







现代人工智能(AI)系统是由基础模型驱动的。本文提出了一套新的基础模型,称为Llama 3。它是一组语言模型,支持多语言、编码、推理和工具使用。我们最大的模型是一个密集的Transformer,具有405B个参数和多达128K个tokens的上下文窗口。本文对Llama 3进行了广泛的实证评价。我们发现Llama 3在大量任务上提供了与领先的语言模型(如GPT-4)相当的质量。我们公开发布了Llama 3,包括405B参数语言模型的预训练和后训练版本,以及用于输入和输出安全的Llama Guard 3模型。本文还介绍了我们通过合成方法将图像、视频和语音功能集成到Llama 3中的实验结果。我们观察到这种方法在图像、视频和语音识别任务上与最先进的方法相比具有竞争力。最终的模型还没有被广泛发布,因为它们仍在开发中。
1 Introduction 介绍
基础模型是语言、视觉、语音和/或其他模式的通用模型,旨在支持各种各样的人工智能任务。它们构成了许多现代人工智能系统的基础。
现代基础模型的发展包括两个主要阶段:(1)预训练阶段,在这个阶段,模型使用直接的任务进行大规模的训练,比如下一个单词预测或字幕;(2)后训练阶段,在这个阶段,模型被调整到遵循指令,与人类偏好保持一致,并提高特定的能力(例如,编码和推理)。
在本文中,我们提出了一套新的语言基础模型,称为Llama 3。Llama 3的模型群支持多语言、编码、推理和工具使用。我们最大的模型是具有405B个参数的密集Transformer,在多达128Ktokens的上下文窗口中处理信息。Llama 3 的每个成员列在表1中。本文给出的所有结果都是针对Llama 3.1模型的,为了简单起见,我们将其称为Llama 3。

我们相信在开发高质量的基础模型中有三个关键的杠杆:数据、规模和管理复杂性。在我们的开发过程中,我们寻求优化这三个杠杆:
•数据。与之前版本的Llama相比(Touvron等人,2023a,b),我们提高了用于预训练和后训练的数据的数量和质量。这些改进包括为训练前数据开发更仔细的预处理和管理管道,为训练后数据开发更严格的质量保证和过滤方法。我们在大约15T多语言标记的语料库上对Llama 3进行了预训练,而Llama 2的标记为1.8T。
•规模。我们以比以前的Llama模型大得多的规模训练模型:我们的旗舰语言模型使用3:8 × 1025 FLOPs进行预训练,几乎比Llama 2的最大版本多50倍。具体来说,我们在15.6T文本tokens上预训练了一个具有405B个可训练参数的旗舰模型。对于基础模型的缩放定律,我们的旗舰模型优于使用相同过程训练的较小模型。虽然我们的缩放定律表明我们的旗舰模型对于我们的训练预算来说是一个近似于计算最优的大小,但我们训练较小的模型的时间也比计算最优的时间长得多。在相同的推理预算下,所得模型比计算最优模型表现得更好。我们使用旗舰模型在后期训练中进一步提高那些较小模型的质量。
•管理复杂性。我们做出的设计选择是为了最大化我们扩展模型开发过程的能力。例如,我们选择了标准的密集Transformer模型架构(Vaswani等人,2017),并进行了较小的调整,而不是选择混合专家模型(Shazeer等人,2017),以最大限度地提高训练稳定性。同样,我们采用了一个相对简单的训练后程序,基于监督微调(SFT)、拒绝抽样(RS)和直接偏好优化(DPO;Rafailov等人(2023)),而不是更复杂的强化学习算法(Ouyang等人,2022;Schulman等人,2017),往往不太稳定,难以扩展。
Llama 3是一组具有8B、70B和405B参数的三种多语言模型。我们在大量的基准数据集上评估了Llama 3的性能,这些数据集涵盖了广泛的语言理解任务。此外,我们进行了广泛的人类评估,将Llama 3与竞争模型进行比较。旗舰Llama 3模型在关键基准测试上的性能概述见表2。我们的实验评估表明,我们的旗舰模型在各种任务中的表现与领先的语言模型(如GPT-4 (OpenAI, 2023a))相当,并且接近于最先进的水平。我们的小型模型是同类中最好的,优于具有相似参数数量的替代模型(Bai等人,2023;Jiang et al, 2023)。Llama 3也提供了比它的前辈更好的平衡在帮助和无害(Touvron等人,2023b)。我们在第5.4节中详细分析了Llama 3的安全性。
我们将在更新版本的Llama 3社区许可下公开发布所有三款Llama 3模型;见https://llama.meta.com。这包括我们的405B参数语言模型的预训练和后训练版本,以及用于输入和输出安全的新版本的Llama Guard模型(Inan等人,2023)。
我们希望旗舰模型的公开发布将激发研究界的创新浪潮,并加速人工通用智能(AGI)发展的负责任道路。
