







概要
之前业务需要实现聚合查询,使用taos流式计算实现,本文记录其中流式计算中遇到的坑。
流式计算概念
流式计算(Stream Processing),也称为实时流计算,是一种计算模式,它能够对连续生成的数据流进行实时处理和分析。与传统的批处理(Batch Processing)模式不同,流式计算不需要等待所有数据到齐后才开始处理,而是以数据产生为驱动,边接收数据边进行处理。
多用于物联网,金融等大量连续数据处理中
例如数采软件,近期数据存储原始数据,同时通过流式计算存储聚合数据,过期时删除原始数据,只查询聚合数据即可大大降低数据量
Taos流式计算语句
1.创建流式运算语句
CREATE STREAM [IF NOT EXISTS] stream_name [stream_options] INTO stb_name[(field1_name, ...)] [TAGS (create_definition [, create_definition] ...)] SUBTABLE(expression) AS subquery
其中stream_options中的参数为
stream_options: {
TRIGGER [AT_ONCE | WINDOW_CLOSE | MAX_DELAY time]
WATERMARK time
IGNORE EXPIRED [0|1]
DELETE_MARK time
FILL_HISTORY [0|1]
IGNORE UPDATE [0|1]
}
TRIGGER:触发器,设置什么时候触发流式计算
WATERMARK:水印,判断时间戳是否已经计算
IGNORE_EXPIRED:是否忽略过期数据
DELETE_MARK:删除时间标记,超时自动删除
FILL_HISTORY:是否启动流式时计算历史数据
IGNORE_UPDATE:是否忽略修改数据
其中subquery的参数为
subquery: SELECT select_list
from_clause
[WHERE condition]
[PARTITION BY tag_list]
[window_clause]
subquery代表了定义的流式查询语句
创建聚合库
上面简单介绍了流式查询语句,下面根据聚合时间规划数据库
数据库 DATABASE_6M:用来存储6小时、1天、7天聚合
数据库 DATABASE_1Y:用来存储1月聚合
创建6小时聚合流语句
CREATE STREAM IF NOT EXISTS STREAM_6h fill_history 1 INTO DATABASE_6M.TABLE_NUMERICAL_6h SUBTABLE(CONCAT('p_6h_',id)) AS SELECT _WSTART AS TS, MAX(POINTVALUE) AS MAX_VALUE ,MIN(POINTVALUE) AS MIN_VALUE, AVG(POINTVALUE) AS AVG_VALUE, FIRST(POINTVALUE) AS FIRST_VALUE, LAST(POINTVALUE) AS LAST_VALUE, APERCENTILE(POINTVALUE,50) AS APERCENTILE_VALUE, COUNT(POINTVALUE) AS COUNT_VALUE FROM DATABASE_3M.TABLE_NUMERICAL PARTITION BY EQPID ID INTERVAL(6h)
该语句创建STREAM_6h流,同时计算历史数据,定义了子表的命名规则为p_6h_加pid,间隔6小时
通过之前实现的createStream方法创建流
@Override
public void initStream() {
//原始数据数据库名
String originSource = TDengineDatabaseParamEnums.MONTH_THREE.getDatabaseName() + "." + TDengineConstants.TABLE_NUMERICAL_NAME;
TDengineDatabaseParamEnums[] values = TDengineDatabaseParamEnums.values();
for (TDengineDatabaseParamEnums value : values) {
