









我们要研究什么事情?
预测飞机坐标。
用什么来预测——ADS-B+深度学习
飞机坐标预测是通过ADS-B接收机类型、经纬度、信号接收时间、接收信号强度等来预测飞机当前所处的经纬度的过程。也就是飞机把信号传输到接收机,接收机来跟据收到的信号进行整合与预测,这里与要注意接收机有很多台,本文的数据集来自于OpenSky网络真实的ADS-B数据。
OpenSky网络是什么?
OpenSky网络系统如图1所示。这些数据包括数千台地面ADS-B接收机在一定时间内接收到的ADS-B消息、信号到达时间和信号强度以及各自的接收范围。这些地面接收器由由个人、政府和研究机构组成的志愿者部署,接收到的数据不断上传到OpenSky网络服务器进行汇总。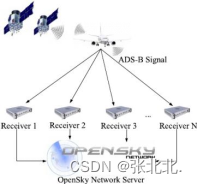
安全:一个重要的问题
ADS-B系统通常是可靠的。然而,在飞机发生故障甚至劫持的情况下,依靠传统的ADS-B系统给出的定位来救援飞机是不明智的。由于ADS-B报文在飞机故障前可能已被篡改,ADS-B报文的具体数据所获得的定位可能是错误定位。且就算是没用被篡改,也会存在信号传输时间差的问题。
怎样安全——用安全的数据
相关实验表明,飞机离接收机越近,信号越强。所以可以利用强度把以下变量与飞机位置联系起来。
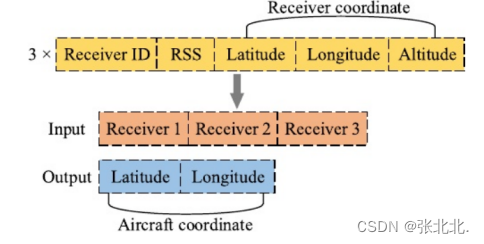
输入的安全数据类型如下图:3个接收机(从接收信号的接收机中选择3个优先级最高的接收机作为输入数据集),每个接收机收到的信号强度(强度不容易被篡改),接收机的位置:包括经度、维度与高度(那么多接收机,总不可能位置都被移动了),即每个接收机5个特征,总共3个接收机,输入特征为3*5=15。
特别的如果某一时刻接收到报告的接收器数量小于3个,则输入数据集将0补充到15个feature。
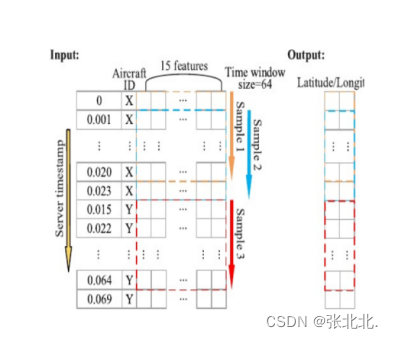
飞机位置与时间相关,且为连续的变量,如何充分利用时间维度的特征——增加采样窗口
为了充分利用数据集的时间维度特征,需要将数据集按连续时间点切片。为了保证切片后每个样本中的时间点是连续的,切片前先按飞机ID对ADS-B消息数据集进行排序,再按服务器的时间戳对每个飞机的数据进行排序。下图的“输入”部分是两种安排的结果。
还需要对样本数据集进行随机洗选,这样可以增加样本的随机性,防止训练过程中模型的抖动,防止过拟合。如下图
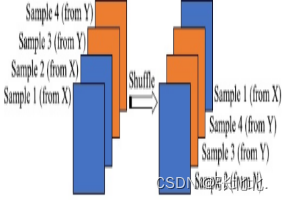
如此我们不难发现,单一时间点对应的输入数据由原来的(1,15)变成了(64,15).很不错!