作为Llama 3开发过程的一部分,我们还开发了模型的多模态扩展,支持图像识别、视频识别和语音理解功能。这些模型仍在积极开发中,尚未准备好发布。除了我们的语言建模结果外,本文还介绍了我们对这些多模态模型的初步实验结果。

2 General Overview 总体概述
Llama 3的模型体系结构如图1所示。我们的Llama 3语言模型的开发包括两个主要阶段:
•语言模型预训练。我们首先将大型多语言文本语料库转换为离散tokens,并在结果数据上预训练大型语言模型(LLM)以执行下一个token预测。在语言模型预训练阶段,模型学习语言的结构,从它所“阅读”的文本中获得大量关于世界的知识。为了有效地做到这一点,需要大规模地进行预训练:我们使用8K个tokens的上下文窗口,在15.6个token上预训练一个具有405B个参数的模型。这个标准的预训练阶段之后是一个持续的预训练阶段,将支持的上下文窗口增加到128K个tokens。详细信息请参见第3节。
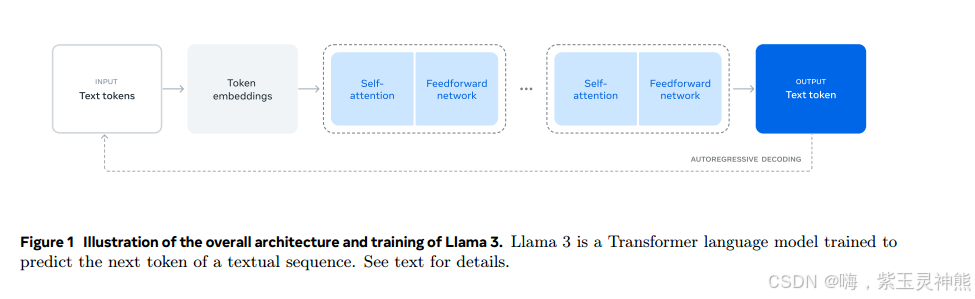
•语言模型后训练。预训练的语言模型对语言有丰富的理解,但它还没有按照我们期望的助手的方式执行指令或行为。我们将模型与人类反馈进行了几轮调整,每一轮都涉及指令调整数据的监督微调(SFT)和直接偏好优化(DPO);Rafailov et al, 2024)。在这个培训后2阶段,我们还集成了新的能力,例如工具使用,并观察到其他领域的强大改进,例如编码和推理。详细信息请参见第4节。最后,在培训后阶段也将安全缓解措施纳入模型,其细节见第5.4节。
生成的模型具有丰富的功能集。他们可以用至少八种语言回答问题,编写高质量的代码,解决复杂的推理问题,并使用部署即用的工具或以零样本的方式使用工具。
我们还进行了实验,其中我们使用合成方法为Llama 3添加图像,视频和语音功能。我们研究的方法包括图28所示的三个附加阶段:
•多模态编码器预训练。我们为图像和语音分别训练编码器。我们在大量的图像-文本对上训练图像编码器。这教会了模型视觉内容和自然语言描述内容之间的关系。我们的语音编码器是用自监督方法,屏蔽部分语音输入,并试图通过离散tokens表示重建被屏蔽的部分。因此,该模型学习语音信号的结构。关于图像编码器的详细信息参见第7节,关于语音编码器的详细信息参见第8节。
•视觉适配训练。我们训练了一个适配器,将预训练的图像编码器集成到预训练的语言模型中。适配器由一系列跨注意层组成,这些层将图像编码器表示提供给语言模型。适配器是在文本-图像对上进行训练的。这使图像表示与语言表示保持一致。在适配器训练期间,我们也更新了图像编码器的参数,但我们有意不更新语言模型参数。我们还在配对视频文本数据的图像适配器之上训练了一个视频适配器。这使模型能够跨框架聚合信息。参见第7节了解详细信息。
•语音适配训练。最后,我们通过一个适配器将语音编码器集成到模型中,该适配器将语音编码转换为可以直接馈送到微调语言模型中的tokens表示。适配器和编码器的参数在监督微调阶段共同更新,以实现高质量的语音理解。在语音适配器训练期间,我们不会更改语言模型。我们还集成了一个文本转语音系统。详细信息请参见第8节。
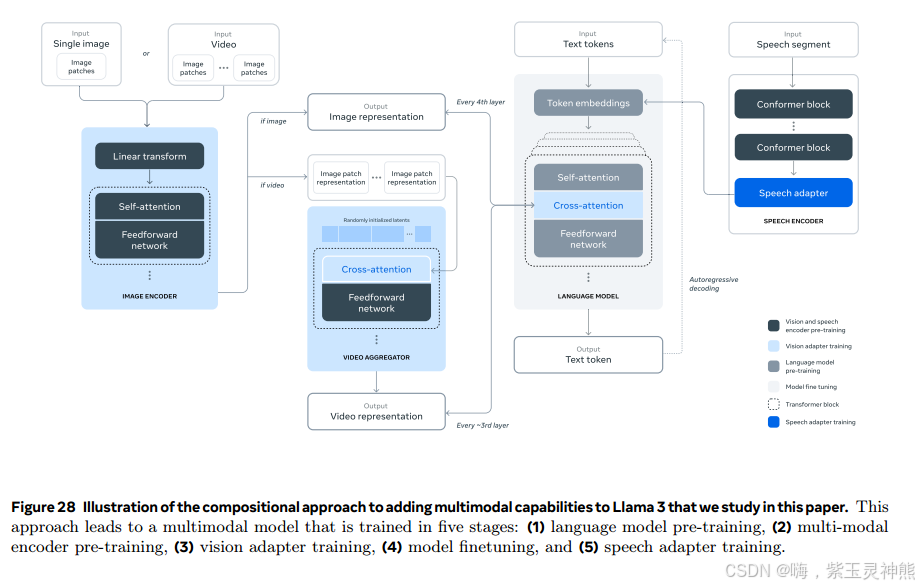
我们的多模态实验使模型能够识别图像和视频的内容,并支持通过语音界面进行交互。这些模型仍在开发中,尚未准备好发布。
3 Pre-Training 预训练
语言模型预训练包括:(1)大规模训练语料库的管理和过滤,(2)模型体系结构的开发以及用于确定模型大小的相应缩放定律,(3)大规模高效预训练技术的开发,以及(4)预训练配方的开发。我们将在下面分别介绍这些组件。
3.1 Pre-Training Data 预训练数据
我们从包含知识的各种数据源中创建用于语言模型预训练的数据集,直到2023年底。我们在每个数据源上应用了几种重复数据删除方法和数据清理机制,以获得高质量的tokens。我们会删除包含大量个人身份信息(PII)的域名,以及包含已知成人内容的域名。
3.1.1 Web Data Curation 网络数据管理
我们使用的大部分数据都是从网上获得的,我们在下面描述了我们的清理过程。
PII和安全过滤。在其他缓解措施中,我们实施了过滤器,旨在从可能包含不安全内容或大量PII的网站中删除数据,根据各种Meta安全标准,已被列为有害的域名,以及已知包含成人内容的域名。
文本提取和清理。我们处理未截断的web文档的原始HTML内容,以提取高质量的多样化文本。为此,我们构建了一个自定义解析器,它提取HTML内容并优化样板删除和内容召回的精度。我们在人工评估中评估了解析器的质量,并将其与针对类似文章的内容进行优化的流行第三方HTML解析器进行了比较,发现它的性能更好。我们小心地处理包含数学和代码内容的HTML页面,以保持该内容的结构。我们维护图像alt属性文本,因为数学内容通常表示为预渲染的图像,其中数学也在alt属性中提供。我们实验评估了不同的清洗配置。我们发现与纯文本相比,markdown对主要在web数据上训练的模型的性能有害,因此我们删除了所有markdown标记。
