







项目中很常见的一个需求就是取出每个种类的前n条数据,这是我们通常想到分组(group by),但是group by后伴随着数据的聚合 每个种类只保留了一条数据,这并不满足我们的需求取前n条数据,这时候我们可以采用以下方式
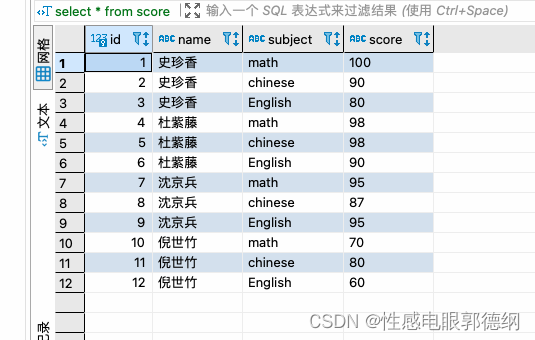
- 场景:有这样一张学生信息表,取每科成绩的前两名 (建表语句见文末)
代码实现:
select * from score a
where 2 > (select count(*) from score b
where b.subject = a.subject
and b.score > a.score
) order by a.subject ,a.score desc
核心思想:
where中的条件可以理解为把原表多加一列排序列,使得每个学科的成绩都有一个排名,这样我们只需要取出排名靠前的两个人就可以实现

那么排名是怎么实现的呢? 这时候我们看 b.subject = a.subject and b.score > a.score 语句
第一条数据执行 替换为数据 是不是就是 math = math and 100 > 100 这个时候很显然 100>100是不成立的,所以 count(*)统计出来的就是0
第二条数据执行 替换为数据 math = math and 100 > 98 此时条件成立可以得出 count(*) = 1 以此类推;其实b.subject = a.subject作用可以理解为分组但未聚合,b.score > a.score相当于给组内排序;此方法适应数据量不大的场景,否则速度会很低
那如果取得是倒数两名同学的成绩呢? 只需要b.score < a.score即可
select * from score a
where 2 > (select count(*) from score b
where b.subject = a.subject
and b.score < a.score
) order by a.subject ,a.score desc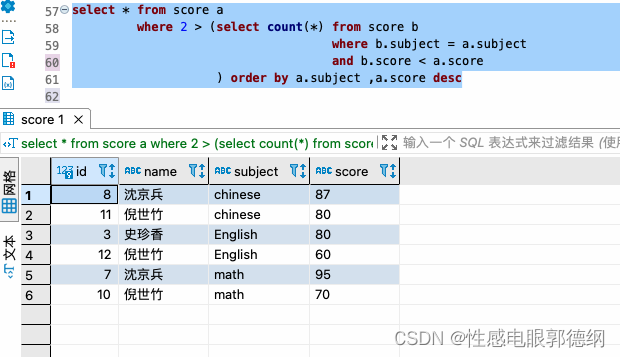
如果是mysql8.0以上可以使用窗口函数 row_number()
select * from (select *
,row_number() over(partition by subject order by score desc) rs
from score) a
where a.rs < 3 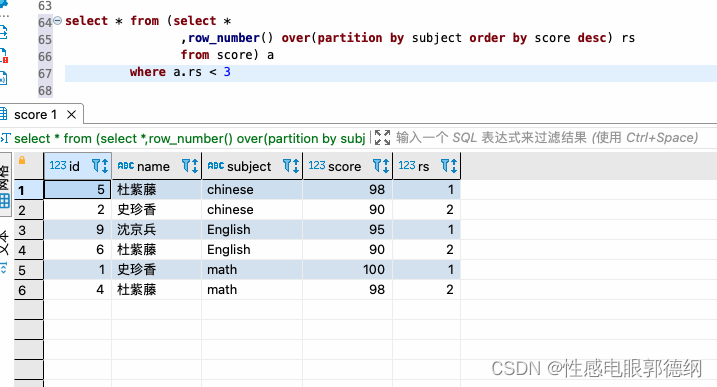
建表语句:
create table score(
id int PRIMARY KEY auto_increment,
name varchar(20) comment '姓名',
subject varchar(20) comment '学科',
score int comment '成绩'
);
insert into score(name, subject, score) values('史珍香','math',100);
insert into score(name, subject, score) values('史珍香','chinese',90);
insert into score(name, subject, score) values('史珍香','English',80);
insert into score(name, subject, score) values('杜紫藤','math',98);
insert into score(name, subject, score) values('杜紫藤','chinese',98);
insert into score(name, subject, score) values('杜紫藤','English',90);
insert into score(name, subject, score) values('沈京兵','math',95);
insert into score(name, subject, score) values('沈京兵','chinese',87);
insert into score(name, subject, score) values('沈京兵','English',95);
insert into score(name, subject, score) values('倪世竹','math',70);
insert into score(name, subject, score) values('倪世竹','chinese',80);
insert into score(name, subject, score) values('倪世竹','English',60);今日分享到此结束啦,希望能帮到各位小伙伴















 2796
2796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









