







🤵♂️ 个人主页:@rain雨雨编程
😄微信公众号:rain雨雨编程
✍🏻作者简介:持续分享机器学习,爬虫,数据分析
🐋 希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、项目概述
在传统的数据分析平台中,如果我们想要分析近一年网站的用户增长趋势,通常需要手动导入数据、选择要分析的字段和图表,并由专业的数据分析师完成分析,最后得出结论。
然而,本次设计的项目与传统平台有所不同。在这个项目中,用户只需输入想要分析的目标,并上传原始数据,系统将利用AI 自动生成可视化图表和学习的分析结论。这样,即使是对数据分析一窍不通的人也能轻松使用该系统。
二、项目介绍
问:什么是 BI ?
答:即商业智能(数据可视化、报表可视化系统)ヾ(´・ω・`)ノ
主流 BI平台:帆软 BI、小马 BI、微软 Power BI
💡 传统 BI 平台需要按照以下步骤:
-
手动上传数据
-
手动选择分析所需的数据行和列(由数据分析师完成)
-
需要手动选择所需的图表类型(由数据分析师完成)
-
生成图表并保存配置 本次项目所设想的智能
BI平台
与传统的BI不同,我们的解决方案允许用户(数据分析者)仅需导入最最最原始的数据集并输入分析目标(例如网站增长趋势),即可利用 AI 自动生成符合要求的图表和结论,从而显著提升分析效率。
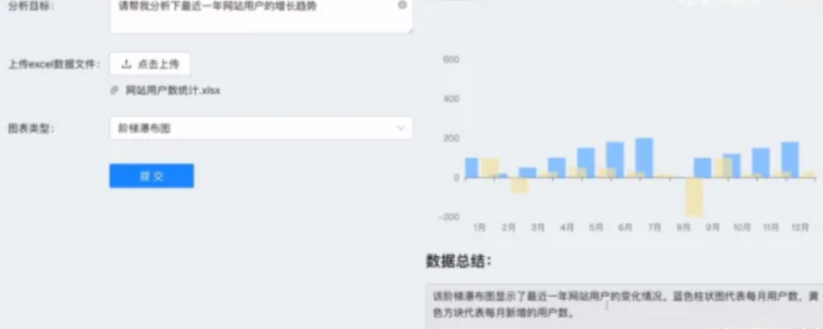
优点:即使没有数据分析经验,也能通过简单的输入目标快速完成数据分析,从而大幅减少人力成本。
三、智能分析业务开发
1. 业务流程
-
用户输入
-
分析目标
-
上传原始数据(
excel) -
更精细化地控制图表:比如图表类型、图表名称等
-
后端校验
-
校验用户的输入否合法(比如长度)
-
成本控制(次数统计和校验、鉴权等)
-
把处理后的数据输入给
AI模型,让AI模型给我们提供图表信息、结论文本 -
图表信息(是一段
json配置,是一段代码)、结论文本在前端进行展示
2. 开发接口
/**
* 智能分析
*
* @param multipartFile
* @param genChartByAiRequest
* @param request
* @return
*/
@PostMapping("/gen")
public BaseResponse<String> genChartByAi(@RequestPart("file") MultipartFile multipartFile,
GenChartByAiRequest genChartByAiRequest, HttpServletRequest request) {
String name = genChartByAiRequest.getName();
String goal = genChartByAiRequest.getGoal();
String chartType = genChartByAiRequest.getChartType();
// 校验
// 如果分析目标为空,就抛出请求参数错误异常,并给出提示
ThrowUtils.throwIf(StringUtils.isBlank(goal), ErrorCode.PARAMS_ERROR, "目标为空");
// 如果名称不为空,并且名称长度大于100,就抛出异常,并给出提示
ThrowUtils.throwIf(StringUtils.isNotBlank(name) && name.length() > 100, ErrorCode.PARAMS_ERROR, "名称过长");
// 读取到用户上传的 excel 文件,进行一个处理
User loginUser = userService.getLoginUser(request);
// 文件目录:根据业务、用户来划分
String uuid = RandomStringUtils.randomAlphanumeric(8);
String filename = uuid + "-" + multipartFile.getOriginalFilename();
File file = null;
try {
// 返回可访问地址
return ResultUtils.success("");
} catch (Exception e) {
// log.error("file upload error, filepath = " + filepath, e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "上传失败");
} finally {
if (file != null) {
// 删除临时文件
boolean delete = file.delete();
if (!delete) {
// log.error("file delete error, filepath = {}", filepath);
}
}
}
}
3. 原始数据压缩
回到智能分析。
-
首先,是获取用户的输入和
excel文件。读取到用户上传的
excel文件之后,进行一个处理,要进行什么处理呢? -
用
chatGPT也好,还是用星火,无论使用哪种AI模型,输入都是数据而非文件。那怎么输入数据呢?ps.
