







📢本篇文章是博主强化学习(RL)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在👉强化学习专栏:
【强化学习】- 【强化学习进阶】(1)---《基于价值VS 基于策略》
基于价值(Value)VS 基于策略(Policy)
目录
1. 基于价值的算法 (Value-based Methods)
2. 基于策略的算法 (Policy-based Methods)
3. 混合算法 (Actor-Critic Methods)
4. 基于模型的方法 (Model-based Methods)
强化学习(Reinforcement Learning,RL) 大致可以分为两类:基于价值的算法 和 基于策略的算法、基于Actor-Critic(混合)以及基于模型的。这几类算法分别侧重于不同的学习方法和策略更新方式。
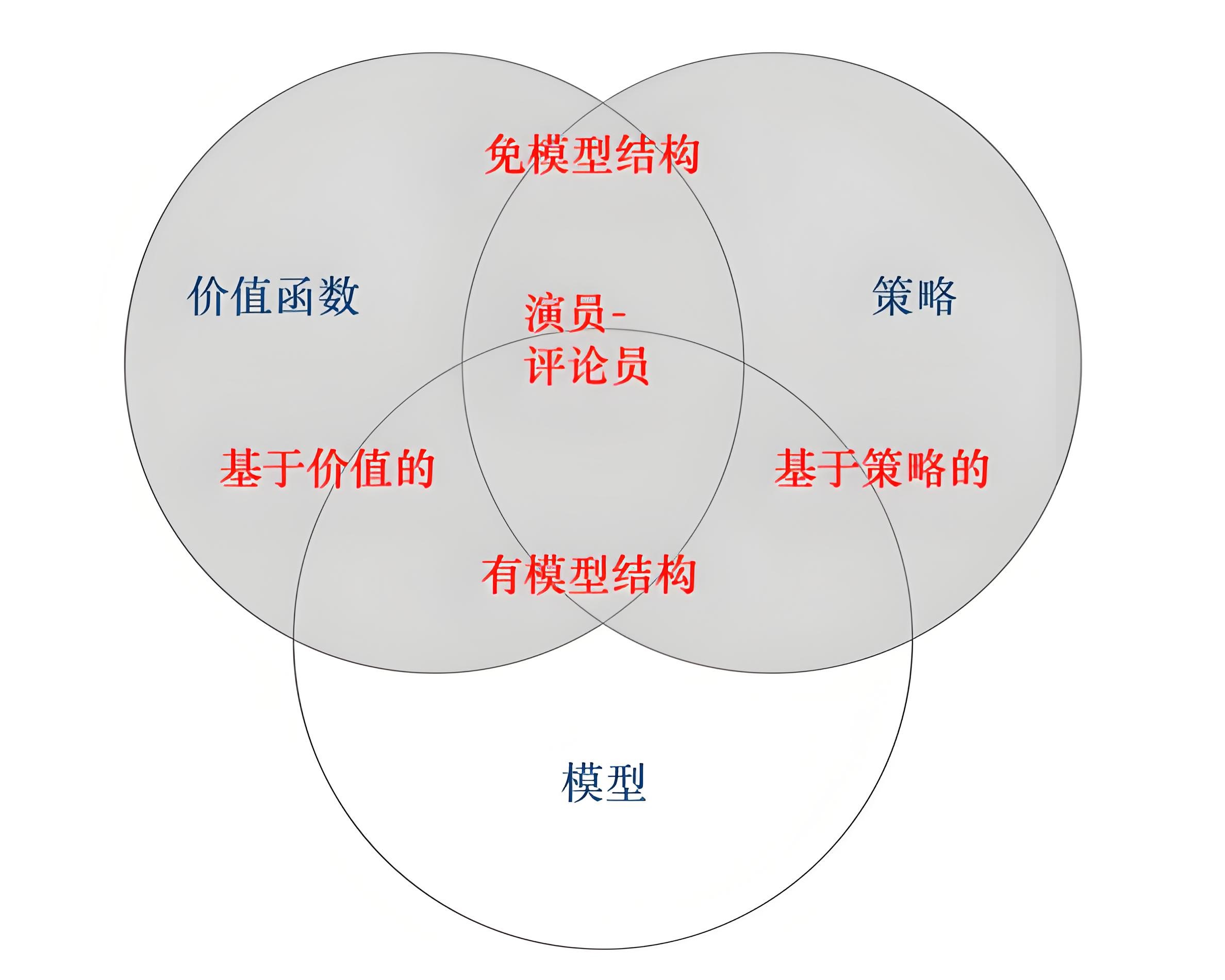
1. 基于价值的算法 (Value-based Methods)
基于价值的算法 主要通过估计 状态-动作值函数(Q函数) 或 状态值函数(V函数) 来学习如何选择动作(一般为贪心选择)。这些算法通过计算每个状态(或状态-动作对)下的预期累积回报来优化决策。
关键思想:
- 学习一个 价值函数,该函数表示在某一状态或状态-动作对下,采取某个动作后能获得的期望回报。
- 在学习过程中,价值函数通过 Q-learning、Sarsa 等方法进行估计。
- 贪心策略 基于当前的价值函数,选择 价值最大化 的动作。
典型算法:
- Q-learning:通过更新 Q 值来寻找最优策略。
- 更新公式:
- 更新公式:
- Sarsa:与 Q-learning 类似,但它使用的是 当前策略 而不是最大 Q 值来更新。
- Deep Q-Network (DQN):使用神经网络来近似 Q 函数,以应对大规模状态空间。
特点:
- 强调通过估计和优化 价值函数 来选择动作。
- 通常是 离散动作空间 下的强大方法。
- 在 连续动作空间 中可能需要扩展(如 DDPG、TD3 等)。
2. 基于策略的算法 (Policy-based Methods)
基于策略的算法 直接学习 策略函数,即 给定状态下采取某个动作的概率分布。这些算法并不依赖于显式的价值函数,而是通过优化策略来直接输出动作。
- 离散动作空间:Actor 网络会输出每个动作的 概率,例如使用 Softmax 函数,表示每个动作的选择概率。
- 连续动作空间:Actor 网络会输出均值和标准差(例如高斯分布的参数),然后根据这些参数来从分布中采样动作。
关键思想:
- 学习一个 直接的策略,该策略映射状态到动作(对于连续动作空间通常是确定性的)。
- 策略的优化通常通过 策略梯度 或 基于期望回报的优化 来进行。
- 在优化过程中,策略被直接更新,以增加采样动作的期望回报。
典型算法:
- Policy Gradient (PG):通过直接优化策略的期望回报来更新策略。
- 策略梯度公式:
其中
是回报,
是策略,
是策略的参数。
- 策略梯度公式:
- REINFORCE:一种基本的策略梯度方法,使用蒙特卡罗方法估计梯度。
- Proximal Policy Optimization (PPO):一种基于策略梯度的优化方法,改进了策略的稳定性和收敛性。
- Actor-Critic (AC):结合了基于价值和基于策略的方法,使用 Actor 网络输出策略,使用 Critic 网络估计价值函数。
特点:
- 适用于 连续动作空间 和 高维状态空间 的问题。
- 不需要值函数(但可以结合值函数)。
- 直接优化策略,适用于一些 复杂的决策任务。
3. 混合算法 (Actor-Critic Methods)
Actor-Critic 方法结合了 基于价值 和 基于策略 的优点。Actor 网络负责选择动作,而 Critic 网络则评估动作的价值。
关键思想:
- Actor:负责选择动作,输出 策略。
- Critic:负责评估当前策略的表现,输出 价值函数(通常是状态值函数或状态-动作值函数)。
- Actor-Critic 方法通过 策略梯度 和 值函数更新 共同优化智能体的性能。
典型算法:
- A3C (Asynchronous Advantage Actor-Critic):采用多线程并行训练,稳定训练过程。
- DDPG (Deep Deterministic Policy Gradient):为连续动作空间设计的 Actor-Critic 方法。
- TD3 (Twin Delayed Deep Deterministic Policy Gradient):对 DDPG 的改进,进一步提高稳定性。
4. 基于模型的方法 (Model-based Methods)
除了基于价值和基于策略的算法,还有一种 基于模型的方法,这些方法尝试通过学习环境的模型(例如,转移函数和奖励函数)来进行规划和决策。模型可以用来模拟环境,并生成模拟经验来优化策略。
例如:奖励模型(Reward Model)
典型算法:
- Dyna-Q:结合了 Q-learning 和环境模型的学习,通过模型生成模拟的经验进行训练。
- Monte Carlo Tree Search (MCTS):广泛用于决策树的搜索中,尤其在策略评估时使用模型来进行预测。
🔍 深度解析
“DDPG 输出的是动作,为什么它不是基于策略的算法?”
