







单变量的线性回归
学习线性回归的概念,完成以下实验:
需要根据每个城市的居民的数量,预测开餐饮店的利润数据在data1.txt里,第一列是城市居民数量,第二列是该城市餐饮店利润。
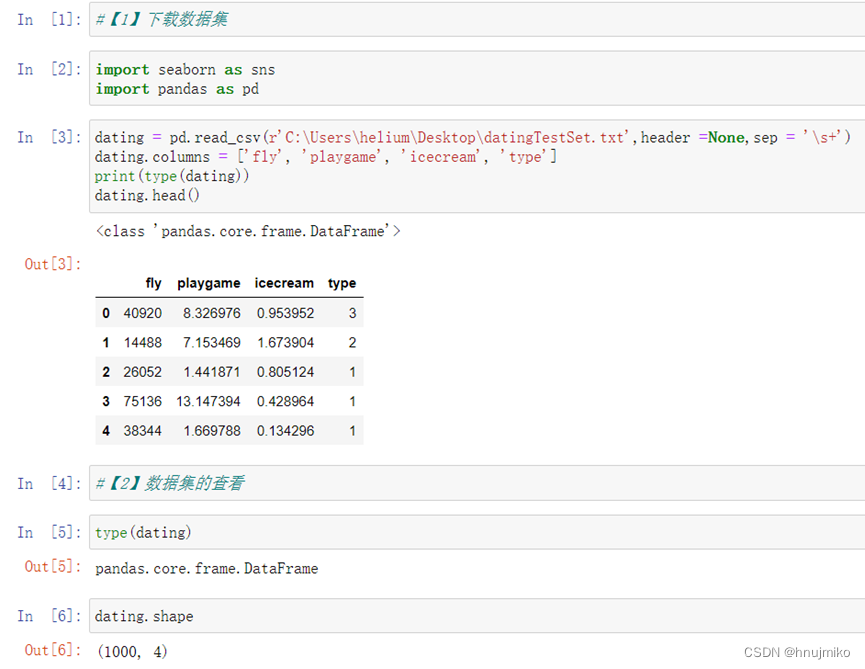
1.读入数据,然后展示数据
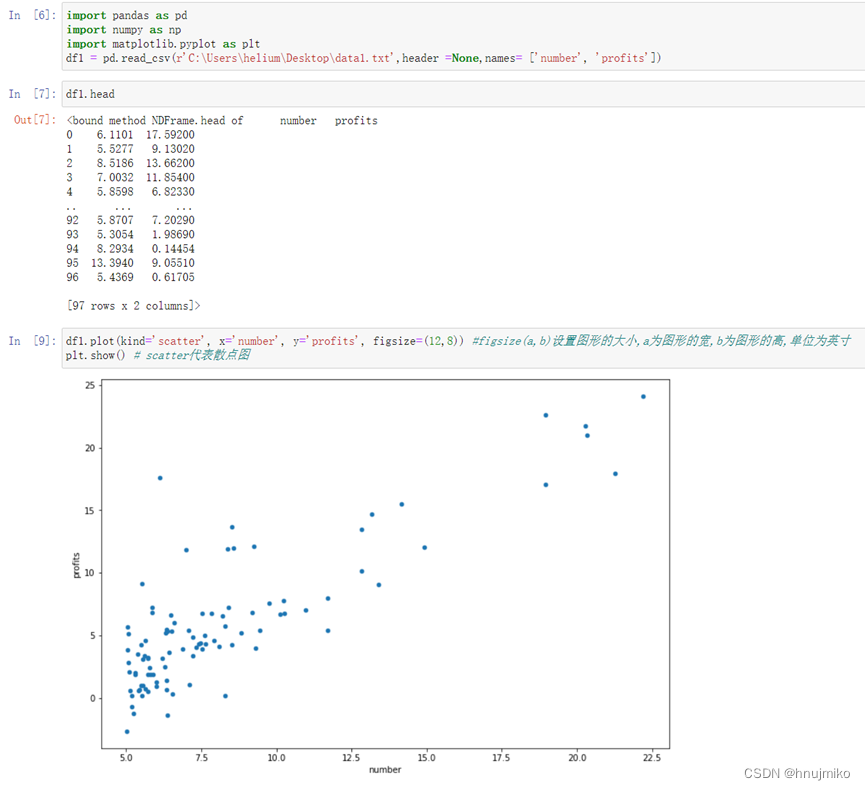
2. 梯度下降
这个部分你需要在现有数据集上,训练线性回归的参数θ
2.1 公式
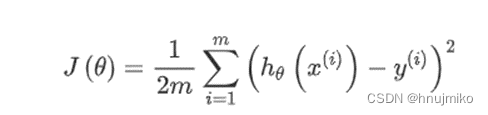
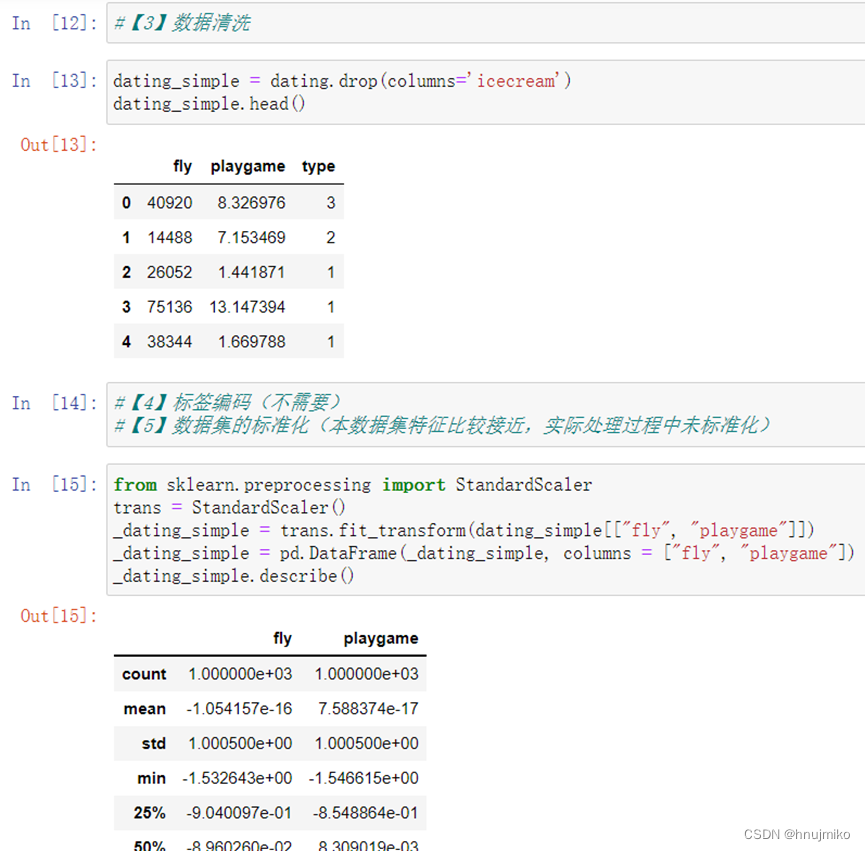
2.2 实现
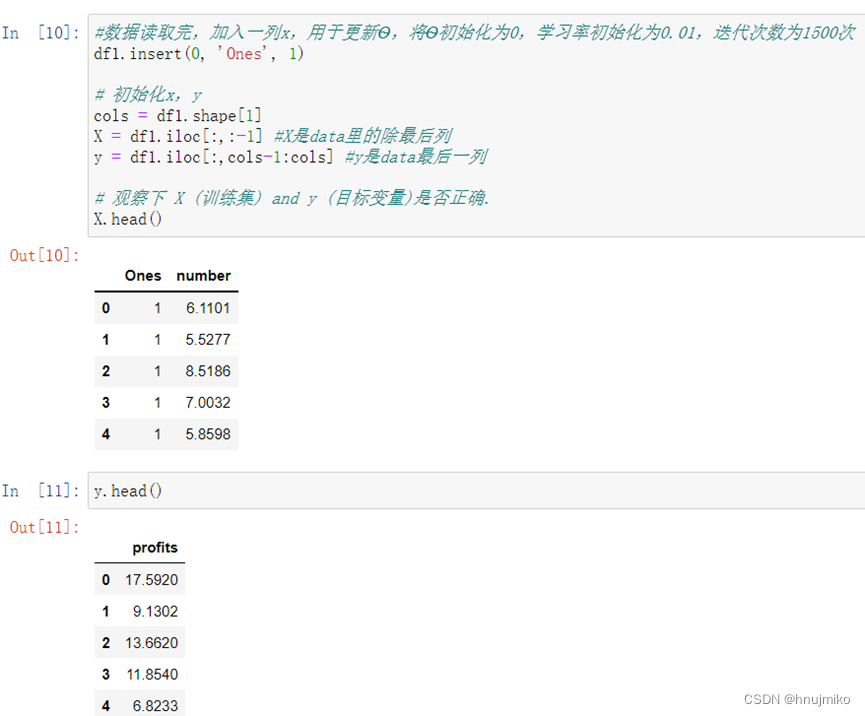
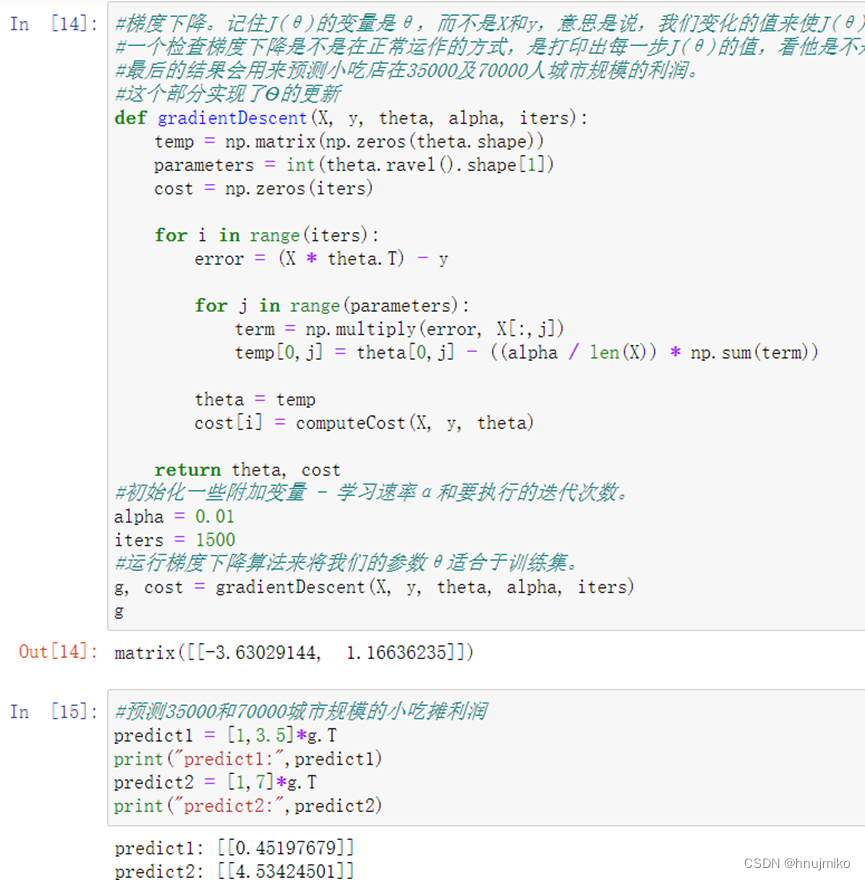
数据前面已经读取完毕,我们要为加入一列x,用于更新θ0,然后我们将θ初始化为0,学习率初始化为0.01,迭代次数为1500次
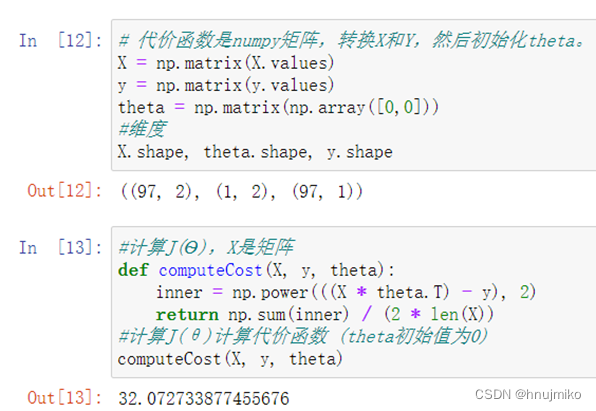
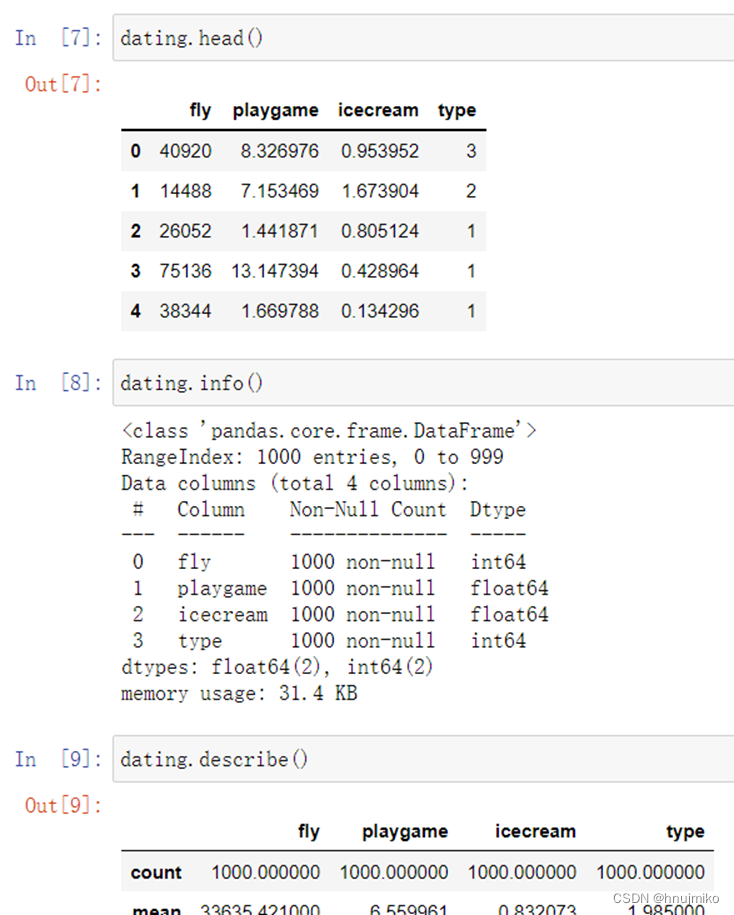
2.3 计算J(θ)
计算代价函数 (theta(θ)初始值为0)
2.4 梯度下降
记住J(θ)的变量是θ,而不是X和y,意思是说,我们变化θ的值来使J(θ)变化,而不是变化X和y的值。
一个检查梯度下降是不是在正常运作的方式,是打印出每一步J(θ)的值,看他是不是一直都在减小,并且最后收敛至一个稳定的值。
θ最后的结果会用来预测小吃店在35000及70000人城市规模的利润。