重复数据删除。我们在URL、文档和行级别应用几轮重复数据删除:
•URL级重复数据删除。我们跨整个数据集执行url级重复数据删除。我们保留与每个URL对应的页面的最新版本。
•文档级重复数据删除。我们在整个数据集上执行全局MinHash (Broder, 1997)去重复,以删除几乎重复的文档。
•行级重复数据删除。我们执行类似于ccNet的积极的行级重复数据删除(Wenzek等人,2019)。我们删除在30M文档的每个bucket中出现超过6次的行。尽管我们的手工定性分析表明,行级重复数据删除不仅删除了导航菜单、cookie警告等各种网站的剩余样板文件,还删除了频繁的高质量文本,但我们的实证评估显示出了很大的改进。
启发式过滤。我们开发了启发式方法来删除额外的低质量文档、异常值和重复过多的文档。启发式的一些例子包括:
•我们使用重复的n-gram覆盖率(Rae et al, 2021)来删除由重复内容(如日志或错误消息)组成的行。这些行可能非常长且唯一,因此不能通过行删除来过滤。
•我们使用“脏话”计数(rafael et al, 2020)来过滤掉未被域名阻止列表覆盖的成人网站。
•我们使用tokens分布Kullback-Leibler散度来过滤掉与训练语料库分布相比包含过多异常token的文档
基于模型的质量过滤。此外,我们尝试应用各种基于模型的质量分类器来子选择高质量的tokens。其中包括使用快速分类器,如fasttext (Joulin等人,2017),训练以识别给定文本是否会被维基百科引用(Touvron等人,2023a),以及在Llama 2预测上训练的基于roberta的计算密集型分类器(Liu等人,2019a)。为了训练一个基于Llama 2的质量分类器,我们创建了一个经过清理的web文档的训练集,描述了质量要求,并指示Llama 2的聊天模型来确定文档是否满足这些要求。出于效率原因,我们使用蒸馏roberta (Sanh等人,2019)为每个文档生成质量分数。我们通过实验评估了各种质量滤波配置的有效性。
代码和推理数据。与DeepSeek-AI等人(2024)类似,我们构建特定领域的管道来提取代码和与数学相关的网页。具体来说,代码和推理分类器都是在Llama 2注释的web数据上训练的蒸馏器模型。与上面提到的一般质量分类器不同,我们对包含数学演绎、STEM领域推理和与自然语言交织的代码的目标网页进行了快速调优。由于代码和数学的tokens分布与自然语言的tokens分布有很大不同,因此这些管道实现了特定领域的HTML提取、自定义文本特性和启发式过滤。
多语言数据。与上面描述的英语处理管道类似,我们实现了过滤器,从可能包含PII或不安全内容的网站中删除数据。我们的多语言文本处理管道有几个独特的功能:
•我们使用基于快速文本的语言识别模型将文档分类为176种语言。
•我们在每种语言的数据中执行文档级和行级重复数据删除。
•我们应用特定于语言的启发式和基于模型的过滤器来删除低质量的文档。
此外,我们使用基于多语言Llama 2的分类器对多语言文档进行质量排序,以确保高质量的内容被优先考虑。我们在实验中确定了预训练中使用的多语言tokens的数量,平衡了英语和多语言基准上的模型性能。
3.1.2 Determining the Data Mix 确定数据组合
为了获得高质量的语言模型,必须仔细确定预训练数据组合中不同数据源的比例。我们确定这种数据组合的主要工具是知识分类和标度定律实验。
知识分类。我们开发了一个分类器来对web数据中包含的信息类型进行分类,以更有效地确定数据组合。我们使用这个分类器对网络上代表性过高的数据类别进行采样,例如,艺术和娱乐。
数据混合的缩放定律。为了确定最佳的数据组合,我们执行缩放定律实验,在该实验中,我们在数据组合上训练几个小模型,并使用它来预测大模型在该混合上的性能(参见3.2.1节)。我们对不同的数据组合重复此过程多次,以选择一个新的数据组合候选。随后,我们在这个候选数据组合上训练一个更大的模型,并在几个关键基准上评估该模型的性能。
数据混合汇总。我们最终的数据组合包含大约50%的与一般知识相关的tokens,25%的数学和推理tokens,17%的代码tokens和8%的多语言tokens。
3.1.3 Annealing Data 退火数据
经验上,我们发现对少量高质量代码和数学数据进行退火(见第3.4.3节)可以提高预训练模型在关键基准上的性能。与Li等人(2024b)类似,我们使用数据混合执行退火,该数据混合在选择的域中对高质量数据进行采样。在我们的退火数据中,我们不包括任何来自常用基准的训练集。这使我们能够评估Llama 3的真正的少量学习能力和域外泛化。
