






1.点评Redis实现分析:
这里创建redis消费组和队列我就不说了,直接看消费组是怎么实现的:

用RabbbitMQ替代Stream
我的想法如下,结合Stream的特点逐一增加RabbitMQ的功能:
特点:
1.Stream可持久化(所以我们采用RabbitMQ的lazy队列以及消息,交换机,队列的可持久化机制)
2.Stream可以多消费者争抢消息,加快消费速度(所以我们采用WorkQueues模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高,并且采用prefetch机制,实现多消费者抢占式争抢消息,能者多劳的效果(默认是轮询方式))
3.Stream可以阻塞读取(RabbitMQ默认监听机制,比阻塞性能更好)
4.Stream没有消息漏读的风险(开启RabbitMQ的消费者确认机制和失败重试机制,前者可以避免消息漏读,后者可以设定次数,读者也可自行在此基础上自行设计失败处理策略)
5.Stream有消息确认机制,保证消息至少被消费一次(同样的开启RabbitMQ相关机制) 这里需要注意一点,我仅仅开启了消费者端的可靠机制(消费者确认和失败重试)和MQ的可靠机制(数据持久化),并没有开启MQ的发送者可靠机制(或称生产者确认,比较消耗MQ性能),读者可自行实现
2.RabbitMQ具体实现
2.1导入MQ的依赖
<!-- rabbitmq-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
<!-- 版本由 spring-boot-starter-parent 自动提供 -->
</dependency>
2.2配置MQ
spring:
rabbitmq:
host: 192.168.10.144 # 你的虚拟机IP
port: 5672 # 端口
virtual-host: /hm-dp # 虚拟主机
username: hm-dp # 用户名
password: 123 # 密码
listener:
simple:
prefetch: 5 # # 每次单个线程只能获取5条消息,处理完成才能获取下一个消息
acknowledge-mode: auto # 自动ack 当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果
retry:
enabled: true # 开启消费者失败重试
initial-interval: 1000ms # 初始的失败等待时长为1秒
multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval(类似csma-cd)
max-attempts: 3 # 最大重试次数
stateless: false # true无状态;false有状态。如果业务中包含事务,这里改为false
2.3设计消息队列和交换机
我考虑使用Direct交换机,设置RoutingKey为"seckill.order"
2.4生产者者发送消息到消息队列
注意我使用的是hash存储,在lua脚本里面判断了当前时间是否到了优惠券的秒杀活动
private final RabbitTemplate rabbitTemplate ;
/**
* 这里先只关注秒杀优惠券的管理 因为普通优惠券的管理 会再添加接口
* @param voucherId
* @return
*/
@Override
public Result seckillVoucher(Long voucherId) throws InterruptedException {
//1. 执行lua脚本
Long userId = UserHolder.getUser().getId();
Long res = (Long) stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(),
userId.toString()
);
//2. 判断结果是否为0
if (res != 0) {
//3.1 否 返回异常信息
if (res == 1)
return Result.fail("优惠券信息不存在");
else if (res == 2)
return Result.fail("秒杀活动暂未开启");
else if (res == 3)
return Result.fail("秒杀活动已经结束");
else if (res == 4)
return Result.fail("库存不足");
else if (res == 5)
return Result.fail("该用户已经购买过优惠券");
}
//3.2 是 说明用户拥有购买资格将优惠券id,用户id和订单id存入阻塞队列,开启异步下单
long orderId = redisIdWorker.nextId("order");
// 创建优惠券订单并写入阻塞队列
VoucherOrder voucherOrder = new VoucherOrder();
voucherOrder.setUserId(UserHolder.getUser().getId());
voucherOrder.setVoucherId(voucherId);
voucherOrder.setId(orderId);
//写入阻塞队列
// orderTasks.add(voucherOrder);
//存入消息队列等待异步消费
rabbitTemplate.convertAndSend("seckill.direct","seckill.order",voucherOrder);// 这里会自动开启消息持久化机制
//4. 返回账单id
return Result.ok(orderId);
}
2.5消费者开启监听机制
RabbitMQ 天然就是事件驱动的,消费者使用 消息监听,不需要主动轮询
创建listener包和相应监听类(注解注册交换机,队列和绑定关系):

