







一、两个字符编码的参数
javac和java是JDK自带的工具,其中javac是编译工具,java工具启动Java虚拟机并执行java程序。这两个工具都带有设置字符编码的选项。本文讨论字符编码选项的使用场景,和出现乱码的原因。
javac 的字符编码选项
javac -encoding CharSet XXXX.java //CharSet为XXXX.java文件的字符编码。javac编译器根据-encoding后跟随的字符编码,解析.java文件。-encoding不设置的时候,使用系统默认字符集解析.java文件。Windows的默认字符集是GBK。
无论之前的.java文件采用什么编码,编译后的.class文件都使用UTF-8编码。
如果-encoding指定的字符编码与.java文件的字符编码不一致,不一定编译失败,会给后续乱码埋下隐患。
JVM的字符编码选项
java -Dfile.encoding= CharSet XXXX //XXXX为class文件,CharSet是本地设备支持的字符集。-Dfile.encoding并不是设置JVM虚拟机内存字符编码的。JVM虚拟机内存的字符编码是无法设置的,都是UTF-16,这个参数设置的是JVM输入流、输出流默认使用的编码/解码方式。
- 当我们不手动设置JVM参数-Dfile.encoding时,系统默认字符集则取决于语言环境和底层操作系统(Windows的CMD下是GBK,Linux下则跟设置的语言环境有关)
- 当我们手动设置JVM参数-Dfile.encoding=xxx,如果xxx是不支持的字符集,则默认使用’UTF-8’编码。
也可以通过Charset.defaultCharset()返回此 JVM的charset。默认 charset 在虚拟机启动时决定,通常根据语言环境和底层操作系统的 charset 来确定。
Charset.defaultcharset()指的是JVM输入流、输出流默认使用的编码/解码方式。
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}看到上面说可以通过设置系统属性file.encoding来设置默认字符集,那么有些朋友就想通过在运行时,通过System.setProperty("file.encoding", "GBK");来动态改变字符集,虽然可以通过System.setProperty("file.encoding","GBK")修改属性值,但仅仅是修改了file.encoding这个属性值,并不会影响Charset.defaultCharset()。因为JVM启动时就已经设置了Charset.defaultcharset()。
