




🤵♂️ 个人主页:@rain雨雨编程
😄微信公众号:rain雨雨编程
✍🏻作者简介:持续分享机器学习,爬虫,数据分析
🐋 希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
🌟 引言
你是否曾想过,如何用Python一键爬取酷狗音乐Top500排行榜的歌曲信息?今天,我将带你走进Python爬虫的世界,教你如何轻松获取歌曲的排名、歌名、歌手和时长等信息。这不仅是一个技术挑战,更是一个提升编程技能的绝佳机会!
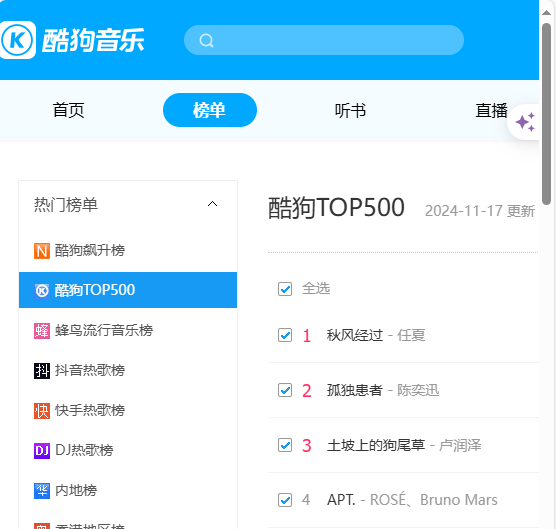
📸 效果图
这张效果图展示了酷狗音乐Top500排行榜的一部分。可以看到,每首歌曲的信息都被清晰地列出,包括排名、歌名、歌手和时长。这样的布局使得用户可以快速浏览和查找他们感兴趣的歌曲。

🛠️ 导入必要的模块
在开始之前,我们需要导入一些Python模块。我们将使用requests模块来发送HTTP请求,os模块处理文件和目录操作。
进入控制台输入:建议使用国内镜像源
pip install requests -i https://mirrors.aliyun.com/pypi/simple
如果你遇到模块报错,可以通过以下国内镜像源安装:
-
清华大学:
https://pypi.tuna.tsinghua.edu.cn/simple -
阿里云:
https://mirrors.aliyun.com/pypi/simple/ -
豆瓣:
https://pypi.douban.com/simple/ -
百度云:
https://pypi.baidu.com/pypi/simple/ -
中科大:
https://pypi.mirrors.ustc.edu.cn/simple/ -
华为云:
https://mirrors.huaweicloud.com/repository/pypi/simple/ -
腾讯云:
https://mirrors.cloud.tencent.com/pypi/simple/
🌐 发送GET请求获取响应数据
我们将设置请求头部信息,模拟浏览器的请求,以获取响应数据的JSON格式内容。以下是如何设置请求头并发送GET请求的示例代码:
def get_html(url):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
response = requests.get(url=url, headers=header)
return response.json()
🔍 如何获取请求头
如果你不熟悉如何获取请求头,可以按照以下步骤操作:
-
打开目标网页并右键点击页面空白处。
-
选择“检查元素”选项,或按下快捷键
Ctrl + Shift + C(Windows)。 -
在开发者工具窗口中,切换到“网络”选项卡。
-
刷新页面以捕获所有的网络请求。
-
在请求列表中选择您感兴趣的请求。
-
在右侧的“请求标头”或“Request Headers”部分,即可找到请求头信息。
🎶 爬取酷狗TOP500排行榜
接下来,我们将从酷狗音乐排行榜中提取歌曲的排名、歌名、歌手和时长等信息。以下是具体步骤:
-
导入模块:
requests用于发送HTTP请求,BeautifulSoup用于解析HTML,time用于控制爬虫的速度。 -
设置请求头部信息:通过
headers字典设置User-Agent,模拟浏览器发送请求,防止被网站封禁。 -
**定义函数
get_info(url)**:该函数接收一个URL参数,用于爬取指定网页的信息。 -
发送网络请求并解析HTML:使用
requests.get()函数发送GET请求获取网页的HTML内容,并使用BeautifulSoup模块解析HTML。 -
通过CSS选择器定位需要的信息:使用
select()方法根据CSS选择器定位到歌曲的排名、歌名和时长等元素。 -
循环遍历每个信息并存储到字典中:使用
zip()函数将排名、歌名和时长等元素打包成一个迭代器,然后通过循环遍历,将每个信息存储到data字典中。 -
打印获取到的信息:使用
print()函数打印data字典中的信息。 -
主程序入口:使用
if __name__ == '__main__':判断当前文件是否被直接执行,如果是则执行以下代码。 -
构造要爬取的页面地址列表:使用列表推导式构造一个包含要爬取的页面地址的列表。
-
调用函数获取页面信息:使用
for循环遍历页面地址列表,并调用get_info()函数获取每个页面的信息。 -
控制爬虫速度:使用
time.sleep()函数控制爬虫的速度,防止过快被封IP。
💻 源码
以下是完整的源码,你可以直接复制并在你的Python环境中运行:
import requests
from bs4 import BeautifulSoup
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
def get_info(url):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank, title, time in zip(ranks, titles, times):
data = {
"rank": rank.get_text().strip(),
"singer": title.get_text().replace("\n", "").replace("\t", "").split('-')[1],
"song": title.get_text().replace("\n", "").replace("\t", "").split('-')[0],
"time": time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls = ["https://www.kugou.com/yy/rank/home/{}-8888.html".format(str(i)) for i in range(1, 24)]
for url in urls:
get_info(url)
time.sleep(1)
文章持续跟新,可以微信搜一搜公众号 [ rain雨雨编程 ],第一时间阅读,涉及数据分析,机器学习,Java编程,爬虫,实战项目等。






















 到【灌水乐园】发言
到【灌水乐园】发言







