这里选择 mahalanobis_robust方法
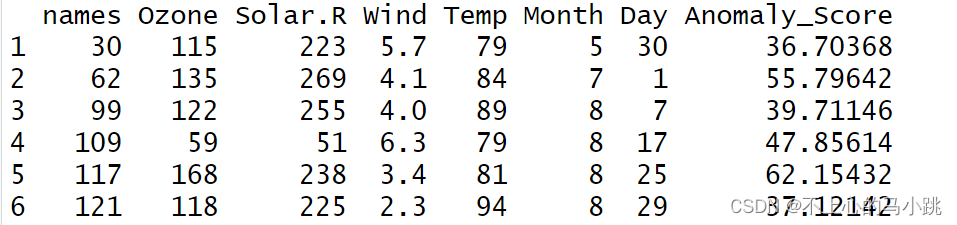
同样有些模型本身就可以用来进行异常值识别如孤立森林,knn等。下面给出结果示意,仅供参考



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