代码如下:
训练集:
[n,m]=size(x_train_norm);
height=64;%连续时间点采样步长,根据需求可变
width=15;%单一时间点输入特征个数
index_3d=1;
i=1;
while i <= n%第一次遍历,确定根据当前矩阵x_train_norm能制作出多少个二维样本
if i+height-1 > n
break;
end
%保证采样窗里只有单个航班的信息
if x_train_norm(i,1) == x_train_norm(i+height-1,1)
index_3d=index_3d+1;
i = i+1;
continue;
end
%若采样窗里不是单个航班,则将窗口跳跃至下一个航班起始位置
for t = 1:height-1
if x_train_norm(i,1) ~= x_train_norm(i+t,1)
i=i+t;
break;
end
end
end
fprintf('total %d \n',index_3d-1);
%提前开辟空间,加快后续运算速度
x_train=zeros(index_3d-1,height,width);
yla_train=zeros(index_3d-1,height);
ylong_train=zeros(index_3d-1,height);
%(index_3d-1)是能够制作的样本数,生成一个1~(index_3d-1)的整数随机序列,用于实现shuffle操作。
% ps:这段代码是灵魂~~~~
randIndex = randperm(index_3d-1);
randIndex=randIndex.';
index_3d=1;
i=1;
while i <= n%第二次遍历,制作训练集
if(~mod(i,1000))
fprintf('已完成 %d 行转换!\n',i);
end
if i+height-1 > n
break;
end
if x_train_norm(i,1) == x_train_norm(i+height-1,1)
index=randIndex(index_3d);%获取一个随机索引(灵魂~~~~)
% 最终得到训练集输入x_train,和训练集输出yla_train、ylong_train
x_train(index,:,:)=x_train_norm(i:i+height-1,2:2+width-1);
yla_train(index,:)=y_train_norm(i:i+height-1,1);
ylong_train(index,:)=y_train_norm(i:i+height-1,2);
index_3d=index_3d+1;
i = i+1;
continue;
end
for t = 1:height-1
if x_train_norm(i,1) ~= x_train_norm(i+t,1)
i=i+t;
break;
end
end
end
测试集:
[n,m]=size(x_train_norm);
height=64;%连续时间点采样步长,根据需求可变
width=15;%单一时间点输入特征个数
index_3d=1;
i=1;
while i <= n%第一次遍历,确定根据当前矩阵x_train_norm能制作出多少个二维样本
if i+height-1 > n
break;
end
%保证采样窗里只有单个航班的信息
if x_train_norm(i,1) == x_train_norm(i+height-1,1)
index_3d=index_3d+1;
i = i+1;
continue;
end
%若采样窗里不是单个航班,则将窗口跳跃至下一个航班起始位置
for t = 1:height-1
if x_train_norm(i,1) ~= x_train_norm(i+t,1)
i=i+t;
break;
end
end
end
fprintf('total %d \n',index_3d-1);
%提前开辟空间,加快后续运算速度
x_train=zeros(index_3d-1,height,width);
yla_train=zeros(index_3d-1,height);
ylong_train=zeros(index_3d-1,height);
%(index_3d-1)是能够制作的样本数,生成一个1~(index_3d-1)的整数随机序列,用于实现shuffle操作。
% ps:这段代码是灵魂~~~~
randIndex = randperm(index_3d-1);
randIndex=randIndex.';
index_3d=1;
i=1;
count=0;
count_all_test=0;
count_single_test=[];
while i <= n%第二次遍历,制作训练集
if(~mod(i,1000))
fprintf('已完成 %d 行转换!\n',i);
end
if i+height-1 > n
count=i-n-1;
count_single_test=[count_single_test count];
count_all_test=count_all_test+1;
count=0;
break;
end
if x_train_norm(i,1) == x_train_norm(i+height-1,1)
index=index_3d;
x_train(index,:,:)=x_train_norm(i:i+height-1,2:2+width-1);
yla_train(index,:)=y_train_norm(i:i+height-1,1);
ylong_train(index,:)=y_train_norm(i:i+height-1,2);
index_3d=index_3d+1;
i = i+1;
count=count+1;
continue;
end
for t = 1:height-1
if x_train_norm(i,1) ~= x_train_norm(i+t,1)
i=i+t;
if count==0
count=-t;
end
count_single_test=[count_single_test count];
count_all_test=count_all_test+1;
count=0;
break;
end
end
end
但是,也引出了一个新的问题,维度还原
维度还原的实现——多次测量的点取平均
很好理解,这里只给出代码:
%加载制作测试集输入时生成的变量count_all_test和count_single_test
load('count_all_test.mat');%加载航班数
load('count_single_test.mat');%加载每个航班的样本数