String databaseName = value.getDatabaseName();
if (databaseName.equals(TDengineDatabaseParamEnums.MONTH_THREE.getDatabaseName())) {
continue;
}
//原始数据源
List<String> aggregateTimeList = StringUtil.getAggregateTimeByDatabaseName(databaseName);
aggregateTimeList.forEach(aggregateTime -> {
String streamName = TDengineConstants.STREAM_NAME_PREFIX + aggregateTime;
String stbName = TDengineConstants.STREAM_TABLE_PREFIX + aggregateTime;
//查询内容
String subquery = StrUtil.format(TDengineSqlConstants.STREAM_SUBQUERY, originSource, aggregateTime);
createStream(streamName, null, stbName, subquery);
});
}
}
具体实现详见上篇文章Tdneing整合MybatisPlus
创建完成后结构如下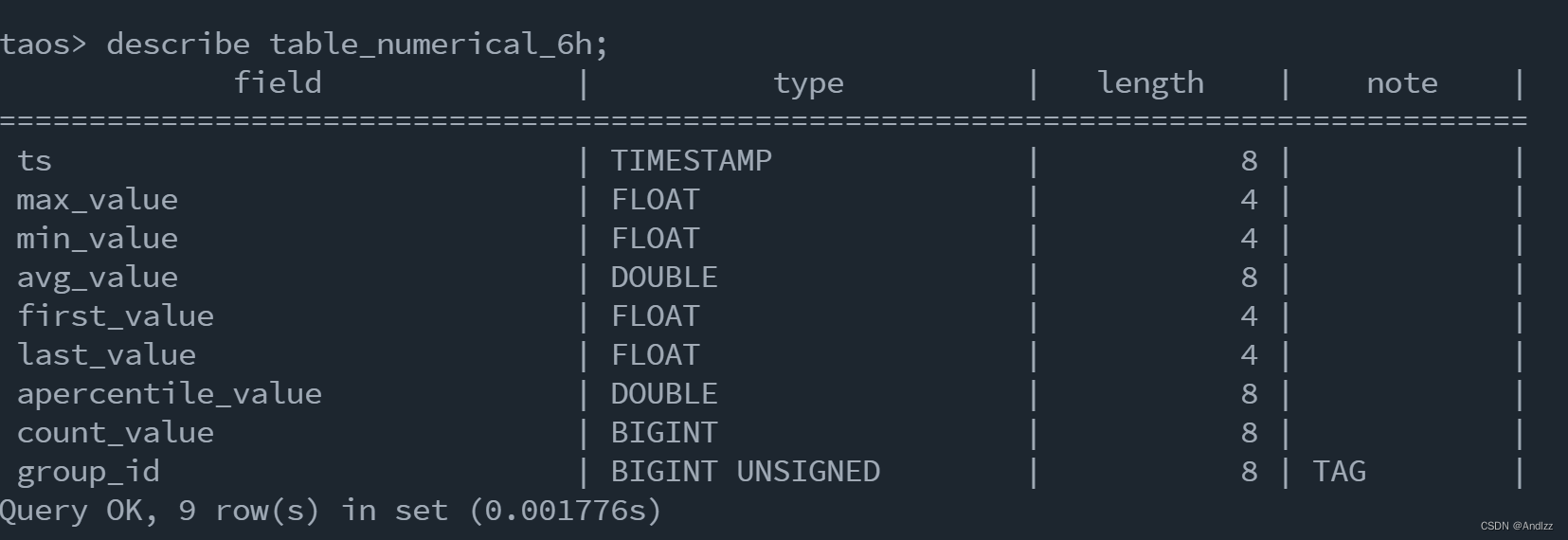
获取聚合数据
1.创建聚合结构实体
@EqualsAndHashCode(callSuper = true)
@Data
@TableName("table_numerical_6h.table_numerical_6h;")
public class TableNumerical extends BaseTaosModel<TableNumerical> {
@ApiModelProperty("最大值")
private Float maxValue;
@ApiModelProperty("最小值")
private Float minValue;
@ApiModelProperty("平均值")
private Double avgValue;
@ApiModelProperty("开始值")
private Float firstValue;
@ApiModelProperty("结束值")
private Float lastValue;
@ApiModelProperty("中位数")
private Double apercentileValue;
@ApiModelProperty("总数")
private Long countValue;
@ApiModelProperty("groupId")
private Long groupId;
}
其余文件省略,查询时根据条件查询即可,示例如下
public void test(){
Timestamp startTime = Timestamp.valueOf(LocalDateTime.now());
Timestamp endTime = Timestamp.valueOf(LocalDateTime.now().plusDays(1));
// 查询子表为4617573834247140801的今天的数据,聚合6小时
List<TableNumerical> list = tableNumericalService.lambdaQuery()
.eq(TableNumerical::getGroupId, "4617573834247140801")
.le(TableNumerical::getTs, endTime)
.ge(TableNumerical::getTs, startTime)
.list();
}
总结
到此,聚合查询实现完毕,最好结合上一篇MybatisPlus整合观看,其中stream_options参数最好根据实际结构决定,本结构用于处理历史数据,所以使用了FILL_HISTORY参数,但是流式计算占用硬盘和内存非常高,暂未测试此参数和taos版本与服务器硬件关联















 2264
2264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









