






生成自然且有意义的响应,以应对多模态人类输入,是大型视觉-语言模型(LVLMs)的基本能力。
虽然当前的开源LVLMs在单回合单图像输入等简化场景中表现出色,但在处理多回合、多图像的复杂对话情境时表现不足。
现有的LVLM基准测试主要关注单选问题或短篇回答,无法充分评估LVLMs在实际人机交互应用中的能力。
因此,我们引入了MMDU,一个全面的基准测试,以及MMDU-45k,一个大规模的instruct-tuning数据集,旨在评估和提升LVLMs在多回合多图像对话中的能力。

我们使用聚类算法从开源维基百科中找到相关的图像和文本描述,并通过GPT-4o模型的帮助,由人工标注构建问答对。
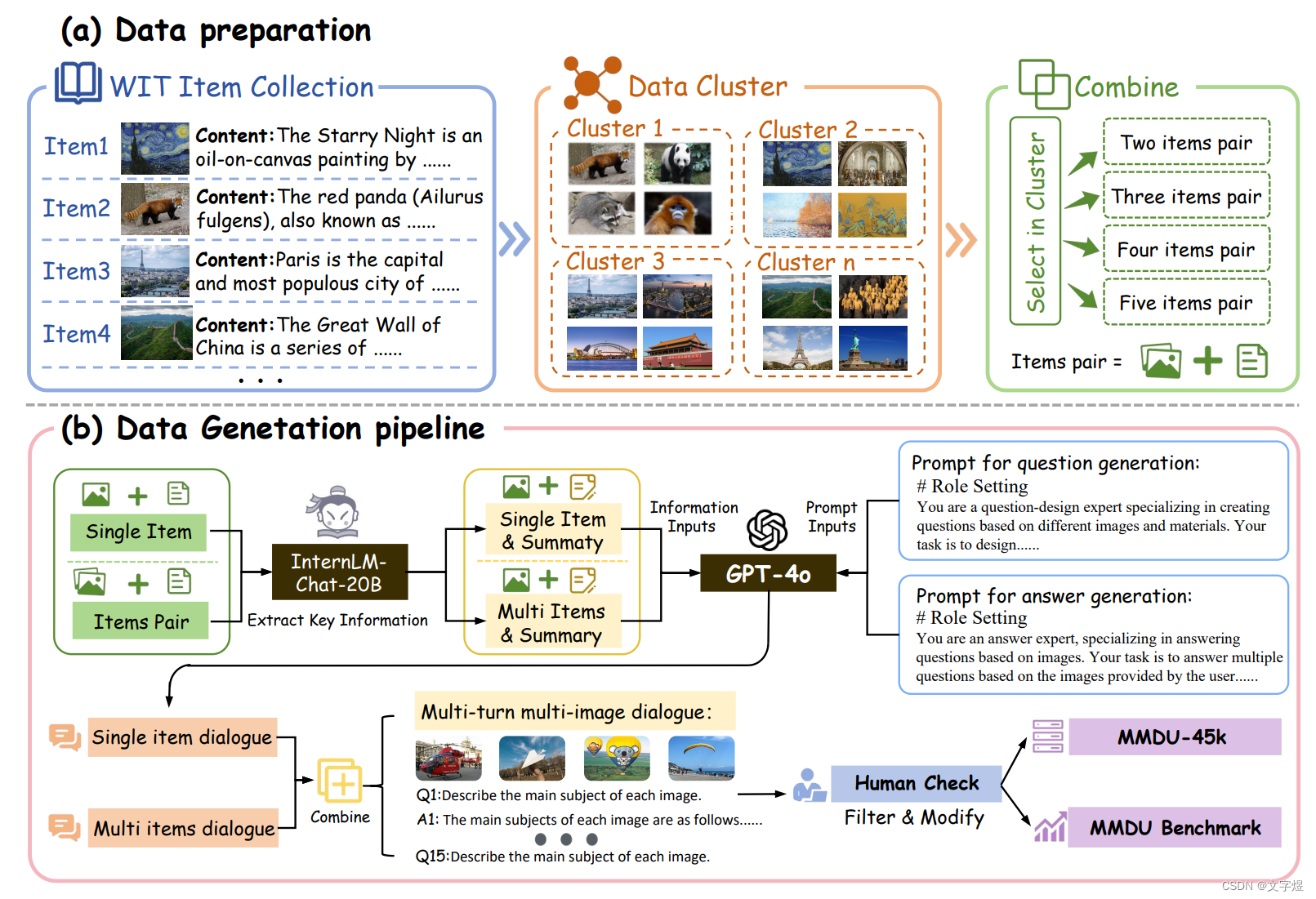
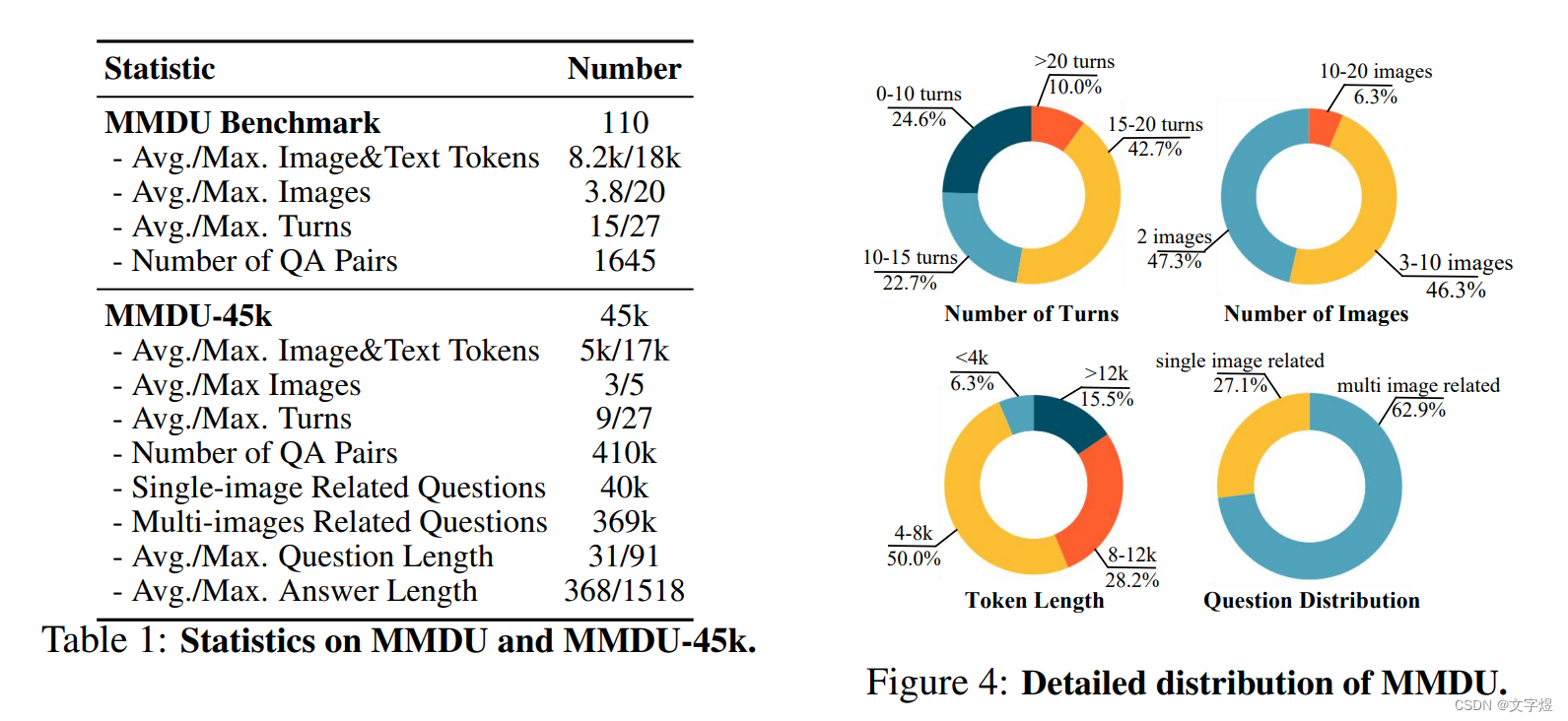
MMDU最多包含18k图像+文本tokens、20张图像和27个回合,这至少是之前基准测试长度的5倍,给当前的LVLMs带来了巨大挑战。
我们对15个具有代表性的LVLMs进行了深入分析,发现开源LVLMs由于缺乏对话instruct-tuning数据,在性能上落后于闭源模型。
我们展示了对开源LVLMs进行MMDU-45k的精细调优显著缩小了这一差距,能够生成更长、更准确的对话,并提高在MMDU和现有基准测试(MMStar: +1.1%、MathVista: +1.5%、ChartQA: +1.2%)上的得分。我们的贡献为缩小当前LVLM模型与实际应用需求之间的差距铺平了道路。

MMDU和MMDU-45k:
Github:https://github.com/Liuziyu77/MMDU/
Homeoage:https://liuziyu77.github.io/MMDU/
Huggingface: https://huggingface.co/datasets/laolao77/MMDU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









