






研究方向:Image Captioning
论文全名:《Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval》
1. 论文介绍
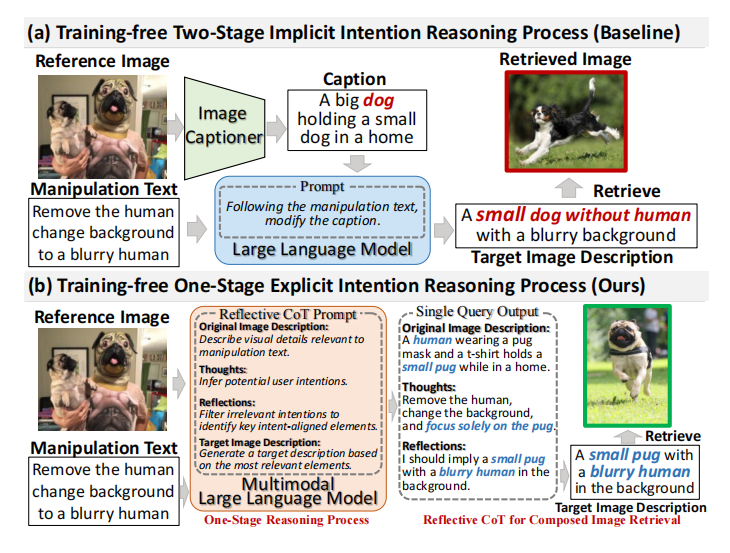
组合图像检索(CIR)旨在检索与参考图像密切相似的目标图像,同时整合用户指定的文本修改,从而更准确地捕捉用户意图。
本文提出了一种新颖的无训练的单阶段方法,用于零样本组合图像检索(ZS-CIR)的单阶段反思思维链推理(OSrCIR),该方法采用多模态大型语言模型来保留必要的视觉信息在单阶段推理过程中进行改进,消除了两阶段方法中的信息丢失。我们的反思思维链框架通过将操纵意图与参考图像的上下文线索对齐来进一步提高解释准确性。
2. 方法介绍
给定一个参考图像 和一个操作文本
,ZS-CIR从图像数据库
中检索出与
在视觉上相似的图像,同时结合
中指定的修改。
我们将目标图像描述作为基于多模态大型语言模型(MLLM)
的组合查询进行推理,为了确保
以人类可理解的方式推理
,我们引入了一个反思思维链提示
。然后使用获得的目标图像描述
通过CLIP进行图像检索,并使用预训练文本编码器
将目标图像描述
和候选图像
嵌入到一个共享的、可搜索的空间中。用余弦相似度计算
匹配分数。
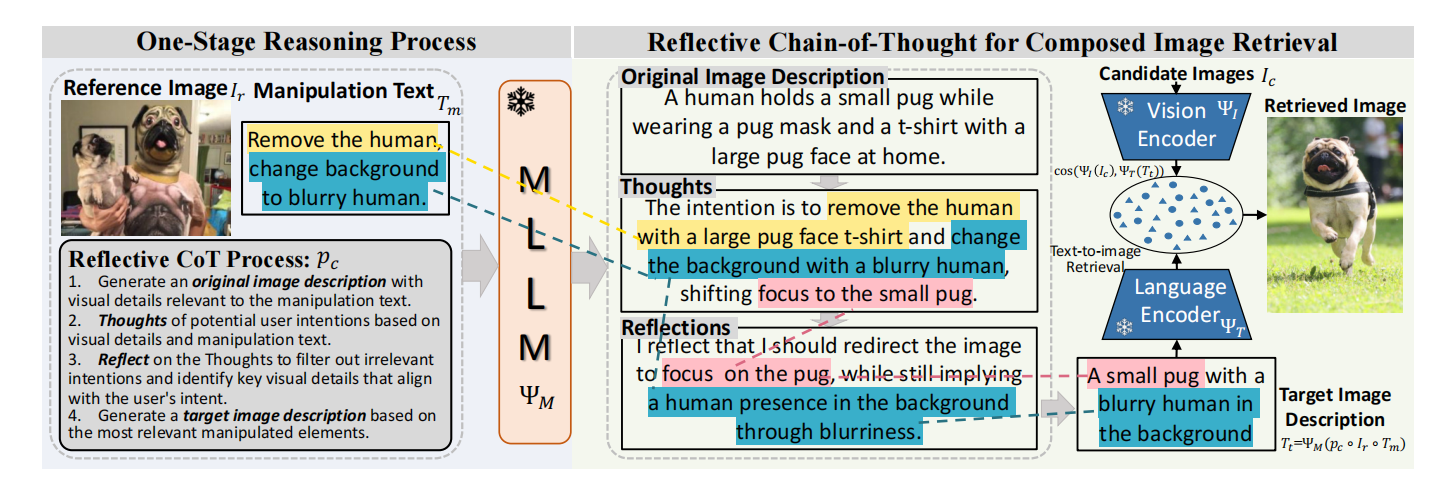
2.1 单阶段推理过程
给定一个多语言语言模型 ,我们按如下方式生成包含用户对参考图像
的操作意图
的目标图像描述
:
2.2 反思思维链用于ZS-CIR
反思CoT提示指导以下逐步推理步骤:
原始图像描述:原始图像描述步骤突出显示参考图像中与用户意图相关的视觉细节。
思考:思维步骤捕捉用户的意图和对可能被操纵的视觉元素的推理。
反思:进一步评估这些元素以识别那些最符合用户意图的内容。
目标图像描述:基于与目标检索最相关的视觉修改生成精炼的描述。
语境中的语言引导视觉学习:单纯为反思性CoT过程提供指导对于大型语言模型理解每一步骤所需的CoT过程是不足够的。我们利用在语境中学习的方法,该方法通过提供一些预期的大型语言模型输出的文本示例,而不需要参考图像,来指导大型语言模型在每个步骤中的推理过程。
组合图像检索:给定目标图像描述 ,我们的模型使用一个冻结的预训练CLIP对图像搜索数据库
和
进行编码。重新检索到的目标图像
确定如下:
其中选定的目标图像是与生成的目标图像描述最相似的一个。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









