







[DM]python3爬取网页信息存储到达梦(含源码)
申明:本爬虫代码供学习使用,爬取到的资料不商用,出现法律等问题概不负责。
项目功能
通过python爬取网页上面高清图片信息,存储到达梦数据库
技术栈
python3.6.8 + DM8
环境
| 类型 | 版本 |
|---|---|
| 服务器 | CentOS Linux release 7.6.1810 (Core) |
| 数据库 | dm8_20221020_x86_rh6_64 |
| python | 3.6.8 |
| 网页 | https://sc.chinaz.com/ |
Python3驱动安装
#!/usr/bin/python3
#coding:utf-8
import requests
from lxml import etree
import dmPython
import re
import rarfile
import os
1. DM8驱动安装
python3.6.8 安装dmPython驱动: 类似python2.7.5安装,具体命令如下:
#进入数据库安装目录drivers/python/dmPython
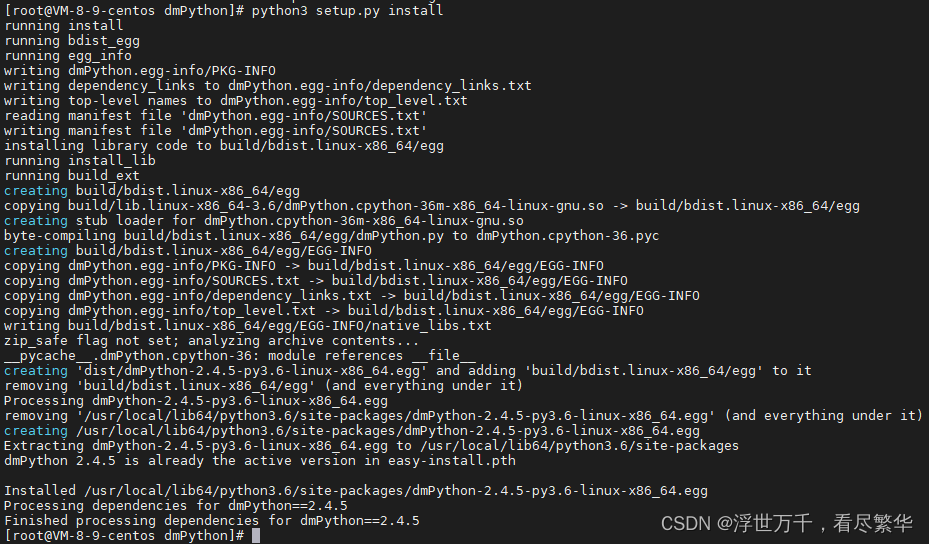
python3 setup.py install
安装成功如下图:
报错:fatal error: Python.h: No such file or directory
yum install python3-devel
2.requests、lxml 、rarfile驱动安装
#requests
pip3 install requests
#lxml
pip3 install lxml
rarfile安装:
- 下载linux系统对应的文件:rarlab官网
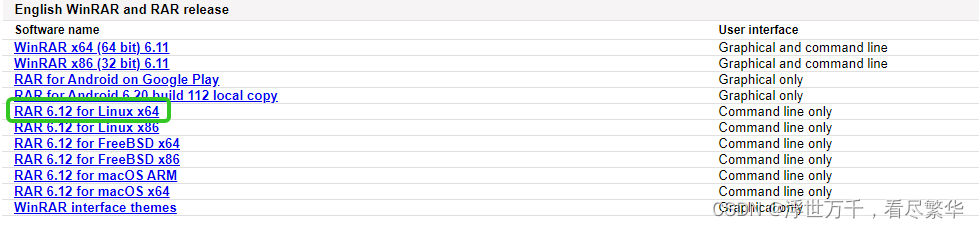
- 上传、解压、安装
tar -xzvf rarlinux-x64-612.tar.gz
cd rar
make
make install
初始化数据库脚本
#创建表空间
CREATE TABLESPACE "PICTURE" DATAFILE 'PICTURE' SIZE 150 AUTOEXTEND ON;
#创建用户
CREATE USER "PICTURE" IDENTIFIED BY "********"
LIMIT FAILED_LOGIN_ATTEMPS 3, PASSWORD_LOCK_TIME 1, PASSWORD_GRACE_TIME 10
DEFAULT TABLESPACE "PICTURE";
#授权
GRANT "RESOURCE" TO "PICTURE";
GRANT ALTER DATABASE,CREATE ROLE,CREATE SCHEMA,CREATE TABLE,CREATE VIEW,CREATE PROCEDURE,
CREATE SEQUENCE,CREATE TRIGGER,CREATE INDEX,CREATE CONTEXT INDEX,BACKUP DATABASE,
CREATE LINK,CREATE PACKAGE,CREATE SYNONYM,CREATE PUBLIC SYNONYM,DROP ROLE,DROP PUBLIC SYNONYM,
CREATE TABLESPACE,ALTER TABLESPACE,DROP TABLESPACE TO "PICTURE";
#创建表
CREATE TABLE "PICTURE"."images"
(
"id" INT IDENTITY(1, 1) NOT NULL,
"name" VARCHAR(100),
"file_name" VARCHAR(100),
"size" NUMBER(22,0),
"image" BLOB,
NOT CLUSTER PRIMARY KEY("id")) STORAGE(ON "MOVIES", CLUSTERBTR) ;
COMMENT ON TABLE "MOVIES"."images" IS '图片表';
COMMENT ON COLUMN "MOVIES"."images"."id" IS '主键';
COMMENT ON COLUMN "MOVIES"."images"."name" IS '名称';
COMMENT ON COLUMN "MOVIES"."images"."file_name" IS '文件名称';
