







目录
shell概念
-
把整个命令序列按照格式写在一起,可以方便的重复使用的命令序列
-
使用函数可以避免代码重复。
-
函数可以将大的工程分割为若干小的功能模块,可以随时调用。代码的可读性更强。
函数的表达式
定义方法
基本函数定义:
function function_name {
# 函数体
}
或者简化写法:
function_name() {
# 函数体
}
这是定义最基本的Shell函数的方式。
带参数的函数:
function_name() {
# 使用$1, $2, ...来引用参数
local var1=$1
local var2=$2
# 函数体
}
可以在函数内部使用$1、$2等来引用传递给函数的参数。
带返回值的函数:
function_name() {
# 函数体
echo "Some result"
}
要获取函数的返回值,可以使用$(function_name)来捕获函数的输出。
函数调用:
result=$(function_name arg1 arg2)
这是如何调用一个函数,并将其返回值存储在变量中的方式。
匿名函数: 在一些Shell环境中,可以使用匿名函数,如:
() {
# 匿名函数体
}
返回值
函数可以通过不同的方式返回值。以下是一些常见的返回值方式:
使用 return 语句: 通过在函数内部使用 return 语句,可以显式地指定函数的返回值。示例如下:
function get_result() {
local result="This is the result"
return "$result"
}
在调用函数后,可以通过 $? 来获取函数的返回值:
get_result
returned_value=$?
echo "Returned value: $returned_value"
使用 echo 或 printf 输出: 函数可以使用 echo 或 printf 来输出结果,然后在函数调用时捕获这些输出,如下所示:
function get_result() {
local result="This is the result"
echo "$result"
}
在函数调用时,可以将输出捕获到一个变量中:
returned_value=$(get_result)
echo "Returned value: $returned_value"
或者直接将输出赋给一个变量:
result_variable=$(get_result)
echo "Result: $result_variable"
使用全局变量: 函数可以在全局范围内设置一个变量,然后在函数外部访问这个变量,以获取返回值。示例如下:
result=""
function get_result() {
result="This is the result"
}
get_result
echo "Returned value: $result"
传参
通过位置参数传递参数:
通过位置参数传递参数是最常见的方式。在函数内部,你可以使用 $1、$2、$3 等来获取传递给函数的参数,分别表示第一个、第二个、第三个参数,以此类推。
my_function() {
echo "第一个参数是 $1"
echo "第二个参数是 $2"
}
my_function arg1 arg2
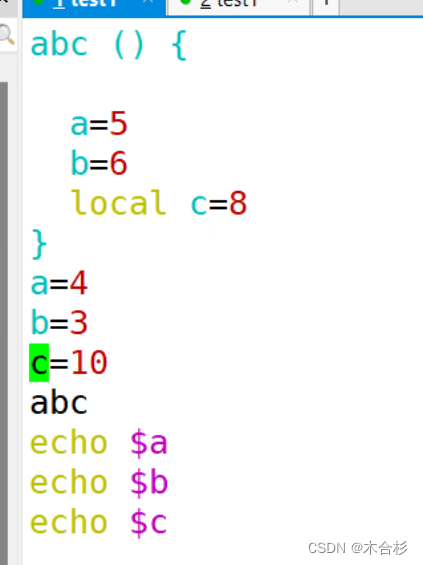
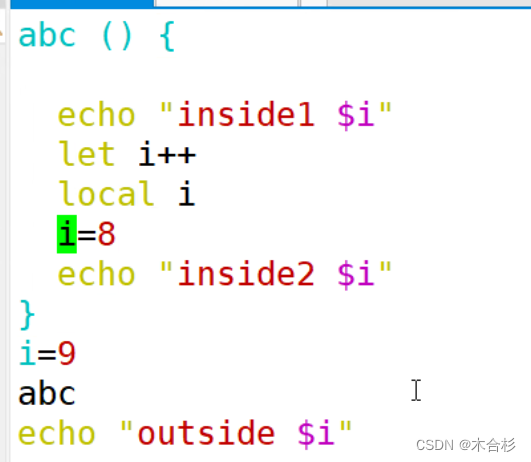
只有全局变量才能被外部使用,内部的变量只限于函数内部,外部是不能引用内部的变量参数。
递归
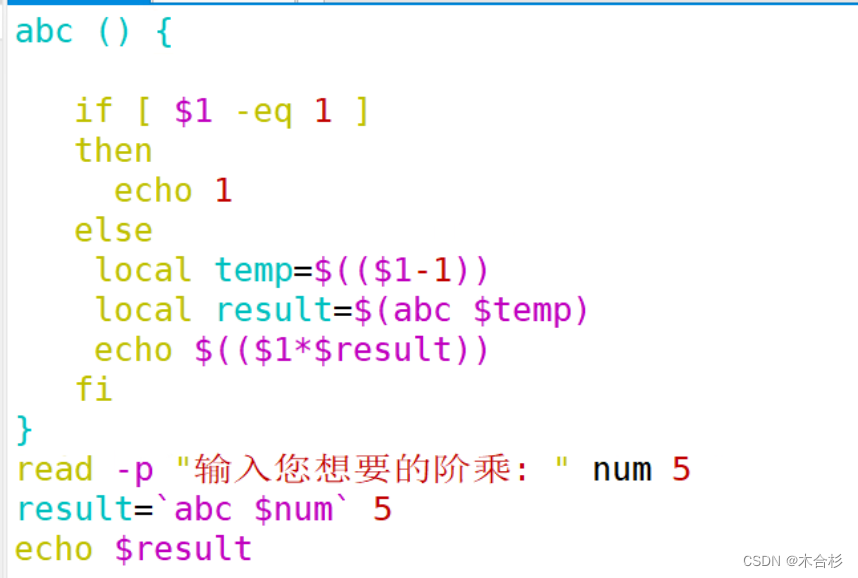
使用递归来实现某个任务或操作的重复执行,直到满足某个条件为止。递归是指函数在执行过程中调用自身的过程。

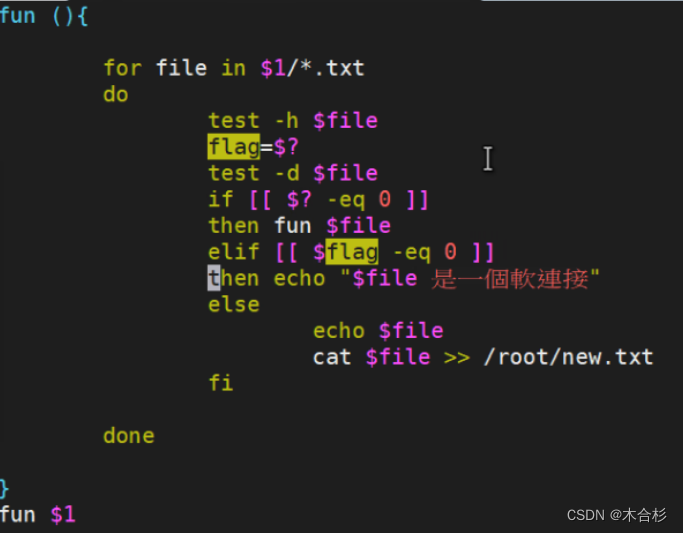
函数库
-