梯队下降的迭代公式: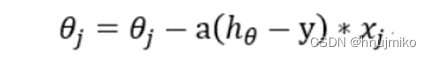
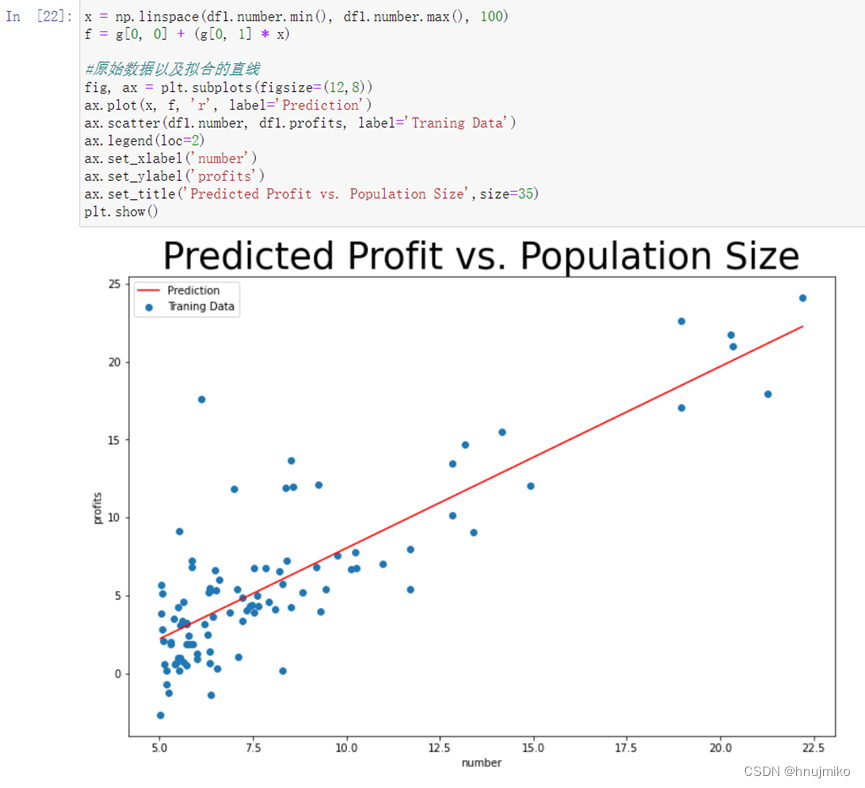
2.5 可视化J(θ)
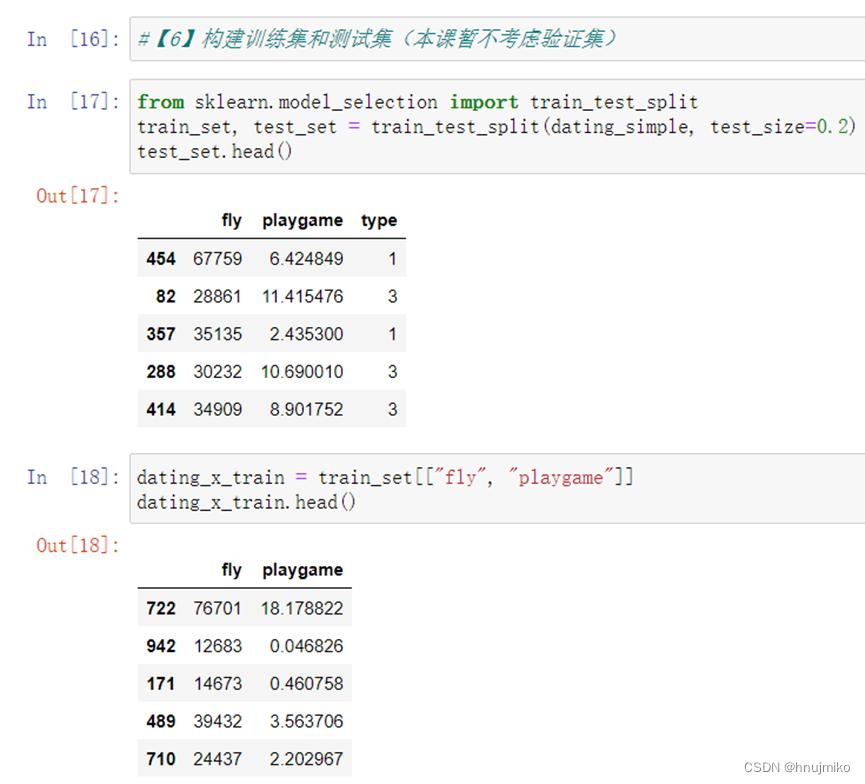
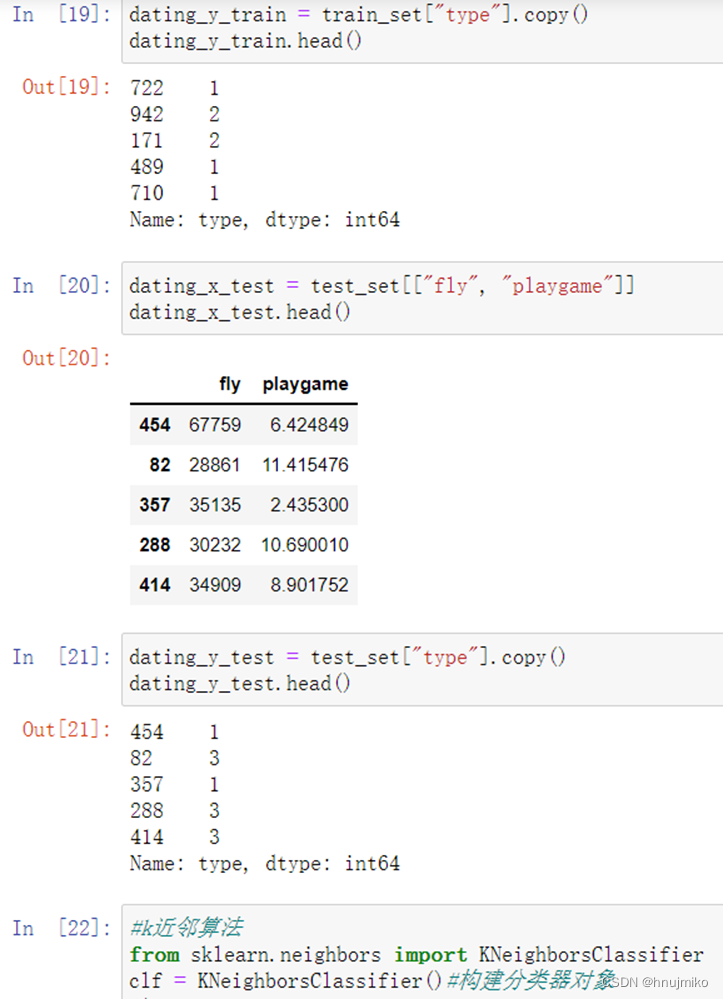
机器学习实验
1.网上阅读常用的机器学习算法,并撰写阅读报告
k近邻算法:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。与待预测点最近的训练数据集中的k个邻居,把k个近邻中最常见的类别预测为带预测点的类别。一句话说就是用你的邻居来判断你。
朴素贝叶斯算法:朴素即特征条件独立;贝叶斯即基于贝叶斯定理(P(A|B)=P(B|A) P(A) / P(B)),当X=(x1, x2)发生的时候,哪一个yk发生的概率最大。一句话说就是在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
决策树算法:CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。每次通过一个特征,将数据尽可能的分为纯净的两类,递归的分下去。一句话说就是用树的概念来分类。
逻辑回归算法:通过一个映射方式,将特征X=(x1,x2)映射成P(y=ck),求使得所有概率之积最大化的映射方式里的参数,计算p(y=ck) 取概率最大的那个类别作为预测对象的分类。面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。