我们可以验证一下Windows环境下的默认字符集
import java.nio.charset.Charset;
public class CharsetTest {
public static void main(String[] args) {
System.out.println(Charset.defaultCharset());
}
}注意要使用命令行的方式编译运行
javac CharsetTest.java
java CharsetTest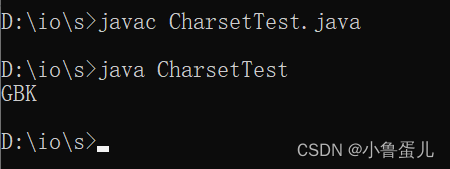
为什么不在idea直接测试呢?
因为idea可以设置字符集,具体如图
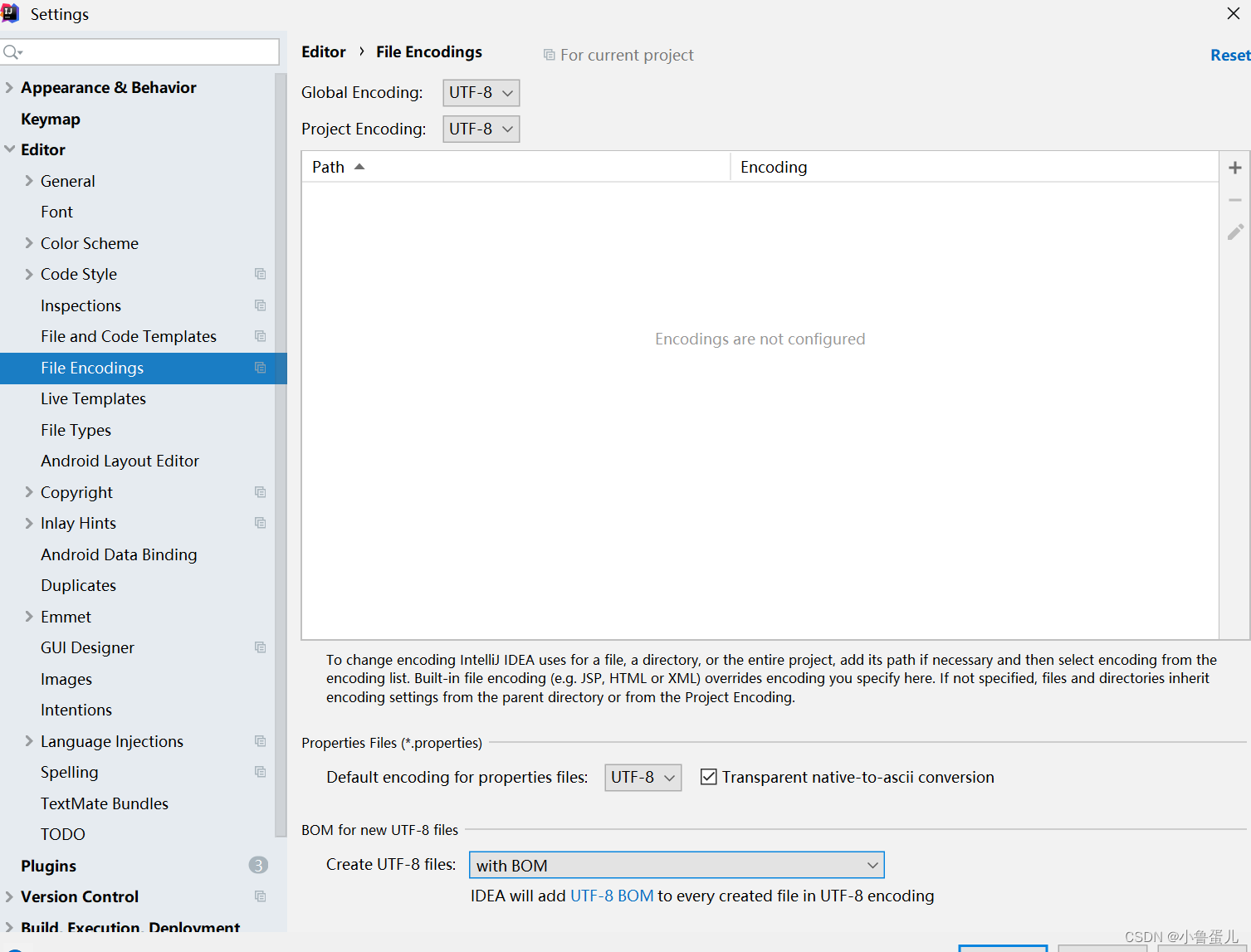
你设置的字符集不同,结果自然不一样。
这里再说明一下 sun.jnu.encoding 和 file.encoding 的区别
sun.jnu.encoding 影响文件名的创建,而 file.encoding 则影响到文件内容。
二、Java在编译到执行过程涉及到的字符编码

这里其实并不是UTF-8,是一种modified UTF-8,这里就姑且认为是UTF-8。
上图是.java文件从编译到执行的几个过程,这几个过程涉及到字符编码,具体解释如下:
①:A.java就是一个文本文件(以某种编码格式来存储:UTF-8、GBK、ISO-8859-1等),java编译器要解析这个文本文件并编译生成.class文件。而要想解析它,就必须知道它的编码方式。如果指定的编码与文件的编码不一致,要么编译失败,要么导致class文件中的字符乱码。
②:以不同编码方式编码的A.java经过Java编译器编译生成了同一个相同的A.class,编码格式为UTF-8。
③:Java虚拟机以二进制字节流的形式加载A.class,A.class中的字符编码是UTF-8,加载到JVM虚拟机内存中后,字符编码是UTF-16。
④:输出结果,如代码中指定了字符集,则按照代码中指定的字符集输出到设备中。如果代码中未指定字符集,则按照JVM启动时 -Dfile.encoding指定的字符集,如果没有指定-Dfile.encoding为默认的字符集输出到设备中。
从上图可以理解不管采用那种格式的源文件,只要正确告诉编译器源文件的编码格式,编译器就会得到正确的结果。同时只要告诉JVM正确的输出流需要的编码格式,JVM就可以返回正确编码格式的输出流。
那么要想不产生乱码就需要注意如下两个环节:
- 告诉编译器你java源文件的编码格式。
- 告诉jvm你显示或者构造字符串输出流时的希望的编码。
JVM中运行时数据都是使用UTF-16进行编码的。为什么JVM使用的是UTF-16,而不适用兼容性更好的UTF-8呢?