AI接口普遍都有输入字数限制。所以我们要尽可能压缩数据,能够允许多传一些数据。
Al提词技巧1:持续输入,持续优化
AI提词技巧2:数据压缩(内容压缩,比如把很长的内容提取关键词,也可以让Al来做)
-
去写一个工具类(
excel转csv),在com.yupi.springbootinit.utils下创建ExcelUtils.java。怎么处理
excel?使用csv对excel文件的数据进行提取和压缩 👉 开源库
我们请求接收的是multipartFile。
package com.yupi.springbootinit.utils;
import cn.hutool.core.collection.CollUtil;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.support.ExcelTypeEnum;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.ObjectUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* Excel 相关工具类
*/
@Slf4j
public class ExcelUtils {
/**
* excel 转 csv
*
* @param multipartFile
* @return
*/
public static String excelToCsv(MultipartFile multipartFile) {
// File file = null;
// try {
// file = ResourceUtils.getFile("classpath:网站数据.xlsx");
// } catch (FileNotFoundException e) {
// e.printStackTrace();
// }
// 读取数据
List<Map<Integer, String>> list = null;
try {
list = EasyExcel.read(multipartFile.getInputStream())
.excelType(ExcelTypeEnum.XLSX)
.sheet()
.headRowNumber(0)
.doReadSync();
} catch (IOException e) {
log.error("表格处理错误", e);
}
// 如果数据为空
if (CollUtil.isEmpty(list)) {
return "";
}
// 转换为 csv
StringBuilder stringBuilder = new StringBuilder();
// 读取表头(第一行)
LinkedHashMap<Integer, String> headerMap = (LinkedHashMap) list.get(0);
List<String> headerList = headerMap.values().stream().filter(ObjectUtils::isNotEmpty).collect(Collectors.toList());
stringBuilder.append(StringUtils.join(headerList, ",")).append("\n");
// 读取数据(读取完表头之后,从第一行开始读取)
for (int i = 1; i < list.size(); i++) {
LinkedHashMap<Integer, String> dataMap = (LinkedHashMap) list.get(i);
List<String> dataList = dataMap.values().stream().filter(ObjectUtils::isNotEmpty).collect(Collectors.toList());
stringBuilder.append(StringUtils.join(dataList, ",")).append("\n");
}
return stringBuilder.toString();
}
public static void main(String[] args) {
excelToCsv(null);
}
}
现在要真实地把它移到我们的请求处理,咱们前端请求传来的是multipartFile,把multipartFile传进来,其他的东西先注释。
/**
* 智能分析
*
* @param multipartFile
* @param genChartByAiRequest
* @param request
* @return
*/
@PostMapping("/gen")
public BaseResponse<String> genChartByAi(@RequestPart("file") MultipartFile multipartFile,
GenChartByAiRequest genChartByAiRequest, HttpServletRequest request) {
String name = genChartByAiRequest.getName();
String goal = genChartByAiRequest.getGoal();
String chartType = genChartByAiRequest.getChartType();
// 校验
// 如果分析目标为空,就抛出请求参数错误异常,并给出提示
ThrowUtils.throwIf(StringUtils.isBlank(goal), ErrorCode.PARAMS_ERROR, "目标为空");
// 如果名称不为空,并且名称长度大于100,就抛出异常,并给出提示
ThrowUtils.throwIf(StringUtils.isNotBlank(name) && name.length() > 100, ErrorCode.PARAMS_ERROR, "名称过长");
// 把multipartFile传进来,其他的东西先注释
String result = ExcelUtils.excelToCsv(multipartFile);
return ResultUtils.success(result);
// // 读取到用户上传的 excel 文件,进行一个处理
// User loginUser = userService.getLoginUser(request);
