







 超级会员免费看
超级会员免费看
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: Python星球日记 - Q&A:入门篇常见问题及答疑(建议收藏)
欢迎来到Python星球日记系列的🪐的答疑篇!

一、面向对象编程常见问题
1. 类与对象的基本概念困惑
问题:我理解函数式编程,但面向对象的概念让我感到困惑。什么时候应该使用类?self参数是什么意思?
回答:面向对象编程(OOP)确实是许多Python初学者的一个障碍,但掌握它能让你的代码更加模块化和可维护。让我们从核心概念开始梳理。
类(Class) 本质上是一个蓝图,它定义了一种新的数据类型,包含属性(数据)和方法(函数)。而对象(Object) 是类的一个实例,它基于类的蓝图创建,拥有自己的数据。
想象一个类就像一个饼干模具,而对象就是用这个模具制作的不同饼干。虽然它们的形状相同(共享相同的方法),但每个饼干可以有不同的装饰(不同的属性值)。
# 定义一个简单的类
class Dog:
# 初始化方法(构造函数)
def __init__(self, name, age):
self.name = name # 实例属性
self.age = age
# 实例方法
def bark(self):
return f"{self.name} says woof!"
def birthday(self):
self.age += 1
return f"{self.name} is now {self.age} years old"
# 创建类的实例(对象)
my_dog = Dog("Rex", 3)
your_dog = Dog("Buddy", 2)
# 访问属性和调用方法
print(my_dog.name) # 输出: Rex
print(your_dog.bark()) # 输出: Buddy says woof!
print(my_dog.birthday()) # 输出: Rex is now 4 years old
现在,让我们解答几个关键问题:
什么是self参数?
self是Python类中每个实例方法的第一个参数,它引用调用该方法的对象实例。当你调用my_dog.bark()时,Python实际上在背后将其转换为Dog.bark(my_dog),因此self参数接收到的是my_dog对象。
这允许方法访问和修改该特定实例的属性和执行针对该实例的操作。self不是一个Python关键字,你可以使用其他名称,但按惯例应该使用self。
什么时候应该使用类?
类在以下情况特别有用:
-
当你需要同时跟踪数据和行为时:如果你需要某些数据和操作这些数据的函数,类是理想的选择。
-
表示现实世界的实体:如用户、产品、帖子等,这些通常有多个属性和相关行为。
-
需要创建多个相似但不同的对象:如游戏中的多个角色,每个都有不同的名称、生命值等。
-
实现代码重用和封装:类帮助你组织代码,隐藏细节,并通过继承重用功能。
# 不使用类的写法
user1_name = "Alice"
user1_email = "alice@example.com"
user1_posts = []
def add_post(user_posts, content):
user_posts.append(content)
def display_profile(name, email, posts):
print(f"Name: {name}")
print(f"Email: {email}")
print(f"Posts: {len(posts)}")
# 使用类的写法
class User:
def __init__(self, name, email):
self.name = name
self.email = email
self.posts = []
def add_post(self, content):
self.posts.append(content)
def display_profile(self):
print(f"Name: {self.name}")
print(f"Email: {self.email}")
print(f"Posts: {len(self.posts)}")
# 创建使用
user1 = User("Alice", "alice@example.com")
user1.add_post("Hello world!")
user1.display_profile()
使用类的版本更加组织化,所有相关的数据和行为都封装在一起,对于每个用户都可以创建单独的实例,同时保持代码的结构一致。
类与函数的选择
- 如果你只需要执行一个特定操作而不需要维护状态,使用函数。
- 如果你需要将数据和行为组合在一起,跟踪状态,或创建多个具有相似行为但不同数据的实例,使用类。
记住,Python允许你灵活地混合函数式和面向对象的编程风格,选择最适合你问题的工具即可。
2. 继承与多态的应用
问题:我了解了基本的类和对象,但继承和多态这些概念让我困惑。它们有什么作用,如何正确使用?
回答:继承和多态是面向对象编程的两个强大概念,它们帮助我们实现代码重用和灵活性。让我们通过实例来理解这些概念。
继承(Inheritance)
继承允许一个类(子类)获取另一个类(父类)的属性和方法。这促进了代码重用,并建立了类之间的层次结构。
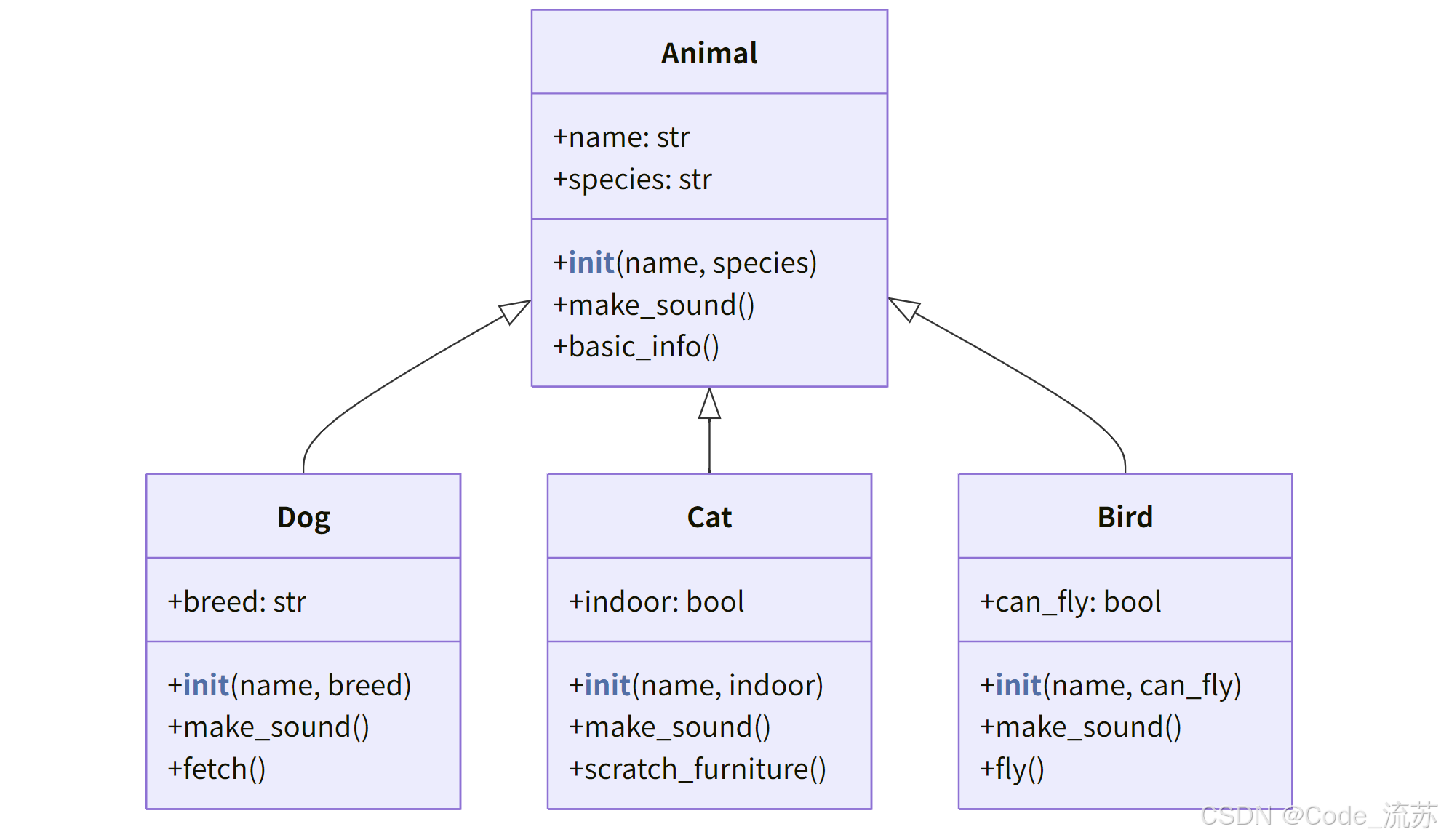
# 父类(基类)
class Animal:
def __init__(self, name, species):
self.name = name
self.species = species
def make_sound(self):
print("一些动物声音")
def basic_info(self):
return f"{self.name} 是一只 {self.species}"
# 子类(派生类)
class Dog(Animal):
def __init__(self, name, breed):
# 调用父类的初始化方法
super().__init__(name, species="狗")
self.breed = breed
# 重写父类方法
def make_sound(self):
print("汪汪!")
# 添加新方法
def fetch(self):
return f"{self.name} 捡回了球!"
# 另一个子类
class Cat(Animal):
def __init__(self, name, indoor=True):
super().__init__(name, species="猫")
self.indoor = indoor
def make_sound(self):
print("喵喵!")
def scratch_furniture(self):
return f"{self.name} 抓挠了家具!"
