









大数据基础day1
HDFS(Hadoop分布式文件系统)
一种旨在在商品硬件上运行的分布式文件系统
- HDFS具有高度的容错能力,旨在部署在低成本硬件上。
- HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序
- HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。
- HDFS最初是作为Apache Nutch Web搜索引擎项目的基础结构而构建的。
- HDFS是Apache Hadoop Core项目的一部分。
字典与文件系统
文件系统定义
文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易。
文件名
在文件系统中,文件名是用于定位存储位置。
元数据(Metadata)
保存文件属性的数据,如文件名,文件长度,文件所属用户组,文件存储位置等。
数据块(Block)
存储文件的最小单元。对存储介质划分了固定的区域,使用时按这些区域分配使用。
HDFS架构包含三个部分
- Client:支持业务访问HDFS,从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行
- NameNode:用于存储、生成文件系统的元数据。运行一个实例
- DataNode:DataNode用于存储实际的数据,将自己管理的数据块上报给NameNode ,运行多个实例
HDFS写数据流程(确保一致性)
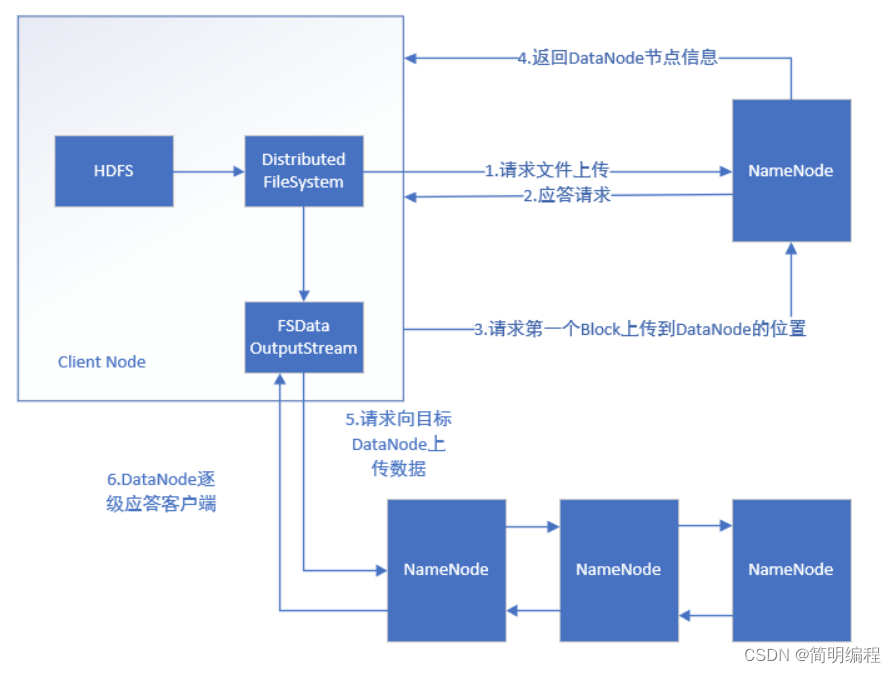
1.提出申请 -2.创建元数据 -3.数据拆分 -4.数据写入(第一个节点写入 其他节点复制)-5.ack检查包 -6.关闭接口 -7.元数据固化
HDFS读数据(确保效率性)
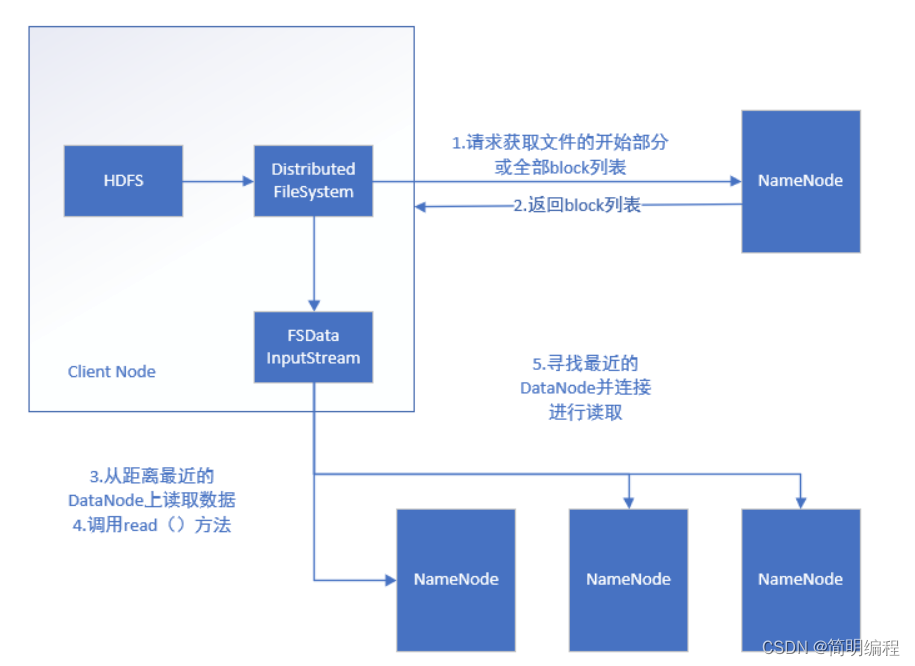
1.提出申请 -2.查找元数据-3读取 (就近原则)- 4.关掉
HDFS(高可用)HA
