






贡献:
1.将text2sql任务分解为3个阶段,实体和上下文检索、模式选择和查询生成
2.一种可扩展的分层检索方法,用于提取重要的实体和上下文。
3.一个高效的三阶段架构修剪协议,包括单独的列过滤、表选择和最终的列选择,以提取最小足够架构。
4.一个经过微调的开源DeepSeek-33B编码器模型,采用新颖的训练数据集构建方法,通过噪声注入来减轻错误传播。
5.一个高性能的端到端开源管道,确保信息的隐私
6.在已知方法中,在BIRD数据集上获得了最好的结果
CHESS:由三个部分组成实体和上下文检索(Entity and Context Retrieval),模式选择(Schema Selection),查询生成(Query Generation)。具体结构如下:
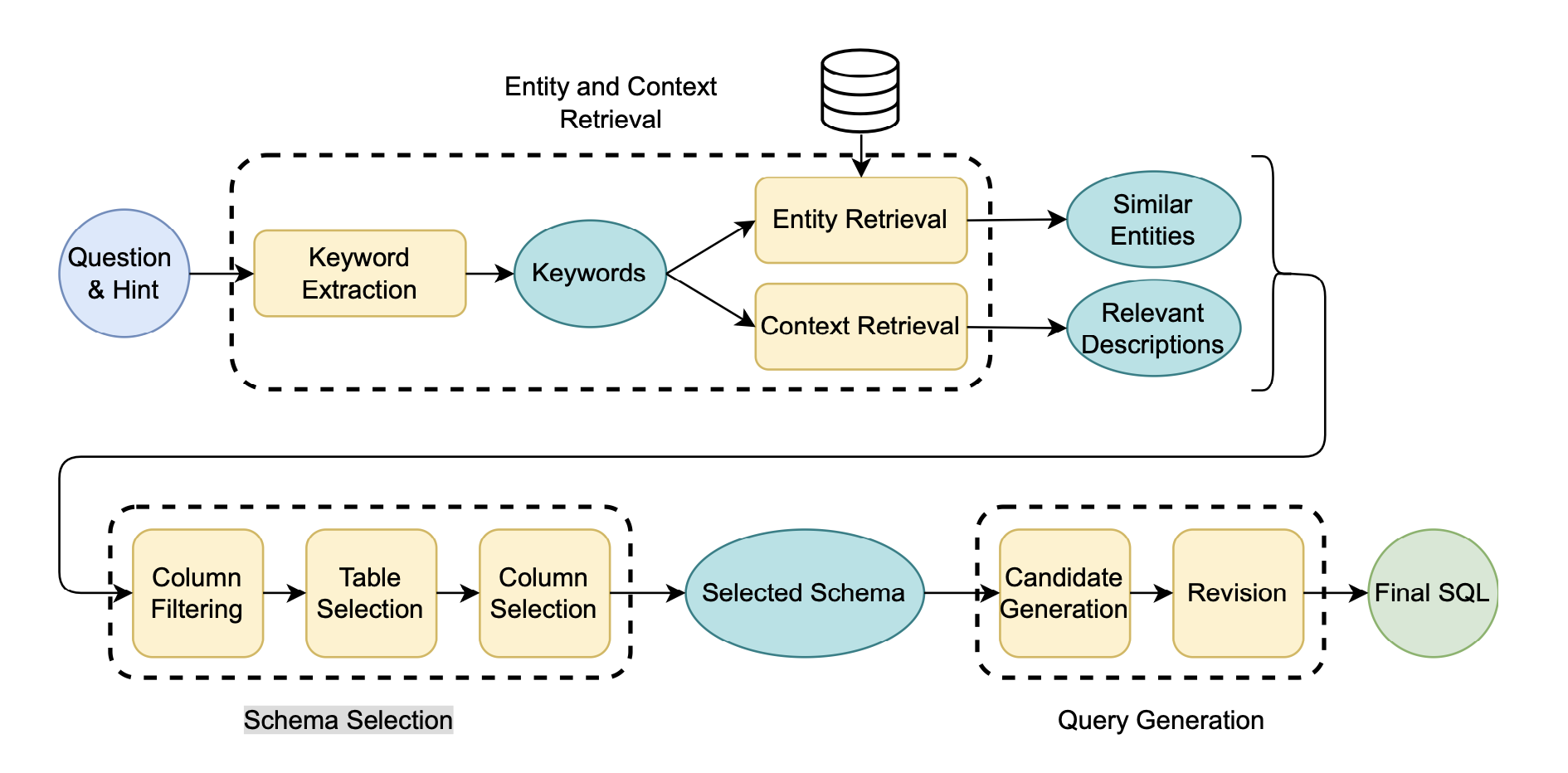
实体和上下文检索有三个步骤:
1.关键词提取(keyword extraction):使用任务和问题的少量示例来提示模型,要求它识别和提取关键字、关键词和命名实体。
2.实体检索(entity retrieval):更灵活的搜素方法-编辑距离相似度量,提高检索效率的方法-基于局部敏感哈希(LSH)的语义相似度度量的分层检索策略见附录c
3.内容检索(context retrieval):预处理的时候,创建好描述向量库。通过提取关键字,找到最匹配的向量库中的句子。