# 使用这些类
my_dog = Dog("小黑", "拉布拉多")
my_cat = Cat("咪咪")
print(my_dog.basic_info()) # 来自父类的方法
my_dog.make_sound() # 重写的方法
print(my_dog.fetch()) # 子类特有的方法
print(my_cat.basic_info())
my_cat.make_sound()
print(my_cat.scratch_furniture())
继承的关键优势:
- 代码重用:子类继承父类的所有功能,不需要重复编写。
- 层次结构:可以创建类的分类系统,表示"是一种"的关系。
- 可扩展性:可以通过扩展现有类来添加新功能,而无需修改原始代码。
Python中的继承技巧:
- 使用
super():调用父类的方法是最佳实践,避免直接使用父类名。 - 多重继承:Python支持多重继承(一个类可以继承多个类),但应谨慎使用以避免复杂性。
- 方法解析顺序(MRO):Python使用C3线性化算法来决定多重继承中的方法调用顺序。
多态(Polymorphism)
多态允许使用不同类的对象,但通过相同的接口与它们交互。这提供了更大的灵活性和可扩展性。
多态有两种主要形式:
- 运行时多态:通过方法重写实现
- 编译时多态:通过方法重载实现(Python不直接支持,但可以通过默认参数等模拟)
# 继续使用上面的Animal, Dog, Cat类示例
# 多态的强大之处
def pet_sounds(animal):
# 不需要知道动物的具体类型
animal.make_sound()
# 调用同一函数,传入不同类型的对象
animals = [
Dog("小黑", "德牧"),
Cat("咪咪"),
Dog("小白", "柴犬")
]
# 每个动物都会发出自己的声音
for animal in animals:
print(animal.basic_info())
pet_sounds(animal)
多态的关键优势:
- 灵活性:可以编写适用于父类对象的代码,后续添加新的子类不需要修改该代码。
- 抽象:不需要关心对象的具体类型,只需关心它们能做什么。
- 可扩展性:可以轻松添加新的子类,而无需修改使用这些类的现有代码。
Python中的"鸭子类型":
Python还支持一种称为"鸭子类型"的概念:如果一个对象行为像鸭子(有鸭子应有的方法),我们就把它当做鸭子,而不关心它的实际类型。
class NotAnAnimal:
def __init__(self, name):
self.name = name
def make_sound(self):
print("我不是动物,但我也能发声!")
def basic_info(self):
return f"{self.name} 是一个奇怪的东西"
# 即使NotAnAnimal不是Animal的子类,它也能与pet_sounds函数一起工作
strange_thing = NotAnAnimal("怪物")
pet_sounds(strange_thing) # 可以工作,因为它有make_sound方法
在Python中,我们更关心对象能做什么(它有什么方法),而不是它是什么(它的类型)。这种灵活性是Python的关键特性之一。
何时使用继承与多态?
- 当你有明确的"是一种"关系时使用继承(例如,狗是一种动物)
- 当你想要多个类通过相同接口工作,但有不同行为时使用多态
- 当你想要重用代码并创建类的层次结构时使用继承
- 避免过度使用继承,有时组合更合适("组合优于继承"原则)
理解这些概念可以帮助你设计更灵活、可维护的代码结构,特别是在处理复杂问题时。
3. 类方法、静态方法与实例方法的区别
问题:我在Python类中看到了@classmethod和@staticmethod装饰器,它们与普通的实例方法有什么区别?什么情况下应该使用它们?
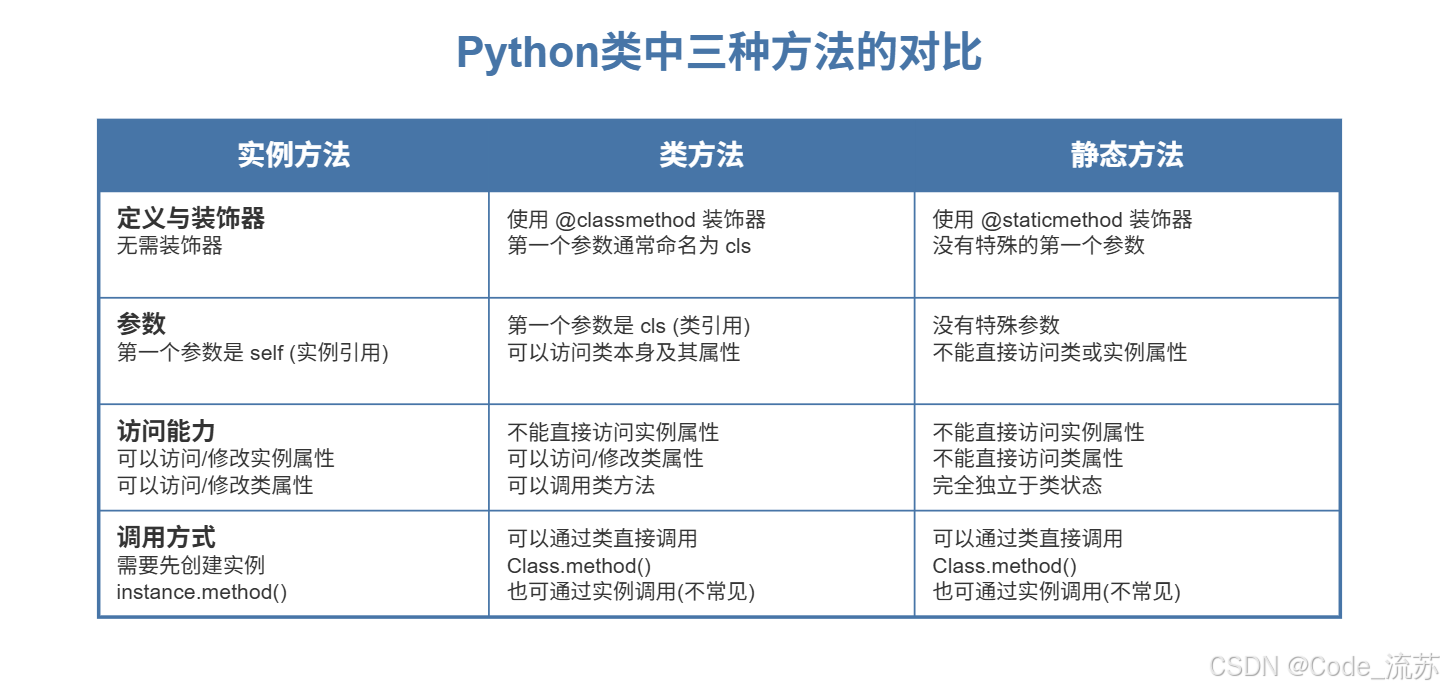
回答:Python类中的三种方法类型(实例方法、类方法、静态方法)各有特点和使用场景。让我详细解释它们的区别和适用场景:
1. 实例方法(Instance Method)
这是最常见的方法类型,第一个参数是self,它引用调用该方法的特定实例。
class Student:
def __init__(self, name, grade):
self.name = name
self.grade = grade
# 实例方法 - 操作特定实例的数据
def get_grade(self):
return f"{self.name}'s grade is {self.grade}"
def improve_grade(self, amount):
self.grade += amount
return f"{self.name}'s grade improved to {self.grade}"
# 使用实例方法
student = Student("Alice", 85)
print(student.get_grade()) # Alice's grade is 85
print(student.improve_grade(5)) # Alice's grade improved to 90
特点与用途:
- 可以通过
self访问和修改实例属性 - 能够访问类属性
- 主要用于对特定实例进行操作
- 需要创建类的实例才能调用
使用场景:当方法需要与实例的状态交互时,使用实例方法。
2. 类方法(Class Method)
类方法通过@classmethod装饰器定义,第一个参数通常命名为cls,它引用类本身而非实例。
class Student:
school_name = "Python高级中学" # 类属性
student_count = 0
def __init__(self, name, grade):
self.name = name
self.grade = grade
Student.student_count += 1
# 实例方法
def get_grade(self):
return f"{self.name}'s grade is {self.grade}"
# 类方法 - 操作类的数据
@classmethod
def get_school_name(cls):
return cls.school_name
@classmethod
def change_school_name(cls, new_name):
cls.school_name = new_name
return f"School name changed to {cls.school_name}"
@classmethod
def get_student_count(cls):
return f"Total students: {cls.student_count}"
# 类方法作为替代构造函数
@classmethod
def from_string(cls, data_string):
name, grade = data_string.split('-')
return cls(name, int(grade))
# 使用类方法
print(Student.get_school_name()) # Python高级中学
print(Student.change_school_name("Python精英学院")) # School name changed to Python精英学院
# 创建实例
student1 = Student("Bob", 78)
student2 = Student("Carol", 92)
print(Student.get_student_count()) # Total students: 2
# 使用替代构造函数
student3 = Student.from_string("David-88")
print(student3.get_grade()) # David's grade is 88
特点与用途:
- 可以访问和修改类属性
- 不能直接访问实例属性(无
self参数) - 可以在不创建实例的情况下调用
- 可以用作替代构造函数
- 传递给它的总是类,而不是实例
使用场景:
- 需要访问或修改类的状态时(类属性)
- 创建工厂方法,提供多种方法来创建实例
- 需要类级别的功能,不依赖于任何特定实例
3. 静态方法(Static Method)
静态方法通过@staticmethod装饰器定义,不接收特殊的第一个参数。它们本质上是恰好位于类命名空间中的普通函数。
class MathUtils:
# 静态方法 - 不访问实例或类的状态
@staticmethod
def add(a, b):
return a + b
@staticmethod
def multiply(a, b):
return a * b
@staticmethod
def is_prime(n):
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
# 使用静态方法
print(MathUtils.add(5, 3)) # 8
print(MathUtils.multiply(4, 7)) # 28
print(MathUtils.is_prime(17)) # True
# 也可以通过实例调用,但很少这样做
math = MathUtils()
print(math.is_prime(13)) # True
特点与用途:
- 不能访问实例属性(无
self参数) - 不能访问类属性(无
cls参数) - 本质上就是普通函数,与类/实例状态完全无关
- 可以由类或实例调用
使用场景:
- 方法逻辑与类的状态完全无关
- 只是为了组织代码结构而放在类中的工具函数
- 功能上属于类的概念范畴,但不需要访问类或实例数据
如何选择使用哪种方法类型?
选择取决于方法的目的和它需要访问的数据:
-
使用实例方法,当方法需要:
- 访问或修改特定实例的属性
- 依赖于实例的状态
- 对特定对象执行操作
-
使用类方法,当方法需要:
- 访问或修改类属性
- 不需要访问特定实例的状态
- 作为替代构造函数(工厂方法)
- 需要在继承中引用正确的类
-
使用静态方法,当方法:
- 不需要访问实例或类的状态
- 仅在逻辑上属于类,但功能上独立
- 只是为了组织代码结构而放在类中
实际应用的简单规则:
- 如果方法使用了
self参数(访问实例属性或方法),它应该是实例方法。 - 如果方法不使用
self但使用cls参数(访问类属性或方法),它应该是被@classmethod装饰的类方法。 - 如果方法既不使用
self也不使用cls,它应该是被@staticmethod装饰的静态方法。
通过正确选择方法类型,你可以使代码更清晰、更符合面向对象的设计原则,同时减少错误和混淆。
二、并发与异步编程疑问
1. 多线程与多进程:如何选择?
问题:Python中的多线程和多进程有什么区别?我应该如何选择使用哪种方式来加速我的程序?