为什么要定义函数库: 函数库的主要目的是避免代码的重复编写。当你有一段经常使用的代码块时,将其封装成函数,并保存在一个库文件中,然后在需要的脚本中引用这个函数库,以便在不必重复编写相同代码的情况下重复使用它。
-
引用函数库: 在一个脚本中需要引用函数库时,可以使用点号
.或source命令将函数库文件引入。例如:
. /path/to/your-library-file.sh
# 或
source /path/to/your-library-file.sh
-
库文件的后缀: 库文件的后缀可以是任意的,但通常使用
.lib或其他约定俗成的后缀,以便更容易辨认它们是函数库文件。 -
可执行选项: 通常函数库文件没有可执行选项,因为它们包含的是函数定义而不是可直接执行的脚本。
-
库文件的位置: 函数库文件不必和引用它们的脚本放在同一目录中,只需要在脚本中指定函数库文件的路径即可。
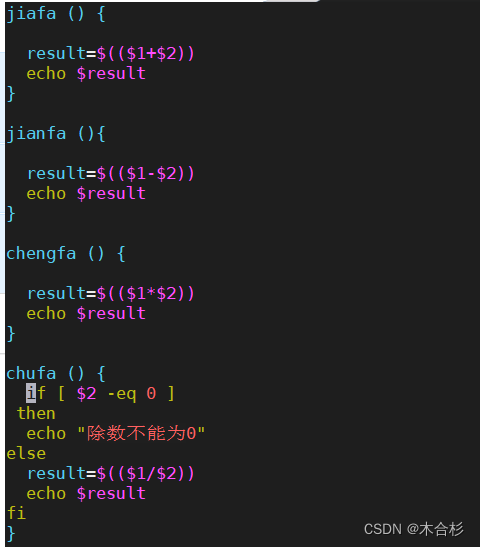
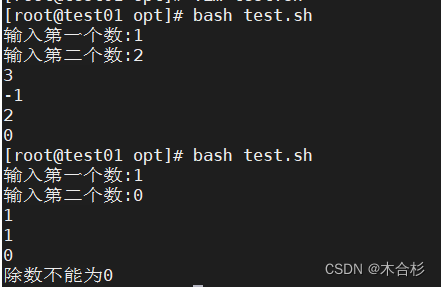
数组
数组概念
-
使用数组来存储一组数据。数组是一种有序的数据集合,可以包含不同类型的元素,如整数、字符串等。
-
可以一次性的多个变量,长度不限
-
数组的元素类型:int string float
定义数组
使用括号 () 来定义数组,其中数组元素之间使用空格来分隔。以下是定义数组的一般形式:
array_name=(element1 element2 element3 ... elementN)
在这个语法中,array_name 是数组的名称,element1, element2, element3, 等等是数组中的元素。你可以根据需要在数组中包含任意数量的元素,这些元素可以是字符串、整数等各种数据类型。
以下是一个示例,演示如何定义一个名为 my_array 的数组:
my_array=(apple banana cherry date)
这将创建一个名为 my_array 的数组,包含了4个元素,分别是 "apple", "banana", "cherry", 和 "date"。
你还可以使用单引号或双引号来定义数组元素,例如:
fruits=('apple' 'banana' 'cherry' 'date')
或者:
colors=("red" "green" "blue" "yellow")
一旦定义了数组,你可以使用下标来访问和操作数组中的元素,如${my_array[0]}表示访问数组 my_array 中的第一个元素。
访问数组
使用数组的名称和下标。下面是如何访问数组元素的方法:
array_name[index]
-
array_name是数组的名称。 -
index是要访问的元素的下标,从0开始。
以下是一些示例:
my_array=("apple" "banana" "cherry" "date")
# 访问第一个元素
first_element="${my_array[0]}"
echo "第一个元素是: $first_element"
# 访问第三个元素
third_element="${my_array[2]}"
echo "第三个元素是: $third_element"
你还可以在循环中使用下标来遍历整个数组,以便访问和处理数组中的每个元素:
my_array=("apple" "banana" "cherry" "date")
# 遍历数组并打印每个元素
for ((i = 0; i < ${#my_array[@]}; i++)); do
echo "元素 $i: ${my_array[i]}"
done
获取数组长度
echo ${#test[*]}
在上述示例中,${#my_array[@]} 用于获取数组的长度,然后使用循环遍历数组中的元素。

数组切片
通过数组切片来获取数组的一部分元素。数组切片允许你选择从数组中的特定下标开始的一系列元素,或者选择数组的一部分来创建一个新数组。下面是如何在Shell中使用数组切片:
${array_name[@]:start_index:length}
-
array_name是数组的名称。 -
start_index是切片的起始下标,从0开始。 -
length是要切片的元素数量。
下面是一些示例:
my_array=("apple" "banana" "cherry" "date" "fig" "grape")
# 从下标2开始,获取3个元素
slice=("${my_array[@]:2:3}")
echo "切片数组: ${slice[@]}"
在这个示例中,${my_array[@]:2:3} 获取了从下标2开始的3个元素,即 "cherry", "date", 和 "fig"。
你还可以选择切片数组的一部分并将其存储在一个新数组中,如下所示:
my_array=("apple" "banana" "cherry" "date" "fig" "grape")
# 从下标1开始,获取前3个元素,存储在新数组中
new_array=("${my_array[@]:1:3}")
echo "新数组: ${new_array[@]}"
这将创建一个新数组 new_array 包含 "banana", "cherry", 和 "date" 这3个元素。
请注意,切片操作是基于数组的下标进行的,因此请确保数组中有足够的元素来执行所需的切片操作,否则可能会导致越界错误。
数组替换
使用下标来替换数组中的元素。要替换数组中的特定元素,可以使用以下语法:
array_name[index]="new_value"
-
array_name是数组的名称。 -
index是要替换的元素的下标,从0开始。 -
"new_value"是要替换的新值。
以下是一个示例,演示如何替换数组中的元素:
my_array=("apple" "banana" "cherry" "date")
# 替换第二个元素
my_array[1]="grape"
# 打印更新后的数组
echo "更新后的数组: ${my_array[@]}"
在这个示例中,我们将数组 my_array 中的第二个元素 "banana" 替换为 "grape"。
你还可以在循环中使用循环变量和下标来迭代数组,并根据需要替换元素。例如:
my_array=("apple" "banana" "cherry" "date")
# 遍历数组并替换特定元素
for ((i = 0; i < ${#my_array[@]}; i++)); do
if [ "${my_array[i]}" == "cherry" ]; then
my_array[i]="kiwi"
fi
done
# 打印更新后的数组
echo "更新后的数组: ${my_array[@]}"
在这个示例中,我们遍历数组并查找特定元素 "cherry",然后将其替换为 "kiwi"。
[root@loaclhost shuzu1]#arr1=(${arr1[*]/4/66}) #如果想要永久替换的话,可通过重新赋值实现
[root@loaclhost shuzu1]#echo ${arr1[*]}
1 2 3 66 5
数组删除
使用 unset 命令来删除数组中的特定元素。以下是如何删除数组中的元素的方法:
unset array_name[index]
-
array_name是数组的名称。 -
index是要删除的元素的下标,从0开始。
以下是一个示例,演示如何删除数组中的元素:
my_array=("apple" "banana" "cherry" "date")
# 删除第二个元素
unset my_array[1]
# 打印更新后的数组
echo "更新后的数组: ${my_array[@]}"
在这个示例中,我们使用 unset 命令删除了数组 my_array 中的第二个元素 "banana"。删除后的数组将只包含 "apple", "cherry", 和 "date" 这三个元素。