模式选择:
目标:缩小模式的范围,以便只包含生成 SQL 查询所需的表和列。
单列过滤:直接询问LLM,过滤掉不相关的列,仅用于删除显而易见的不相关的列
表选择:和列过滤类似,但对表
最终列选择:减少到所需的最少列集
查询生成:
候选生成:利用前两步的信息要求LLM生成一个SQL语句。
修改步骤:提供了一个与数据库模式、问题、生成的候选 SQL 查询及其执行结果有关的模型。然后要求模型评估 SQL 查询的正确性,并在必要时进行修改。
预处理:
数据库值,按照实体检索中的描述,我们通过创建局部敏感哈希(LSH)索引来进行语法搜索。包含需要语义理解的较长文本的数据库目录,我们使用向量数据库检索方法来度量语义相似度。
更具体的细节见目录C
实验:
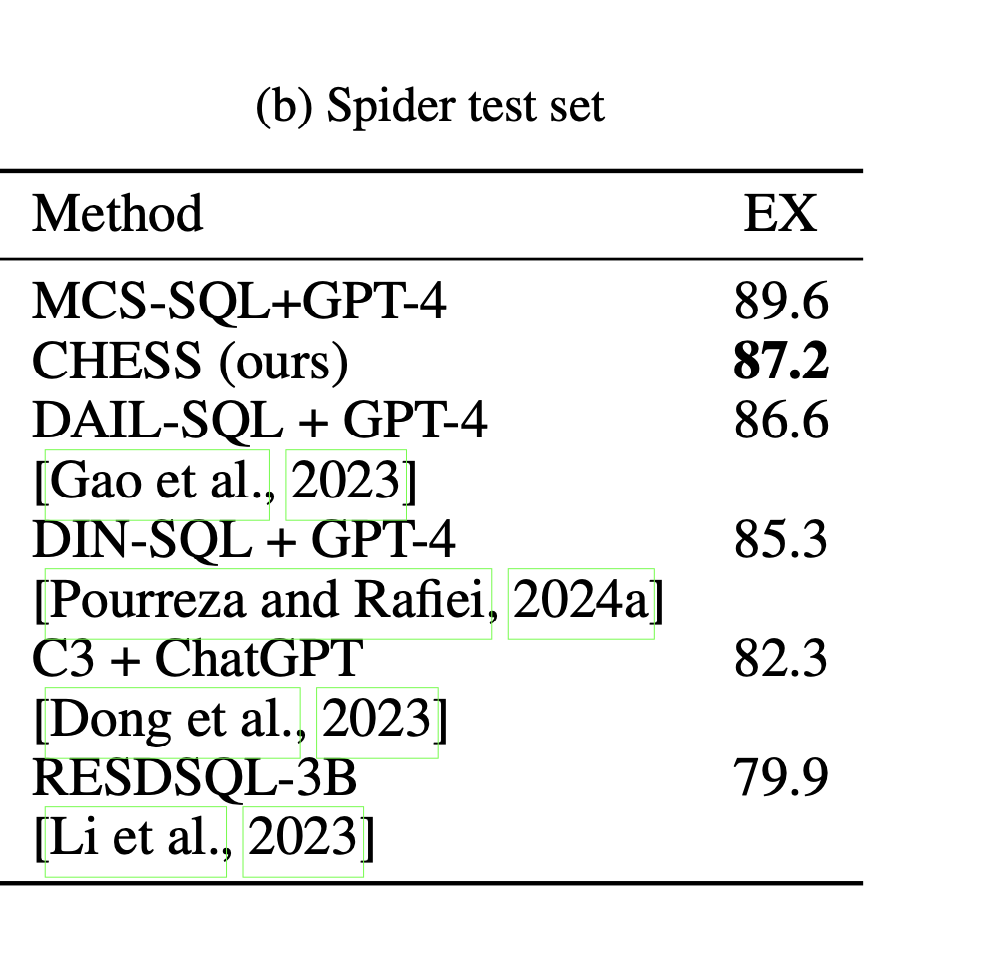
Spider数据集:
SDS:对BIRD的每个数据库的10%进行了抽样,产生的数据集。
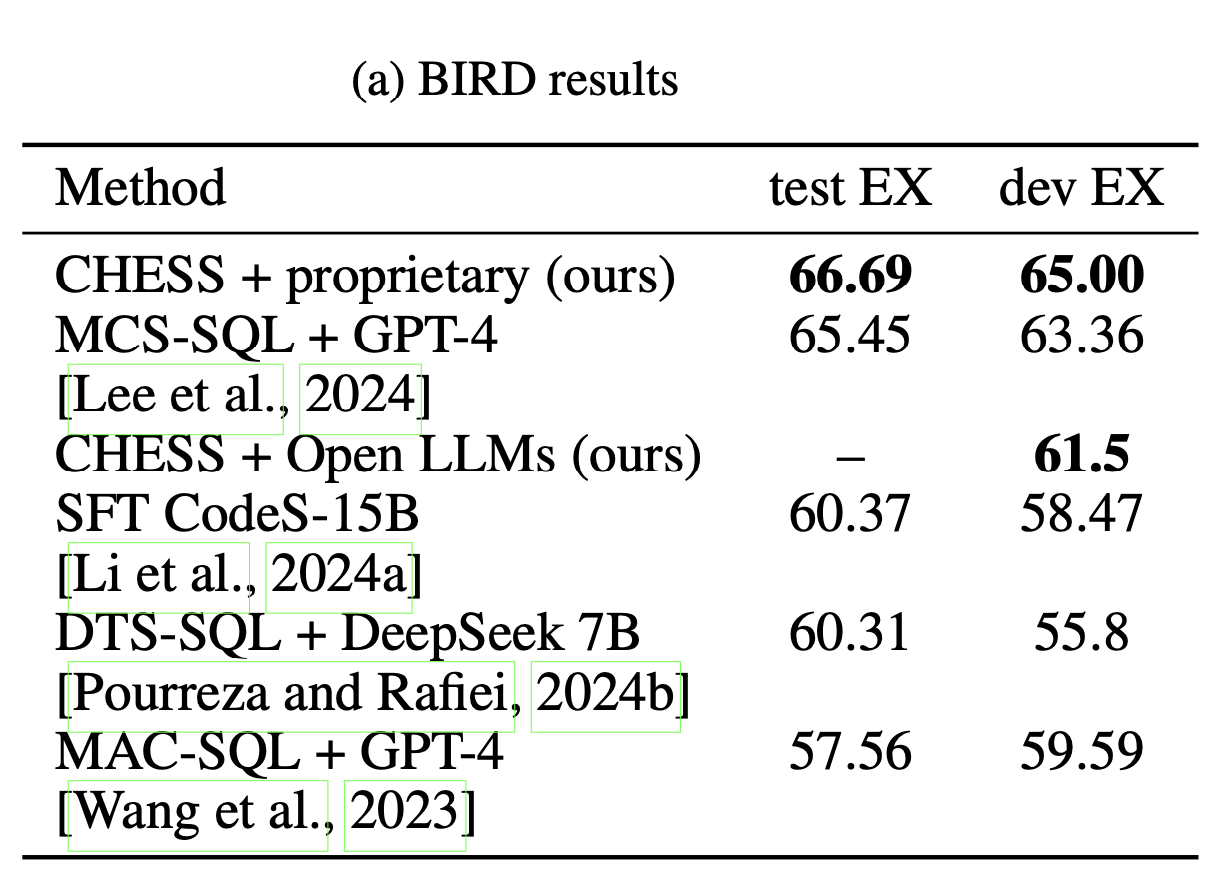
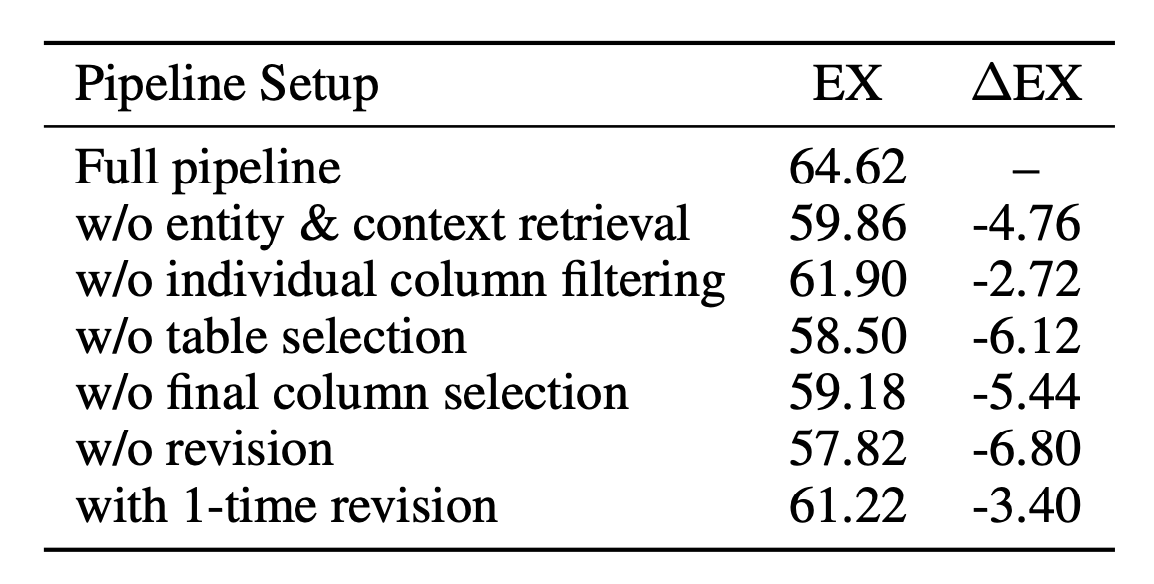
消融研究:
模型消融技术:

模块消融技术:
不同复杂度查询的性能评估:

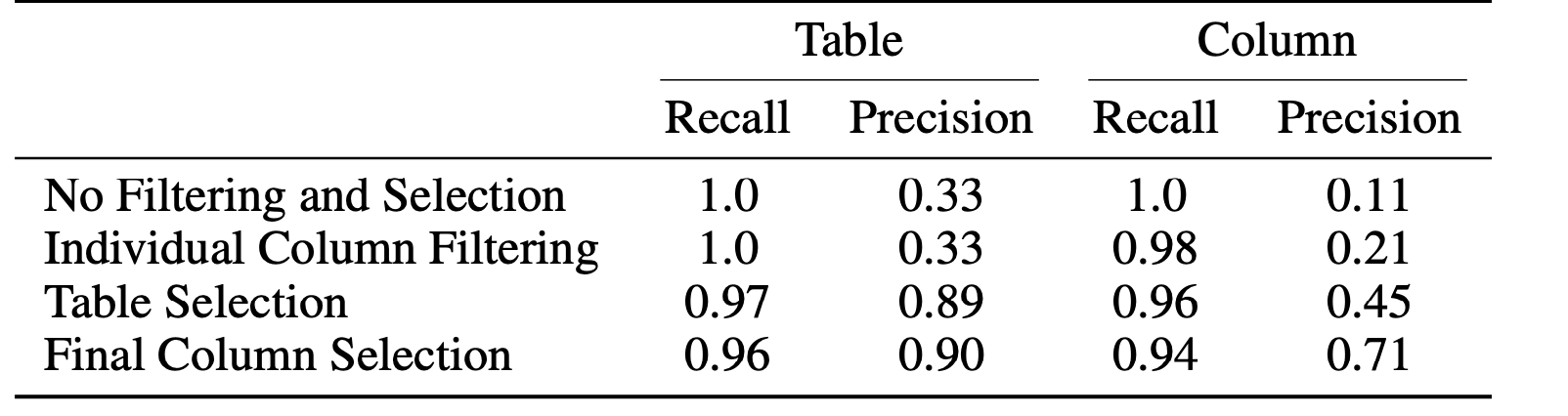
模式选择的评估:
具体说明:
1.keyword extraction:直接将语句和evidence传输给大模型要求大模型直接解析出其中的keywords
