






在图像分类通用步骤中,第一步是训练数据集,第二步是测试数据集,而无论是训练还是测试,对我们而言都是黑盒子。我们只知道模型从训练数据中学习到了特征,然后应用到测试集数据集中,最终得出测试集数据的分类结果。对于其中的细节,我们就不得而知了。因此本文将在训练好模型的基础上,在测试集进行数据降维可视化,观察模型将不同数据划分到什么位置,有助于我们理解模型在面对图像是进行了怎样的判断。来源:同济子豪兄
本文在原代码的数据上,实现了复现。使用的网络是VGG16,使用的测试数据是ImageNet随机抽取100个类别。代码是在jupyter notebook上运行的。
载入训练好的模型,对测试集图像进行分类
import os
from tqdm import tqdm
import numpy as np
import pandas as pd
import cv2
from PIL import Image
from model12_BNsigdctest2 import vgg
import torch
import torch.nn.functional as F
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)数据预处理,采用ImageNet的预处理方式
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])载入数据:1是载入测试的数据集,方法和训练数据集的载入方式一样;2是载入类别索引标签
# 数据集文件夹路径
dataset_dir = 'E:\imageN2012'
test_path = os.path.join(dataset_dir, 'val')
from torchvision import datasets
# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)
print('测试集图像数量', len(test_dataset))
print('类别个数', len(test_dataset.classes))
print('各类别名称', test_dataset.classes)
# 载入类别名称 和 ID索引号 的映射字典
# 获得类别名称
json_path = './class_indices100s.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
classes = json.load(f)
print(classes[str(0)])导入模型:模型怎么写的,就怎么载入权重
model=vgg("vgg16",num_classes=100,num=1)
m1="sigdctestimg10_1_s"