回答:并发编程是提高程序性能的重要手段,但选择正确的并发模型对于获得最佳性能至关重要。Python提供了多线程、多进程以及异步IO等不同的并发机制,它们各有优缺点。
Python中的全局解释器锁(GIL)
在讨论Python的多线程和多进程之前,必须先了解全局解释器锁(Global Interpreter Lock, GIL)。GIL是CPython解释器中的一个机制,它确保同一时刻只有一个线程可以执行Python字节码,这意味着在标准的CPython实现中,多线程无法在多核CPU上实现真正的并行计算。
这一限制导致Python多线程在CPU密集型任务上表现不佳,但在IO密集型任务上仍然非常有效。
多线程(Threading)
多线程在Python中通过threading模块实现:
import threading
import time
def worker(name):
print(f"线程 {name} 开始工作")
time.sleep(2) # 模拟IO操作
print(f"线程 {name} 完成工作")
# 创建多个线程
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(f"t{i}",))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print("所有线程已完成")
多线程的优势:
- 轻量级:线程创建和切换的开销较小
- 共享内存:线程之间可以直接共享内存空间,便于数据交换
- 适合IO密集型任务:当线程在等待IO时,其他线程可以继续执行
多线程的劣势:
- 受GIL限制:无法在多核上并行执行计算任务
- 线程安全问题:共享内存导致需要关注线程同步,避免竞态条件
- 调试困难:并发问题难以重现和调试
多进程(Multiprocessing)
多进程在Python中通过multiprocessing模块实现:
import multiprocessing
import time
def worker(name):
print(f"进程 {name} 开始工作")
time.sleep(2) # 模拟CPU计算
print(f"进程 {name} 完成工作")
if __name__ == "__main__":
# 创建多个进程
processes = []
for i in range(5):
p = multiprocessing.Process(target=worker, args=(f"p{i}",))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
print("所有进程已完成")
多进程的优势:
- 真正的并行计算:可以充分利用多核CPU
- 独立的内存空间:每个进程有自己的Python解释器和内存空间,不受GIL限制
- 稳定性更高:一个进程崩溃不会影响其他进程
多进程的劣势:
- 资源开销大:进程创建和切换的成本高
- 内存占用更多:每个进程有独立内存空间,无法直接共享数据
- 进程间通信复杂:需要使用特殊机制(如队列、管道)进行数据交换
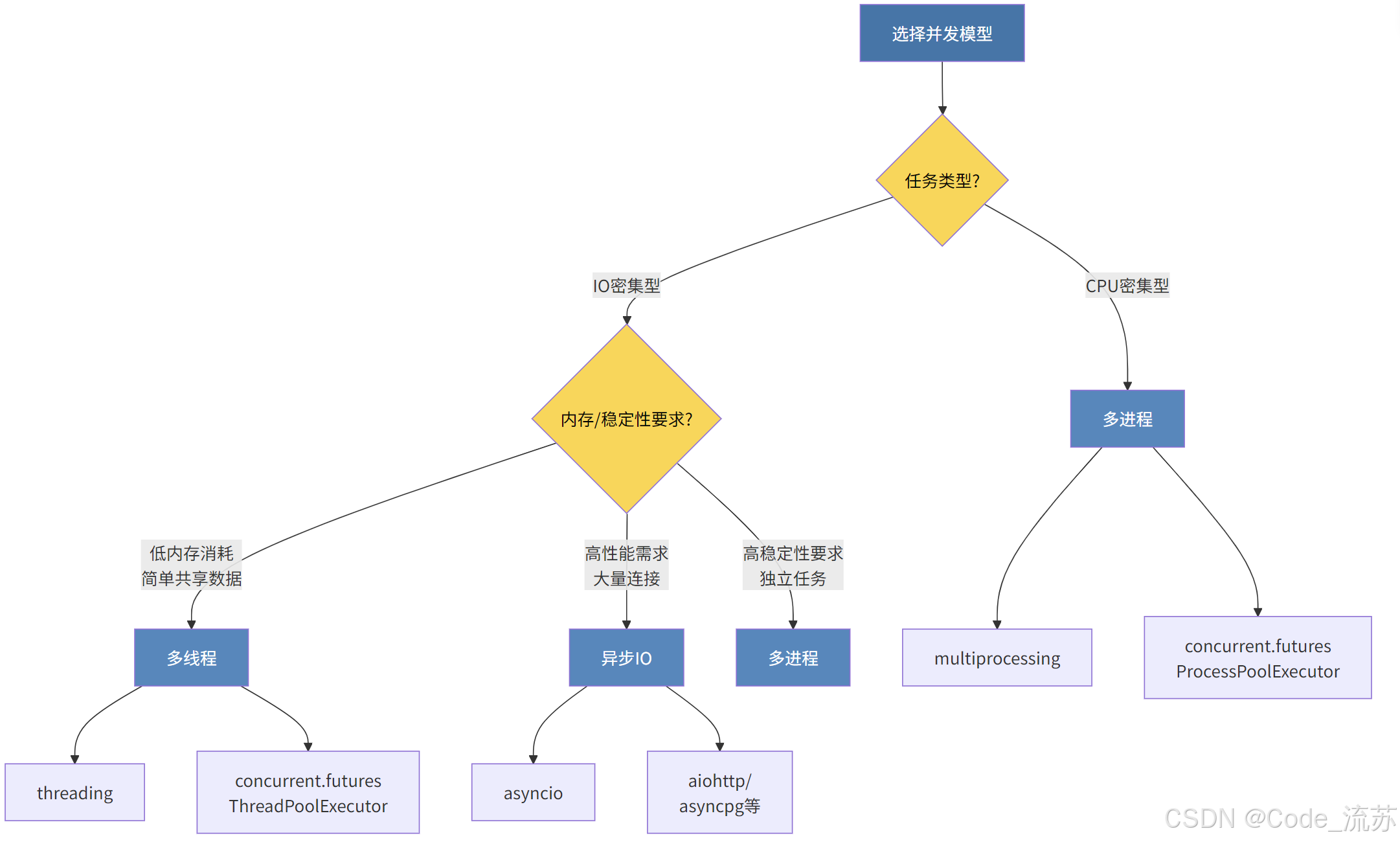
如何选择?
选择多线程还是多进程主要取决于你的任务类型:
选择多线程,当:
- 任务是IO密集型的(如网络请求、文件操作)
- 需要频繁共享数据
- 需要创建大量并发单元(线程更轻量)
- 内存使用是一个限制因素
选择多进程,当:
- 任务是CPU密集型的(如数据计算、图像处理)
- 需要充分利用多核CPU
- 任务间相对独立,数据共享需求较少
- 每个任务需要大量内存,但可能导致内存泄漏或崩溃
混合策略与其他选择
在实际应用中,常常会使用混合策略:
- 进程池+线程池:使用进程池处理CPU密集型任务,每个进程内使用线程池处理IO任务
from multiprocessing import Pool
from concurrent.futures import ThreadPoolExecutor
import time
def cpu_task(data):
# 一个CPU密集型任务
result = 0
for i in range(10000000):
result += i
return result + data
def io_tasks(count):
# 一组IO密集型任务
results = []
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(io_task, i) for i in range(count)]
for future in futures:
results.append(future.result())
return sum(results)
def io_task(n):
# 模拟IO操作
time.sleep(0.1)
return n
if __name__ == "__main__":
# 使用进程池处理CPU密集型任务
with Pool(processes=4) as pool:
cpu_results = pool.map(cpu_task, range(8))
# 在主进程中处理IO密集型任务
io_result = io_tasks(20)
print(f"CPU任务结果: {sum(cpu_results)}")
print(f"IO任务结果: {io_result}")
-
使用asyncio:对于IO密集型任务,
asyncio(异步IO)往往是比多线程更高效的选择 -
考虑其他实现:如PyPy(没有GIL)或特定领域的库(如NumPy,可以绕过GIL进行高效计算)
性能比较
下面是不同并发模型在不同类型任务下的性能比较:
CPU密集型任务(如计算素数):
- 多进程:最快(可以充分利用多核)
- 单线程:中等性能
- 多线程:最慢(由于GIL和线程切换开销)
IO密集型任务(如网络请求):
- 异步IO:处理大量连接时通常最快
- 多线程:适中(线程数适当时效果好)
- 多进程:适用于需要处理大量数据的场景
- 单线程:最慢
记住,没有一种通用的解决方案适合所有情况。理解你的任务特性和各种并发模型的优缺点,选择最适合你特定需求的方案,并通过实际测试验证性能。
2. 异步IO与asyncio入门
问题:我听说异步编程在Python中越来越重要,特别是asyncio库。但异步编程的概念和语法让我感到困惑,如何理解和使用asyncio?