请注意,删除元素后,数组中会出现空的位置,即被删除的元素所在的位置将保持为空。如果你想要删除后重新排列数组,可以在删除元素后执行数组重新排序的操作。
另外,还可以使用数组切片来创建一个新数组,其中排除了要删除的元素。这样可以更有效地删除元素并生成一个新的数组。例如:
my_array=("apple" "banana" "cherry" "date")
# 创建一个新数组,排除第二个元素
new_array=("${my_array[@]:0:1}" "${my_array[@]:2}")
# 打印新数组
echo "新数组: ${new_array[@]}"
在这个示例中,我们创建了一个新数组 new_array,其中排除了第二个元素 "banana"。这样你可以维护一个新的数组,而不是修改原始数组。
数组追加
使用不同的方法来向数组追加元素。以下是一些常见的方法:
- 直接给数组指定索引赋值:
myArray[0]="元素1"
myArray[1]="元素2"
这种方法将元素直接赋值给数组的指定索引位置。
- 使用
+=操作符来追加元素:
myArray+=("新元素")
这将在数组的末尾追加新元素。
- 使用数组展开操作:
myArray=("${myArray[@]}" "新元素")
这种方法将原数组的所有元素展开为独立的单元,然后添加新元素。
- 使用
array[index]的方式:
myArray[${#myArray[@]}]="新元素"
这将使用数组的长度作为新元素的索引,从而实现追加。
下面是一个完整的示例,演示如何向Shell数组追加元素:
# 定义一个空数组
myArray=()
# 添加元素
myArray[0]="元素1"
myArray[1]="元素2"
# 追加元素
myArray+=("新元素")
# 使用数组展开操作追加元素
myArray=("${myArray[@]}" "另一个新元素")
# 使用数组长度追加元素
myArray[${#myArray[@]}]="最后一个新元素"
# 打印数组
echo "数组元素:${myArray[@]}"
上述方法可以帮助你在Shell脚本中实现向数组追加元素的功能。


seq
通常用于生成数字序列。它的主要作用是生成一系列整数,以便在Shell脚本中进行循环或者其他数值操作。下面是一些常见用法和示例:
生成从1到N的数字序列:
seq N
例如,要生成从1到10的数字序列:
seq 10
生成从M到N的数字序列:
seq M N
例如,要生成从3到8的数字序列:
seq 3 8
指定步长(步进值):
seq -s STEP M N
例如,要生成从1到10的数字序列,步长为2:
seq -s 2 1 10
逆序生成数字序列:
seq -s STEP -w N M
例如,要逆序生成从10到1的数字序列:
seq -s -1 -w 10 1
在上述示例中,-s 用于指定步长,-w 用于指定输出的数字是否带有前导零。你可以根据需要自定义参数来生成不同范围和步长的数字序列。
"seq" 命令在Shell脚本中常用于迭代循环和生成一系列数字,以便进行重复操作。
排序
冒泡排序
冒泡排序是一种最基本的交换排序法 之所以叫冒泡, 是因为每一个元素都可以像小气泡一样, 根据自身大小一点一点的向数组的一侧移动
原理
每一次冒泡只能确定一个数, 将数组的一个数归位 第一次确定末尾的数字, 第二次确定倒数第二位…第n 1次确定第二个位置 剩下的只能处于第一位 每一轮的处理规则(以升序为例) 从第一个下标开始,也就是0, 比较第一个与第二个元素的大小 如果第一个元素比第二个元素大,则交换两者位置 然后比较第二个元素与第三个元素的大小, 如果第二个比第三个大,则交换 此时确保大的数值一直在向右侧移动 以此类推, 一直进行比较与交换,直到确定最后一个位置的值,此时的值一定是最大值


















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