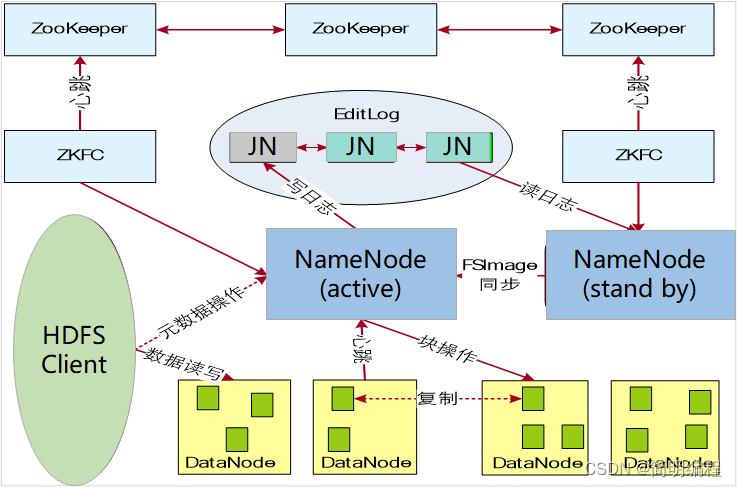
利用ZooKeeper实现主备NameNode(解决单点故障问题)
Zookeeper主要用于存储HA下状态文件
双NameNode 保证同一时间总有一个节点正常工作
ZKFC(ZooKeeper Failover Controller)用于监控NameNode节点的主备状态 通过心跳机制 向上层报告自己的状态每3s 发送一条消息(共12条消息)
元数据 持久化:通过快照和日志文件
联邦机制:并行设立多个NameNode节点
副本机制:3副本保证数据安全
同分布 :减少无效的io操作
HBase
hbase是采用java语言编写的一款开源的基于HDFS的 nosql型数据库,不支持SQL.没有表关系,数据最终是存储在HDFS上,在启动hbase集群之前,必须要先启动HDFS
存储模式:列存储
不支持事务,仅支持单行事务
易于扩展
三种读取数据的方式
- 基于rowkey(行键)的读取
- 基于rowkey的range范围的读取
- 扫描全表数据
HBase的表的三个特征
- 储量大:一个表可存储上十亿行数据,拥有上百万列
- 面向列:基于列族管理操作,进行列式存储方案
- 稀疏性:对于NULL值的数据不占用任何磁盘空间,对效率没有任何影响表关系松散
HBase架构
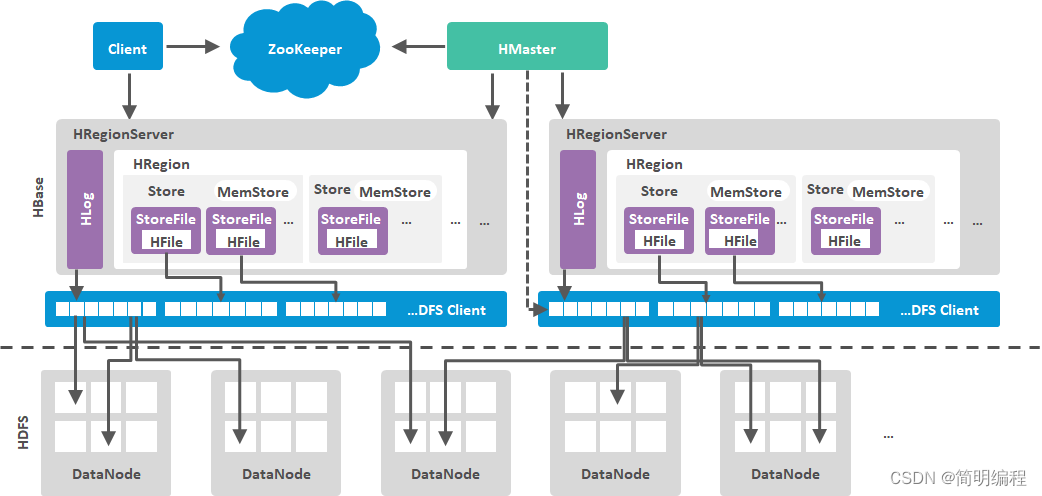
HBase读取数据的流程
- 客户端提出申请
- 查找数据存放的位置 (在哪个region中)
- 调用get scan 对region进行扫描
HBase写入数据的流程
- 提出申请
- 明确分区(生成元数据表)
- 将数据分配到HRegionServer
- 先写日志 hlog 然后再写region
- 固化到hdfs
mapreduce
map --生成键值对
reduce – 做聚合操作
洗牌机制 – 小范围的聚合 数据节点之间的聚合















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