@Slf4j
@Component
@RequiredArgsConstructor
public class SpringRabbitListener {
private final VoucherOrderServiceImpl voucherOrderService;
/**
* 消息队列测试
* @param msg
* @throws InterruptedException
*/
// 利用RabbitListener来声明要监听的队列信息
// 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。
// 可以看到方法体中接收的就是消息体的内容
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
/**
* 监听direct.queue1消息队列,如果不存在
* 就创建相关交换机,队列和绑定关系,然后进行消费
* 配置文件里开启了prefetch = 1 线程会抢占式获取消息队列信息
* @param voucherOrder 优惠券订单信息
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1",
durable = "true",
arguments = @Argument(name = "x-queue-mode", value = "lazy")),// 设置消息队列默认为持久化和开启lazy队列模式(消息会直接存入磁盘,避免内存爆仓。)
exchange = @Exchange(name = "seckill.direct", type = ExchangeTypes.DIRECT),//设置交换机名称和类型,默认为DIRECT类型与自动持久化
key = {"seckill.order"} //设定RoutingKey
),
concurrency = "1-10" // 启动动态线程池(最低1个,最多10个)并发消费
)
public void receiveMessage(VoucherOrder voucherOrder, Message message) {
log.debug("接收到的消息 ID:{} ",message.getMessageProperties().getMessageId());
log.debug("线程: {} - \n收到优惠券订单消息:{}",Thread.currentThread().getName(), voucherOrder);
voucherOrderService.handleVoucherOrder(voucherOrder);
}
}
这里的一个RabbitListener注解相当于开启了一个Redis消费者组(Stream),而我相当于开了1个组,并且开了一个大小为10的线程池并发消费。
handleVoucherOrder逻辑(注意我使用的是hash存储,在lua脚本里面判断了当前时间是否到了优惠券的秒杀活动):
/**
* 我就不加锁了 老师的md文档加了锁
* @param order
*/
@Transactional
public void handleVoucherOrder(VoucherOrder order) {
// 这里 1 不在需要分布式锁了 因为前面的lua脚本 已经保证了 只有一个用户线程可以进入创建订单的业务
// 为什么呢? 因为 判断有没有订单和添加订单是原子操作 添加到hash表里面了 ,而且redis本身就是单线程的应用
// 所以同一时刻 只有一个用户线程可以创建订单,而这个用户线程一旦创建了订单,其他用户线程再也无法创建了
// 其次因为这里开启了一个子线程,所以 里面已经没有了userid 和orderid 了
Long userId = order.getUserId();
Long voucherId = order.getVoucherId();
// 这里一定是0
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 2.2.判断是否存在
if (count > 0) {
// 用户已经购买了 其实这里也走不到 一定不会的
log.error("用户已经购买过了");
return;
}
// 3.用户购买,需要扣减库存写入Sql
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1") // set stock = stock -1
.eq("voucher_id", voucherId).gt("stock", 0).update(); //where id = ? and stock > 0
if (!success) {
//扣减库存 理论不会出现
log.error("库存不足");
return ;
}
// 保存订单
save(order);
//throw new RuntimeException("模拟异常,故意的");
// return;
}
在这里需要解释一下,我开启了消费者的可靠性,具体包括:
1.消费者确认机制:
在yaml文件里开启了auto模式:
auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:
- 如果是业务异常,会自动返回
nack; - 如果是消息处理或校验异常,自动返回
reject;
当我们把配置改为auto时,消息处理失败后,会回到RabbitMQ,并重新投递到消费者。
因此这种情况下:当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
当然也可以到这里就停了,不进行失败重试机制和处理策略,这样一旦消费者异常,会一直循环读取消息,直到修改数据库成功(实现的效果和点评老师用Redis实现的一致)
2.失败重试机制:
所以我开启了失败重试机制,设置了最大重试次数为3:
- 消费者在失败后消息没有重新回到MQ无限重新投递,而是在本地重试了3次
- 本地重试3次以后,抛出了
AmqpRejectAndDontRequeueException异常。查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是reject
但是这种情况下
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回reject,消息会被丢弃
所以需要开启一个失败处理策略
3.失败处理策略
在之前的测试中,本地测试达到最大重试次数后,消息会被丢弃。这在某些对于消息可靠性要求较高的业务场景下,显然不太合适了。
因此Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
而且开启stateless: false 即业务里面包含了事务机制,需要回滚,回滚需要设置消息id
业务里面包含了事务机制
方法一:给消息设置id:当 stateless: false 时,Spring AMQP 使用 stateful retry,它依赖于消息的 messageId 进行状态管理(例如记录重试次数)
方法二:设置改用 stateless: true,改为手动开启事务
采用方法一,同时抛弃jdk的消息转换机制,自定义消息转换机制
2.6声明error队列和交换机
定义config包和RabbitMqConfig类:

失败处理策略和消息转换器的实现:
@Configuration
@RequiredArgsConstructor
public class RabbitMqConfig {
@Bean
public MessageConverter messageConverter (){
// 使用Jackson2JsonMessageConverter注入MessageConverter作为消息转换器
Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();
// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息
jjmc.setCreateMessageIds(true);
return jjmc;
}
// 定义错误队列,交换机 和队列 绑定关系
@Bean
public DirectExchange directExchange(){
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){
Map<String, Object> args = new HashMap<>();
args.put("x-queue-mode", "lazy"); // 设置为 Lazy 队列
return new Queue("error.queue",true, false,false,args);
}
@Bean
public Binding binding(DirectExchange directExchange, Queue errorQueue) {
return BindingBuilder.bind(errorQueue).to(directExchange).with("error");// 关键字RouteKey为error
}
/**
* - RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
* - ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
* - RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
* @param
* @return
*/
// 替代原来的失败处理策略
@Bean
public MessageRecoverer messageRecoverer (RabbitTemplate rabbitTemplate){
return new RepublishMessageRecoverer(rabbitTemplate,"error.direct","error");
}
}
以上我们基本实现了与RedisStream流相等的消息队列,主要包括以下特性:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
同时在此基础上有更好的消息确认机制和重试机制,点评实现的重试机制是处理pendding订单,如果处理过程中失败,会一直重试,MQ允许设置重试次数和重试失败后存入error队列
其实可以为error队列设置额外的数据库和监听器处理,这里读者可以自行实现。
3.效果分析
3.1开启异常模拟(模拟订单信息存入数据失败)

在事务里面开启模拟异常测试:

可以看到本地和Redis的库存保持一致都为201,同时目前订单信息为0
然后用postman自测:

显示购买成功,实际上用户有购买资格,然后把信息传递到消息队列,就返回购买成功了

这一段逻辑,所以我们需要查看消息队列的情况:
首先我们的日志:

这端日志有三段(我没全部截取),说明模拟异常重试了三次,重试机制是正确执行了
然后查看redis和数据库,发现redis执行成功,库存-1,然后数据库事务回滚,数据库数据并未改变:

然后查看消息队列(error)

发现error.queue正确存储了执行失败的消息(序列化机制也是正确的),同时也避免了异常业务频繁占用资源的情况(如果Redis的实现方式会一直重试)
但是出现了数据不一致问题,所以针对error.queue必须有额外的处理措施,例如写异常到数据库定期检查,或者为error队列设定监听器处理相关业务,重新执行更新数据库的操作。具体还是要根据业务自己设计,因为这里我是模拟的业务异常,所以我也没有设计对应方法,在处理的时候也要考虑业务幂等性的问题。
同时为了检测消息是否持久化到了文件,将mq进行重启测试(模拟mq宕机):