支持向量机算法:以二分类为例,假设数据可用完全分开:用一个超平面将两类数据完全分开,且最近点到平面的距离最大
集成方法——随机森林:训练集m,有放回的随机抽取m个数据,构成一组,共抽取n组采样集,n组采样集训练得到n个弱分类器。弱分类器一般用决策树或神经网络,将n个弱分类器进行组合得到强分类器。
集成方法——Adaboost:训练集m,用初始数据权重训练得到第一个弱分类器,根据误差率计算弱分类器系数,更新数据的权重,使用新的权重训练得到第二个弱分类器,以此类推,根据各自系数,将所有弱分类器加权求和获得强分类器。
集成方法——梯度提升树GBDT:训练集m,获得第一个弱分类器,获得残差,然后不断地拟合残差;所有弱分类器相加得到强分类器。
其他
【1】xgboost
GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开
XGBoost损失函数对误差部分做二阶泰勒展开,更加准确,更快收敛
【2】lightgbm
微软:快速的,分布式的,高性能的基于决策树算法的梯度提升框架,速度更快。
【3】stacking
堆叠或者叫模型融合,先建立几个简单的模型进行训练,第二级学习器会基于前级模型的预测结果进行再训练
【4】神经网络
参考资料:
(15条消息) 数据挖掘领域十大经典算法之—K-邻近算法/kNN(超详细附代码)_fuqiuai的博客-CSDN博客
(15条消息) 数据挖掘领域十大经典算法之—CART算法(超详细附代码)_fuqiuai的博客-CSDN博客_cart算法代码
1.完成下面的题目一,可参考后面附的参考代码