2.entity retrieval:获取上一步的keywords,根据keywords和OpenAI embeddings打分,获取相似的列。使用预处理阶段获得的LSH获取相似的值。
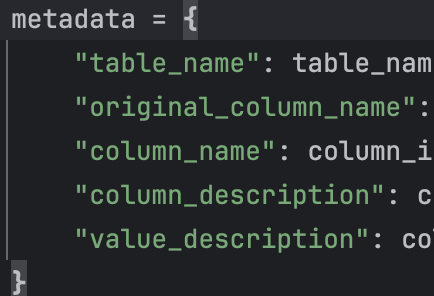
3.context retrieval:使用向量数据库,获得最相关的k个列,并将它们的描述(包括列别名,列描述,值描述)一起输出。其中的向量数据库是在预处理阶段,根据下图的参数构建的。
4.LSH(局部敏感哈希):
(1)什么是LSH:
用于估计两个文档的相似度的,较小时可以直接使用Jaccard系数来评估,过大时则需要使用Minhash函数来估计Jaccard系数
假设我们有两个文档:
- 文档 A: "abc"
- 文档 B: "bcd"
Step 1: 生成 Shingles
- 文档 A 的 2-grams: {ab, bc}
- 文档 B 的 2-grams: {bc, cd}
Step 2: 应用哈希函数
假设我们有两个哈希函数:h1 和 h2
h1 对应哈希值:ab -> 1, bc -> 2, cd -> 3
h2 对应哈希值:ab -> 2, bc -> 1, cd -> 2
Step 3: 生成 MinHash 签名
- 对文档 A (shingles: {ab, bc}):