weight_path = "./vgg16_12_BN{}_best.pth".format(m1)
model.load_state_dict(torch.load(weight_path, map_location=device))
model = model.eval().to(device)创建存储表格1:
df = pd.DataFrame()
df['图像路径'] = img_paths
df['标注类别ID'] = test_dataset.targets
df['标注类别名称'] = [paths.split('\\')[3] for paths in img_paths]创建记录表格2:记录各图像的分类和置信度
n=3
df_pred = pd.DataFrame()
for idx, row in tqdm(df.iterrows()):
img_path = row['图像路径']
img_pil = Image.open(img_path).convert('RGB')
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
pred_logits = model(input_img) # 执行前向预测,得到所有类别的 logit 预测分数
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
pred_dict = {}
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
# top-n 预测结果
for i in range(1, n+1):
pred_dict['top-{}-预测ID'.format(i)] = pred_ids[i-1]
pred_dict['top-{}-预测名称'.format(i)] = classes[str(pred_ids[i-1])]
pred_dict['top-n预测正确'] = row['标注类别ID'] in pred_ids
# 每个类别的预测置信度
for idx, each in enumerate(classes):
pred_dict['{}-预测置信度'.format(each)] = pred_softmax[0][idx].cpu().detach().numpy()
df_pred = df_pred.append(pred_dict, ignore_index=True)处理完成后会得到如下表格:
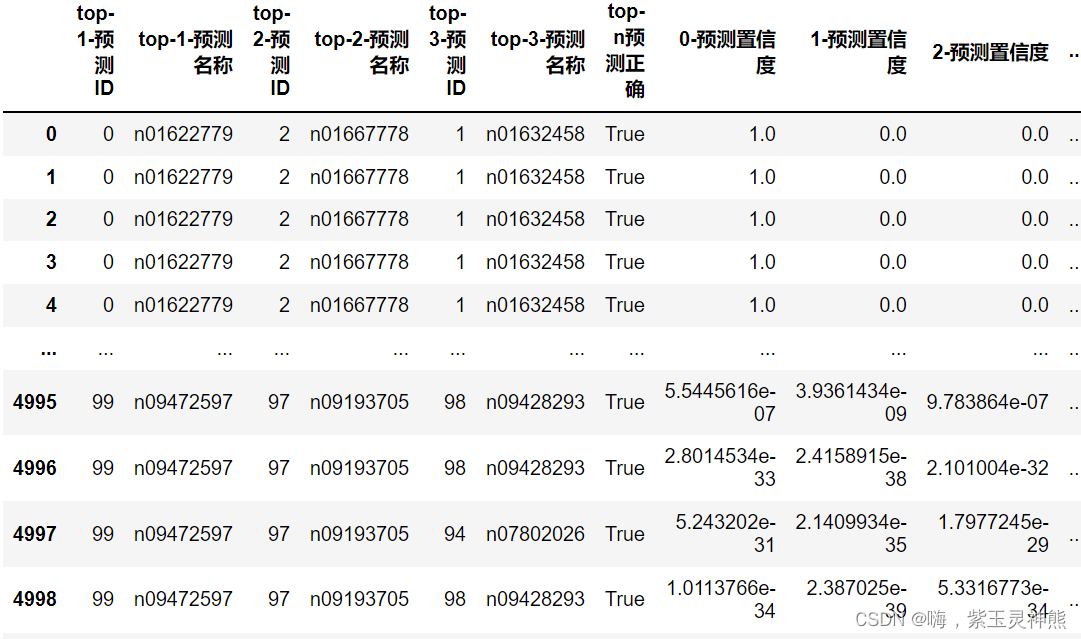
拼接表格1和表格2:
df = pd.concat([df, df_pred], axis=1)结果如下:
