







名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪)
本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
0、思维导图
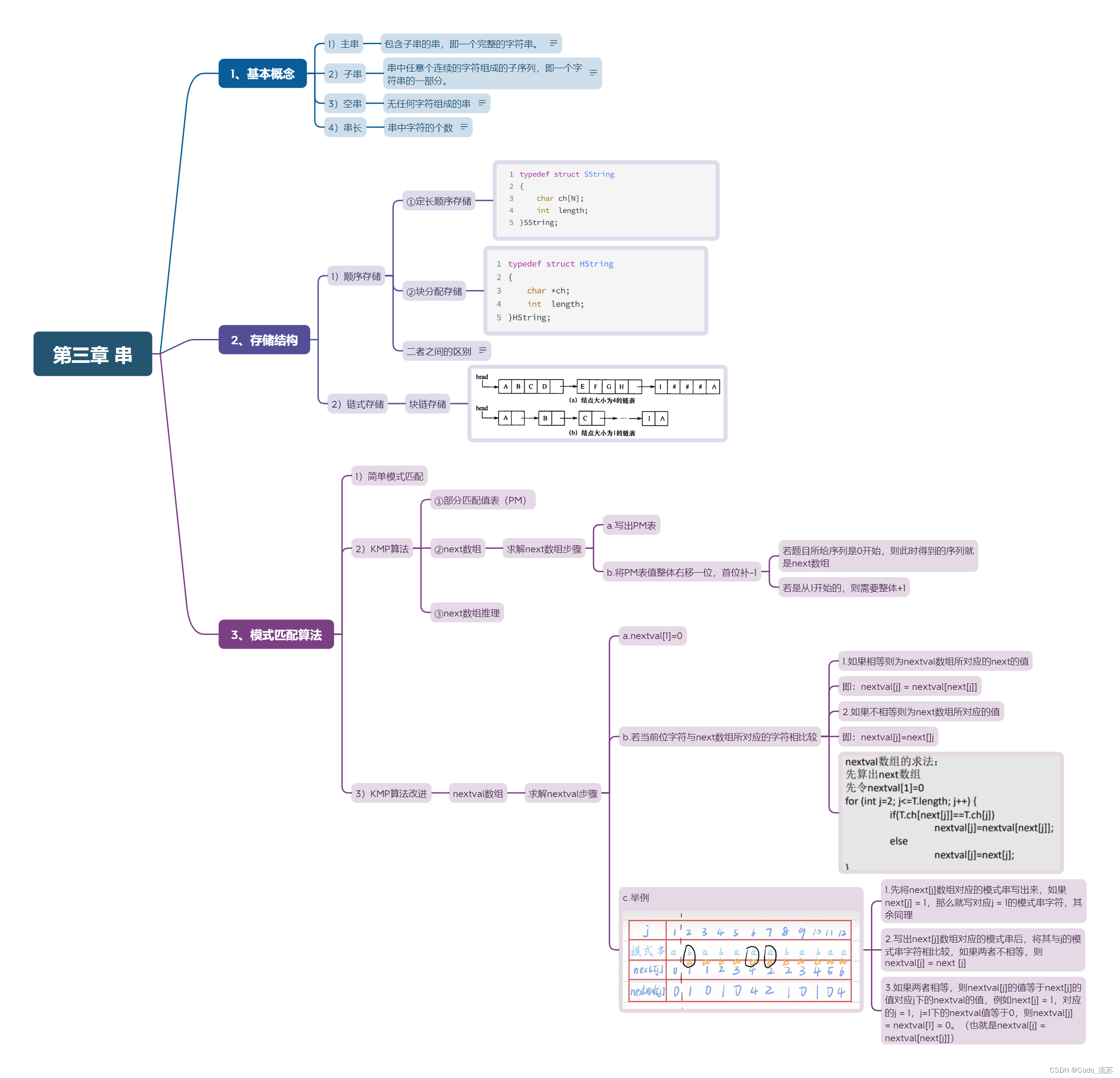
1、基本概念
1)主串
-
包含子串的串,即一个完整的字符串。
例如:“数据结构"是一个主串,它包含了"数”、“据”、“结”、"构"等子串。
2)子串
-
串中任意个连续的字符组成的子序列,即一个字符串的一部分。
例如:“数据结构"的子串有"数”、“据”、“结”、“构”、“数据”、"结构"等。
“abcd"的子串有"a”、“b”、“c”、"d"等。
3)空串
-
无任何字符组成的串
空串的长度为零,用""表示。例如,""是一个空串。
4)串长
-
串中字符的个数
为一个非负整数,用n表示。例如,"abcd"的串长为4。
2、存储结构
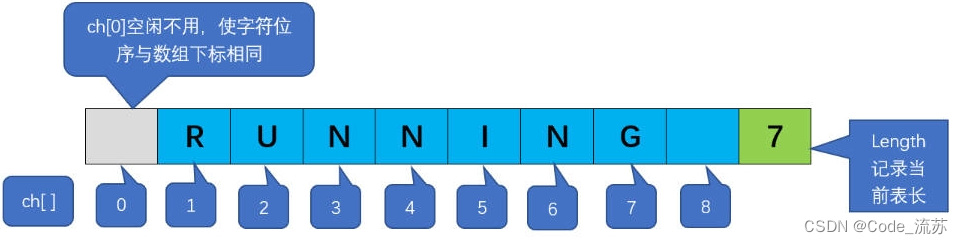
1)顺序存储
顺序存储结构使用一段连续的存储单元一次存放串中的字符。这种结构类似于数组的存储方式,每个字符占用一个存储单元。
在串的顺序存储结构中,有两种常见的实现方式:定长顺序存储和块分配存储。这两种方式都是在连续的存储单元中存放字符串,但它们在管理这些存储单元的方式上有所不同。
1️⃣定长顺序存储
typedef struct SString
{
char ch[N];
int length;
}SString;
在定长顺序存储中,每个字符串都被分配一个固定大小的存储区域。这个固定大小通常是根据应用场景中字符串的最大长度来设定的。
-
优点:
- 存取简单快捷,可以直接通过索引访问任何一个字符。
- 存储结构固定,便于管理。
-
缺点:
- 不够灵活。如果分配的存储空间大于实际需要,会造成存储空间的浪费;如果小于实际需要,则无法存放更长的字符串。
- 调整字符串长度时(如拼接、截断操作),可能需要复制整个字符串到新的存储区域,效率较低。
2️⃣块分配存储
typedef struct Hstring
{
char *ch;
int length;
}Hstring;
块分配存储(也称为堆分配存储)中,字符串被存储在动态分配的内存块中。每个字符串可以根据需要分配合适大小的存储空间。
-
优点:
- 灵活高效地利用内存。仅根据字符串的实际长度分配存储空间,避免了空间浪费。
- 易于处理长度变化较大的字符串操作,如拼接、修改等。
-
缺点:
- 存储管理相对复杂。需要动态分配和释放内存,可能导致内存碎片。
- 相较于定长存储,访问字符时可能略微慢一些,因为可能涉及到指针跳转。
3️⃣区别
- 定长顺序存储适用于字符串长度固定或变化不大的应用场景,如固定长度的记录处理。
- 块分配存储则适用于字符串长度变化较大的场景,特别是那些需要频繁进行字符串拼接、截断等操作的应用。
2)链式存储
链式存储结构通过一系列的节点来存储串中的字符,每个节点包含一个字符和指向下一个节点的指针。这种结构类似于链表。
3、模式匹配算法
1)简单模式匹配
简单模式匹配算法(也称为朴素模式匹配算法或暴力模式匹配算法)是一种最基本的字符串搜索方法,它尝试在主字符串(通常表示为 S S S)中查找一个子串(称为模式串,表示为 P P P),并返回模式串在主字符串中的位置。
1️⃣算法步骤
- 初始化:令主字符串的位置索引为 i = 0 i=0 i=0,模式串的位置索引为 j = 0 j=0 j=0。
- 匹配:比较主字符串的第
i
i
i 个字符和模式串的第
j
j
j 个字符。
- 如果相等, i i i 和 j j j 同时加一,继续比较下一个字符。
- 如果不相等,将 i i i 回溯到上一次匹配开始的下一个字符位置,即 i = i − j + 1 i = i - j + 1 i=i−j+1,并将 j j j 重置为 0 0 0,重新开始匹配。