重启完检测error.queue

发现交换机,队列,以及存入的堆积消息正常存在,说明我们的持久化措施也是正确的!
3.2正常业务压测分析
将Redis信息和数据库恢复成一致(库存201),删除Redis里面多余的订单信息,删除error.queue队列的信息,然后直接开启jmeter进行压测
压测前:
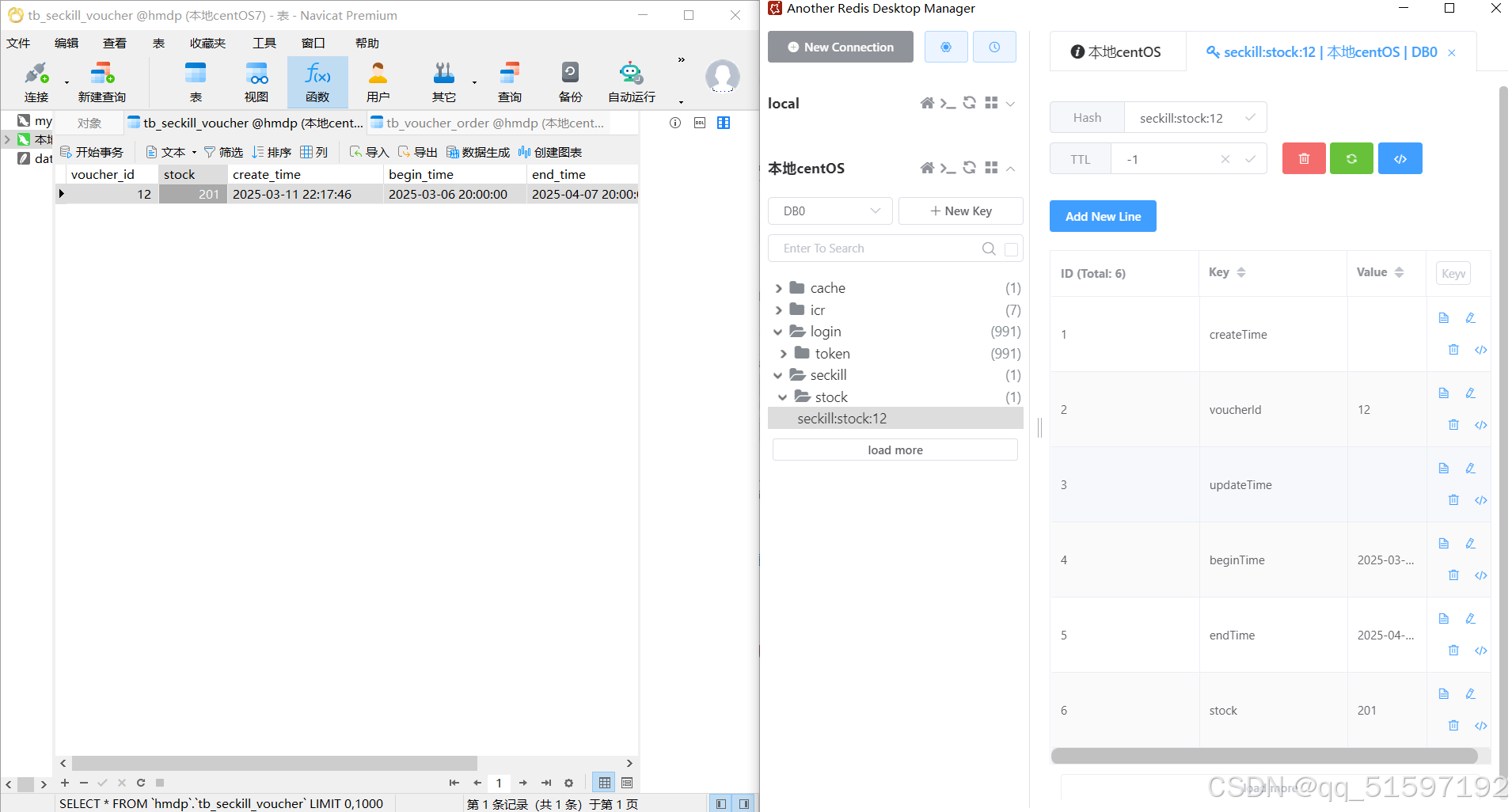
压测后(先预热,再压测):

可以看到效果还是相当好的。
查看redis和mysql:

确实有201个订单生成
消息队列(我没有监测消息队列的性能)

可以看到消息队列也是正常的。
所以这次改造还是十分完美的,而且完全契合老师的redis的实现方案,同时也让我回顾了以下RabbitMQ的相关知识。

















 3683
3683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