运行代码保存为: 机器学习.ipynb
运行截图如下:
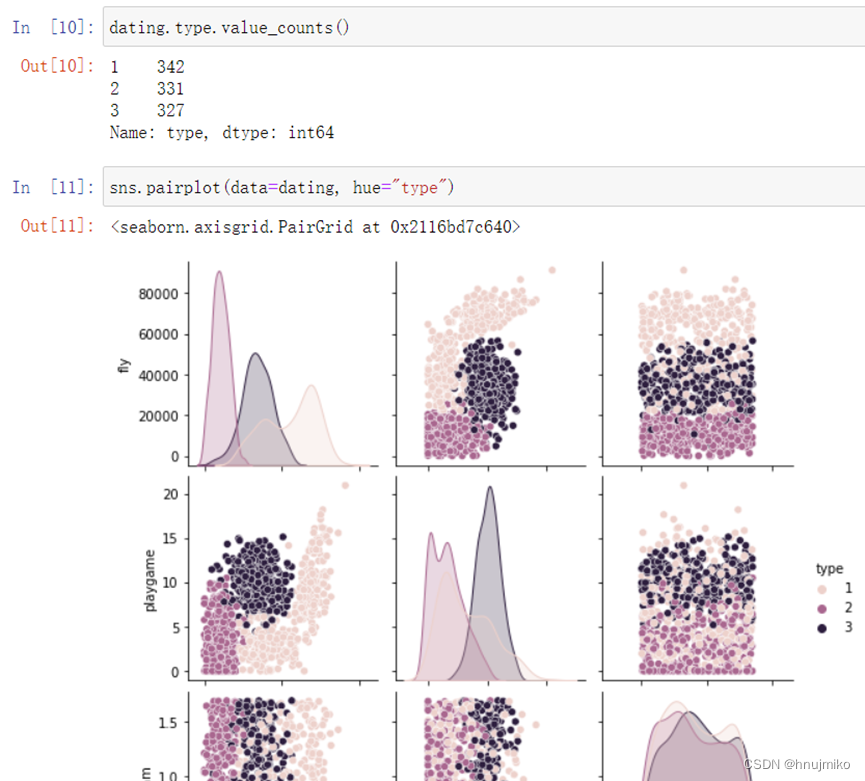
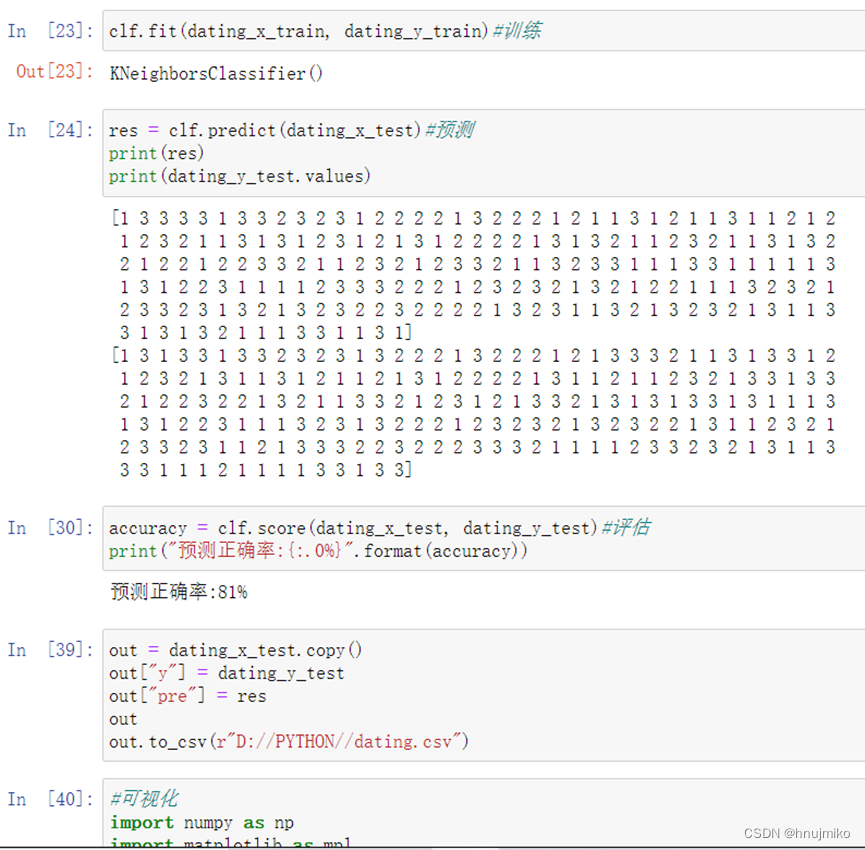
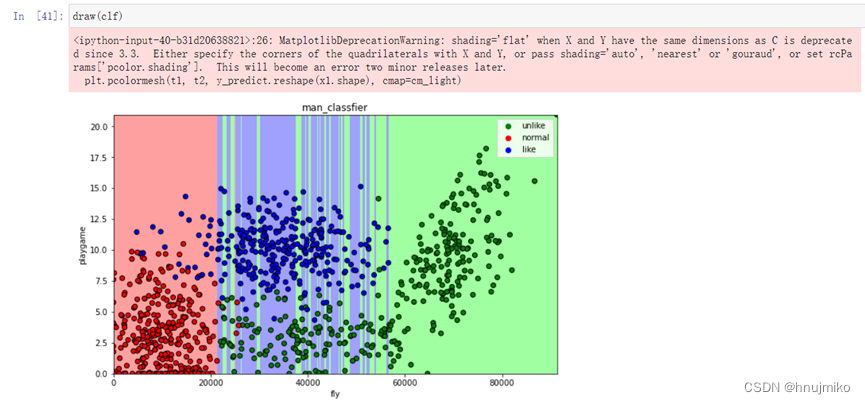
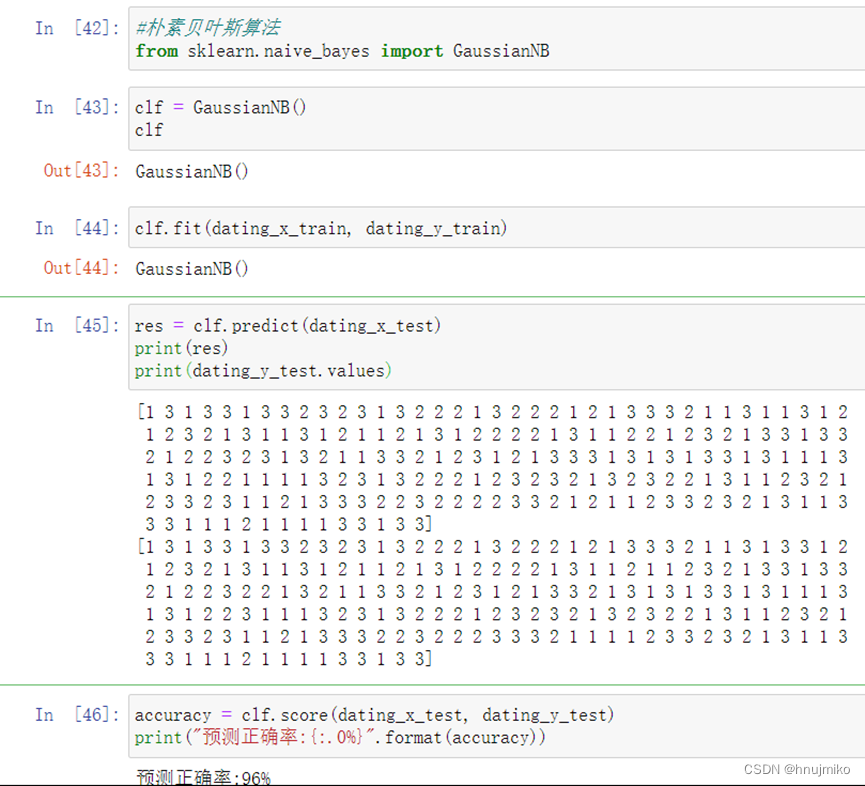
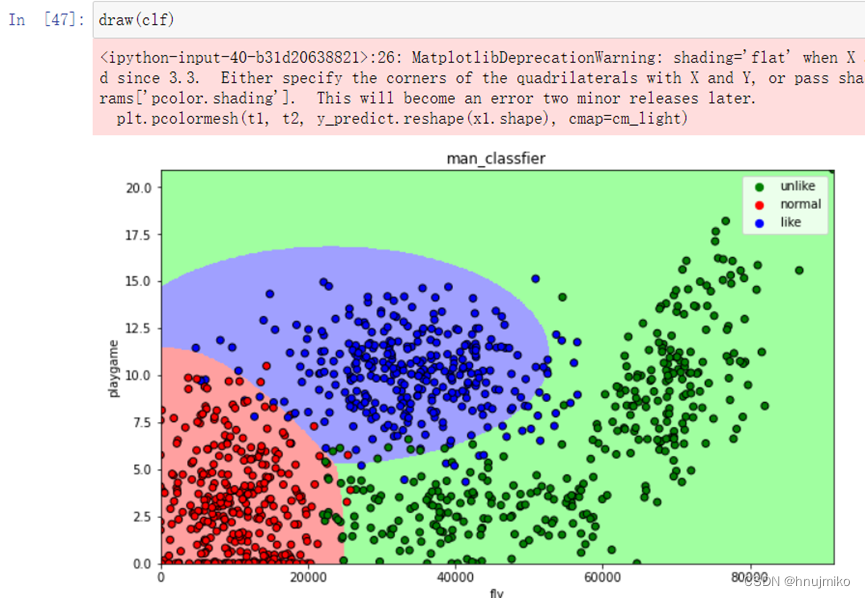