COMMENT ON COLUMN "MOVIES"."images"."size" IS '图片大小';
COMMENT ON COLUMN "MOVIES"."images"."image" IS '图片二进制数据';
代码介绍
- DM8数据库连接
import dmPython
try:
# 获取数据连接
conn = dmPython.connect(user='SYSDBA',password='Dameng123',server='localhost',port=10236)
# 构造一个当前连接上的 cursor 对象,用于执行操作
cursor = conn.cursor()
print('Python:conn success!')
# 关闭连接
conn.close()
except(dmPython.Error, Exception) as err:
print(err)
- 获取下载地址(部分代码)
# 根据一级地址 获取 二级地址
def get_request(self):
# 循环一级地址
for i in range(0,41):
if i == 1:
link = '*****'
else:
link = '*****' + str(i) + '.html'
# 获取临时二级地址
self.parse_html(link)
# 获取二级地址
self.split_https()
def parse_html(self,link):
req = requests.get(link)
#print("页面状态码:",req.status_code)
# 返回响应对象
html = req.content.decode('utf-8', 'ignore')
# 用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象
parse_html = etree.HTML(html)
# 过滤获取地址
r_list = parse_html.xpath('//div[@class="bot-div"]/a/@href')
# 过滤获取图片名称
rname_list = parse_html.xpath('//div[@class="bot-div"]/a/@title')
htm_list.extend(r_list)
name_list.extend(rname_list)
# 获取真实图片下载地址
def get_down_address(self):
print('开始收集下载地址')
for l in range(0,len(https_list)):
link = https_list[l]
req = requests.get(link)
html = req.content.decode('utf-8', 'ignore')
parse_html = etree.HTML(html)
r_list = parse_html.xpath('//p[@js-do="downUrl"]/a/@href')
#判断下载地址是否拿到
if len(r_list) >= 1:
down_list.append(r_list[0])
else:
down_list.append(0)
print('完成下载地址收集')
源码
#!/usr/bin/python3
#coding:utf-8
import requests
from lxml import etree
import dmPython
import re
import rarfile
import os
class CodeSpider(object):
# 初始化参数
def __init__(self):
# 二级地址
global https_list
# 临时地址
global htm_list
# 下载地址
global down_list
# 图片名称
global name_list
global conn
htm_list=[]
name_list=[]
https_list=[]
down_list=[]
try:
conn = dmPython.connect(user='SYSDBA',password='Dameng123',server='localhost',port=10236)
print('Python:conn success!')