在OpenAI (2023a)之后,我们评估了退火对GSM8k (Cobbe等人,2021)和MATH (Hendrycks等人,2021b)训练集的效果。我们发现,在GSM8k和MATH验证集上,退火使预训练的Llama 38b模型的性能分别提高了24.0%和6.4%。然而,405B模型的改进可以忽略不计,这表明我们的旗舰模型具有强大的上下文学习和推理能力,并且不需要特定的域内训练样本来获得强大的性能。
使用退火来评估数据质量。与Blakeney等人(2024)类似,我们发现退火使我们能够判断小的特定领域数据集的价值。我们通过将经过50%训练的Llama 38b模型的学习率在40B个tokens上线性退火到0来衡量这些数据集的价值。在这些实验中,我们将30%的权重分配给新数据集,其余70%的权重分配给默认数据组合。使用退火来评估新数据源比对每个小数据集进行标度律实验更有效。
3.2 Model Architecture 网络结构
Llama 3使用标准的、密集的Transformer架构(Vaswani et al, 2017)。在模型架构方面,它与Llama和Llama 2 (Touvron et al, 2023a,b)没有明显偏差;我们的业绩增长主要得益于数据质量和多样性的提高以及培训规模的扩大。
在Llama 3中,我们做了一些较小的修改:
•我们使用分组查询关注(GQA;Ainslie等(2023))使用8个key-value头来提高推理速度并减少解码期间键值缓存的大小。
•我们使用attention mask来防止同一序列内不同文档之间的自我注意。我们发现这种变化在标准预训练中影响有限,但在很长序列的持续预训练中很重要。
•我们使用具有128K tokens 的词汇表。我们的tokens词汇表结合了来自tiktoken3标记器的100K个标记和28K个额外的标记,以更好地支持非英语语言。与Llama 2标记器相比,我们的新标记器将英语数据样本的压缩率从每个标记3.17个字符提高到3.94个字符。这使得模型能够在相同数量的训练计算中“读取”更多的文本。我们还发现,从选择的非英语语言中添加28K个tokens可以提高压缩比和下游性能,而对英语tokens化没有影响。
•我们将RoPE基频超参数增加到500,000。这使我们能够更好地支持较长的上下文;Xiong等人(2023)表明,该值对上下文长度达到32,768时有效。
Llama 3 405B使用126层的架构,a token 表示维度为16,384,使用了128个注意头;详见表3。根据我们的训练预算为3.8 × 10^25 FLOPs的数据缩放定律,这使得模型大小近似为计算最优。

3.2.1 Scaling Laws 缩放规则
我们开发缩放规则(Hoffmann et al, 2022;Kaplan等人,2020),在给定预训练计算预算的情况下,确定旗舰模型的最佳模型大小。除了确定最佳模型大小之外,一个主要的挑战是预测旗舰模型在下游基准任务上的性能,这有几个问题:(1)现有的缩放规则通常只预测下一个token的预测损失,而不是具体的基准性能。(2)缩放规则可能是嘈杂和不可靠的,因为它们是基于使用较小的计算预算进行的预训练运行而开发的(Wei等人,2022b)。
为了应对这些挑战,我们实施了一种两阶段的方法来开发缩放规则,以准确预测下游基准性能:
1. 我们首先建立了计算最优模型在下游任务上的负对数似然与训练flop之间的相关性。
2. 接下来,我们将下游任务的负对数似然与任务精度关联起来,利用缩规则模型和使用更高计算FLOPs训练的旧模型。在这一步中,我们特别利用了Llama 2系列模型。
这种方法使我们能够在给定计算最优模型的特定数量的训练flop的情况下预测下游任务性能。我们使用类似的方法来选择预训练数据组合(参见3.4节)。
缩放规则实验。具体来说,我们使用6 × 101^8 FLOPs和10^22 FLOPs之间的计算预算,通过预训练模型构建缩放规则。在每个计算预算中,我们使用每个计算预算中的模型大小子集来预训练大小在40M到16B参数之间的模型。在这些训练运行中,我们使用余弦学习率计划和2000个训练步骤的线性热身。根据模型的大小,峰值学习率设置在2 × 10^−4到4 × 10^−4之间。我们将余弦衰减设为峰值的0.1。每一步的权重衰减设置为该步学习率的0.1倍。我们对每个计算规模使用固定的批处理大小,范围在250K到4M之间。
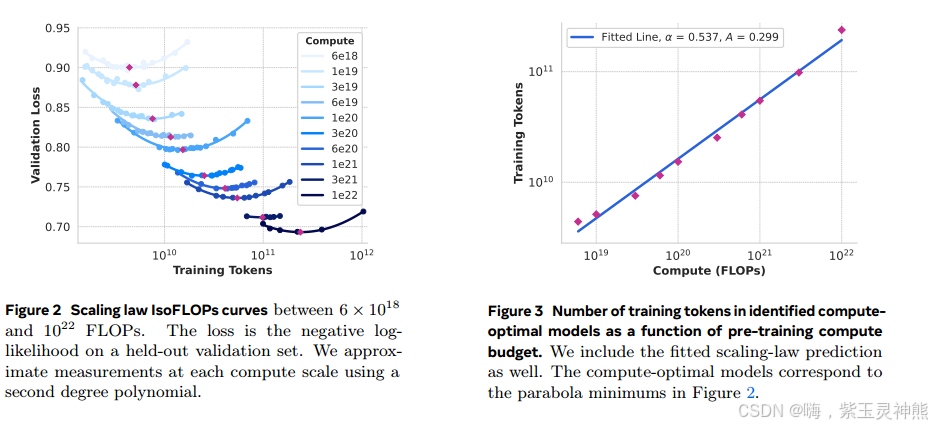
这些实验产生了图2中的IsoFLOPs曲线。这些曲线中的损失是在一个单独的验证集上测量的。我们使用二次多项式拟合测量的损耗值,并确定每个抛物线的最小值。我们将抛物线的最小值作为在相应的预训练计算预算下的计算最优模型。