h1 最小值: min(1, 2) = 1
h2 最小值: min(2, 1) = 1 - MinHash 签名: (1, 1)
- 对文档 B (shingles: {bc, cd}):
h1 最小值: min(2, 3) = 2
h2 最小值: min(1, 2) = 1 - MinHash 签名: (2, 1)
Step 4: 估计 Jaccard 系数
比较两个文档的 MinHash 签名:
- 签名相同位置上相同值的比例: 1/2
(2)在预处理阶段如何创建LSH:
先在预处理阶段获取所有的唯一值,然后计算minhash,并插入到LSH中
5.column filtering:从全部数据开始筛选,根据entity_retrieval的similar_value还有问题和evidence的信息挨个询问列是否是相关的,排除掉所有明显不相关的列并获得思维链,然后将entity_retrieval中similar_columns的列加入并且将所有表连接的外键加入。
6.table selection:根据上一步的值,entity_retrieval中的similar_values、context_retrieval的值生成scheme的字符串,然后询问大模型,获得选择的表和思维链(选择相应表的理由)。最后使用entity_retrieval中similar_columns的结果与当前结果和在一起,然后增加外键
7.column selection:与table selection类似,只不过询问的是每一个列
8.candidate generation:根据entity_retrieval的similar_value和context_retrieval的schema_with_description和上一步的结果来直接获取sql和生成sql的逻辑链
9.revision:根据entity_retrieval的similar_value和context_retrieval的schema_with_description和全部的数据库schema来构建schema。然后检查上一步的结果的sql是否是正确的。之后找到错误的实体。最后将sql语句,错误的实体塞给大模型,让其进行修正
10.错误实体寻找方法:根据sql中实体和值的结果在entity_retrieval的similar_value的结果比对,不在这里面的,给它在其中找一个最相似的实体出来,然后根据模板生成一个提示
11.为了让candidate generation生成更好的SQL,微调了DeepSeek Coder 34B模型,其中在构建微调数据集中插入了一些不正确的表和列(它们与正常的schema共享相似的命名规范和语义属性),根据论文中消融实验的结果表明,确实更好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