回答:异步编程确实是近年来Python发展的重点方向,特别是处理IO密集型任务时,asyncio提供了比传统多线程更高效的并发模型。
理解异步编程的核心概念
异步编程与传统的同步编程有根本区别。在同步编程中,代码按顺序执行,当遇到IO操作时,程序会阻塞等待结果。而在异步编程中,当遇到IO操作时,程序可以"暂停"当前任务,去执行其他任务,等IO完成后再回来继续执行。
核心概念:
-
协程(Coroutine):可以在执行过程中暂停和恢复的函数。Python使用
async def定义协程。 -
事件循环(Event Loop):协程调度器,管理所有正在运行的协程,决定何时执行哪个协程。
-
await表达式:用于暂停协程,等待另一个协程/任务完成。 -
Future/Task:表示尚未完成的操作结果,Task是特殊的Future,封装了协程。
asyncio基础示例
让我们从一个简单的例子开始,理解asyncio的基本使用:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay) # 非阻塞的睡眠
print(what)
async def main():
print(f"开始时间: {time.strftime('%X')}")
# 这两个协程会依次执行,总共需要3秒
await say_after(1, "hello")
await say_after(2, "world")
print(f"结束时间: {time.strftime('%X')}")
# Python 3.7+
asyncio.run(main())
在上面的例子中,两个say_after调用是顺序执行的,因为我们使用了await等待第一个调用完成后才执行第二个。
现在让我们看看并发执行的例子:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"开始时间: {time.strftime('%X')}")
# 创建任务对象,不等待执行完成就继续
task1 = asyncio.create_task(say_after(1, "hello"))
task2 = asyncio.create_task(say_after(2, "world"))
# 等待两个任务完成
await task1
await task2
print(f"结束时间: {time.strftime('%X')}")
asyncio.run(main())
这个例子中,两个任务会同时开始执行,总共只需要约2秒(以最长的任务为准),而不是3秒。这就是异步IO的优势 - 在一个任务等待IO时,其他任务可以继续执行。
实用示例:异步网络请求
下面是一个更实际的例子,使用aiohttp库执行并发网络请求:
import asyncio
import aiohttp
import time
async def fetch_url(session, url):
async with session.get(url) as response:
return await response.text()
async def fetch_all(urls):
async with aiohttp.ClientSession() as session:
tasks = [asyncio.create_task(fetch_url(session, url)) for url in urls]
# 等待所有任务完成
results = await asyncio.gather(*tasks)
return results
async def main():
urls = [
"https://www.python.org",
"https://www.google.com",
"https://www.github.com",
"https://www.stackoverflow.com",
"https://www.wikipedia.org"
]
start = time.time()
pages = await fetch_all(urls)
end = time.time()
print(f"下载了 {len(pages)} 个网页,总大小: {sum(len(page) for page in pages)} 字节")
print(f"总耗时: {end - start:.2f} 秒")
# 运行主协程
asyncio.run(main())
使用asyncio处理网络请求比使用多线程更高效,尤其是在处理大量连接时。
asyncio常用API
以下是asyncio中最常用的函数和方法:
-
基础函数
asyncio.run(coro):运行协程,并返回结果asyncio.create_task(coro):将协程包装为Task对象开始执行asyncio.gather(*coros):并发运行多个协程,返回结果列表asyncio.sleep(delay):异步睡眠(非阻塞)
-
任务和Future
asyncio.wait(aws):等待多个协程/任务,提供更灵活的控制asyncio.wait_for(aw, timeout):等待单个协程,支持超时asyncio.as_completed(aws):按完成顺序迭代协程结果
-
并发和同步原语
asyncio.Lock:异步锁,防止多协程同时访问共享资源asyncio.Semaphore:限制同时执行的协程数量asyncio.Queue:协程间的通信和数据传递
异步上下文管理器
使用async with语句可以简化资源管理:
async def fetch_data():
async with aiohttp.ClientSession() as session:
async with session.get('https://api.example.com/data') as response:
return await response.json()
异步迭代器
使用async for可以异步迭代序列:
async def process_data(data_stream):
async for chunk in data_stream:
# 处理每个数据块
result = await process_chunk(chunk)
print(result)
异步编程的常见陷阱
- 混合同步和异步代码:在同步函数中调用异步函数需要特殊处理
# 错误示例
def sync_function():
result = async_function() # 错误!不能直接调用协程
# 正确示例
def sync_function():
loop = asyncio.new_event_loop()
result = loop.run_until_complete(async_function())
loop.close()
- 阻塞事件循环:在协程中执行CPU密集型任务会阻塞整个事件循环
async def cpu_bound_task():
# 错误:这会阻塞事件循环
result = [i**2 for i in range(10000000)]
return result
# 正确示例:使用线程池或进程池执行CPU密集型任务
async def cpu_bound_task():
loop = asyncio.get_running_loop()
result = await loop.run_in_executor(None, lambda: [i**2 for i in range(10000000)])
return result
- 忘记await:未使用await的协程不会被执行
async def main():
# 错误:协程不会执行
asyncio.sleep(1) # 缺少await
# 正确
await asyncio.sleep(1)
# 或者,如果不需要等待完成
asyncio.create_task(asyncio.sleep(1))
异步编程的适用场景
asyncio特别适合处理:
- 网络请求(HTTP客户端、API交互)
- 数据库操作(支持异步的数据库驱动)
- 文件IO操作
- 微服务间通信
- WebSocket和长连接处理
不适合的场景:
- CPU密集型计算(应使用多进程)
- 需要精确实时响应的应用
- 简单的短执行脚本(异步带来的复杂性可能得不偿失)
理解和掌握asyncio确实需要一些时间,但随着异步编程在Python生态中的普及,这项投资将非常值得。从简单的示例开始,逐步构建更复杂的异步应用,你会发现asyncio能够显著提高IO密集型应用的性能和吞吐量。
3. 并发编程中的死锁、竞态和安全问题
问题:在使用多线程或协程时,我有时会遇到程序卡住或得到不一致的结果。什么是死锁和竞态条件?如何避免这些问题?
回答:并发编程带来性能提升的同时,也引入了一些复杂的问题,如死锁、竞态条件和线程安全问题。这些问题如果不妥善处理,会导致程序行为不可预测或完全停止运行。让我们深入理解这些问题及其解决方案。
竞态条件(Race Condition)
竞态条件发生在两个或多个线程访问共享数据并尝试同时修改它时。由于线程执行的时间和顺序不可预测,这可能导致意外的结果。
示例:多个线程同时递增一个计数器
import threading
counter = 0
def increment():
global counter
for _ in range(100000):
# 以下三个步骤不是原子操作
current = counter # 读取
current += 1 # 修改
counter = current # 写回
# 创建10个线程,每个都执行increment函数
threads = []
for _ in range(10):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print(f"Counter: {counter}") # 预期为1,000,000,但可能会小于这个值
在上面的例子中,由于读取-修改-写入不是原子操作,不同线程可能会覆盖彼此的更改,导致最终计数器值小于预期。
解决方案:使用锁(Lock)来保护共享资源
import threading
counter = 0
lock = threading.Lock()
def increment():
global counter
for _ in range(100000):
with lock: # 获取锁
counter += 1 # 临界区 - 一次只有一个线程可以执行
# 创建10个线程
threads = []
for _ in range(10):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print(f"Counter: {counter}") # 现在应该总是1,000,000
死锁(Deadlock)
死锁发生在两个或多个线程互相等待对方释放资源时,导致程序永久卡住。最典型的情况是"环形等待",线程A持有线程B需要的资源,同时B持有A需要的资源。
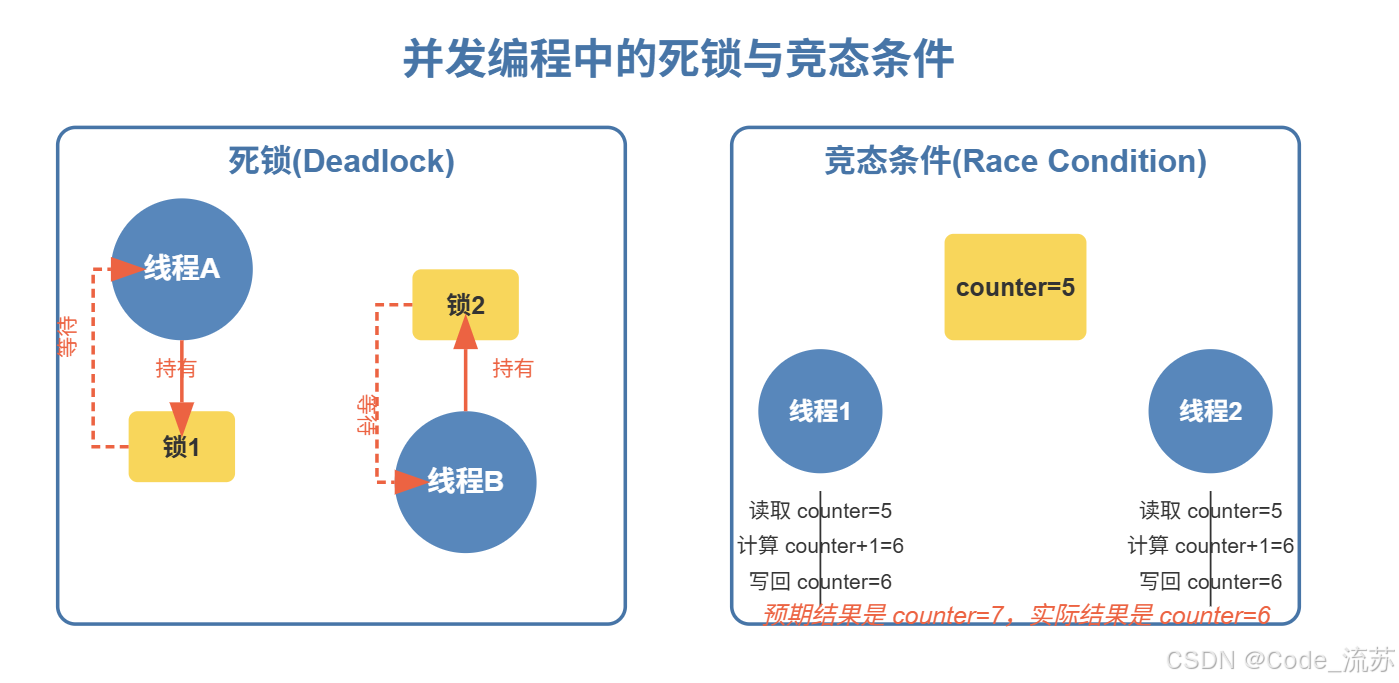
示例:两个线程分别获取两把锁,但以不同顺序
import threading
import time
# 创建两把锁
lock1 = threading.Lock()
lock2 = threading.Lock()
def thread_a():
print("线程A尝试获取锁1...")
with lock1:
print("线程A获得了锁1")
time.sleep(0.5) # 做一些工作
print("线程A尝试获取锁2...")
with lock2:
print("线程A获得了锁2")
print("线程A完成工作")
def thread_b():
print("线程B尝试获取锁2...")
with lock2:
print("线程B获得了锁2")
time.sleep(0.5) # 做一些工作
print("线程B尝试获取锁1...")