我们使用以这种方式确定的计算最优模型来预测特定计算预算的训练token的最优数量。为此,我们假设计算预算C和最优训练tokens,N*(C):
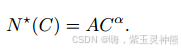
使用图2中的数据拟合A和α。我们发现(α;A) = (0.53;0.29);相应的配合如图3所示。将得到的缩放定律外推到3.8 × 10^25 FLOPs,建议在16.55T tokens上训练402B参数模型。
一个重要的观察结果是,随着计算预算的增加,IsoFLOPs曲线在最小值附近变得更平坦。这意味着旗舰模型的性能对于模型大小和训练tokens之间的权衡的小变化是相对健壮的。基于这一观察,我们最终决定训练一个具有405B参数的旗舰模型。
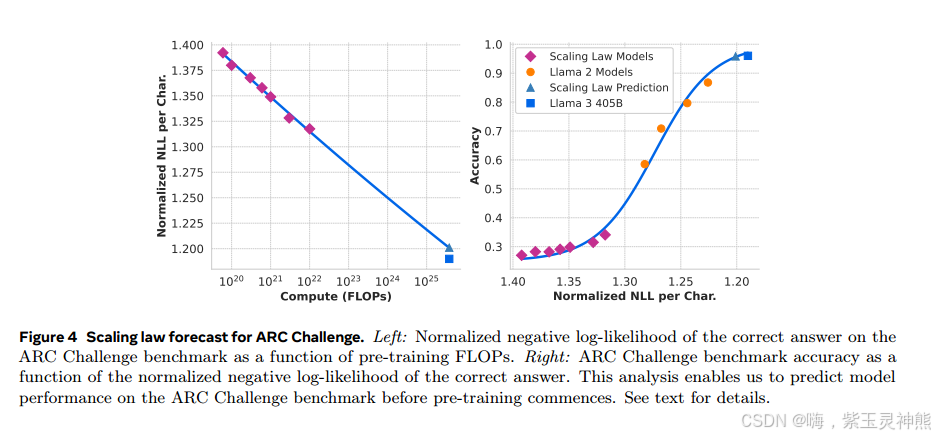
预测下游任务的性能。我们使用所得的计算最优模型来预测旗舰Llama 3模型在基准数据集上的性能。首先,我们将基准和训练flop中正确答案的(归一化的)负对数似然线性关联。在此分析中,我们仅使用在上述数据混合上训练到10^22 FLOPs的缩放律模型。接下来,我们使用缩放律模型和Llama 2模型建立了对数似然和精度之间的s型关系,其中Llama 2模型使用Llama 2数据混合和标记器进行训练。我们在ARC Challenge基准测试上展示了这个实验的结果,如图4)。我们发现这个两步缩放定律预测(外推超过四个数量级)非常准确:它只略微低估了旗舰Llama 3模型的最终性能。
3.3 Infrastructure, Scaling, and Efficiency 基础硬件设施、规模和效率
我们描述了为Llama 3 405b大规模预训练提供动力的硬件和基础设施,并讨论了一些优化,从而提高了训练效率
3.3.1 Training Infrastructure 训练的基础配置
Llama 1和2模型在Meta的AI研究超级集群上进行训练(Lee和Sengupta, 2022)。随着我们进一步扩展,Llama 3的训练被迁移到Meta的生产集群(Lee et al, 2024)。这设置优化生产级的可靠性,这是必不可少的,因为这在我们扩大培训规模时是至关重要的。
计算。Llama 3 405b在高达16K H100 GPUs上进行训练,每个GPU以700W TDP和80GB HBM3运行,使用Meta的Grand Teton AI服务器平台(Matt Bowman, 2022)。每台服务器配置8个GPUs和2个CPUs。在服务器内部,8个GPUs通过NVLink连接。使用MAST (Choudhury等人,2024),Meta的全球规模训练调度程序来安排训练任务。
存储。构造(Pan et al, 2021)是Meta的通用分布式文件系统,用于构建用于Llama 3预训练的存储结构(Battey和Gupta, 2024)。它在配备ssd的7500台服务器中提供240 PB的存储空间,并支持2 TB /s的可持续吞吐量和7 TB /s的峰值吞吐量。一个主要的挑战是支持高度突发的检查点写入,这会在短时间内使存储结构饱和。检查点保存每个GPU的模型状态,每个GPU从1 MB到4 GB不等,用于恢复和调试。我们的目标是在检查点期间尽量减少GPU暂停时间,并增加检查点频率,以减少恢复后丢失的工作量
网络。Llama 3 405b在基于Arista 7800和Minipack2 Open Compute Project4 OCP机架交换机的融合以太网(RoCE)结构上使用RDMA。Llama 3家族中的较小模型使用Nvidia Quantum2 Infiniband结构进行训练。RoCE和Infiniband集群都利用GPUs之间400 Gbps的互连。尽管这些集群之间存在底层网络技术差异,但我们对它们进行了调优,以便为这些大型训练工作负载提供相同的性能。我们进一步阐述了我们的RoCE网络,因为我们完全拥有它的设计。
•网络拓扑。我们基于roce的AI集群由24K GPUs组成,通过三层Clos网络连接(Lee et al ., 2024)。在底层,每个机架承载16个GPUs,分布在两个服务器之间,并通过一个Minipack2机架顶部(ToR)交换机连接。在中间层,192个这样的机架通过Cluster switch连接在一起,形成3072个GPUs的pod,具有全等分带宽,确保不会出现超订阅。在顶层,同一数据中心大楼内的8个这样的pod通过聚合交换机连接起来,形成一个24K GPUs集群。然而,汇聚层的网络连接并没有保持全部平分带宽,而是有1:7的超额订阅比例。我们的模型并行方法(见第3.3.2节)和训练作业调度器(Choudhury等人,2024)都经过优化,以了解网络拓扑,旨在最大限度地减少pod之间的网络通信。