// // 文件目录:根据业务、用户来划分
// String uuid = RandomStringUtils.randomAlphanumeric(8);
// String filename = uuid + "-" + multipartFile.getOriginalFilename();
// File file = null;
// try {
//
// // 返回可访问地址
// return ResultUtils.success("");
// } catch (Exception e) {
log.error("file upload error, filepath = " + filepath, e);
// throw new BusinessException(ErrorCode.SYSTEM_ERROR, "上传失败");
// } finally {
// if (file != null) {
// // 删除临时文件
// boolean delete = file.delete();
// if (!delete) {
log.error("file delete error, filepath = {}", filepath);
// }
// }
// }
}
4. 调用AI
引入依赖
<!--修改version为最新稳定版-->
<dependency>
<groupId>io.github.briqt</groupId>
<artifactId>xunfei-spark4j</artifactId>
<version>1.3.0</version>
</dependency>
然后刷新 maven 就安装成功
配置
xun-fei:
client:
appId:
apiSecret:
apiKey:
注意这个是和spring同级目录
读取配置文件
/**
* @author leikooo
* @Description 星火 AI 配置类
*/
@Configuration
@ConfigurationProperties(prefix = "xun-fei.client")
@Data
public class XingHuoConfig {
private String appId;
private String apiSecret;
private String apiKey;
@Bean
public SparkClient sparkClient() {
SparkClient sparkClient = new SparkClient();
sparkClient.apiKey = apiKey;
sparkClient.apiSecret = apiSecret;
sparkClient.appid = appId;
return sparkClient;
}
}
下面配置,写在 resource/META-INF/additional-spring-configuration-metadata.json
作用是不让星火配置文件变黄
{
"properties": [
{
"name": "xun-fei.client.appId",
"type": "java.lang.String"
},
{
"name": "xun-fei.client.apiSecret",
"type": "java.lang.String"
},
{
"name": "xun-fei.client.apiKey",
"type": "java.lang.String"
}
]
}
调用
确认版本
注意自己 API 的版本,最近免费领的绝大部分都是 3.5 版本,好像是又换了名称但是问题不大,具体对应关系:
https://www.xfyun.cn/doc/spark/Web.html#_1-%E6%8E%A5%E5%8F%A>3%E8%AF%B4%E6%98%8E 具体以官网为准
这个 wss://spark-api.xf-yun.com/v3.5/chat 或者是 wss://spark-api.xf-yun.com/v4.0/chat 中间的 v3.5 、v4.0 这个就是 sendMsgToXingHuo 这个方法里面 apiVersion 的值,看看自己是 v3.5 还是 v4.0
SparkRequest sparkRequest = SparkRequest.builder()
// 消息列表
.messages(messages)
// 模型回答的tokens的最大长度,非必传,取值为[1,4096],默认为2048
.maxTokens(2048)
// 核采样阈值。用于决定结果随机性,取值越高随机性越强即相同的问题得到的不同答案的可能性越高 非必传,取值为[0,1],默认为0.5
.temperature(0.6)
// 指定请求版本
// 具体版本看官方文档 https://www.xfyun.cn/doc/spark/Web.html#_1-%E6%8E%A5%E5%8F%A3%E8%AF%B4%E6%98%8E
// todo 重点修改
.apiVersion(SparkApiVersion.V4_0)
.build();
优化 Promote
请严格按照下面的输出格式生成结果,且不得添加任何多余内容(例如无关文字、> 注释、代码块标记或反引号):
'【【【【' { 生成 Echarts V5 的 option 配置对象 JSON 代码,要求为合法 JSON 格式> 且不含任何额外内容(如注释或多余字符) } '【【【【' 结论: { 提供对数据的详细分析结论,内容应尽可能准确、详细,不允许添加其他无关文字> 或注释 }
示例: 输入: 分析需求: 分析网站用户增长情况,请使用柱状图展示 原始数> > 据: 日期,用户数 1号,10 2号,20 3号,30
期望输出: '【【【【' { "title": { "text": "分析网站用户增长情况" > > }, "xAxis": { "type": "category", "data": ["1号", "2号", "3> > 号"] }, "yAxis": { "type": "value" }, "series": [ { "name": > > "用户数", "type": "bar", "data": [10, 20, 30] } ] } '【【【【' > 结论: 从数据看,网站用户数由1号的10人增长到2号的20人,再到3号的30人,> 呈现出明显的上升趋势。这表明在这段时间内网站用户吸引力增强,可能与推广活> 动、内容更新或其他外部因素有关。