yla=zeros(6000000,1);%预分配空间,用于存放降维后的数据
ylong=zeros(6000000,1);
len_y=1;%表示yla\ylong的index
y1=yla_pre.';%yla_pre和ylong_pre即为原始输出的预测坐标
y2=ylong_pre.';%ylong_pre按行排放,转成按列排
y_count=0;%表示y1\y2的index
size=64;%采样窗长度
count=0;%count为当前航班的样本数
for t = 1:count_all_test
fprintf("t=%d\n",t);
count=count_single_test(1,t);%count为当前航班的样本数
temp1=zeros(10000,10000);
temp2=zeros(10000,10000);
y_1=zeros(10000,1);
y_2=zeros(10000,1);%预分配空间,加速
if count<0%小于零表示采样时由于长度小于采样窗长度,没有被采到,所以在恢复时补nan
count=abs(count);
y_=nan(count,1);
yla(len_y:len_y+count-1,1)=y_;
ylong(len_y:len_y+count-1,1)=y_;
len_y=len_y+count;
continue;
end
%将同航班数据分解并排入同一个矩阵,方便求平均
for i = 1:count
temp1(i:i+size-1,i)=y1(:,i+y_count);
temp2(i:i+size-1,i)=y2(:,i+y_count);
end
y_count=y_count+count;
%按行求和
y_1=sum(temp1,2);
y_2=sum(temp2,2);
len=count+size-1;
%按行求平均
for i = 1:len
if i<size
y_1(i,1)=y_1(i,1)/i;
y_2(i,1)=y_2(i,1)/i;
%如果觉得前段和后段预测重复次数太少,可以选择抛弃数据
% y_1(i,1)=nan;
% y_2(i,1)=nan;
elseif i>len-size+1
y_1(i,1)=y_1(i,1)/(len-i+1);
y_2(i,1)=y_2(i,1)/(len-i+1);
% y_1(i,1)=nan;
% y_2(i,1)=nan;
else
%对重复预测次数最多的中间段取平均
y_1(i,1)=y_1(i,1)/size;
y_2(i,1)=y_2(i,1)/size;
end
end
yla(len_y:len_y+len-1,1)=y_1(1:len,1);
ylong(len_y:len_y+len-1,1)=y_2(1:len,1);
len_y=len_y+len;
end
提出的N-Inception-LSTM模型
将Inception和LSTM结合,灵感来源于CNN-LSTM网络,能够同时提取数据集中的空间和时间信息,而将普通的CNN换成Inception模块,能够增加网络的尺度适应性
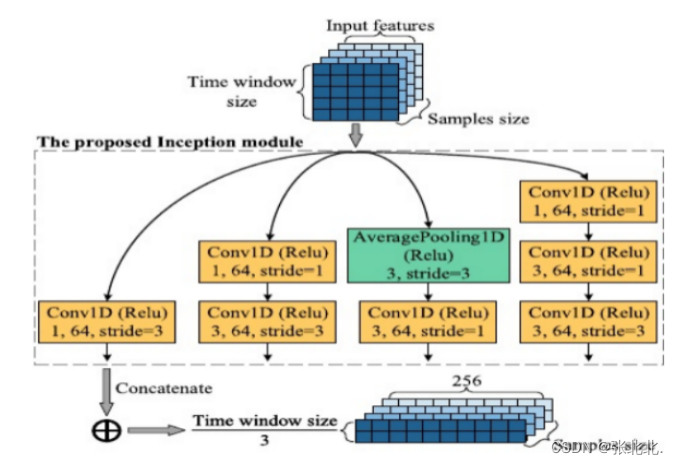
提出的N-Inception-LSTM模型的Inception部分使用了Inception- V2模块作为参考。图11显示了一个新的Inception模块,它是为本文中特定的样本集设计的。它的每一部分都是一维运算。特别是当这个数字在数以千万计的样本中,该设计显著提高了网络对不同尺度的适应性和计算效率。提出的N-Inception-LSTM模型由多个Inception模块和LSTM模块组成。
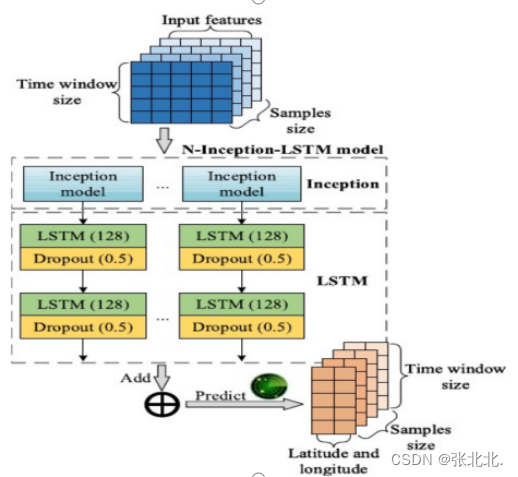
定义N-Inception-LSTM模型,如上图所示。
1.一个N-Inception-LSTM模型由N个并行的Inception-LSTM模型组成。
2.每个Inception-LSTM模型由一个Inception模型和两个LSTM模块组成。
3.Inception模型:4个定义的inception模块
4.LSTM模型:每个LSTM有128个操作单元,后面有一个参数为0.5的Dropout层防止过度拟合。
N-Inception- LSTM模型的输入和输出分别是算法1产生的输入和输出样本集。并行N- Inception-LSTM模型的目的是增加整个模型的宽度,拓宽感知范围。
通过改变N来观察不同数量的并行模型对最终预测结果的影响,最终发现n=2为局部最优模型
参考文献
https://blog.csdn.net/qq_39291503/article/details/117673374
https://blog.csdn.net/qq_39291503/article/details/117742694
https://blog.csdn.net/qq_39291503/article/details/117841988?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-117841988-blog-117742694.235%5Ev29%5Epc_relevant_default_base3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-117841988-blog-117742694.235%5Ev29%5Epc_relevant_default_base3&utm_relevant_index=5
Y. Chen, J. Sun, Y. Lin, G. Gui and H. Sari, “Hybrid n-Inception-LSTM-based aircraft coordinate prediction method for secure air traffic,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 3, pp. 2773-2783, Mar. 2022, doi: 10.1109/TITS.2021.3095129.(Impact factors: 9.6)
**
文章给出的代码不完全且是远古的tensorflow版本,这里用pytorch进行model部分的复写
**
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.branch_a10 = nn.Sequential(
nn.Conv1d(15, 64, kernel_size=1, stride=3, padding=1),#变窗口改64 所有都改
nn.ReLU()
)