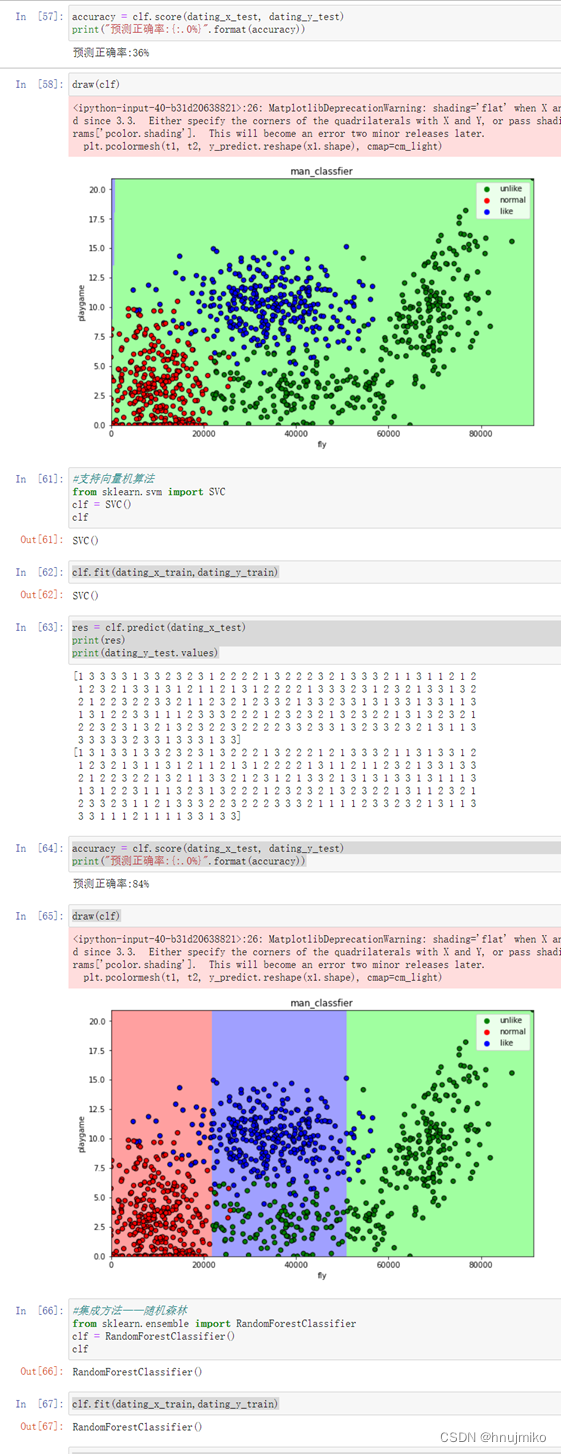
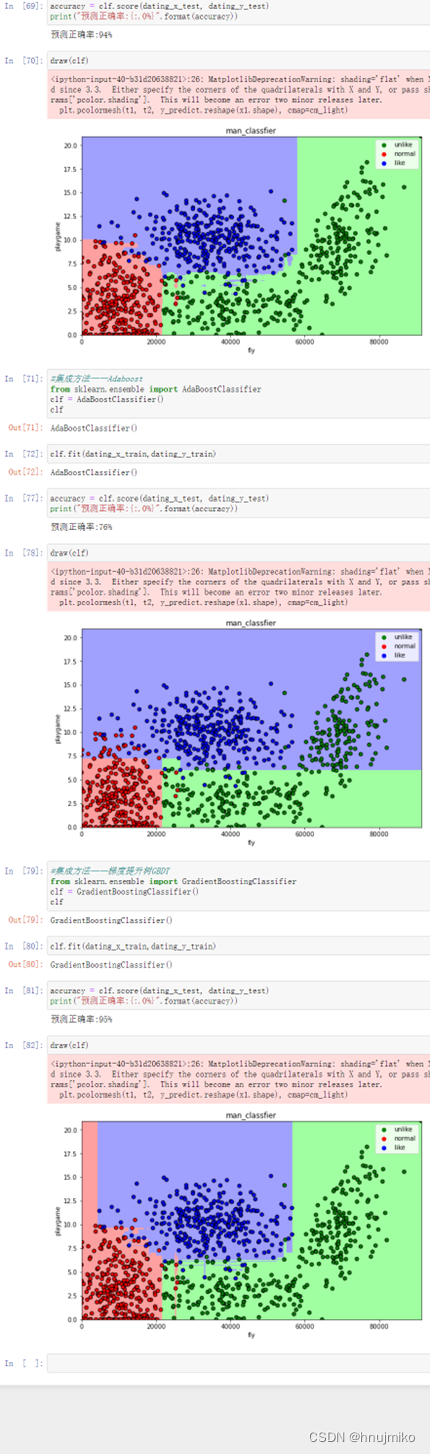