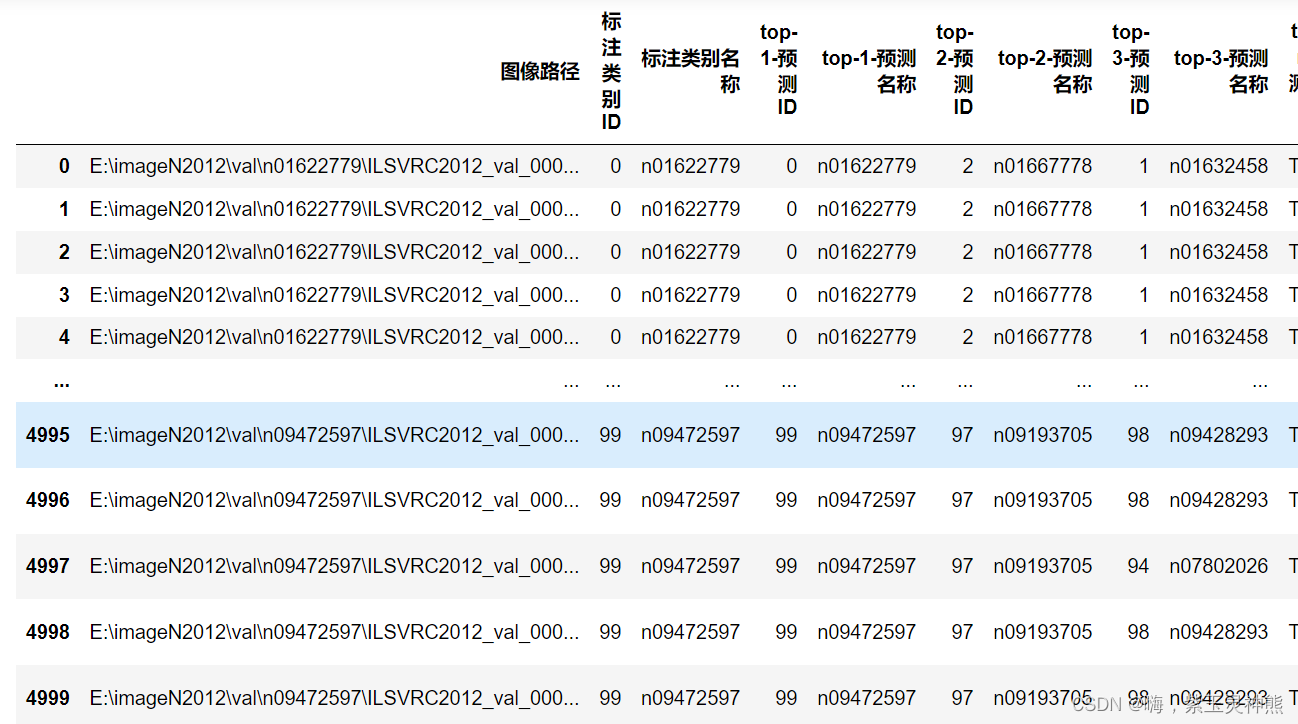
保存完整表格:
df.to_csv('测试集预测结果.csv', index=False)计算图像的语义特征:
从载入的模型中抽取中间层的输出作为图像的语义特征:
我的模型定义如下:



我的模型最后是全连接层,所以抽取第二个全连接层的输出作为图像的语义特征。
from torchvision.models.feature_extraction import create_feature_extractor
model_trunc = create_feature_extractor(model, return_nodes={'classifier.4': 'semantic_feature'})载入图像分类结果,以获取图像和图像路径、名称等信息:
df = pd.read_csv('测试集预测结果.csv')计算每张图像的语义特征并存储:
encoding_array = []
img_path_list = []
for img_path in tqdm(df['图像路径']):
img_path_list.append(img_path)
img_pil = Image.open(img_path).convert('RGB')
input_img = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
feature = model_trunc(input_img)['semantic_feature'].squeeze().detach().cpu().numpy() # 执行前向预测,得到 avgpool 层输出的语义特征
encoding_array.append(feature)
encoding_array = np.array(encoding_array)结果如下:最终得到5000个,4096维度的语义特征,即每张图像的语义特征使用一个4096维度的特征来表示。5000是图像的数量。

保存结果:
np.save('测试集语义特征.npy', encoding_array)使用t_SNE方法对数据降维可视化
载入语义特征:
encoding_array = np.load('测试集语义特征.npy', allow_pickle=True)载入图像分类结果,类别名称:
df = pd.read_csv('测试集预测结果.csv')
classes = df['标注类别名称'].unique()可视化配置:
import seaborn as sns
