






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
今天带给大家猫眼实时票房的字体反爬,废话不多说直接开始
一、业务逻辑分析
抓包,分析得知为动态数据,点击Fetch/XHR,并点击第一个数据包。
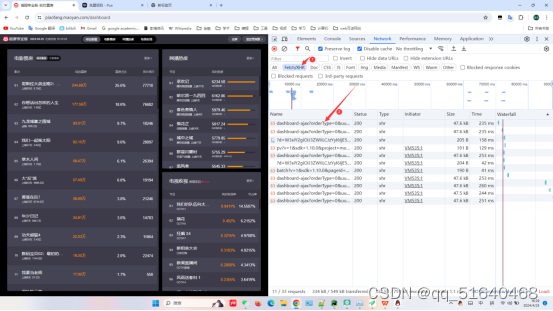
发现目标数据
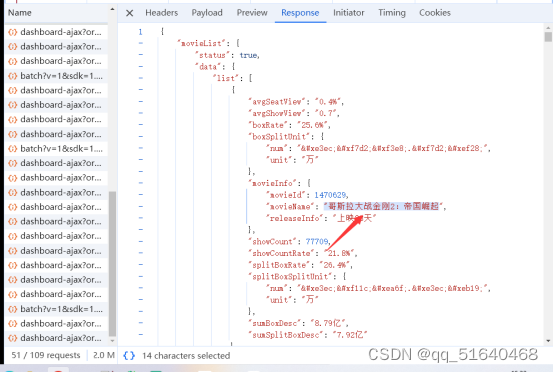
发现为get请求,请求param有
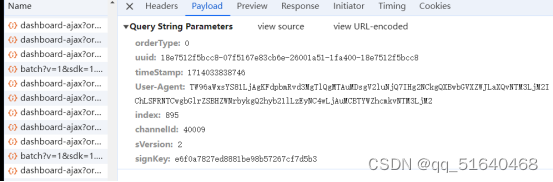
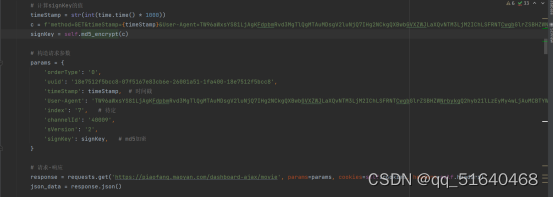
发现只有timeStamp[时间戳],signKey为需要动态生成的参数,进入到对应的js文件,全局搜索signKey,发现一个js文件
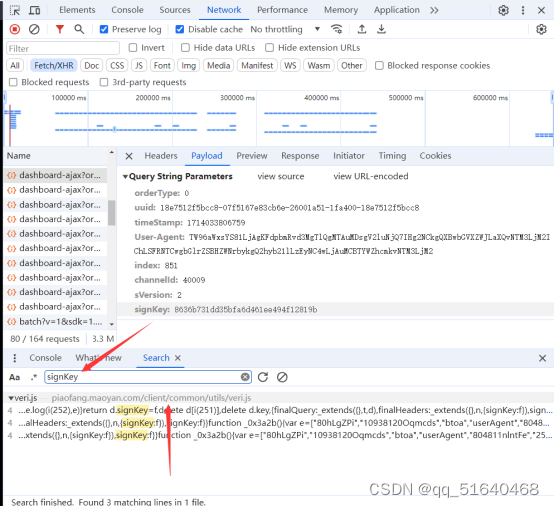
找到signKey,并打上断点,发现断住了
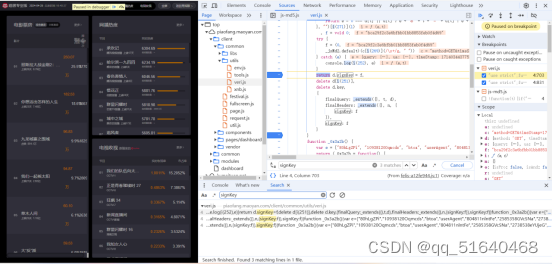
分析发现,划线的代码是signKey的生成位置
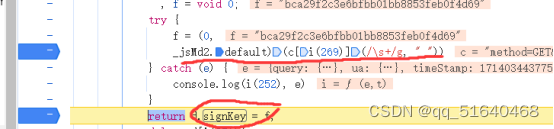
在控制台中输入(0,_jsMd2.default)(ci(269))得到
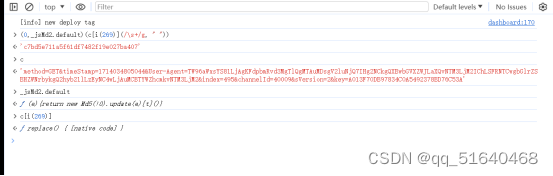
猜测signKey是对c的一个MD5加密,打开MD5加密网站进行验证
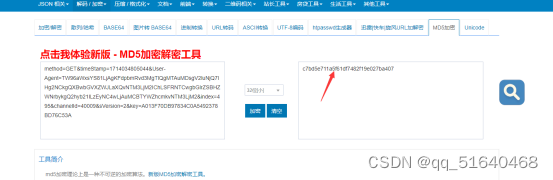
网站加密后为:c7bd5e711a5f61df7482f19e027ba407
猫眼为:‘c7bd5e711a5f61df7482f19e027ba407’
猜测正确,构造请求对象进行请求
分析发现爬下来的数据进行的加密,联想到起点网
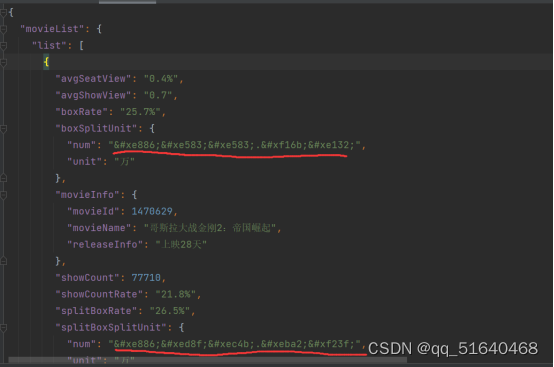
发现数据末尾有字体文件的下载url

在FontCreator中查看字体文件有
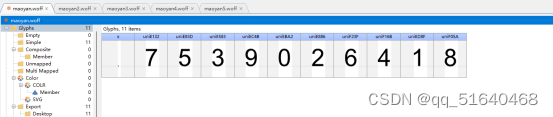
使用第三方库fontTools处理字体文件,生成xml文件发现name是随机的
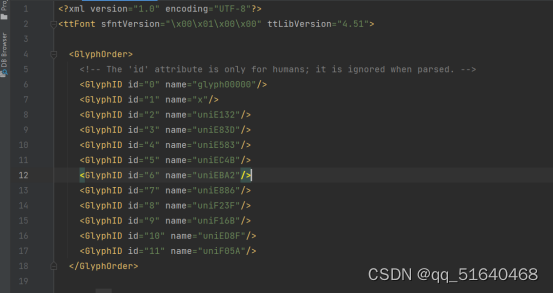
另一个字体文件的xml

下面是起点中文网的,name是有规律的,这极大增加了难度,只能通过坐标了。
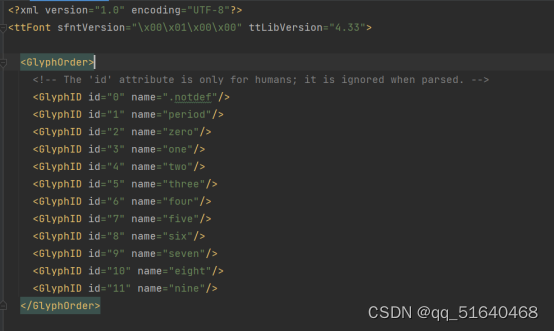
但是我发现坐标变动幅度很大,并不像以前一样小幅变动,呈现倍数的关系,下面以1为例
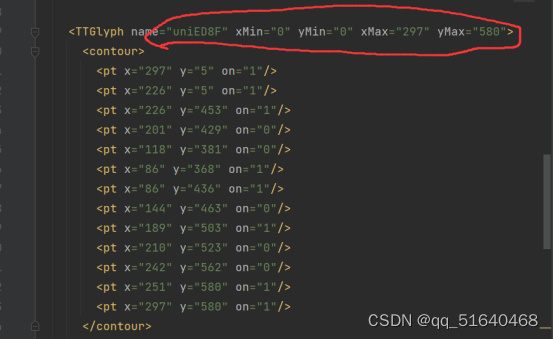
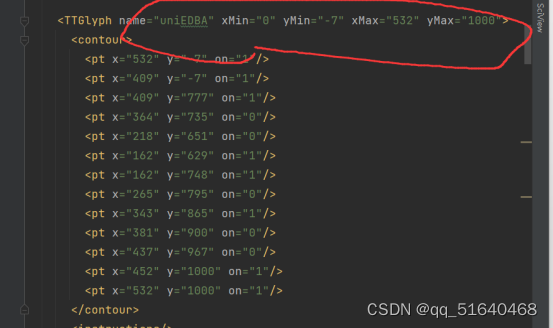
也有小幅变动的情形
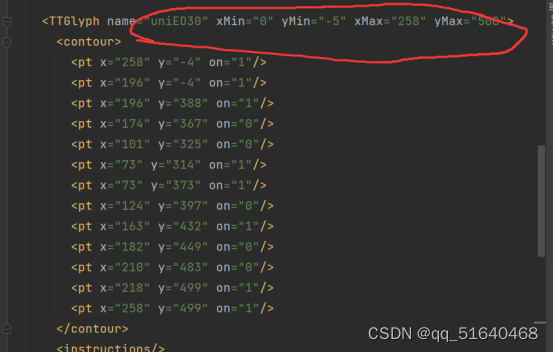