•负载均衡。LLM训练产生大量的网络流,很难使用传统方法(如等成本多路径(ECMP)路由)在所有可用的网络路径上实现负载平衡。为了应对这一挑战,我们采用了两种技术。首先,我们的集合库在两个GPUs之间创建了16个网络流,而不是一个,从而减少了每个流的流量并提供了更多的流用于负载均衡。其次,我们的增强型ecmp (E-ECMP)协议通过对数据包RoCE报头中的附加字段进行散列,有效地平衡了跨不同网络路径的这16个流。
•堵塞控制。我们在主干中使用深度缓冲开关(Gangidi等人,2024)来适应由集体通信模式引起的瞬态堵塞和缓冲。这种设置有助于限制由慢速服务器引起的持续拥塞和网络反压力的影响,这在培训中很常见。最后,通过E-ECMP实现更好的负载平衡可以显著降低堵塞的可能性。通过这些优化,我们成功地运行了一个24K GPU集群,没有使用传统的堵塞控制方法,如数据中心量化堵塞通知(DCQCN)。
3.3.2 Parallelism for Model Scaling 并行的模型规模
为了扩展我们最大模型的训练,我们使用4D并行——四种不同并行方法的组合——来分割模型。这种方法有效地将计算分布在多个GPU上,并确保每个GPU的模型参数、优化器状态、梯度和激活符合其HBM。我们对4D并行性的实现如图5所示。它结合了张量并行性(TP;Krizhevsky et al (2012);Shoeybi等人(2019);Korthikanti等人(2023)),管道并行度(PP;Huang等(2019);Narayanan等(2021);Lamy-Poirier(2023)),语境平行(CP;Liu et al . (2023a)),数据并行性(DP;Rajbhandari等人(2020);Ren et al . (2021);赵等(2023b))。
张量并行性将单个权重张量在不同的设备上分成多个块。管道并行性将模型垂直分层划分为各个阶段,使得不同的设备可以并行处理整个模型管道的不同阶段。上下文并行性将输入上下文划分为段,减少了非常长的序列长度输入的内存瓶颈。我们使用完全分片数据并行(FSDP;Rajbhandari等人,2020;Ren等,2021;Zhao等人,2023b),将模型、优化器和梯度进行分片,同时实现数据并行,在多个gpu上并行处理数据,并在每个训练步骤后进行同步。我们使用FSDP来优化Llama 3分片的状态和梯度,但对于模型分片,我们不会在前向计算后重新分片,以避免在向后传递期间额外的全集通信。
GPU的利用率。通过对并行配置、硬件和软件的仔细调优,我们实现了BF16模型FLOPs利用率(MFU;Chowdhery et al(2023))对表4所示配置的影响为38-43%。在DP=128的16K gpu上,MFU略微下降到41%,而在DP=64的8K gpu上,MFU下降到43%,这是由于在训练期间,每个DP组需要保持每个批的全局令牌不变的批大小较低
管道并行性改进。我们在现有的实现中遇到了几个挑战:
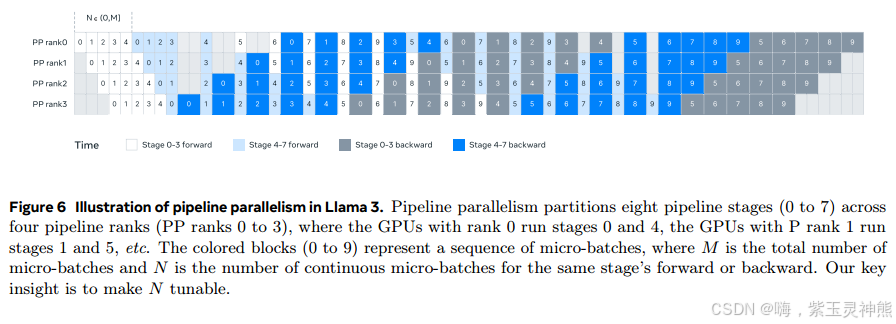
•批量大小约束。当前的实现对每个GPU支持的批处理大小有限制,要求它可以被管道阶段的数量整除。以图6为例,管道并行度的深度优先调度(DFS) (Narayanan et al, 2021)要求N = PP = 4,而宽度优先调度(BFS;Lamy-Poirier(2023))要求N = M,其中M为微批总数,N为同一阶段前进或后退的连续微批数。然而,预训练通常需要灵活地调整批大小。
•内存不平衡。现有的管道并行实现导致资源消耗不平衡。由于嵌入和预热微批,第一阶段消耗更多的内存。
•计算不平衡。在模型的最后一层之后,我们需要计算输出和损失,使这一阶段成为执行延迟瓶颈。

为了解决这些问题,我们修改流水线计划,如图6所示,它允许灵活地设置N——在本例中N = 5,它可以在每个批中运行任意数量的微批。这允许我们运行:(1)当我们有大规模批量大小限制时,微批比阶段数量少;或者(2)使用更多的微批来隐藏点对点通信,在DFS和广度优先调度(BFS)之间找到最佳的通信和内存效率。为了平衡管道,我们分别从第一阶段和最后阶段减少一个Transformer层。这意味着第一阶段的第一个模型块只有嵌入,最后阶段的最后一个模型块只有输出投影和损失计算。为了减少管道气泡,我们使用交错调度(Narayanan et al, 2021),在一个管道等级上使用V个管道级。管道总气泡比为PP−1 V * M。此外,我们在PP中采用异步点对点通信,这大大加快了训练速度,特别是在文档掩码引入额外计算不平衡的情况下。我们启用TORCH_NCCL_AVOID_RECORD_STREAMS来减少异步点对点通信的内存使用。最后,为了降低内存成本,基于详细的内存分配分析,我们主动释放不会用于未来计算的张量,包括每个管道阶段的输入和输出张量,这些张量不会用于未来的计算。通过这些优化,我们可以在没有激活检查点的情况下对Llama 3进行8K标记序列的预训练。