对于这组数据来说,通过比较预测正确率可以看出朴素贝叶斯思想正确率最高,表现较好,在舍弃每年吃冰淇淋的公升数这个不重要特征时,可以发现模型性能的提高,所以前期对于数据的处理还是很重要的。
人工智能导论作业
课堂练习9.22
1.已知x={1,2,3},那么可以计算3* x 的值吗?如果可以,值是什么?如果不可以,请解释原因。
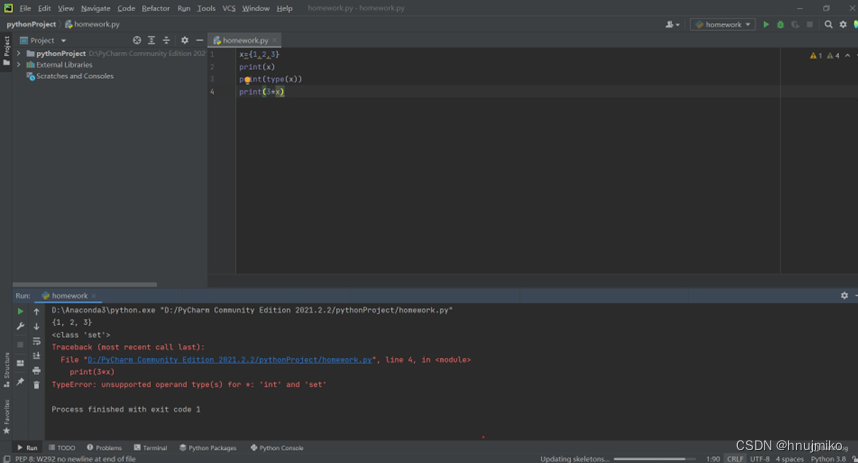
不可以,x是set类型,而3是int类型。另外查阅资料,*操作符在实现上是复制了值的引用,而不是创建了新的对象。比如int值[1]*4,最后结果为[4,4,4,4]。
2.已知x= zip (‘ abc ',1234'),那么连续两次执行 list ( x )会得到同样的结果吗?如果能,结果是什么?如果不能,请解释原因。
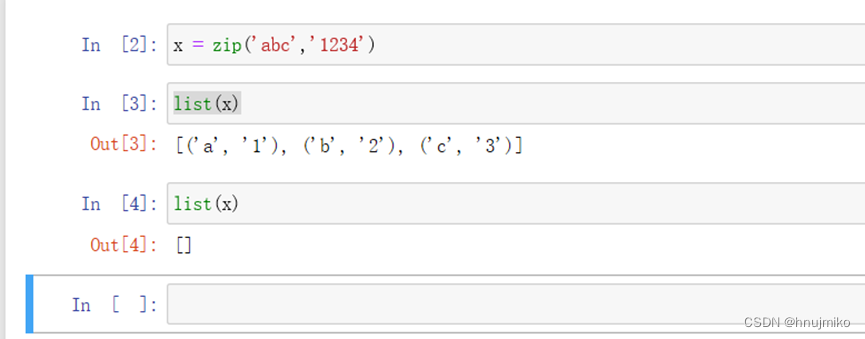
连续两次执行list(x)得到的结果是不同的。 第一次得到的是:[('a','1'),('b','2'),('c','3')]。第二次得到的是:[]。因为zip函数会返回一个zip对象(实际上就是一个生成器),list函数要用完这个生成器才能创建一个列表,而生成器只能用一次。
3.编写程序,让用户在键盘上输入一个自然数 n ,然后在区间[1,5n]上随机生成 n 个不重复的自然数,输出这些自然数,然后继续编写代码对这些自然数进行处理,只保留所有偶数,并输出这些偶数。