- 重复:重复步骤2,直到模式串完全匹配,或主字符串的字符比较完毕。
- 返回结果:如果模式串 P P P 在主字符串 S S S 中完全匹配,返回模式串开始匹配的位置;否则,返回 − 1 -1 −1 或其他表示不匹配的值。
2️⃣举例
假设我们有主字符串 S = "ABCDABCD" S = \text{"ABCDABCD"} S="ABCDABCD" 和模式串 P = "ABC" P = \text{"ABC"} P="ABC":
- 第一次比较 S [ 0 … 2 ] S[0\ldots2] S[0…2] 与 P [ 0 … 2 ] P[0\ldots2] P[0…2],匹配成功。
- 如果我们寻找下一个匹配,当 S [ 1 … 3 ] S[1\ldots3] S[1…3] 与 P [ 0 … 2 ] P[0\ldots2] P[0…2] 不匹配时, i i i 会回溯到 2 2 2(即 1 − 0 + 1 1 - 0 + 1 1−0+1), j j j 重置为 0 0 0,然后继续匹配。
2)KMP算法
1️⃣概念
KMP算法(Knuth-Morris-Pratt字符串搜索算法),是一种高效的字符串匹配算法。它在不匹配时,通过已匹配的部分信息避免从头开始搜索,从而提高匹配效率。KMP算法的核心是构建一个部分匹配表(也称为"失败函数"或"前缀函数"),用以在字符串匹配过程中跳过不必要的比较。
部分匹配表的构建基于以下概念:
- 前缀:对于字符串 S S S, S S S 的前缀是从 S S S 的开头开始的任何子字符串。
- 后缀:对于字符串 S S S, S S S 的后缀是从 S S S 的结尾结束的任何子字符串。
部分匹配表为每个位置 i i i 计算一个值,该值表示字符串从头开始到位置 i i i 的子字符串中,有多长的相同前缀和后缀。这个值被用于当字符不匹配时,确定下一步匹配的起始位置。
2️⃣举例
例如,对于字符串 “ABCDABD”,其部分匹配表如下:
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | A | B | D |
| 值 | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
在实际的字符串搜索过程中,KMP算法使用这个表来决定在不匹配时下一步应该跳过多少个字符。这样,算法避免了从主字符串的每个字符开始匹配,显著提高了搜索效率。
3️⃣补充(PM和next数组求解步骤)
①部分匹配值表(PM)
②next数组求解步骤
-
a.写出PM表
-
b.将PM表值整体右移一位,首位补-1
-
若题目所给序列是0开始,则此时得到的序列就是next数组
-
若是从1开始的,则需要整体+1
-
3)KMP算法改进
nextval数组求解步骤
-
a.nextval[1]=0
-
b.若当前位字符与next数组所对应的字符相比较
-
如果相等则为nextval数组所对应的next的值
-
即:nextval[j] = nextval[next[j]]
-
如果不相等则为next数组所对应的值
-
即:nextval[j]=next[]j
-
-
c.具体步骤如下:
-
1.先将next[j]数组对应的模式串写出来,如果next[j] = 1,那么就写对应j = 1的模式串字符,其余同理
-
2.写出next[j]数组对应的模式串后,将其与j的模式串字符相比较,如果两者不相等,则nextval[j] = next [j]
-
3.如果两者相等,则nextval[j]的值等于next[j]的值对应j下的nextval的值,例如next[j] = 1,对应的j = 1,j=1下的nextval值等于0,则nextval[j] = nextval[1] = 0。(也就是nextval[j] = nextval[next[j]])