这让我一时难以下手,我想要么先判断一下最大坐标是多少倍,然后除以倍数再通过坐标近似进行识别是否可行,这时我发现了一个近似于1.5倍,让我有点绝望
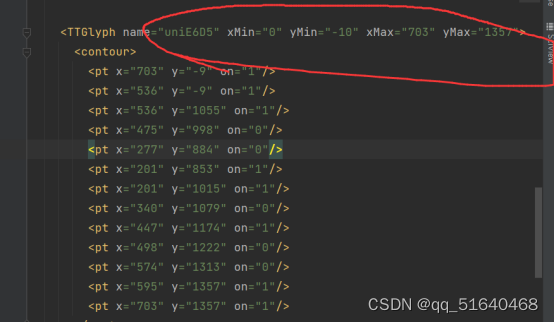
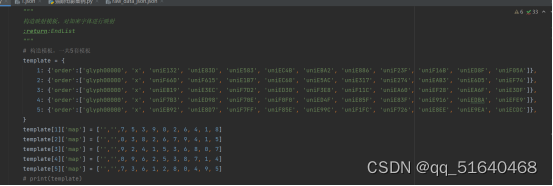
我再一次请求,想看看有没有别的倍数,这时候我发现,字体文件的微妙之处。服务器返回的字体文件只有5种,还句话说每请求一次就会返回预设的5种字体文件中的一种,这下子就好办了,只要建立5个不同的字体映射,然后判断新返回的字体文件属于5种中的哪一种,就可以识别字体了,然后就有了下面的代码。
最后顺利获得了数据
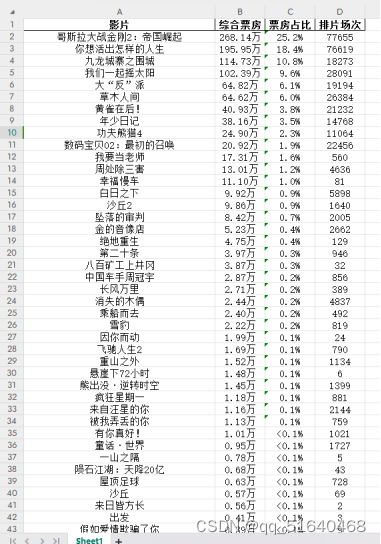
二、代码逻辑
1.引入库
代码如下(示例):
import requests
import time, json, re
import hashlib, jsonpath
from fontTools.ttLib import TTFont
import pandas as pd
2.主体代码
代码如下:
class SendRequest():
# 初始化函数
def __init__(self):
self.cookies = {
'_lxsdk_cuid': '18e7512f5bcc8-07f5167e83cb6e-26001a51-1fa400-18e7512f5bcc8',
'_lxsdk': '18e7512f5bcc8-07f5167e83cb6e-26001a51-1fa400-18e7512f5bcc8',
'_lxsdk_s': '18e7512f5bd-af4-a9a-fc2%7C%7C9',
}
self.headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': '_lxsdk_cuid=18e7512f5bcc8-07f5167e83cb6e-26001a51-1fa400-18e7512f5bcc8; _lxsdk=18e7512f5bcc8-07f5167e83cb6e-26001a51-1fa400-18e7512f5bcc8; _lxsdk_s=18e7512f5bd-af4-a9a-fc2%7C%7C9',
'Pragma': 'no-cache',
'Referer': 'https://piaofang.maoyan.com/dashboard/movie',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'X-FOR-WITH': 'ACsndNv2CnlB52Tbs2GOKRGuHEvx+wD7uhj2pw3IFsaF1yRwYk5jYHv9rgOM/LfkcOKDCQaiq7aOSEYK04vN5vBBorD8whiMGhpNmKKmui4712ZxAakjX/pxSOr2OGSyFrPdcpC7++FhWUpy+pGxw7sHO39yQgGxXxSD7ZfsVXwXobST4J7dFi6IHYj7FdfCuUOZ35tWXBSS4qLbMC92xw==',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