调用
@Service
@Slf4j
public class AIManager {
@Resource
private SparkClient sparkClient;
/**
* 向 AI 发送请求
*
* @param isNeedTemplate 是否使用模板,进行 AI 生成; true 使用 、false 不使用 ,false 的情况是只想用 AI 不只是生成前端代码
* @param content 内容
* 分析需求:
* 分析网站用户的增长情况
* 原始数据:
* 日期,用户数
* 1号,10
* 2号,20
* 3号,30
* @return AI 返回的内容
* '【【【【'
* <p>
* '【【【【'
*/
public String sendMsgToXingHuo(boolean isNeedTemplate, String content) {
List<SparkMessage> messages = new ArrayList<>();
if (isNeedTemplate) {
// AI 生成问题的预设条件
String predefinedInformation = "请严格按照下面的输出格式生成结果,且不得添加任何多余内容(例如无关文字、注释、代码块标记或反引号):\n" +
"\n" +
"'【【【【'" +
"{ 生成 Echarts V5 的 option 配置对象 JSON 代码,要求为合法 JSON 格式且不含任何额外内容(如注释或多余字符) } '【【【【' 结论: {\n" +
"提供对数据的详细分析结论,内容应尽可能准确、详细,不允许添加其他无关文字或注释 }\n" +
"\n" +
"示例: 输入: 分析需求: 分析网站用户增长情况,请使用柱状图展示 原始数据: 日期,用户数 1号,10 2号,20 3号,30\n" +
"\n" +
"期望输出: '【【【【' { \"title\": { \"text\": \"分析网站用户增长情况\" }, \"xAxis\": { \"type\": \"category\", \"data\": [\"1号\", \"2号\", \"3号\"] }, \"yAxis\": { \"type\": \"value\" }, \"series\": [ { \"name\": \"用户数\", \"type\": \"bar\", \"data\": [10, 20, 30] } ] } '【【【【' 结论: 从数据看,网站用户数由1号的10人增长到2号的20人,再到3号的30人,呈现出明显的上升趋势。这表明在这段时间内网站用户吸引力增强,可能与推广活动、内容更新或其他外部因素有关。";
messages.add(SparkMessage.systemContent(predefinedInformation + "\n" + "----------------------------------"));
}
messages.add(SparkMessage.userContent(content));
// 构造请求
SparkRequest sparkRequest = SparkRequest.builder()
// 消息列表
.messages(messages)
// 模型回答的tokens的最大长度,非必传,取值为[1,4096],默认为2048
.maxTokens(2048)
// 核采样阈值。用于决定结果随机性,取值越高随机性越强即相同的问题得到的不同答案的可能性越高 非必传,取值为[0,1],默认为0.5
.temperature(0.6)
// 指定请求版本
.apiVersion(SparkApiVersion.V4_0)
.build();
// 同步调用
String responseContent = sparkClient.chatSync(sparkRequest).getContent().trim();
if (!isNeedTemplate) {
return responseContent;
}
log.info("星火 AI 返回的结果 {}", responseContent);
AtomicInteger atomicInteger = new AtomicInteger(1);
while (responseContent.split("'【【【【'").length < 3) {
responseContent = sparkClient.chatSync(sparkRequest).getContent().trim();
if (atomicInteger.incrementAndGet() >= 4) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "星火 AI 生成失败");
}
}
return responseContent;
}
}
测试
测试代码
/**
* @author <a href="https://github.com/lieeew">leikooo</a>
* @date 2024/9/12
* @description
*/
@SpringBootTest(classes = MainApplication.class)
public class TestJava {
@Resource
private AIManager aiManager;
// import org.junit.jupiter.api.Test;
@Test
public void test() {
String c = "分析需求:\n" +
"分析网站用户的增长情况 \n" +
"请使用 柱状图 \n" +
"原始数据:\n" +
"日期,用户数\n" +
"1号,10\n" +
" 2号,20\n" +
" 3号,30";
String s = aiManager.sendMsgToXingHuo(true, c);
System.out.println("s = " + s);
}
}
文章持续跟新,可以微信搜一搜公众号 [ rain雨雨编程 ],第一时间阅读,涉及数据分析,机器学习,Java编程,爬虫,实战项目等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