self.branch_b10 = nn.Sequential(
nn.Conv1d(15, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c10 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=3, padding=1),
nn.Conv1d(15, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d10 = nn.Sequential(
nn.Conv1d(15, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
# 定义20四个分支
self.branch_a20 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=3, padding=0),#变窗口256为n*4 所有都改
nn.ReLU()
)
self.branch_b20 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=0),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c20 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=3, padding=1),
nn.Conv1d(256, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d20 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=0),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_a30 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=3, padding=1),
nn.ReLU()
)
self.branch_b30 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c30 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=2, padding=1),
nn.Conv1d(256, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d30 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_a40 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=3, padding=1),
nn.ReLU()
)
self.branch_b40 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c40 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=3, padding=1),
nn.Conv1d(256, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d40 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
# y50
self.lstm1 = nn.LSTM(input_size=256, hidden_size=128, num_layers=1, batch_first=True)
self.dropout1 = nn.Dropout(p=0.5)
self.lstm2 = nn.LSTM(input_size=128, hidden_size=128, num_layers=1, batch_first=True)
self.dropout2 = nn.Dropout(p=0.5)
self.branch_a11 = nn.Sequential(
nn.Conv1d(15, 64, kernel_size=1, stride=3, padding=1),
nn.ReLU()
)
self.branch_b11 = nn.Sequential(
nn.Conv1d(15, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c11 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=3, padding=1),
nn.Conv1d(15, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d11 = nn.Sequential(
nn.Conv1d(15, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
# 定义20四个分支
self.branch_a21 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=3, padding=0),
nn.ReLU()
)
self.branch_b21 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=0),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c21 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=3, padding=1),
nn.Conv1d(256, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d21 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=0),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_a31 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=3, padding=1),
nn.ReLU()
)
self.branch_b31 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c31 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=2, padding=1),