self.key = 'A013F70DB97834C0A5492378BD76C53A'
# md5加密函数
def md5_encrypt(self,input_string):
# 创建一个md5对象
m = hashlib.md5()
# 提供需要加密的数据,必须是bytes类型
m.update(input_string.encode('utf-8'))
# 获取16进制的哈希值
return m.hexdigest()
# 请求函数
@property
def URquest(self):
# 计算signKey的值
timeStamp = str(int(time.time() * 1000))
c = f'method=GET&timeStamp={timeStamp}&User-Agent=TW96aWxsYS81LjAgKFdpbmRvd3MgTlQgMTAuMDsgV2luNjQ7IHg2NCkgQXBwbGVXZWJLaXQvNTM3LjM2IChLSFRNTCwgbGlrZSBHZWNrbykgQ2hyb21lLzEyNC4wLjAuMCBTYWZhcmkvNTM3LjM2&index=978&channelId=40009&sVersion=2&key={self.key}'
signKey = self.md5_encrypt(c)
# 构造请求参数
params = {
'orderType': '0',
'uuid': '18e7512f5bcc8-07f5167e83cb6e-26001a51-1fa400-18e7512f5bcc8',
'timeStamp': timeStamp, # 时间戳
'User-Agent': 'TW96aWxsYS81LjAgKFdpbmRvd3MgTlQgMTAuMDsgV2luNjQ7IHg2NCkgQXBwbGVXZWJLaXQvNTM3LjM2IChLSFRNTCwgbGlrZSBHZWNrbykgQ2hyb21lLzEyMy4wLjAuMCBTYWZhcmkvNTM3LjM2', # 固定
'index': '7', # 待定
'channelId': '40009',
'sVersion': '2',
'signKey': signKey, # md5加密
}
# 请求-响应
response = requests.get('https://piaofang.maoyan.com/dashboard-ajax/movie', params=params, cookies=self.cookies, headers=self.headers)
json_data = response.json()
return json_data
# 处理数据
def DealData(self):
json_data = self.URquest