except(dmPython.Error, Exception) as err:
print(err)
# 根据一级访问地址获取图片下载地址所在的二级页面地址和图片名称
def get_request(self):
for i in range(0,41):
if i == 1:
link = '*****'
else:
link = '*****' + str(i) + '.html'
self.parse_html(link)
self.split_https()
def parse_html(self,link):
req = requests.get(link)
#print("页面状态码:",req.status_code)
html = req.content.decode('utf-8', 'ignore')
parse_html = etree.HTML(html)
r_list = parse_html.xpath('//div[@class="bot-div"]/a/@href')
rname_list = parse_html.xpath('//div[@class="bot-div"]/a/@title')
htm_list.extend(r_list)
name_list.extend(rname_list)
def split_https(self):
for r in htm_list:
link = 'https://sc.chinaz.com' + str(r)
https_list.append(link)
# 获取图片真实下载地址
def get_down_address(self):
print('开始收集下载地址')
for l in range(0,len(https_list)):
link = https_list[l]
req = requests.get(link)
html = req.content.decode('utf-8', 'ignore')
parse_html = etree.HTML(html)
r_list = parse_html.xpath('//p[@js-do="downUrl"]/a/@href')
#判断下载地址是否拿到
if len(r_list) >= 1:
down_list.append(r_list[0])
else:
down_list.append(0)
print('完成下载地址收集')
# 图片下载
def down_images(self):
for l in range(0,len(down_list)):
link = down_list[l]
if link != 0:
name = name_list[l]
div = '/root/movies/'
# 获取URL中最后一个反斜杠/后面的内容
filename = re.findall(r"[^/]+(?!.*/)",link)[0]
req = requests.get(url=link)
html = req.content
if req.headers.get('content-type') == 'text/html':
continue
if link.endswith('.rar'):
#将按照下载到本地
with open(div + filename,'wb') as f:
f.write(html)
#判断文件不存跳过本次循环
if not os.path.exists(div + filename):
continue
#读取压缩包的文件
try:
myRarFile = rarfile.RarFile(div + filename)
except (rarfile.Error, Exception) as err:
print('error : rarfile读取压缩包失败,跳过!!')
os.remove(div + filename)
continue
for file in myRarFile.infolist():
#print(file.filename.split("/")[1].split(".")[0],filename.split(".")[0])
# 获取压缩包里面的图片
if file.filename.split("/")[1].split(".")[0] == filename.split(".")[0]:
html = myRarFile.read(file)
size = file.file_size
#插入DM数据库
self.insert_dm(name, file.filename.split("/")[1] ,size,html)
myRarFile.close()
#删除压缩包
os.remove(div + filename)
else:
size = req.headers.get('Content-Length')
#插入DM数据库
self.insert_dm(name,filename,size,html)
#插入DM8数据库
def insert_dm(self,name,filename,size,html):
#插入DM数据库
try:
cursor = conn.cursor()
cursor.execute ('insert into PICTURE.images(name,file_name,"size","image") values(?,?,?,?);',name,filename,size,html)
print(filename + ' python: insert success!')
except (dmPython.Error, Exception) as err:
print(err)
if __name__ == '__main__':
spider = CodeSpider()
spider.get_request()
spider.get_down_address()
spider.down_images()
conn.close()
执行结果
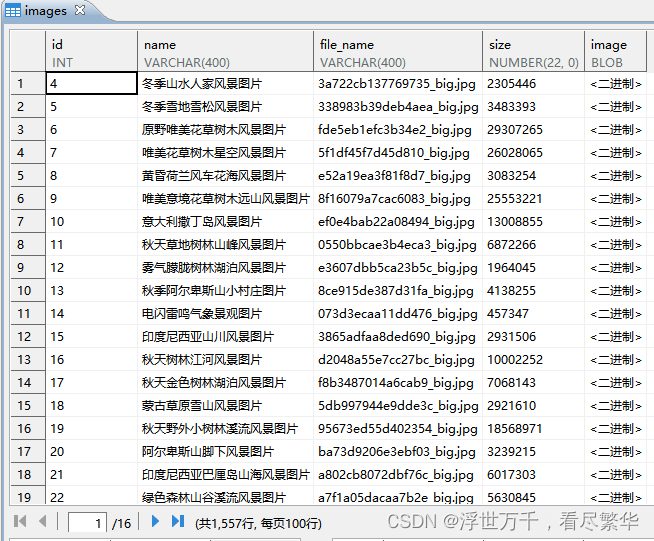
后记
如果文中那里有误,欢迎指出,大家共同交流进步!
技术参考:
python2.7.5驱动安装: https://eco.dameng.com/document/dm/zh-cn/app-dev/python-python.html
DM8下载地址: https://eco.dameng.com/download/
DM8安装手册: https://eco.dameng.com/document/dm/zh-cn/start/install-dm-linux-prepare.html















 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