这是因为历史原因导致JVM运行时的数据使用UTF-16的编码。在Unicode最初诞生的时候,由于当时只有一个16位长的基本多文种平面,也就是只有0~65535的空间,两个字节刚好够用。这也解释了为什么Java中char是两个字节。
但是到了2001年,中国人大举入侵ISO和Unicode委员会,用已经颁布的GB18030-2000为基础,在Unicode 3.1标准中一口气加入了42711个CJK扩展字符,整个Unicode字符集一下增大到94205个字符,2个字节放不下了,UTF-16原来是变长编码的事也被人想起来了(中国人偷笑,GB系列从第一天起就是变长编码)。从此UTF-16就变得很尴尬,它一来存储空间利用率不高,二来又是个变长编码无法直接访问其中的码元。但是完全放弃UTF-16成本太高,所以现在JVM的运行时数据依然是UTF-16编码的。
由于成本问题不能放弃UTF-16,但是UTF-8的兼容性和流行程度,又使得JVM必须做点什么来使得其内部数据不会被编码方式影响,于是就有了这个modified UTF-8。
modified UTF-8
在通常用法下,Java程序语言在通过InputStreamReader和OutputStreamWriter读取和写入串的时候支持标准UTF-8。在Java内部,以及Class文件里存储的字符串是以一种叫modified UTF-8的格式存储的。
modified UTF-8 大致和 UTF-8 编码相同,但是有以下三个不同点:
- 空字符(null character,U+0000)使用双字节的0xc0 0x80,而不是单字节的0x00。
- 仅使用1字节,2字节和3字节格式,而UTF-8支持更多的字节
- 基本多文种平面之外的补充字符以代理对(surrogate pairs)的形式表示
使用双字节空字符保证了在已编码字符串中没有嵌入空字节。因为C语言等语言程序中,单字节空字符是用来标志字符串结尾的。当已编码字符串放到这样的语言中处理,一个嵌入的空字符将把字符串一刀两断。
modified UTF-8在没有超过前三个字节表示的时候,和UTF-8编码方式一样,但是超过以后会以代理对(surrogate pairs)的形式表示。至于为什么要以代理对形式表示。这个是因为JVM的默认编码是UTF-16导致的。
一开始的Unicode只有一个可以用16位长完全表示的基本多文种平面,所以Java中的字符(char)为16位长,一个char可以存所有的字符。后来Unicode增加了很多辅助平面,两个字节存不下那些字符,但是为了向后兼容Java不可能更改它的基本语法实现,于是对于超过U+FFFF的字符 (从0x10000到0x10FFFF,称作扩展字符)就需要用两个16位长数据来表示。modified UTF-8由UTF-16格式的代理码元来代替原先的Unicode码元作为字符编码表的码元。
UTF-16格式的代理码元编码规则如下:
1)先将UTF-16补充码的数值减去0x10000;
2)将减掉之后的数值分为两个10比特的数值,假设高10位的值表示为Vh,低10位的值表示为Vl;
3)对于数值对中第一个16位的双字节来说,用0xD800加上高10位的值Vh;
4)对于数值对中第二个16位的双字节来说,用0xDC00加上低10位的值Vl。
数值对中的每一个16位的值,MUTF-8都会使用3个字节对其进行编码。由于每个UTF-16的补充字符都需要用两个16位的值对来表示,所以MUTF-8编码过后会使用6个字节。
这里可以计算一下,UTF-8要表示16位的数值需要三个字节,是这样表示的,1110xxxx 10xxxxxx 10xxxxxx,其中1和0是标识位,x代表具体的Unicode值.
JVM把UTF-16编码出来的16位长的数据(2字节,操作系统用8位长的数据,即1字节)作为最小单位进行信息交换。这样的话既不改变原来JVM中的编码规则,又减少了很多扩展字符从UTF-8转码到UTF-16时的运算量,是不是很刺激?正常从UTF-8转到UTF-16要先读出Unicode值,然后进行计算代理码元才能得到.
modified UTF-8保证了一个已编码字符串可以一次编为一个UTF-16码,而不是一次一个Unicode码位,使得所有的Unicode字符都能在Java上显示。
不过也不是没有缺点的,使用modified UTF-8进行解码解出来的是UTF-16编码编出来的数据,而UTF-16处理扩展字符需要两个16位长表示。也就是说,要用两个代理码元共同表示一个Unicode码位。原本使用UTF-8编码只需要最多4个字节就能存储一个Unicode码位,使用modified UTF-8编码后却需要6个字节来存储两个代码单元。
总结起来就是,modified UTF-8是对UTF-16的再编码,modified UTF-8和UTF-8是两种完全不同的编码。
所以JVM无需解码UTF-16的数据,modified UTF-8代理码元会处理这个映射关系
参考文章
java jvm 编码_Javac和JVM的字符编码问题_weixin_39950764的博客-CSDN博客
Java 编译、运行过程中的字符编码 - 简书 (jianshu.com)















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