长序列的上下文并行性。在扩展Llama 3的上下文长度时,我们利用上下文并行性(CP)来提高内存效率,并允许对长度高达128K的极长序列进行训练。在CP中,我们跨序列维度进行分区,具体地说,我们将输入序列划分为2 × CP块,以便每个CP秩接收两个块,以便更好地实现负载平衡。第i个CP等级收到了第i个和(2 × CP−1−i)个块。
与现有的CP实现在环状结构中重叠通信和计算(Liu et al, 2023a)不同,我们的CP实现采用基于全聚的方法,首先对键(K)和值(V)张量进行全聚,然后计算局部查询(Q)张量块的关注输出。尽管在关键路径上暴露了全聚通信延迟,但我们仍然采用这种方法,主要有两个原因:(1)基于全聚的CP注意更容易、更灵活地支持不同类型的注意掩码,如文档掩码;(2)暴露的全采集延迟很小,因为通信K和V张量比使用GQA的Q张量小得多(Ainslie et al, 2023)。因此,注意力计算的时间复杂度比all-gather (O(s2) vs . O(S),其中S表示全因果掩模中的序列长度)大一个数量级,使得all-gather开销可以忽略不计。
网络感知并行配置。并行维的顺序,[TP, CP, PP, DP],优化了网络通信。最内层的并行性需要最高的网络带宽和最低的延迟,因此通常限制在同一服务器内。最外层的并行性可以在多跳网络中传播,并且应该容忍更高的网络延迟。因此,基于对网络带宽和延迟的需求,我们将并行度维度按[TP, CP, PP, DP]的顺序排列。DP(即FSDP)是最外层的并行性,因为它可以通过异步预取分片模型权重和减少梯度来容忍更长的网络延迟。确定以最小通信开销同时避免GPU内存溢出的最佳并行配置是具有挑战性的。我们开发了一个内存消耗估计器和一个性能投影工具,帮助我们探索各种并行配置,项目整体训练性能,并有效地识别内存差距。
数值稳定性。通过比较不同并行设置之间的训练损失,我们修复了几个影响训练稳定性的数值问题。为了保证训练的收敛性,我们在多个微批的反向计算中使用了FP32梯度积累,并在FSDP的数据并行工作者中减少了FP32的分散梯度。对于前向计算中多次使用的中间张量,例如视觉编码器输出,在FP32中也会累积后向梯度。
3.3.3 Collective Communication 集群通信
Llama 3 的集体通信库是基于Nvidia的NCCL库的一个分支,称为NCCLX。NCCLX显著提高了NCCL的性能,特别是对于更高延迟的网络。回想一下,并行度维的顺序是[TP, CP, PP, DP],其中DP对应于FSDP。最外层的并行度维度PP和DP可以通过多跳网络进行通信,延迟可达数十微秒。原始的NCCL集合——FSDP中的all-gather和reduce-scatter, pp中的point-to-point——需要数据分块和分段数据复制。这种方法导致了几个低效率,包括(1)需要通过网络交换大量的小控制消息以促进数据传输,(2)额外的内存复制操作,以及(3)使用额外的GPU周期进行通信。对于Llama 3的训练,我们通过调整分块和数据传输来解决这些低效率的子集,以适应我们的网络延迟,对于大型集群来说,网络延迟可能高达数十微秒。我们还允许小的控制消息以更高的优先级穿越我们的网络,特别是避免在深缓冲区核心交换机中被阻塞。我们正在进行的未来Llama版本的工作包括对NCCLX进行更深入的修改,以全面解决上述所有问题。
3.3.4 Reliability and Operational Challenges 可靠性和开源挑战
16K GPU训练的复杂性和潜在的故障场景超过了我们操作过的更大的CPU集群。此外,训练的同步特性使其容错性较差——单个GPU故障可能需要重新启动整个作业。尽管存在这些挑战,对于Llama 3,我们在支持自动化集群维护(如固件和Linux内核升级)的同时实现了超过90%的有效训练时间(Vigraham and Leonhardi, 2024),这导致每天至少有一次训练中断。有效训练时间衡量的是花费在有用训练上的时间。
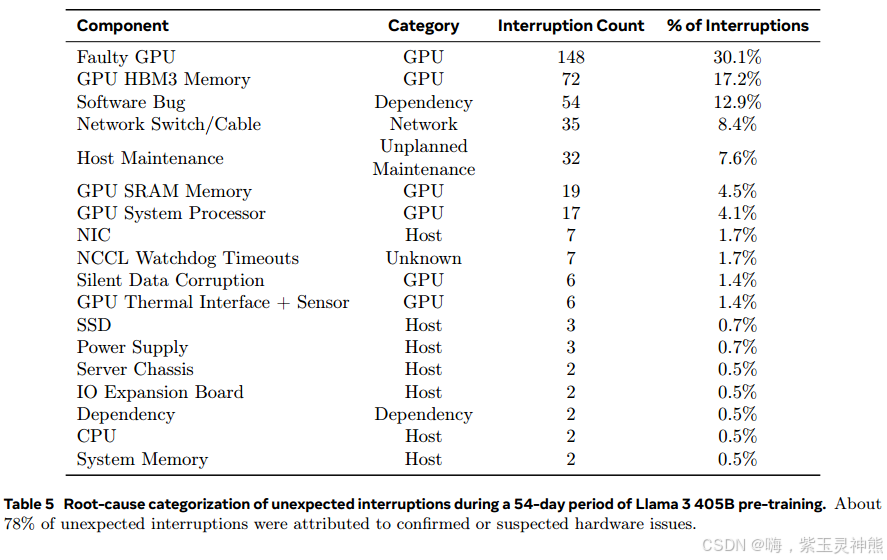
在54天的预培训快照期间,我们总共经历了466次工作中断。其中,47次是由于自动化维护操作(如固件升级)或运营商发起的操作(如配置或数据集更新)而计划中断的。剩下的419个是意外中断,分类见表5。大约78%的意外中断归因于已确认的硬件问题,如GPU或主机组件故障,或疑似硬件相关问题,如静默数据损坏和计划外的单个主机维护事件。GPU问题是最大的一类,占所有意外问题的58.7%。尽管出现了大量的故障,但在此期间只需要三次重大的人工干预,其余的问题都由自动化处理。