# 写入json数据,此时为未加工的数据
with open('1.json', 'w', encoding='utf-8')as f:
json.dump(json_data, f, ensure_ascii=False)
# ------------------------调试用↓--------------------------------
# 读出json数据
# with open('1.json', 'r', encoding='utf-8')as f:
# json_data = json.load(f)
# ------------------------调试用↑--------------------------------
#利用jsonpath进行数据解析
movieList = jsonpath.jsonpath(json_data, '$..list')[0]
raw_data = []
for li in movieList:
# 1.影票名
movieName = jsonpath.jsonpath(li, '$..movieName')[0]
# 2.综合票房
# 数字
boxSplit = jsonpath.jsonpath(li, '$..boxSplitUnit.num')[0]
# 单位
Unit = jsonpath.jsonpath(li, '$..boxSplitUnit.unit')[0]
boxSplitUnit = boxSplit + Unit
# 3.票房占比
boxRate = jsonpath.jsonpath(li, '$..boxRate')[0]
# 4.排片场次
showCount = jsonpath.jsonpath(li, '$..showCount')[0]
raw_data.append({"movieName":movieName, "boxSplitUnit":boxSplitUnit, "boxRate":boxRate, "showCount":showCount})
# 获取字体url
fontStyle = jsonpath.jsonpath(json_data, '$..fontStyle')[0].split('url')[-1]
fontStyle_url = 'https://' + re.findall('.*//(.*?).woff".*', fontStyle)[0] + '.woff'
# 获得处理好的数据
return raw_data, fontStyle_url
def Pre_FontDeal(self):
# 保存处理后的数据、字体url
raw_data, fontStyle_url = self.DealData()
json_data = {'List': raw_data, 'FontUrl': fontStyle_url}
# 写入json数据
with open('raw_data_json.json', 'w', encoding='utf-8') as f:
json.dump(json_data, f, ensure_ascii=False)
# ------------------------调试用↓--------------------------------
# # 读出json数据
# with open('raw_data_json.json', 'r', encoding='utf-8')as f:
# json_data = json.load(f)
# ------------------------调试用↑--------------------------------
"""
此时的json数据票房显示为:".万"
需要将其变成:[59526, 60815, 62015, '.', 60491, 59453, '万']
"""
List = jsonpath.jsonpath(json_data, '$..List')[0]
fontStyle_url = jsonpath.jsonpath(json_data, '$..FontUrl')[0]
for li in List:
boxSplitUnit = li['boxSplitUnit']
boxSplitUnit = re.sub('&#', '0', boxSplitUnit).split('.')
end_boxSplitUnit = []
# 整数位
Z = boxSplitUnit[0].split(';')[:-1]
# 小数位
D = boxSplitUnit[1].split(';')
end_boxSplitUnit.extend(Z)
end_boxSplitUnit.append('.')
end_boxSplitUnit.extend(D)
prep_map = []
for num in end_boxSplitUnit:
if num not in ['.', '万']:
prep_map.append(int(eval(num)))
else:
prep_map.append(num)
li['boxSplitUnit'] = prep_map
"""
获得新的数据样式为:
[{'movieName': '哥斯拉大战金刚2:帝国崛起', 'boxSplitUnit': [59526, 60815, 62015, '.', 60491, 59453, '万'], 'boxRate': '25.9%', 'showCount': 77761},
{'movieName': '你想活出怎样的人生', 'boxSplitUnit': [60815, 59453, 62015, '.', 61803, 60322, '万'], 'boxRate': '18.7%', 'showCount': 76757},
{'movieName': '我们一起摇太阳', 'boxSplitUnit': [61530, 60322, '.', 60322, 59526, '万'], 'boxRate': '9.5%', 'showCount': 28108}.......