with lock1:
print("线程B获得了锁1")
print("线程B完成工作")
# 创建两个线程
t1 = threading.Thread(target=thread_a)
t2 = threading.Thread(target=thread_b)
# 启动线程
t1.start()
t2.start()
# 等待线程结束
t1.join()
t2.join()
上面的代码可能导致死锁:线程A获取锁1后等待锁2,同时线程B获取锁2后等待锁1,两个线程永远等待下去。
解决方案:
- 固定锁的获取顺序:总是以相同的顺序获取锁
def thread_a():
with lock1:
time.sleep(0.5)
with lock2:
print("线程A完成工作")
def thread_b():
with lock1: # 现在两个线程都是先获取lock1,再获取lock2
time.sleep(0.5)
with lock2:
print("线程B完成工作")
- 使用超时机制:尝试获取锁时设置超时
def thread_b():
acquired = False
while not acquired:
if lock2.acquire(timeout=1): # 尝试获取锁2,但最多等待1秒
try:
if lock1.acquire(timeout=1): # 尝试获取锁1,同样最多等待1秒
try:
print("线程B完成工作")
finally:
lock1.release()
else:
print("线程B无法获取锁1,稍后重试")
finally:
lock2.release()
acquired = True
else:
print("线程B无法获取锁2,稍后重试")
- 使用更高级的同步机制:如
threading.RLock(可重入锁)、信号量、条件变量等
线程安全问题
线程安全指的是代码在多线程环境中正确运行的能力,不会产生不期望的结果。Python中的许多操作并不是线程安全的,需要特别注意。
常见的线程安全问题:
- 复合操作:由多个单独操作组成的操作不是原子的
# 非线程安全的字典更新
shared_dict = {}
def update_dict(key, value):
if key not in shared_dict: # 检查
shared_dict[key] = value # 更新
# 如果两个线程同时执行,可能都会通过检查,导致后一个线程覆盖前一个线程的值
- 容器修改:在遍历容器时修改它
# 可能导致运行时错误
my_list = [1, 2, 3, 4, 5]
def process_list():
for item in my_list:
if item % 2 == 0:
my_list.remove(item) # 在遍历过程中修改列表,可能导致跳过元素或索引错误
解决方案:
- 使用锁保护共享资源:
shared_dict = {}
dict_lock = threading.Lock()
def update_dict(key, value):
with dict_lock:
if key not in shared_dict:
shared_dict[key] = value
- 使用线程安全容器:如
queue.Queue
import queue
# 线程安全的队列
safe_queue = queue.Queue()
def producer():
for i in range(10):
safe_queue.put(i) # 线程安全的添加元素
def consumer():
while not safe_queue.empty():
item = safe_queue.get() # 线程安全的获取元素
process_item(item)
- 使用原子操作:某些操作在Python中是原子的,如整数的简单赋值
# 这是原子操作,不需要额外的锁
x = 10
# 但这不是原子操作,需要锁保护
x += 1
- 使用线程局部存储:每个线程有自己的独立副本
import threading
# 创建线程局部存储
local_data = threading.local()
def worker():
# 每个线程设置自己的值
local_data.value = threading.current_thread().name
print(f"线程 {threading.current_thread().name} 的值: {local_data.value}")
# 创建多个线程
threads = []
for i in range(5):
t = threading.Thread(target=worker, name=f"Thread-{i}")
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
asyncio中的并发安全
尽管asyncio使用单线程事件循环,但仍然需要注意并发安全问题,因为协程可能在任何await点被切换。
示例:
import asyncio
counter = 0
async def increment():
global counter
# 读取当前值
current = counter
# 模拟一些异步操作
await asyncio.sleep(0.01) # 可能在此处切换到另一个协程
# 增加并写回
counter = current + 1
async def main():
# 创建1000个协程任务
tasks = [asyncio.create_task(increment()) for _ in range(1000)]
# 等待所有任务完成
await asyncio.gather(*tasks)
print(f"Counter: {counter}") # 预期为1000,但可能会小于这个值
asyncio.run(main())
解决方案:使用asyncio.Lock
import asyncio
counter = 0
lock = asyncio.Lock()
async def increment():
global counter
async with lock: # 使用异步锁
current = counter
await asyncio.sleep(0.01)
counter = current + 1
async def main():
tasks = [asyncio.create_task(increment()) for _ in range(1000)]
await asyncio.gather(*tasks)
print(f"Counter: {counter}") # 现在应该总是1000
asyncio.run(main())
最佳实践与预防措施
- 最小化共享状态:尽量减少线程间共享的数据
- 使用不可变数据:不可变对象不需要同步措施
- 使用高级并发库:如
concurrent.futures,它们已经处理了许多并发问题 - 使用线程安全数据结构:如
queue.Queue - 锁的粒度:使锁的范围尽可能小,只保护真正需要的部分
- 避免嵌套锁:降低死锁风险
- 使用超时机制:避免永久等待
- 正确的锁顺序:固定获取多个锁的顺序
- 考虑无锁算法:某些情况下可以使用CAS(比较并交换)等技术
- 代码审查:让有并发经验的开发者审查代码
通过理解这些问题和采取适当的措施,可以大大减少并发编程中的错误。记住,并发编程本质上比顺序编程更复杂,需要更谨慎的设计和更全面的测试。
三、常见包与第三方库使用问题
1. Pip与虚拟环境管理技巧
问题:如何有效管理Python包和依赖关系?创建和使用虚拟环境有什么最佳实践?
回答:随着Python项目的增长,有效管理依赖关系变得至关重要。Python虚拟环境和pip包管理器是解决这一问题的核心工具。让我分享一些实用技巧和最佳实践。
虚拟环境基础
虚拟环境是隔离的Python环境,允许在不同项目中使用不同版本的包,而不会相互干扰。
创建虚拟环境的方法:
- 使用内置的venv模块(Python 3.3+推荐)
# 创建虚拟环境
python -m venv myenv
# 激活虚拟环境
# Windows:
myenv\Scripts\activate
# MacOS/Linux:
source myenv/bin/activate
# 停用虚拟环境
deactivate
- 使用virtualenv(支持Python 2和3)
# 安装virtualenv
pip install virtualenv
# 创建虚拟环境
virtualenv myenv
# 激活与停用与venv相同
- 使用Conda(数据科学领域常用)
# 创建环境
conda create --name myenv python=3.9
# 激活环境
# Windows:
conda activate myenv
# MacOS/Linux:
conda activate myenv
# 停用环境
conda deactivate
pip高级使用技巧
pip是Python的包管理器,但很多用户只了解基本的pip install命令。以下是一些高级技巧:
- 使用requirements.txt管理依赖
# 生成依赖列表
pip freeze > requirements.txt
# 安装依赖
pip install -r requirements.txt
- 精确控制版本
# requirements.txt示例
numpy==1.20.3 # 精确版本
pandas>=1.3.0 # 最低版本
matplotlib~=3.4.2 # 兼容版本(3.4.x)
- 使用pip-tools优化依赖管理
pip-tools提供了两个命令:pip-compile生成锁定的依赖列表,pip-sync安装精确的依赖版本。
# 安装pip-tools
pip install pip-tools
# 从requirements.in生成锁定的requirements.txt
pip-compile requirements.in
# 安装并确保只有requirements.txt中的包被安装
pip-sync requirements.txt
- 使用国内镜像源加速下载
# 临时使用
pip install package-name -i https://pypi.tuna.tsinghua.edu.cn/simple
# 永久设置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
- 查看包信息和依赖关系
# 查看已安装包
pip list
# 查看过时的包
pip list --outdated
# 查看包的详细信息
pip show package-name
- 卸载包及其依赖
# 基本卸载
pip uninstall package-name
# 批量卸载(需要额外工具)
pip install pip-autoremove
pip-autoremove package-name
虚拟环境管理最佳实践
- 为每个项目创建独立的虚拟环境
这样每个项目可以有自己的依赖版本,避免冲突。
- 将虚拟环境目录添加到.gitignore
虚拟环境不应该被版本控制,而应该通过requirements.txt重新创建。
# .gitignore
venv/
env/
.env/
- 使用pipenv或Poetry进行更现代的依赖管理
这些工具结合了pip和virtualenv的功能,提供更强大的依赖解析。
Pipenv示例:
# 安装pipenv
pip install pipenv
# 安装包(自动创建虚拟环境)
pipenv install numpy pandas
# 激活环境
pipenv shell
# 安装开发依赖
pipenv install pytest --dev
Poetry示例:
# 安装poetry
pip install poetry
# 创建新项目
poetry new my-project
# 添加依赖
poetry add numpy pandas
# 运行命令
poetry run python script.py
- 使用pyenv管理Python版本
当需要在同一系统上使用多个Python版本时,pyenv是理想选择。
# 安装pyenv (MacOS/Linux)
curl https://pyenv.run | bash
# 安装特定Python版本
pyenv install 3.9.5
# 设置全局Python版本
pyenv global 3.9.5
# 为当前目录设置Python版本
pyenv local 3.8.10
- 设置项目级别的.env文件
存储环境变量,如API密钥,但不要将它们添加到版本控制中。
# .env
API_KEY=your_api_key_here
DEBUG=True
使用python-dotenv加载这些变量:
from dotenv import load_dotenv
load_dotenv() # 加载.env文件中的环境变量
- 使用Docker容器化应用
对于更复杂的项目,Docker提供了更完整的环境隔离解决方案:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "app.py"]
解决常见的pip和虚拟环境问题
- "找不到命令"错误
问题:激活虚拟环境后仍然使用系统Python
解决:确保PATH环境变量正确设置,可以使用which python(Unix)或where python(Windows)检查
- 依赖冲突
问题:安装新包时出现依赖冲突
解决:使用pip install --upgrade-strategy eager或考虑使用Poetry等更强大的依赖解析工具
- 权限错误
问题:pip安装时出现权限错误
解决:
- 使用虚拟环境(首选)
- 添加
--user标志:pip install --user package-name - 在Windows上以管理员身份运行命令提示符
- SSL证书错误
问题:pip下载时出现SSL证书验证错误
解决:
- 更新pip:
python -m pip install --upgrade pip - 临时解决:
pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org package-name
- 过时的pip缓存
问题:安装的包与预期不符
解决:清除pip缓存:pip cache purge
通过掌握这些工具和技巧,你可以有效管理Python项目的依赖关系,避免常见问题,并为团队协作创建一致的开发环境。随着项目规模和复杂性的增长,投资学习更高级的依赖管理工具如Poetry将带来更大的回报。
2. NumPy、Pandas与数据分析库FAQ
问题:在使用NumPy和Pandas进行数据分析时,我经常遇到一些困惑和挑战。有哪些常见问题及其解决方案?