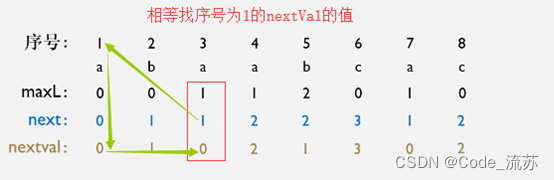
-
C语言实现KMP算法求解next数组和nextval数组:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
void computeLPSArray(char* pat, int M, int* lps) {
int len = 0;
lps[0] = 0;
int i = 1;
while (i < M) {
if (pat[i] == pat[len]) {
len++;
lps[i] = len;
i++;
} else {
if (len != 0) {
len = lps[len - 1];
} else {
lps[i] = 0;
i++;
}
}
}
}
void computeNextValArray(char* pat, int M, int* lps, int* nextval) {
nextval[0] = -1;
for (int i = 1; i < M; i++) {
int j = lps[i - 1];
while (j >= 0 && pat[i] != pat[j]) {
j = nextval[j];
}
nextval[i] = j + 1;
}
}
void printArray(int* arr, int size, string name) {
cout<<name<<":"<<endl;
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
void KMPSearch(char* pat, char* txt) {
int M = strlen(pat);
int N = strlen(txt);
int* lps = (int*)malloc(M * sizeof(int));
int* nextval = (int*)malloc(M * sizeof(int));
computeLPSArray(pat, M, lps);
computeNextValArray(pat, M, lps, nextval);
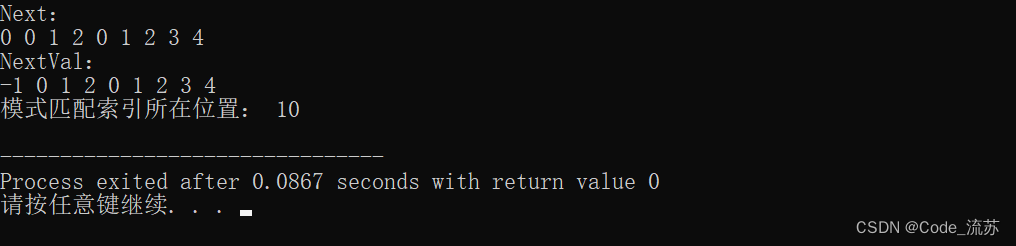
// 打印lps (next数组) 和 nextval数组
printArray(lps, M, "Next");
printArray(nextval, M, "NextVal");
int i = 0;
int j = 0;
while (i < N) {
if (pat[j] == txt[i]) {
j++;
i++;
}
if (j == M) {
printf("模式匹配索引所在位置: %d \n", i - j);
j = lps[j - 1];
} else if (i < N && pat[j] != txt[i]) {
if (j != 0) {
j = nextval[j]; // 使用nextval优化跳转
} else {
i = i + 1;
}
}
}
free(lps);
free(nextval);
}
int main() {
char txt[] = "ABABDABACDABABCABAB";
char pat[] = "ABABCABAB";
KMPSearch(pat, txt);
return 0;
}
上述内容笔记部分图片来源网络,侵删。
参考内容:
1.《王道数据结构》
2.计算next和nextVal值
3.数据结构电子讲义Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder)
点赞加关注,收藏不迷路!本篇文章对你有帮助的话,还请多多点赞支持!
















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