"""
New_List = List
# print(New_List)
return New_List, fontStyle_url
def FontDeal(self):
"""
构造映射模板,对加密字体进行映射
:return:EndList
"""
# 构造模板,一共5套模板
template = {
1: {'order':['glyph00000', 'x', 'uniE132', 'uniE83D', 'uniE583', 'uniEC4B', 'uniEBA2', 'uniE886', 'uniF23F', 'uniF16B', 'uniED8F', 'uniF05A']},
2: {'order':['glyph00000', 'x', 'uniF66D', 'uniF615', 'uniE1B7', 'uniEC68', 'uniE5AC', 'uniE317', 'uniE274', 'uniEAB3', 'uniE6D5', 'uniEF74']},
3: {'order':['glyph00000', 'x', 'uniEB19', 'uniE3EC', 'uniF7D2', 'uniED30', 'uniF3E8', 'uniF11C', 'uniEA60', 'uniEF28', 'uniEA6F', 'uniE3DF']},
4: {'order':['glyph00000', 'x', 'uniF7B3', 'uniED98', 'uniF70E', 'uniF0F0', 'uniED4F', 'uniE85F', 'uniE83F', 'uniE916', 'uniEDBA', 'uniEFE9']},
5: {'order':['glyph00000', 'x', 'uniEB92', 'uniE8D7', 'uniF7FF', 'uniF85E', 'uniE99C', 'uniF1FC', 'uniF726', 'uniE8EE', 'uniE9EA', 'uniECDC']},
}
template[1]['map'] = ['','',7, 5, 3, 9, 0, 2, 6, 4, 1, 8]
template[2]['map'] = ['','',0, 3, 8, 2, 6, 7, 9, 4, 1, 5]
template[3]['map'] = ['','',9, 2, 4, 1, 5, 3, 6, 8, 0, 7]
template[4]['map'] = ['','',0, 9, 6, 2, 5, 3, 8, 7, 1, 4]
template[5]['map'] = ['','',7, 3, 6, 1, 2, 8, 0, 4, 9, 5]
# print(template)
New_List, fontStyle_url = self.Pre_FontDeal()
# print(New_List[0])
# 写入字体文件
bytes_data = requests.get(fontStyle_url).content
with open('maoyan_new.woff', 'wb') as f:
f.write(bytes_data)
# 打开字体文件
font_obj_new = TTFont('maoyan_new.woff') # 打开本地字体文件maoyan.woff
font_obj_new.saveXML('maoyan_new.xml') # 将woff文件转化成xml格式并保存到本地,主要是方便我们查看内部数据结构
cmap_num = 0
"""
通过getGlyphOrder()的值,判断用何种模板
"""
for k,v in template.items():
if v['order'] == font_obj_new.getGlyphOrder():
cmap_num = k
else:
continue
print("===============正在使用的是模板%s===============" % cmap_num)
# 映射1
cmap1 = font_obj_new.getBestCmap() # 获取最新获取的字体映射关系
# 映射2
order = template[cmap_num]['order'] # 构造所选模板的映射关系
map = template[cmap_num]['map'] # 构造所选模板的映射关系
cmap2 = dict(zip(order, map))
# 进行映射生成最终数据
for li in New_List:
boxSplitUnit = li['boxSplitUnit']
results = []
for i in boxSplitUnit:
try:
result = cmap2[cmap1[i]]
results.append(str(result))
except:
results.append(i)
DealedBoxSplitUnit = ''.join(results)
li['boxSplitUnit'] = DealedBoxSplitUnit
EndList = New_List
return EndList
# print(max(font_obj1['glyf']["uniE583"].coordinates))
def SaveDataToExcel(self):
EndList = self.FontDeal()
insert_data = []
# 拼接最终保存数据
for li in EndList:
insert_data.append([li['movieName'], li['boxSplitUnit'], li['boxRate'], li['showCount']])
df = pd.DataFrame(insert_data, columns=['影片', '综合票房', '票房占比', '排片场次'])
# 形成excel文件
df.to_excel('data.xlsx', index=False)
return EndList
if __name__ == '__main__':
# 获取当前时间的时间戳
timestamp = time.time()
# 将时间戳转换为结构化时间
struct_time = time.localtime(timestamp)
# 格式化结构化时间为指定格式
formatted_time = time.strftime("%Y/%m/%d %H:%M:%S", struct_time)
# 输出格式化后的时间戳
print(f'{formatted_time} 的数据:')
t = SendRequest()
EndList = t.SaveDataToExcel()
print(EndList)
总结
以上就是今天要讲的内容,本文仅仅简单介绍了猫眼实时票房的反爬。

















 2302
2302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