DDPG 同时具有“策略”成分,被归类为 是 Actor-Critic 的一种。
DDPG 是基于策略的 + 基于价值的混合算法(Actor-Critic),因为它既有确定性的“策略”是,同时 heavily 依赖 Q 值函数进行训练。
🔹 首先,策略分为两种:
| 策略类型 | 描述 | 示例 |
|---|---|---|
| 随机策略(Stochastic Policy) | 输出动作的概率分布(如 PG, PPO) | |
| 确定性策略(Deterministic Policy) | 输出一个具体动作 |
👉 DDPG 使用的是确定性策略:
🔹 然而,光有策略 ≠ 基于策略算法!
基于策略的算法 的核心是:
直接通过优化期望回报对策略参数进行梯度更新(例如 REINFORCE、PPO)。
而 DDPG 虽然有策略函数(Actor),但:
-
策略更新依赖 Critic 网络的 Q 值估计:
也就是说,DDPG 的策略更新是依赖 Q 值梯度反向传导的,并不是直接根据策略自身的期望回报来优化。
-
Critic 网络是核心评估器:
- Critic 学习 Q 值函数,用于训练 Actor。
- 没有 Critic,Actor 根本无法优化。
- 所以,它的策略是 “从值函数中学出来的”。
虽然 DDPG 有策略(Actor 输出确定性动作),但由于 它不是独立更新策略,而是通过 Critic 提供的 Q 值梯度来间接优化策略,因此它本质上是 基于 Actor-Critic 的算法。
至于说他偏重于基于策略还是基于价值,我个人倾向于基于价值。
🧠 总结:
强化学习算法大致可以分为以下几类:
- 基于价值的算法:通过学习价值函数来选择动作(如 Q-learning、DQN)。
- 基于策略的算法:通过学习策略函数直接选择动作(如 Policy Gradient、REINFORCE)。
- 混合算法:结合价值函数和策略函数,既有基于价值的元素,又有基于策略的元素(如 Actor-Critic、DDPG)。
- 基于模型的方法:通过学习环境模型进行决策和规划(如 Dyna-Q、MCTS)。
分类方法:
| 算法 | 策略类型 | 是否独立更新策略? | 依赖 Q 函数? | 类型归属 |
|---|---|---|---|---|
| PPO, REINFORCE | 随机策略 | ✅ | ❌ | 基于策略 |
| Q-learning, DQN | 无策略 | ❌ | ✅ | 基于价值(贪心) |
| DDPG, TD3 | 确定性策略 | ❌(依赖 Critic) | ✅ | Actor-Critic/ 基于策略+价值 |
| SAC | 随机策略 | ❌(依赖 Critic) | ✅ | Actor-Critic / 基于策略+价值 |
更多强化学习文章,请前往:【强化学习(RL)】专栏
博客都是给自己看的笔记,如有误导深表抱歉。文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者添加VX:Rainbook_2,联系作者。✨



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