回答:NumPy和Pandas是Python数据分析的基石,但确实存在一些初学者经常遇到的问题。让我们探讨这些常见问题及其解决方案。
NumPy常见问题与解决方案
- 数组维度和形状混淆
问题:在进行广播、矩阵运算等操作时出现维度不匹配错误。
# 错误示例
a = np.array([1, 2, 3]) # 形状 (3,)
b = np.array([[1], [2]]) # 形状 (2, 1)
result = a + b # ValueError: operands could not be broadcast together
解决方案:
# 使用reshape或增加维度
a = np.array([1, 2, 3]).reshape(1, 3) # 形状变为 (1, 3)
b = np.array([[1], [2]]) # 形状为 (2, 1)
result = a + b # 形状为 (2, 3),广播成功
# 或使用np.newaxis
a = np.array([1, 2, 3])[np.newaxis, :] # 同样变为形状 (1, 3)
了解广播规则很重要:较小数组被"广播"以匹配较大数组的形状。
- 内存使用效率问题
问题:处理大型数组时内存不足。
解决方案:
# 使用合适的数据类型
small_integers = np.arange(10000, dtype=np.int8) # 而非默认的int64
# 使用内存映射文件处理大型数组
big_array = np.memmap('tmp.dat', dtype=np.float32, mode='w+', shape=(10000, 10000))
# 分块处理大型数组
def process_in_chunks(filename, chunk_size=1000):
for chunk in np.load(filename, mmap_mode='r'):
# 处理每个块
result = process_chunk(chunk)
yield result
- 视图与副本混淆
问题:不确定操作是创建视图还是副本,导致修改不符预期。
解决方案:
# 理解视图
a = np.arange(10)
b = a[::2] # 创建视图
b[0] = 100 # 这也会修改a
# 确保创建副本
a = np.arange(10)
b = a[::2].copy() # 显式创建副本
b[0] = 100 # 不会影响a
- 轴(axis)参数混淆
问题:在使用如sum(), mean()等聚合函数时,轴参数的行为令人困惑。
解决方案:
# 记住axis=0是沿着行(跨行)操作,axis=1是沿着列(跨列)操作
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.sum(axis=0)) # [5, 7, 9] - 列求和
print(arr.sum(axis=1)) # [6, 15] - 行求和
# 使用命名参数增加代码可读性
row_means = arr.mean(axis=1) # 行平均值
col_means = arr.mean(axis=0) # 列平均值
Pandas常见问题与解决方案
- DataFrame索引和切片困惑
问题:pandas的不同索引方法(loc,iloc,[])令人困惑。
解决方案:
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
}, index=['x', 'y', 'z'])
# [] - 根据列名选择列,根据布尔数组过滤行
print(df['A']) # 选择A列
print(df[df['A'] > 1]) # 过滤行
# loc - 基于标签的索引(行名、列名)
print(df.loc['x']) # 选择行'x'
print(df.loc['x':'y', 'A']) # 选择行'x'到'y',列'A'
# iloc - 基于位置的索引(行号、列号)
print(df.iloc[0]) # 选择第一行
print(df.iloc[0:2, 0]) # 选择前两行,第一列
记住:loc使用标签,iloc使用位置,普通[]主要用于列选择和行过滤。
- 链式索引的警告
问题:SettingWithCopyWarning警告令人困惑。
# 警告示例
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
subset = df[df['A'] > 1]
subset['B'] = 0 # 可能触发SettingWithCopyWarning
解决方案:
# 方法1:使用loc明确索引
df.loc[df['A'] > 1, 'B'] = 0
# 方法2:如果确实需要修改副本,使用copy()明确创建副本
subset = df[df['A'] > 1].copy()
subset['B'] = 0 # 现在不会有警告
- 内存优化问题
问题:处理大型DataFrame时内存不足。
解决方案:
# 1. 优化数据类型
df_optimized = df.copy()
for col in df.columns:
if df[col].dtype == 'float64':
df_optimized[col] = df[col].astype('float32')
elif df[col].dtype == 'int64':
df_optimized[col] = df[col].astype('int32')
# 2. 使用分块读取
chunk_size = 100000
for chunk in pd.read_csv('large_file.csv', chunksize=chunk_size):
# 处理每个数据块
process_chunk(chunk)
# 3. 使用分类数据类型
df['category_column'] = df['category_column'].astype('category')
- 处理缺失值
问题:不确定如何最佳处理缺失值(NaN)。
解决方案:
# 检测缺失值
print(df.isnull().sum()) # 每列的缺失值计数
# 删除缺失值
df_clean = df.dropna() # 删除含有任何NaN的行
df_clean = df.dropna(subset=['important_column']) # 仅在重要列有NaN时删除
# 填充缺失值
df['A'].fillna(df['A'].mean(), inplace=True) # 使用均值填充
df['B'].fillna(method='ffill', inplace=True) # 向前填充
df['C'].fillna(method='bfill', inplace=True) # 向后填充
- 数据合并与连接困惑
问题:merge, join, concat等函数的区别不清。
解决方案:
# concat - 简单堆叠DataFrame
df_combined = pd.concat([df1, df2]) # 垂直堆叠(行方向)
df_combined = pd.concat([df1, df2], axis=1) # 水平堆叠(列方向)
# merge - 类似SQL连接,基于键值
df_merged = pd.merge(df1, df2, on='key_column') # 内连接
df_merged = pd.merge(df1, df2, on='key_column', how='left') # 左连接
# join - 基于索引的便捷方法
df_joined = df1.join(df2) # 以索引为键连接

数据可视化和探索技巧
- 高效数据探索
问题:如何快速了解DataFrame的基本统计特征?
解决方案:
# 基本描述性统计
print(df.describe()) # 数值列的统计摘要
print(df.describe(include=['object'])) # 类别列的统计摘要
# 数据类型和缺失值概览
print(df.info())
# 相关性分析
print(df.corr()) # 数值列间的相关性矩阵
sns.heatmap(df.corr(), annot=True) # 使用seaborn可视化相关性
# 分组统计
print(df.groupby('category').agg({
'numeric_col': ['mean', 'median', 'std'],
'other_col': 'count'
}))
- 常见绘图问题
问题:matplotlib和pandas绘图语法混淆。
解决方案:
import matplotlib.pyplot as plt
import seaborn as sns
# pandas直接绘图(基于matplotlib)
df['numeric_col'].plot(kind='hist') # 直方图
df.plot.scatter(x='A', y='B') # 散点图
df.boxplot(by='category') # 按类别的箱线图
# 使用matplotlib更精细控制
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(df['A'], df['B'], alpha=0.5)
ax.set_title('散点图示例')
ax.set_xlabel('特征A')
ax.set_ylabel('特征B')
plt.tight_layout()
plt.show()
# 使用seaborn简化复杂可视化
sns.pairplot(df) # 特征间的散点图矩阵
sns.scatterplot(x='A', y='B', hue='category', data=df) # 带分类的散点图
- 处理时间序列数据
问题:时间序列索引和重采样困难。
解决方案:
# 创建时间索引
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
# 时间序列切片
last_month = df['2023-01-01':'2023-01-31']
# 重采样(类似SQL的GROUP BY操作)
monthly = df.resample('M').mean() # 按月平均
weekly = df.resample('W').sum() # 按周求和
# 移动窗口计算
df['7d_rolling_avg'] = df['value'].rolling(window=7).mean()
3. Web框架(Django/Flask)常见瓶颈
问题:在使用Django或Flask开发Web应用时,我经常遇到性能瓶颈或配置难题。有哪些常见问题及解决方案?
回答:Python的Web框架如Django和Flask在构建Web应用时非常强大,但随着应用规模的增长,确实会遇到一些常见瓶颈和挑战。以下是一些典型问题及其解决方案。
Django常见问题与优化
- 数据库查询性能问题
问题:随着数据量增加,页面加载变慢,通常是由于低效的数据库查询。
解决方案:
# 问题:多次数据库查询(N+1问题)
# 普通查询,会产生N+1次查询
posts = Post.objects.all()
for post in posts:
print(post.author.name) # 每次循环都会查询author表
# 解决方案:使用select_related/prefetch_related预加载关联数据
# select_related用于ForeignKey和OneToOne关系
posts = Post.objects.select_related('author').all()
for post in posts:
print(post.author.name) # 不会产生额外查询
# prefetch_related用于ManyToMany关系
posts = Post.objects.prefetch_related('tags').all()
for post in posts:
print([tag.name for tag in post.tags.all()]) # 不会产生额外查询
# 只获取需要的字段
users = User.objects.values('id', 'username') # 只选择需要的字段
# 使用索引和优化查询
# 在models.py中添加索引
class Post(models.Model):
title = models.CharField(max_length=100)
published_date = models.DateTimeField(db_index=True) # 添加索引
- 缓存使用不足
问题:重复计算或查询相同数据,没有利用缓存提高性能。
解决方案:
# 配置缓存后端,在settings.py中
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.redis.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379/1',
}
}
# 视图级缓存
from django.views.decorators.cache import cache_page
@cache_page(60 * 15) # 缓存15分钟
def my_view(request):