marker_list = ['.', ',', 'o', 'v', '^', '<', '>', '1', '2', '3', '4', '8', 's', 'p', 'P', '*', 'h', 'H', '+', 'x', 'X', 'D', 'd', '|', '_', 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
class_list = np.unique(df['标注类别名称'])
n_class = len(class_list) # 测试集标签类别数
palette = sns.hls_palette(n_class) # 配色方案
sns.palplot(palette)
# 随机打乱颜色列表和点型列表
import random
random.seed(1234)
random.shuffle(marker_list)
random.shuffle(palette)t_SNE将至二维:
1 t-SNE 算法概述
全称为 t-distributed Stochastic Neighbor Embedding,翻译为 t分布-随机邻近嵌入。
怎么理解这个名字?
首先,t-分布是关于样本(而非总体)的t 变换值的分布,它是对u 变换变量值的标准正态分布的估计分布,是一位学生首先提出的,所以 t-分布全称:学生t-分布。
其次,t-SNE本质是一种嵌入模型,能够将高维空间中的数据映射到低维空间中,并保留数据集的局部特性。t-SNE 可以算是目前效果很好的数据降维和可视化方法之一。
缺点主要是占用内存较多、运行时间长。
t-SNE变换后,如果在低维空间中具有可分性,则数据是可分的;如果在低维空间中不可分,则可能是因为数据集本身不可分,或者数据集中的数据不适合投影到低维空间。
该算法在论文中非常常见,主要用于高维数据的降维和可视化。
Visualizing Data using t-SNE,2008年发表在Journal of Machine Learning Research,大神Hinton的文章:
http://www.jmlr.org/papers/v9/vandermaaten08a.html
2 t-SNE 原理描述
t-SNE将数据点之间的相似度转化为条件概率,原始空间中数据点的相似度由高斯联合分布表示,嵌入空间中数据点的相似度由学生t分布 表示。
通过原始空间和嵌入空间的联合概率分布的KL散度(用于评估两个分布的相似度的指标,经常用于评估机器学习模型的好坏)来评估嵌入效果的好坏。
也就是,将有关KL散度的函数作为损失函数(loss function),通过梯度下降算法最小化损失函数,最终获得收敛结果。
3 t-SNE 精华所在
t-SNE的精华都在以下这些文字:
在文中提到的论文中,主要讨论降维出现的拥挤问题,解决的方法也很巧妙,一旦理解它后就明白为什么叫t-分布随机近邻嵌入。