为了增加有效的培训时间,我们减少了工作启动和检查点时间,并开发了快速诊断和解决问题的工具。我们广泛使用PyTorch内置的NCCL飞行记录器(Ansel等人,2024),这是一个捕获集体元数据和堆栈跟踪到环形缓冲区的功能,因此允许我们快速诊断挂起和性能问题,特别是关于NCCLX。利用这种方法,我们可以有效地记录每个通信事件和每个集体操作的持续时间,并自动将跟踪数据转储到NCCLX看门狗或心跳超时。我们通过在线配置更改(Tang et al ., 2015),在不需要发布代码或重新启动作业的情况下,根据需要在生产环境中有选择地进行计算密集型跟踪操作和元数据收集。
在我们的网络中混合使用NVLink和RoCE,使得大规模训练中的调试问题变得复杂。NVLink上的数据传输通常通过CUDA内核发出的加载/存储操作进行,远程GPU或NVLink连接的失败通常表现为CUDA内核中的加载/存储操作停滞,而不会返回明确的错误代码。NCCLX提高了故障检测的速度和准确性通过与PyTorch紧密的协同设计来检测和定位,允许PyTorch访问NCCLX的内部状态并跟踪相关信息。虽然由于NVLink故障导致的延迟无法完全避免,但我们的系统可以监控通信库的状态,并在检测到此类延迟时自动超时。此外,NCCLX跟踪每个NCCLX通信的内核和网络活动,并提供失败的NCCLX集体内部状态的快照,包括所有级别之间已完成和待处理的数据传输。我们分析这些数据以调试NCCLX缩放问题。
有时,硬件问题可能会导致难以检测的仍在运行但速度缓慢的掉队器。即使是一个掉队的gpu也会减慢其他数千个gpu的速度,通常表现为功能正常但通信缓慢。我们开发了一些工具,对来自选定过程组的潜在问题通信进行优先级排序。通过调查几个最重要的嫌疑人,我们通常能够有效地识别掉队者。
一个有趣的观察是环境因素对大规模训练绩效的影响。对于Llama 3 405b,我们注意到基于一天中的时间的日吞吐量变化为1-2%。这种波动是正午较高温度影响GPU动态电压和频率缩放的结果。
在训练过程中,数以万计的gpu可能同时增加或减少功耗,例如,由于所有gpu等待检查点或集体通信完成,或者整个训练作业的启动或关闭。当这种情况发生时,可能会导致整个数据中心的电力消耗瞬间波动,达到数十兆瓦的量级,从而超出电网的极限。这对我们来说是一个持续的挑战,因为我们要为未来更大的Llama模型进行培训。
3.4 Training Recipe 训练方法
用于预训练Llama 3405b的配方包括三个主要阶段:(1)初始预训练,(2)长上下文预训练和(3)退火。下面将分别描述这三个阶段。我们使用类似的方法来预训练8B和70B模型
3.4.1 Initial Pre-Training 初始化预训练
我们使用余弦学习率计划预训练Llama 3 405b,峰值学习率为8 × 10^−5;8,000步的线性热身,以及在1,200,000步的训练中衰减到8 × 10^−7。我们在训练早期使用较低的批大小来提高训练的稳定性,随后增加批大小来提高效率。具体来说,我们使用4M标记和长度为4,096的序列的初始批大小,并在预训练252M标记后将这些值加倍到8,192个标记的8M序列的批大小。在对2.87T tokens进行预训练后,我们将批大小再次翻倍至16M。我们发现这个训练配方非常稳定:我们观察到很少的损失峰值,并且不需要干预来纠正模型训练偏差。
调整数据组合。我们在训练期间对预训练数据组合进行了一些调整,以提高模型在特定下游任务上的性能。特别是,我们在预训练期间增加了非英语数据的百分比,以提高Llama 3的多语言性能。我们还对数学数据进行了上采样,以提高模型的数学推理性能;我们在预训练的后期阶段添加了更多最新的网络数据,以提高模型的知识截止度;我们对预训练数据的子集进行了下采样,这些子集后来被认定为质量较低。
3.4.2 Long Context Pre-Training 长文本预训练
在预训练的最后阶段,我们对长序列进行训练,以支持多达128K tokens的上下文窗口。由于自关注层的计算量在序列长度上呈二次增长,所以我们没有在较早的时候对长序列进行训练。我们增量地增加支持的上下文长度,预训练,直到模型成功地适应增加的上下文长度。我们通过衡量(1)模型在短背景评估上的表现是否完全恢复,以及(2)模型是否完美地解决了“大海捞针”的任务,来评估适应是否成功。在Llama 3 405B预训练中,我们从最初的8K上下文窗口开始,到最后的128K上下文窗口,分6个阶段逐步增加上下文长度。这个长上下文预训练阶段是使用大约800B个训练token执行的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