# ...
return response
# 模板片段缓存
{% load cache %}
{% cache 500 sidebar %}
{# 缓存的侧边栏内容 #}
{% endcache %}
# 低级缓存API
from django.core.cache import cache
# 设置缓存
cache.set('my_key', complex_calculation(), 60*60) # 缓存1小时
# 获取缓存
result = cache.get('my_key')
if result is None:
result = complex_calculation()
cache.set('my_key', result, 60*60)
- 大文件上传和处理
问题:上传大文件导致服务器内存占用过高或请求超时。
解决方案:
# settings.py中配置
FILE_UPLOAD_MAX_MEMORY_SIZE = 2.5 * 1024 * 1024 # 2.5MB,超过此值使用临时文件
# 使用分块上传处理大文件
def handle_uploaded_file(f):
with open('destination.file', 'wb+') as destination:
for chunk in f.chunks(): # 默认以2.5MB的块读取
destination.write(chunk)
# 对于异步处理大文件,可以使用Celery任务队列
@app.task
def process_large_file(file_path):
# 处理文件的耗时操作
pass
def upload_view(request):
if request.method == 'POST':
form = UploadForm(request.POST, request.FILES)
if form.is_valid():
# 保存文件
instance = form.save()
# 调用异步任务处理文件
process_large_file.delay(instance.file.path)
return redirect('success')
- 静态文件处理
问题:生产环境中静态文件服务效率低下。
解决方案:
# settings.py中配置静态文件
STATIC_URL = '/static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
STATICFILES_STORAGE = 'django.contrib.staticfiles.storage.ManifestStaticFilesStorage' # 使用哈希文件名
# 收集静态文件
python manage.py collectstatic
# 在生产环境中,应由Nginx等Web服务器直接提供静态文件
# Nginx配置示例
server {
# ...
location /static/ {
alias /path/to/your/static/;
expires 30d;
}
}
Flask常见问题与优化
- 应用结构问题
问题:随着应用增长,单文件结构变得难以维护。
解决方案:采用应用工厂模式和蓝图组织代码:
# 项目结构
myapp/
├── __init__.py # 应用工厂
├── auth/ # 认证相关模块
│ ├── __init__.py
│ ├── forms.py
│ ├── models.py
│ └── views.py
├── models.py # 共享模型
├── static/ # 静态文件
└── templates/ # 模板文件
# __init__.py 中使用应用工厂模式
def create_app(config=None):
app = Flask(__name__)
# 加载配置
app.config.from_object('config.default')
if config:
app.config.from_object(config)
# 初始化扩展
db.init_app(app)
# 注册蓝图
from myapp.auth import auth_bp
app.register_blueprint(auth_bp, url_prefix='/auth')
return app
# auth/__init__.py 使用蓝图
from flask import Blueprint
auth_bp = Blueprint('auth', __name__)
from . import views # 导入视图,必须在蓝图创建后
- 数据库连接管理
问题:没有正确管理数据库连接池,导致连接泄漏或过多连接。
解决方案:
# 使用SQLAlchemy时配置连接池
from flask_sqlalchemy import SQLAlchemy
app.config['SQLALCHEMY_ENGINE_OPTIONS'] = {
'pool_size': 10,
'pool_recycle': 3600,
'pool_pre_ping': True,
}
db = SQLAlchemy(app)
# 或者直接使用with语句管理连接
from contextlib import contextmanager
@contextmanager
def get_db_connection():
connection = engine.connect()
try:
yield connection
finally:
connection.close()
# 使用
with get_db_connection() as conn:
result = conn.execute("SELECT * FROM users")
- 请求处理超时
问题:长时间运行的操作导致请求处理超时。
解决方案:
# 将耗时操作移到后台任务
from flask import Flask
from celery import Celery
app = Flask(__name__)
celery = Celery(app.name, broker='redis://localhost:6379/0')
celery.conf.update(app.config)
@celery.task
def long_running_task(arg1, arg2):
# 耗时操作
pass
@app.route('/process')
def process():
# 启动后台任务并立即返回
task = long_running_task.delay('arg1', 'arg2')
return {'task_id': task.id}, 202
- 缓存策略
问题:没有有效使用缓存,导致重复计算或查询。
解决方案:
# 使用Flask-Caching扩展
from flask_caching import Cache
cache = Cache(app, config={'CACHE_TYPE': 'redis', 'CACHE_REDIS_URL': 'redis://localhost:6379/0'})
# 视图函数缓存
@app.route('/expensive-operation')
@cache.cached(timeout=60) # 缓存60秒
def expensive_operation():
# 执行昂贵的操作
return result
# 函数结果缓存
@cache.memoize(timeout=50)
def expensive_function(param1, param2):
# 昂贵的计算
return result
# 手动管理缓存
def get_complex_data():
data = cache.get('complex_data')
if data is None:
data = compute_complex_data()
cache.set('complex_data', data, timeout=3600)
return data
Django与Flask的部署最佳实践
- 使用生产级WSGI服务器
问题:开发服务器不适合生产环境,性能低且不安全。
解决方案:
# 使用Gunicorn作为WSGI服务器
pip install gunicorn
# Django启动命令
gunicorn myproject.wsgi:application --workers=4 --bind=0.0.0.0:8000
# Flask启动命令
gunicorn "myapp:create_app()" --workers=4 --bind=0.0.0.0:8000
# 或者使用uWSGI
uwsgi --http :8000 --module myproject.wsgi
- 反向代理配置
问题:直接暴露Python应用服务器不安全且性能不佳。
解决方案:使用Nginx作为反向代理:
# Nginx配置示例
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
location /static/ {
alias /path/to/static/files/;
expires 30d;
}
location /media/ {
alias /path/to/media/files/;
expires 30d;
}
}
- 安全最佳实践
问题:没有正确配置安全选项,易受攻击。
解决方案:
# Django安全设置
SECRET_KEY = os.environ.get('SECRET_KEY') # 不要硬编码
DEBUG = False # 生产环境禁用调试
ALLOWED_HOSTS = ['example.com'] # 限制允许的主机
SECURE_SSL_REDIRECT = True # 重定向到HTTPS
SESSION_COOKIE_SECURE = True # 仅通过HTTPS发送cookie
CSRF_COOKIE_SECURE = True # 仅通过HTTPS发送CSRF cookie
X_FRAME_OPTIONS = 'DENY' # 防止点击劫持
# Flask安全设置
app.config['SECRET_KEY'] = os.environ.get('SECRET_KEY')
app.config['SESSION_COOKIE_SECURE'] = True
app.config['REMEMBER_COOKIE_SECURE'] = True
# 设置CORS(跨源资源共享)
from flask_cors import CORS
CORS(app, resources={r"/api/*": {"origins": "https://example.com"}})
- 监控与日志
问题:无法及时发现和诊断生产问题。
解决方案:
# Django日志配置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'file': {
'level': 'INFO',
'class': 'logging.FileHandler',
'filename': '/path/to/django.log',
},
},
'loggers': {
'django': {
'handlers': ['file'],
'level': 'INFO',
'propagate': True,
},
},
}
# Flask日志配置
import logging
from logging.handlers import RotatingFileHandler
if not app.debug:
file_handler = RotatingFileHandler('flask-app.log', maxBytes=10240, backupCount=10)
file_handler.setFormatter(logging.Formatter(
'%(asctime)s %(levelname)s: %(message)s [in %(pathname)s:%(lineno)d]'
))
file_handler.setLevel(logging.INFO)
app.logger.addHandler(file_handler)
app.logger.setLevel(logging.INFO)
app.logger.info('Flask startup')
# 考虑使用Sentry等错误追踪服务
import sentry_sdk
from sentry_sdk.integrations.django import DjangoIntegration
sentry_sdk.init(
dsn="https://examplePublicKey@o0.ingest.sentry.io/0",
integrations=[DjangoIntegration()],
traces_sample_rate=1.0,
)
通过应用这些优化和最佳实践,你可以构建更高效、更安全的Django和Flask应用。随着应用的不断成长,持续监控性能瓶颈并采取措施解决它们是很重要的。
4. 机器学习库的使用陷阱
问题:在使用scikit-learn、TensorFlow和PyTorch等机器学习库时,我经常遇到意外的问题。有哪些常见的陷阱和最佳实践?