实验9.23
1.编写程序,生成包含20个随机数的列表,然后将前10个元素升序排列,后10个元素降序排列,并输出结果。

2.编写程序,让用户在键盘上输入一个包含若干整数的列表,输出翻转后的列表。

3.编写函数,接收一个字符串,判断该字符串是否为回文。所谓回文是指,从前向后读和从后向前读。

4.自行创建一个100个元素的列表,输入数据,实现列表的append, extend, insert, remove, pop, index, count, reverse, sort等常用的方法,并使用切片实现获取列表的部分元素,为列表增加元素,替换和修改列表中的元素,删除列表中不连续的元素。
Append:加数字进入列表末尾
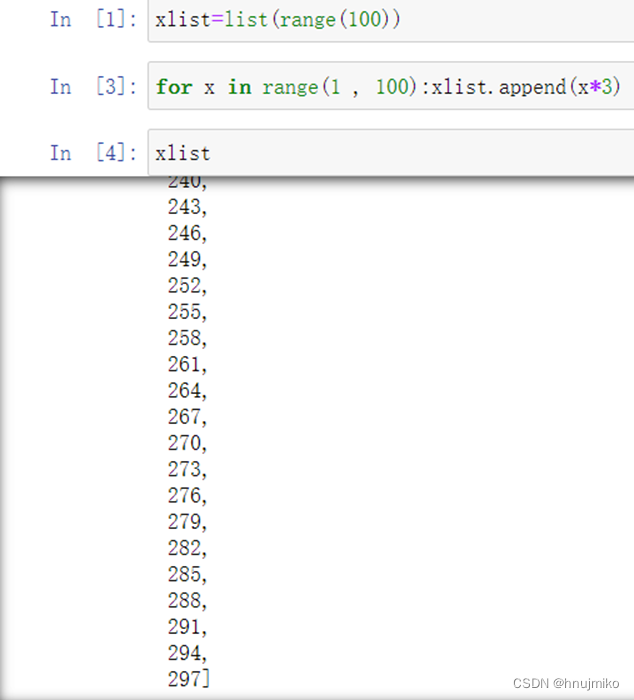
Extend:加入新的列表
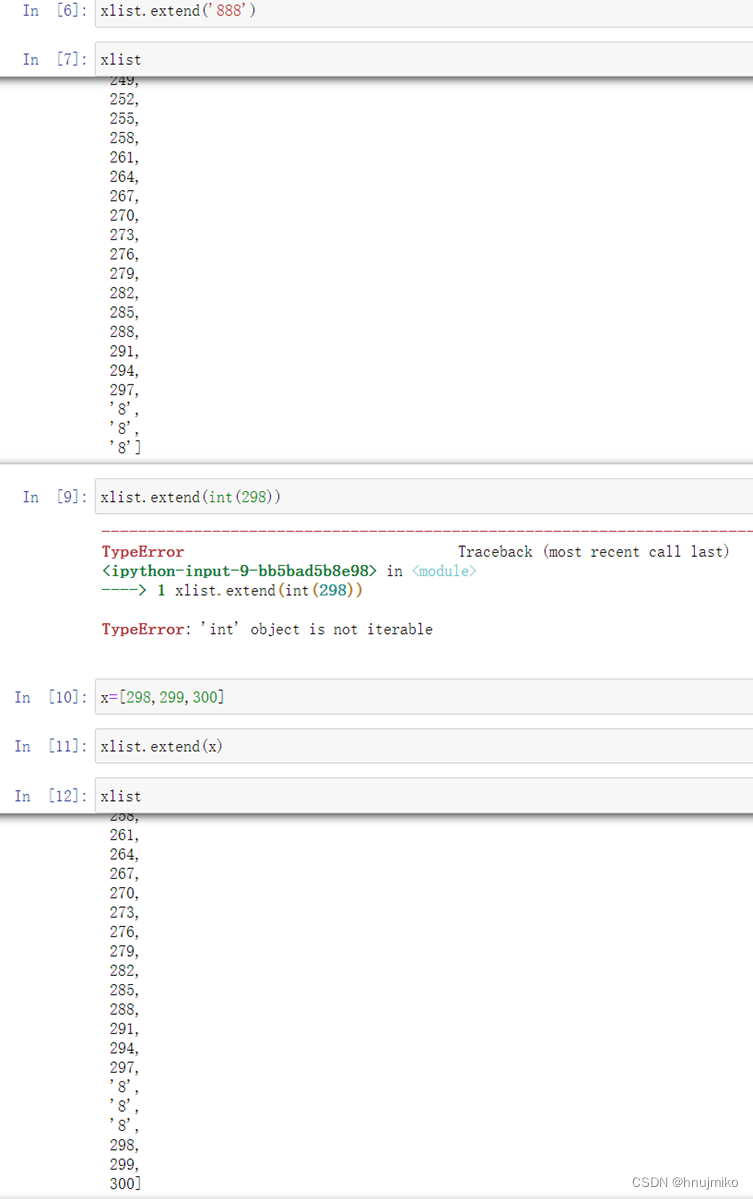
insert(n , 数据):在列表索引值为n的数据后面插入数据
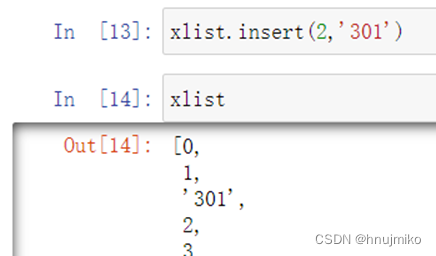
remove(数据项) : 删除指定数据项,若有多个相同的数据,则只删除最前面的那个数据项
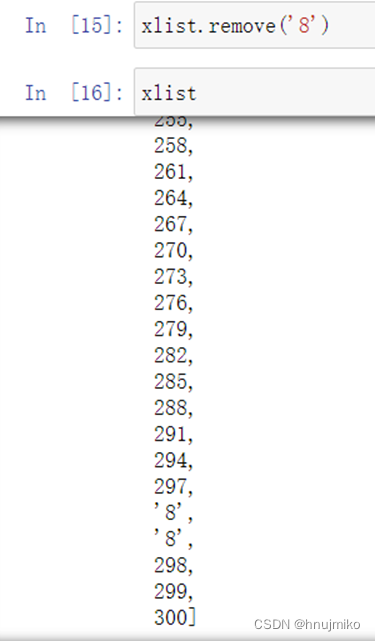
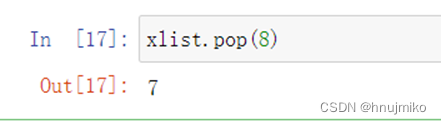
pop(index) :根据索引值移除
index(数据项):返回该数据项的索引值,若找不到报错
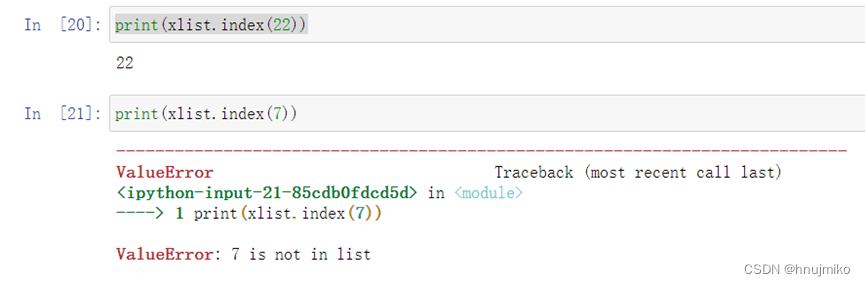
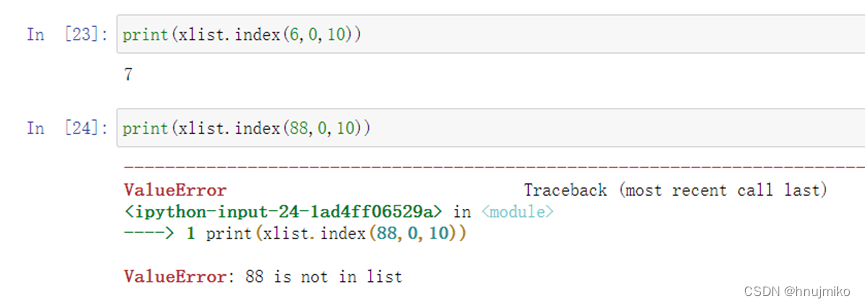
index(数据项, start , end) :在索引值从start到end-1之间查找数据项,返回索引值,若找不到报错
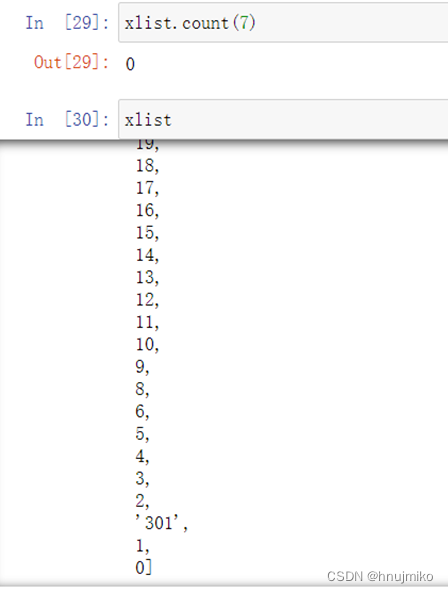
count:某数值在列表中出现的数字
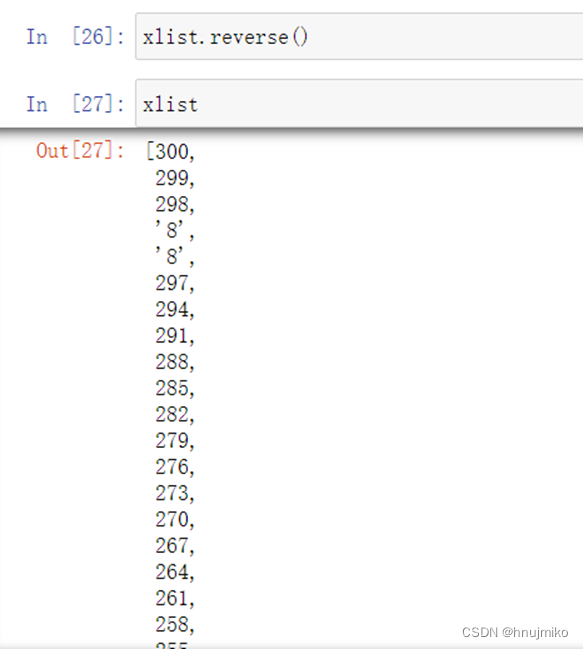
reverse:
Sort:将数组从小到大排序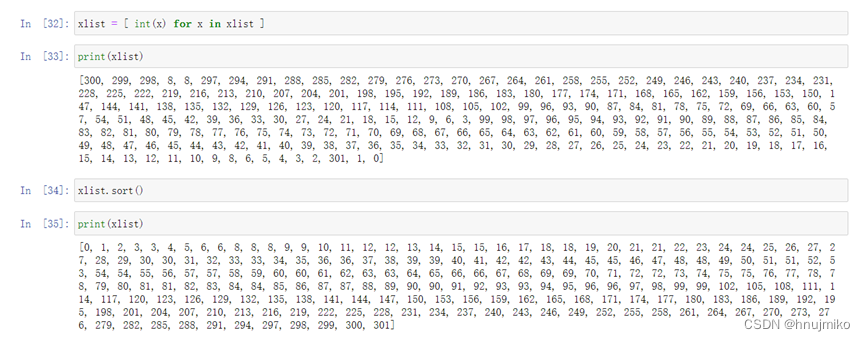
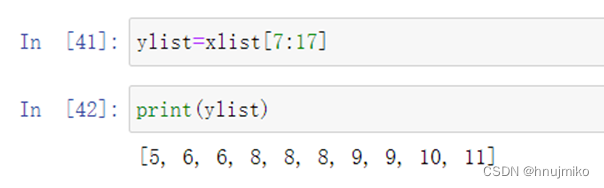
使用切片实现获取列表的部分元素:

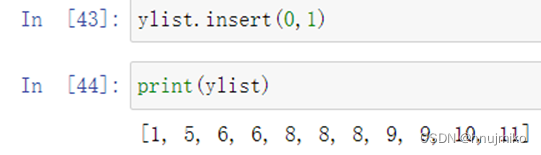
为列表增加元素
替换和修改列表中的元素:将前三个替换成1,1,9,每隔5个间隔修改一个数字为7,根据列表长度乘3

删除列表中不连续的元素:每隔3个删除一个
数据分析及可视化实践10.21
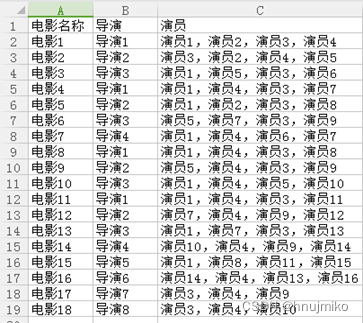
实践一: 假设有个Excel 2007文件“电影导演演员.xlsx”(文件自行生成),其中有三列分别为电影名称、导演和演员列表(同一个电影可能会有多个演员,每个演员姓名之间使用逗号分隔,如图1所示),要求统计每个演员的参演电影数量,并统计最受欢迎的前3个演员。

请在以上代码的基础上进一步改写,检查哪两个演员的关系最好,也就是共同参演的电影数量最多,并进行测试。
#10.21实验 1
import pandas as pd
df = pd.read_excel('电影导演演员.xlsx')#从Excel文件中读取数据dfe
df
pairs = []
vectors = dict()
for i in range(len(df)) : #遍历每一行数据
filmName , actors = df.at[i , '电影名称'] , df.at[i,'演员'].split(',')#获取当前行的演员清单
for actor in actors:#遍历每个演员
vectors[actor] = vectors.get(actor, set())
vectors[actor].add(filmName)
vectors = sorted(vectors.items(), key=lambda x:int(x[0][2:]))
def getActorPair(actors):
result = []
for index, actor1 in enumerate(actors[:-1]):
for fk, actor2 in enumerate(actors[index+1:]):
actorPair = (actor1[0], actor2[0])
films = actor1[1] & actor2[1]
result.append((actorPair, films))
return result
actorPairs = getActorPair(vectors)
closestPair = max(actorPairs, key=lambda item:len(item[1]))
print(closestPair)