如果想象在一个三维的球里面有均匀分布的点,不难想象,如果把这些点投影到一个二维的圆上一定会有很多点是重合的。
所以,为了在二维的圆上想尽可能表达出三维里的点的信息,大神Hinton采取的方法:
把由于投影所重合的点用不同的距离(差别很小)表示。
这样就会占用原来在那些距离上的点,原来那些点会被赶到更远一点的地方。
t分布是长尾的,意味着距离更远的点依然能给出和高斯分布下距离小的点相同的概率值。
从而达到高维空间和低维空间对应的点概率相同的目的。
# 降维到二维
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=20000)
X_tsne_2d = tsne.fit_transform(encoding_array)结果如下:

可视化结果:
# 不同的 符号 表示 不同的 标注类别
show_feature = '标注类别名称'
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 14))
for idx, fruit in enumerate(class_list): # 遍历每个类别
# 获取颜色和点型
color = palette[idx]
marker = marker_list[idx%len(marker_list)]
# 找到所有标注类别为当前类别的图像索引号
indices = np.where(df[show_feature]==fruit)
plt.scatter(X_tsne_2d[indices, 0], X_tsne_2d[indices, 1], color=color, marker=marker, label=fruit, s=150)
plt.legend(fontsize=16, markerscale=1, bbox_to_anchor=(1, 1))
plt.xticks([])
plt.yticks([])
plt.savefig('语义特征t-SNE二维降维可视化.pdf', dpi=300) # 保存图像
plt.show()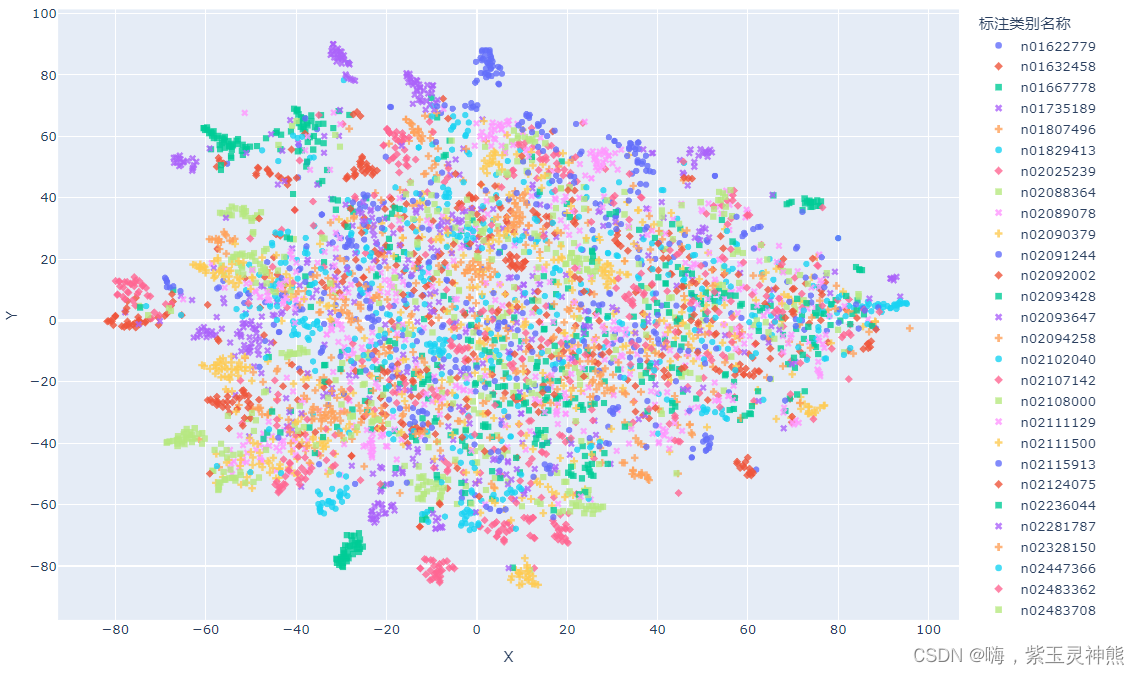
plotply交互式可视化
import plotly.express as px
df_2d = pd.DataFrame()
df_2d['X'] = list(X_tsne_2d[:, 0].squeeze())
df_2d['Y'] = list(X_tsne_2d[:, 1].squeeze())
df_2d['标注类别名称'] = df['标注类别名称']
df_2d['预测类别'] = df['top-1-预测名称']
df_2d['图像路径'] = df['图像路径']