nn.Conv1d(256, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d31 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_a41 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=3, padding=1),
nn.ReLU()
)
self.branch_b41 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
self.branch_c41 = nn.Sequential(
nn.AvgPool1d(kernel_size=3, stride=3, padding=1),
nn.Conv1d(256, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.branch_d41 = nn.Sequential(
nn.Conv1d(256, 64, kernel_size=1, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv1d(64, 64, kernel_size=3, stride=3, padding=1),
nn.ReLU()
)
# y51
self.lstm11 = nn.LSTM(input_size=256, hidden_size=128, num_layers=1, batch_first=True)
self.dropout11 = nn.Dropout(p=0.5)
self.lstm21 = nn.LSTM(input_size=128, hidden_size=128, num_layers=1, batch_first=True)
self.dropout21 = nn.Dropout(p=0.5)
self.dense = nn.Linear(in_features=128, out_features=64)
def forward(self, x):
# 分别通过4个分支
out_a10 = self.branch_a10(x)
out_b10 = self.branch_b10(x)
out_c10 = self.branch_c10(x)
out_d10 = self.branch_d10(x)
y10 = torch.cat((out_a10, out_b10, out_c10, out_d10), dim=1)
out_a20 = self.branch_a20(y10)
out_b20 = self.branch_b20(y10)
out_c20 = self.branch_c20(y10)
out_d20 = self.branch_d20(y10)
y20 = torch.cat((out_a20, out_b20, out_c20, out_d20), dim=1)
# 将4个分支的输出合并起来
out_a30 = self.branch_a30(y20)
out_b30 = self.branch_b30(y20)
out_c30 = self.branch_c30(y20)
out_d30 = self.branch_d30(y20)
y30 = torch.cat((out_a30, out_b30, out_c30, out_d30), dim=1)
out_a40 = self.branch_a40(y30)
out_b40 = self.branch_b40(y30)
out_c40 = self.branch_c40(y30)
out_d40 = self.branch_d40(y30)
y40 = torch.cat((out_a40, out_b40, out_c40, out_d40), dim=1).permute(0, 2, 1)#y50便于lstm的后续数据输入
y50, _ = self.lstm1(y40)
y50 = self.dropout1(y50)
y50, _ = self.lstm2(y50)
y50 = self.dropout2(y50)#丢弃一些东西,防止过拟合
out_a11 = self.branch_a10(x)
out_b11 = self.branch_b10(x)
out_c11 = self.branch_c10(x)
out_d11 = self.branch_d10(x)
y11 = torch.cat((out_a11, out_b11, out_c11, out_d11), dim=1)
out_a21 = self.branch_a20(y11)
out_b21 = self.branch_b20(y11)
out_c21 = self.branch_c20(y11)
out_d21 = self.branch_d20(y11)
y21 = torch.cat((out_a21, out_b21, out_c21, out_d21), dim=1)
# 将4个分支的输出合并起来
out_a31 = self.branch_a30(y21)
out_b31 = self.branch_b30(y21)
out_c31 = self.branch_c30(y21)
out_d31 = self.branch_d30(y21)
y31 = torch.cat((out_a31, out_b31, out_c31, out_d31), dim=1)
out_a41 = self.branch_a40(y31)
out_b41 = self.branch_b40(y31)
out_c41 = self.branch_c40(y31)
out_d41 = self.branch_d40(y31)
y41 = torch.cat((out_a41, out_b41, out_c41, out_d41), dim=1).permute(0, 2, 1)
y51, _ = self.lstm11(y41)
y51 = self.dropout11(y51)
y51, _ = self.lstm21(y51)
y51 = self.dropout21(y51)
out = y50 + y51
out = self.dense(out)
return out
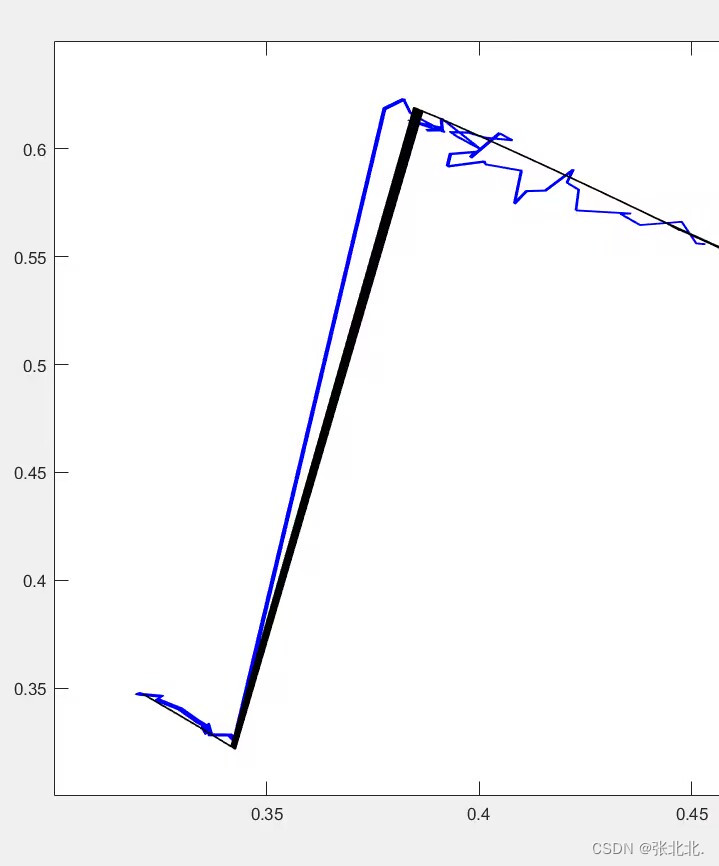
最后给出一张效果图














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