回答:机器学习库功能强大但也蕴含很多隐藏的陷阱,特别是对初学者来说。以下是一些常见问题及解决方案,帮助你避免这些陷阱。
scikit-learn常见问题
- 训练-测试数据泄露
问题:模型性能不真实,因为测试数据的信息泄露到了训练过程中。
# 错误示例
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 错误:在分割前对所有数据进行标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 使用所有数据的统计信息
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y)
解决方案:
# 正确示例
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 仅基于训练数据拟合转换器
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
# 使用训练数据的参数转换测试数据
X_test_scaled = scaler.transform(X_test)
- 交叉验证与超参数调优
问题:过拟合超参数,因为使用了错误的交叉验证策略。
解决方案:
from sklearn.model_selection import GridSearchCV, KFold
# 创建嵌套交叉验证
outer_cv = KFold(n_splits=5, shuffle=True, random_state=42)
inner_cv = KFold(n_splits=3, shuffle=True, random_state=42)
# 超参数网格
param_grid = {'n_estimators': [10, 50, 100], 'max_depth': [None, 10, 20]}
# 网格搜索
grid_search = GridSearchCV(
estimator=RandomForestClassifier(),
param_grid=param_grid,
cv=inner_cv, # 内部交叉验证用于超参数选择
scoring='accuracy'
)
# 外部交叉验证评估模型性能
from sklearn.model_selection import cross_val_score
scores = cross_val_score(grid_search, X, y, cv=outer_cv)
print(f"Cross-validated accuracy: {scores.mean():.3f} ± {scores.std():.3f}")
- 处理类别特征
问题:不正确处理类别特征导致模型失效或性能下降。
解决方案:
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# 定义类别特征和数值特征
categorical_features = ['gender', 'education', 'occupation']
numerical_features = ['age', 'income', 'debt_ratio']
# 创建特征转换管道
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_features),
# 对没有顺序关系的类别特征使用独热编码
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])
# 创建完整管道
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier())
])
# 拟合与预测
model.fit(X_train, y_train)
predictions = model.predict(X_test)
- 特征重要性解释
问题:错误解释特征重要性,特别是在有相关特征的情况下。
解决方案:
from sklearn.inspection import permutation_importance
# 使用置换重要性,比内置特征重要性更可靠
result = permutation_importance(
model, X_test, y_test, n_repeats=10, random_state=42, n_jobs=-1
)
# 展示结果
for i in result.importances_mean.argsort()[::-1]:
print(f"{feature_names[i]}: {result.importances_mean[i]:.3f} ± {result.importances_std[i]:.3f}")
# 对于线性模型,确保先标准化特征再解释系数
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
pipeline.fit(X_train, y_train)
# 获取标准化后的特征系数
coefficients = pipeline.named_steps['model'].coef_[0]
for feature, coef in zip(feature_names, coefficients):
print(f"{feature}: {coef:.3f}")
TensorFlow/Keras常见问题
- 内存泄漏与资源管理
问题:训练长时间运行后内存使用量持续增加。
解决方案:
import tensorflow as tf
import gc
# 在每个训练周期后清理
for epoch in range(epochs):
# 训练代码
model.fit(X_train, y_train, batch_size=batch_size, epochs=1)
# 清理
gc.collect()
tf.keras.backend.clear_session()
# 禁用急切执行可减少内存占用
tf.compat.v1.disable_eager_execution()
# 限制GPU内存增长
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
- 数据预处理管道效率低
问题:数据加载和预处理成为训练瓶颈。
解决方案:
# 使用tf.data API构建高效的数据管道
def preprocess_fn(image, label):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [224, 224])
image = tf.cast(image, tf.float32) / 255.0
return image, label
# 创建高效的数据集
train_dataset = tf.data.Dataset.from_tensor_slices((image_paths, labels))
train_dataset = train_dataset.map(
lambda x, y: (tf.io.read_file(x), y)
).map(
preprocess_fn, num_parallel_calls=tf.data.experimental.AUTOTUNE
).batch(
batch_size
).prefetch(
tf.data.experimental.AUTOTUNE # 预取数据提高效率
)
# 使用数据集训练
model.fit(train_dataset, epochs=10)
- 保存与加载模型问题
问题:保存的模型在加载时出现错误,尤其是自定义层或损失函数。
解决方案:
import tensorflow as tf
# 自定义层
class CustomLayer(tf.keras.layers.Layer):
def __init__(self, units):
super(CustomLayer, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w)
# 关键:实现get_config方法
def get_config(self):
config = super(CustomLayer, self).get_config()
config.update({'units': self.units})
return config
# 创建和训练模型
model = tf.keras.Sequential([
CustomLayer(32),
tf.keras.layers.Activation('relu')
])
model.compile(optimizer='adam', loss='mse')
model.fit(x_train, y_train, epochs=5)
# 保存模型
model.save('custom_model')
# 加载模型(需要提供自定义对象)
loaded_model = tf.keras.models.load_model(
'custom_model',
custom_objects={'CustomLayer': CustomLayer}
)
- 梯度爆炸/消失问题
问题:训练不稳定,损失为NaN或训练停滞。
解决方案:
# 梯度裁剪
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001, clipnorm=1.0)
model.compile(optimizer=optimizer, loss='mse')
# 使用批量归一化
model = tf.keras.Sequential([
tf.keras.layers.Dense(128),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 权重初始化很重要
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, kernel_initializer='he_normal'),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 对于RNN,考虑LSTM/GRU替代简单RNN
model = tf.keras.Sequential([
tf.keras.layers.LSTM(128, return_sequences=True),
tf.keras.layers.LSTM(64),
tf.keras.layers.Dense(10, activation='softmax')
])
PyTorch常见问题
- 训练循环中的常见错误
问题:没有正确实现训练循环,导致梯度累积或不更新。
解决方案:
import torch
import torch.nn as nn
import torch.optim as optim
# 正确的训练循环
def train(model, dataloader, criterion, optimizer, device):
model.train() # 设置为训练模式
running_loss = 0.0
for inputs, targets in dataloader:
# 移到GPU
inputs, targets = inputs.to(device), targets.to(device)
# 清零梯度 - 重要!
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloader.dataset)
return epoch_loss
- 内存管理与GPU利用
问题:GPU内存耗尽或利用率低。
解决方案:
# 限制PyTorch的CUDA内存分配
torch.cuda.set_per_process_memory_fraction(0.7) # 使用最多70%的GPU内存
# 定期清理缓存
torch.cuda.empty_cache()
# 针对大型模型的梯度累积
model = MyModel().to(device)
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
accumulation_steps = 4 # 每4批次更新一次
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 缩放损失以适应梯度累积
loss = loss / accumulation_steps
# 反向传播
loss.backward()
# 每accumulation_steps步骤更新一次权重
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
- 模型评估与推理模式
问题:在评估时忘记设置模型为eval模式,导致结果不一致。
解决方案:
# 正确的评估循环
def evaluate(model, dataloader, criterion, device):
model.eval() # 设置为评估模式 - 重要!
running_loss = 0.0
correct = 0
with torch.no_grad(): # 不计算梯度,节省内存
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
running_loss += loss.item() * inputs.size(0)
_, preds = torch.max(outputs, 1)
correct += torch.sum(preds == targets.data)
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = correct.double() / len(dataloader.dataset)
return epoch_loss, epoch_acc
- 模型部署与保存问题
问题:保存和加载模型时出现问题,或部署时性能不佳。
解决方案:
# 保存完整模型(包括优化器状态)- 用于继续训练
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, 'checkpoint.pt')
# 加载模型继续训练
checkpoint = torch.load('checkpoint.pt')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
# 仅保存模型权重 - 用于部署
torch.save(model.state_dict(), 'model_weights.pt')
# 加载权重到模型
model = MyModel()
model.load_state_dict(torch.load('model_weights.pt'))
model.eval() # 设置为评估模式
# 导出为ONNX格式以便在其他平台部署
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "model.onnx",
export_params=True,
opset_version=10,
input_names=['input'],
output_names=['output'])
机器学习项目的一般性最佳实践
- 数据版本控制
重要性:数据变化会影响模型性能,追踪数据版本有助于重现结果。
解决方案:
# 使用DVC (Data Version Control)
pip install dvc
# 初始化DVC项目
dvc init
# 添加数据文件到DVC
dvc add data/dataset.csv
# 更改后提交数据变更
dvc add data/dataset.csv
git add data/dataset.csv.dvc
git commit -m "Updated dataset"
# 推送到远程存储
dvc push
- 实验跟踪
重要性:跟踪实验参数、性能指标和模型版本,便于比较和重现。
解决方案:
# 使用MLflow跟踪实验
import mlflow
import mlflow.sklearn
# 启动实验
mlflow.start_run()
# 记录参数
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("n_estimators", 100)
# 训练模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 记录指标
accuracy = model.score(X_test, y_test)
mlflow.log_metric("accuracy", accuracy)
# 保存模型
mlflow.sklearn.log_model(model, "random_forest_model")
# 结束实验
mlflow.end_run()
- 模型解释性
重要性:了解模型决策过程,增加信任和透明度。
解决方案:
# 使用SHAP解释模型
import shap
# 创建解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# 可视化特征重要性
shap.summary_plot(shap_values, X_test)
# 对单个预测进行解释
shap.force_plot(explainer.expected_value[1], shap_values[1][0], X_test.iloc[0])
通过避免这些常见陷阱并采用最佳实践,你可以构建更可靠、更高性能的机器学习模型。机器学习是一个实践性强的领域,不断尝试、记录和改进是成功的关键。
四、总结与学习资源推荐
作为《Python星球日记》答疑篇的结尾,我想总结一些关键点,并推荐一些有价值的学习资源,帮助你继续深入Python学习之旅。
1. 入门学习路径回顾
在学习Python编程的过程中,许多初学者会经历以下几个阶段:
- 基础语法阶段:掌握变量、数据类型、控制流、函数等核心概念
- 数据结构与算法阶段:深入理解列表、字典、集合及其使用场景
- 模块与库应用阶段:学习使用标准库和第三方库解决实际问题
- 实践项目阶段:通过构建完整项目整合所学知识
- 深入专业领域阶段:如Web开发、数据分析、机器学习等特定方向
无论你处于哪个阶段,保持编写代码的习惯和持续学习的心态都是进步的关键。
2. 推荐学习资源
官方文档
- Python官方文档 - 最权威的Python参考资料
- Python标准库文档 - 详细介绍Python内置功能
交互式学习平台
- Python Tutor - 可视化Python代码执行过程
- LeetCode - 提高算法和编程能力的平台
- DataCamp - 数据科学和Python编程课程
开源电子书
- Automate the Boring Stuff with Python - 通过自动化任务学习Python
- Python Data Science Handbook - 数据科学必备指南
视频教程
- MIT 6.0001 Introduction to Computer Science and Programming in Python - 麻省理工学院的Python入门课程
- CS50’s Web Programming with Python and JavaScript - 哈佛大学的Web开发课程
社区论坛
- Stack Overflow - 解决编程问题的最大社区
- Python社区 - 官方Python社区资源
3. 持续学习的建议
- 建立编码习惯:每天至少写一小段代码,保持编程思维活跃
- 参与开源项目:通过贡献开源项目提升实际项目经验
- 解决实际问题:将Python应用于解决工作或生活中的实际问题
- 教会他人:尝试向他人解释概念,这有助于巩固自己的理解
- 关注新发展:Python生态系统不断发展,保持对新特性和库的关注
4. 《Python星球日记》系列展望
在《Python星球日记》系列的后续内容中,我们将继续探索更多高级主题和实战项目,包括:
- 深度学习实战:使用PyTorch和TensorFlow构建复杂模型
- 大数据处理:使用Spark和Dask处理TB级数据
- Web应用部署:从开发到云端部署的完整流程
- Python性能优化:提升代码执行速度的高级技巧
- 生成式AI应用:使用Python构建基于大模型的应用
敬请期待更多精彩内容,我们将一起在Python的星球上继续探险!
结语
Python学习是一段永无止境的旅程,每一位程序员都会在这个过程中遇到各种各样的问题和挑战。希望这篇《Python星球日记》答疑篇能够解答你在学习过程中的一些疑惑,并为你提供有价值的解决方案。
记住,编程能力的提升不仅仅来自于阅读教程和文档,更重要的是通过实践和解决实际问题。遇到困难时,不要轻易放弃,尝试理解问题本质并寻找解决方案的过程,正是成长最快的时刻。
在Python星球的探索之旅中,你会发现这门语言的简洁性和强大功能让它成为许多领域的理想工具。无论你的目标是什么,持续学习和实践将是你成功的关键。
让我们带着好奇心和探索精神,继续在Python星球上航行,发现更多精彩的编程世界!
Python星球日记 - 未完待续…
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!


















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