df_2d.to_csv('t-SNE-2D.csv', index=False)
fig = px.scatter(df_2d,
x='X',
y='Y',
color=show_feature,
labels=show_feature,
symbol=show_feature,
hover_name='图像路径',
opacity=0.8,
width=1000,
height=600
)
# 设置排版
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()
fig.write_html('语义特征t-SNE二维降维plotly可视化.html')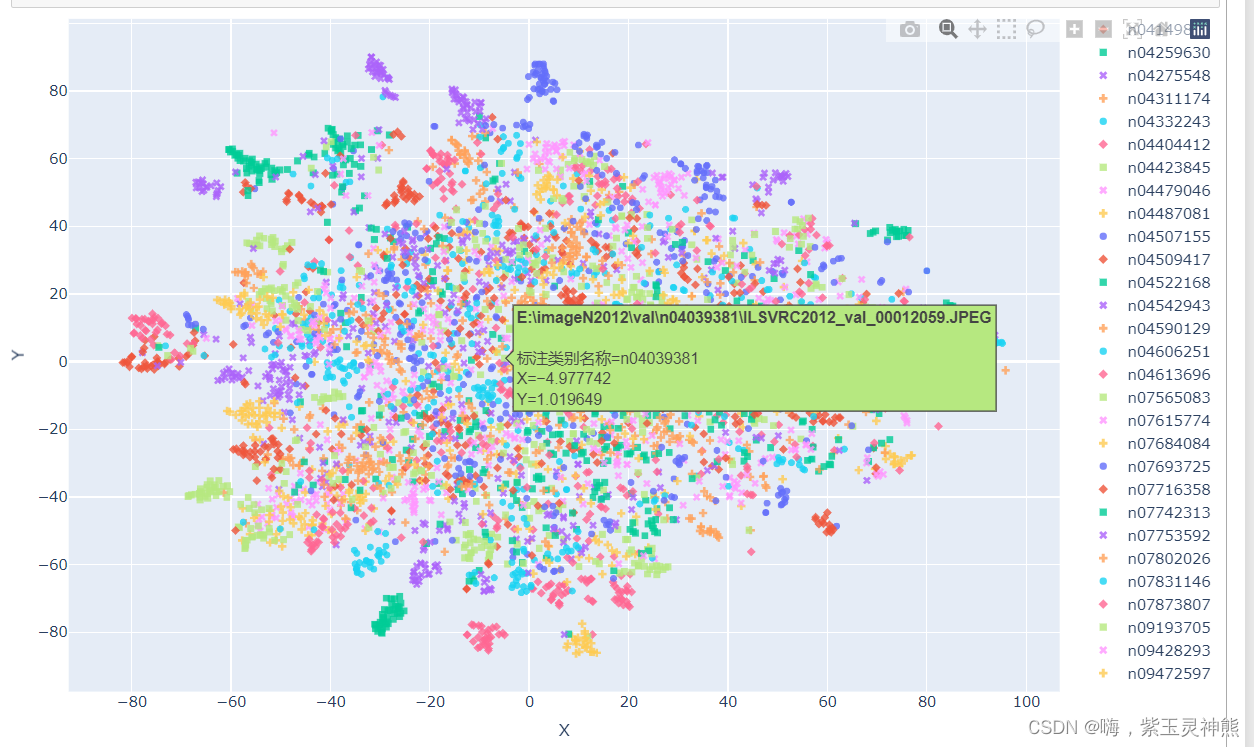
t-SNE降维至三维,并可视化
# 降维到三维
from sklearn.manifold import TSNE
tsne = TSNE(n_components=3, n_iter=10000)
X_tsne_3d = tsne.fit_transform(encoding_array)
show_feature = '标注类别名称'
df_3d = pd.DataFrame()
df_3d['X'] = list(X_tsne_3d[:, 0].squeeze())
df_3d['Y'] = list(X_tsne_3d[:, 1].squeeze())
df_3d['Z'] = list(X_tsne_3d[:, 2].squeeze())
df_3d['标注类别名称'] = df['标注类别名称']
df_3d['预测类别'] = df['top-1-预测名称']
df_3d['图像路径'] = df['图像路径']
df_3d.to_csv('t-SNE-3D.csv', index=False)
fig = px.scatter_3d(df_3d,
x='X',
y='Y',
z='Z',
color=show_feature,
labels=show_feature,
symbol=show_feature,
hover_name='图像路径',
opacity=0.6,
width=1000,
height=800)
# 设置排版
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()
fig.write_html('语义特征t-SNE三维降维plotly可视化.html')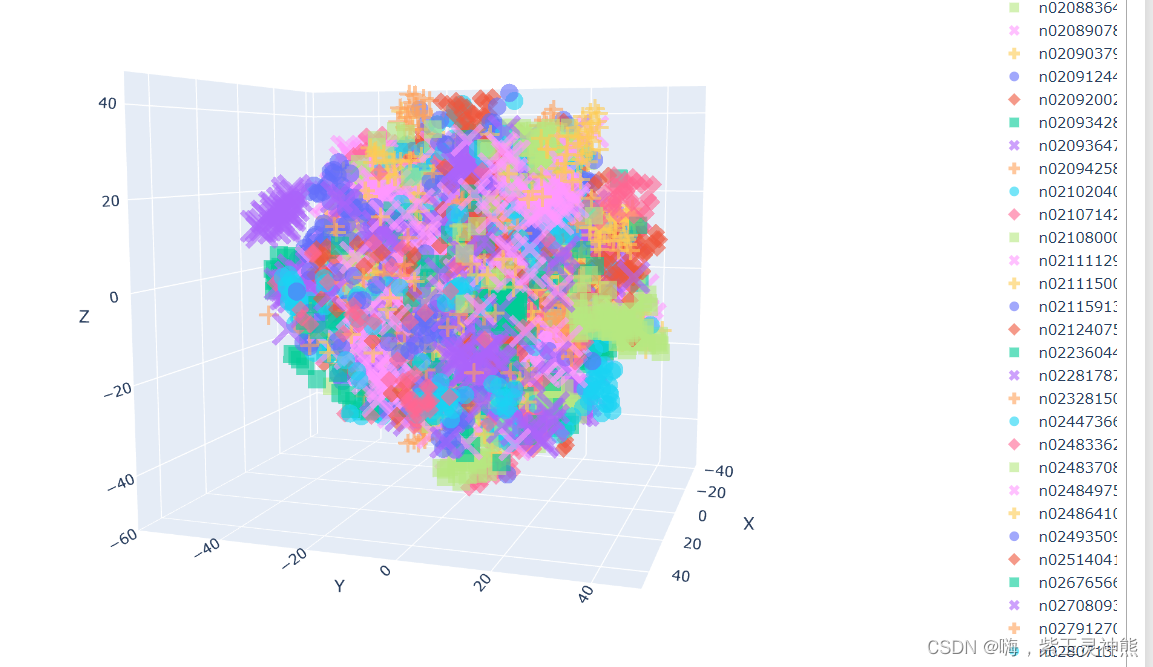


















 3412
3412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