实践二:运行下面的程序,在当前文件夹中生成饭店营业额模拟数据文件data.csv。

然后完成下面的任务:
1)使用pandas读取文件data.csv中的数据,创建DataFrame对象,并删除其中所有缺失值;
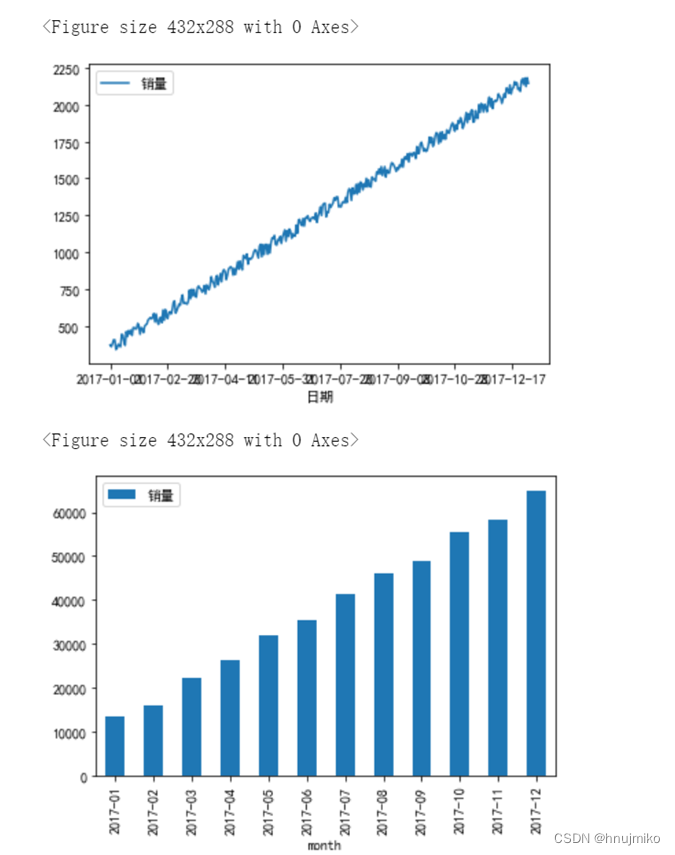
2)使用matplotlib生成折线图,反应该饭店每天的营业额情况,并把图形保存为本地文件first.jpg;
3)按月份进行统计,使用matplotlib绘制柱状图显示每个月份的营业额,并把图形保存为本地文件second.jpg;
4)按月份进行统计,找出相邻两个月最大涨幅,并把涨幅最大的月份写 maxMonth.txt;
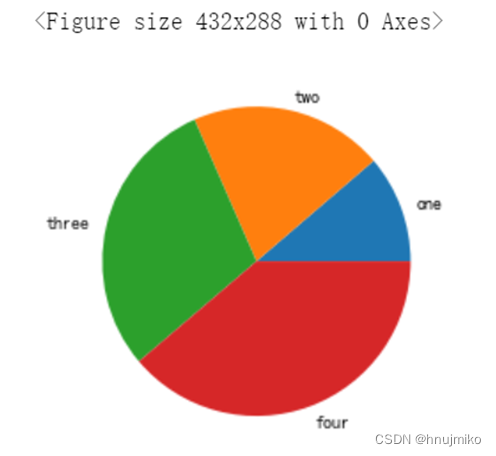
5)按季度统计该饭店2017年的营业额数据,使用matplotlib生成饼状图显示2017年4个季度的营业额分布情况,并把图形保存为本地文件third.jpg。
6)改进以上程序,使得生成的second.jpg中每个柱的上部显示该柱对应的数据值;生成的third.jpg中每个扇形能够显示其对应的比例。
7)继续修改代码,对生成的折线图、柱状图、饼状图进行美化
#使用pandas读取数据文件,创建DataFrame对象,并删除其中所有缺失值;
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif']=['SimHei'] #pyplot中文显示
df=pd.read_csv('data.csv',encoding='cp936')
df=df.dropna() #读取数据,丢弃缺失值
#使用matplotlib生成每天营业额折线图,保存图形为first.jpg
plt.figure()
df.plot(x='日期')
plt.savefig(r'D:/artificial intelligence/first.jpg')
#使用matplotlib绘制每个月营业额柱状图,保存为second.jpg
plt.figure()
df1=df[:] #str1.rindex(str2)返回子串 str2 在串str1中最后出现位置,如果没有匹配的字符串会报异常
df1['month']=df1['日期'].map(lambda x:x[:x.rindex('-')])#提取出月份,新建了一个month列出来
df1=df1.groupby(by='month',as_index=False).sum() #as_inside=False不把month作为新的index
df1.plot(x='month',kind='bar')
plt.savefig('D:/artificial intelligence/second.jpg')
#找出相邻两个月最大涨幅,并写入maxMonth.txt
plt.figure()
df2=df1.drop('month',axis=1).diff()#在销量列中每月跟上月相减的差集
m=df2['销量'].nlargest(1).keys()[0]#查找销量列中差集最大的一个数所对应的索引
with open('D:/artificial intelligence/maxMonth.txt','w')as fp:
fp.write(df1.loc[m,'month'])#索引m对应的month
#使用matplotlib显示2018年4个季度的营业额分布饼状图,保存为third.jpg
plt.figure()
one=df1[:3]['销量'].sum()
two=df1[3:6]['销量'].sum()
three=df1[6:9]['销量'].sum()
four=df1[9:12]['销量'].sum()
plt.pie([one,two,three,four],labels=['one','two','three','four'])
plt.savefig('D:/artificial intelligence/third.fig')
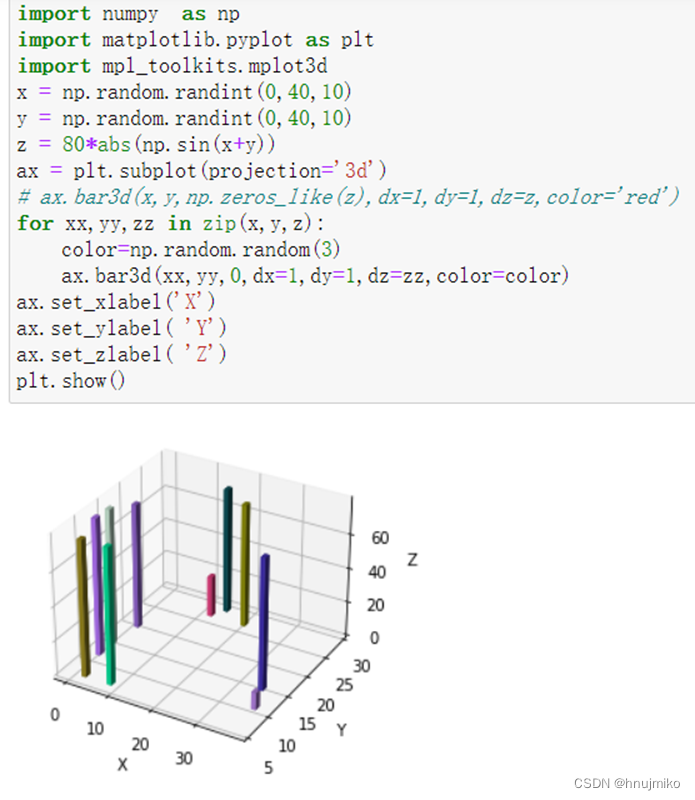
实践三:绘制三维柱状图

修改以上代码,使得每个柱的颜色不同
import numpy as np
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d
x = np.random.randint(0,40,10)
y = np.random.randint(0,40,10)
z = 80*abs(np.sin(x+y))
ax = plt.subplot(projection='3d')
# ax.bar3d(x, y,np.zeros_like(z),dx=1,dy=1,dz=z,color='red')
for xx,yy,zz in zip(x,y,z):
color=np.random.random(3)
ax.bar3d(xx,
yy,
0,
dx=1,
dy=1,
dz=zz,
color=color)
ax.set_xlabel('X')
ax.set_ylabel( 'Y')
ax.set_zlabel( 'Z')
plt.show()
















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









