






模型选择
-
任务类型出发
-
回归任务
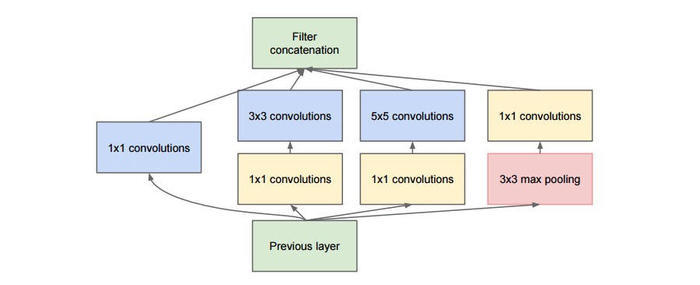
- Inception模块
GoogLeNet是由Inception模块进行组成的,GoogLeNet采用了模块化的结构,因此修改网络结构时非常简单方便。
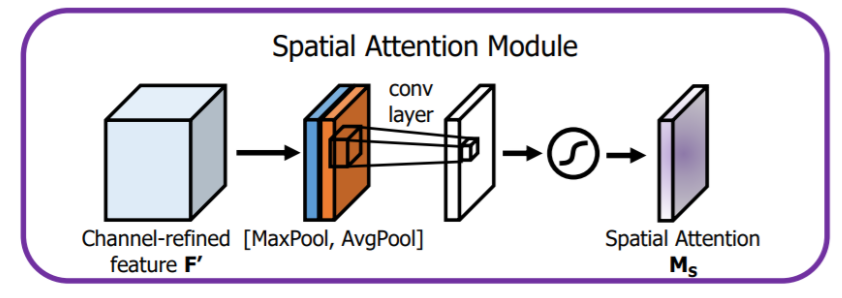
- 空间注意力模块
空间注意力聚焦在“哪里”是最具信息量的部分。计算空间注意力的方法是沿着通道轴应用平均池化和最大池操作,然后将它们连接起来生成一个有效的特征描述符。
-
分类任务
图像分类
基于CIFAR-10数据集实现图像10分类。项目完整代码详见:从论文到代码深入解析带有门控单元的gMLP算法
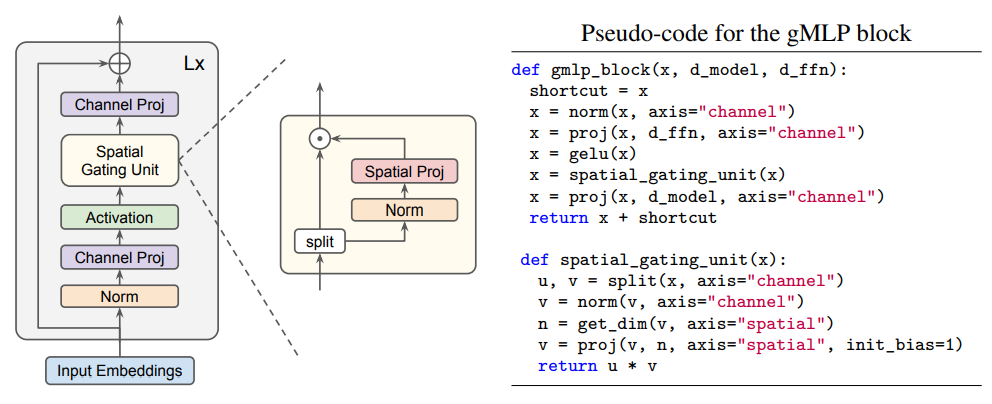
gMLP中,最核心的部分就是空间选通单元(Spatial Gating Unit,SGU),它的结构如下图所示:
-
场景任务
这里说的场景任务是针对某一个特定的场景开发的深度学习任务,相比于回归和分类任务来说,场景任务的难度更高。这里说的场景任务包括但不限于目标检测、图像分割、文本生成、语音合成、强化学习等。(利用paddle模型库)
- 模型训练
- 基于高层API训练模型
- 使用PaddleX训练模型
- 模型训练通用配置基本原则
- 每个输入数据的维度要保持一致,且一定要和模型输入保持一致
- 配置学习率衰减策略⑩,训练的上限轮数一定要计算正确
- BatchSize不宜过大,太大容易内存溢出,且一般为二次幂
超参优化
-
概念:模型的超参数指的是模型外部的配置变量,是不能通过训练的进行来估计其取值不同的,且不同的训练任务往往需要不同的超参数。
超参数不同,最终得到的模型也是不同的。
一般来说,超参数有:学习率,迭代次数,网络的层数,每层神经元的个数等等。
常见的超参数有以下三类:
- 网络结构,包括神经元之间的连接关系、层数、每层的神经元数量、激活函数的类型等 .
- 优化参数,包括优化方法、学习率、小批量的样本数量等 .
- 正则化系数
-
手动调参四大方法
-
使用提前停止来确定训练的迭代次数(防止过拟合)
做一个判断,满足条件,终止循环
for epoch in range(MAX_EPOCH): // 训练代码 print('{}[TRAIN]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy())) if (): break model.train()if 条件:
- 分类准确率不再提升
- loss降到一个想要的范围
-
让学习率从高逐渐降低
-
宽泛策略
在使用神经网络来解决新的问题时,⼀个挑战就是获得任何⼀种非寻常的学习,也就是说,达到比随机的情况更好的结果。
也许下面的方法能给你带来某些不一样的启发:
- 通过简化网络来加速实验进行更有意义的学习
- 通过更加频繁的监控验证准确率来获得反馈
通过简化网络来加速实验进行更有意义的学习
假设,我们第⼀次遇到 MNIST 分类问题。刚开始,你很有激情,但是当模型完全失效时,你会就得有些沮丧。
此时就可以将问题简化,将十分类问题转化成二分类问题。丢开训练和验证集中的那些除了 0 和 1的那些图像,即我们只识别0和1。然后试着训练⼀个网络来区分 0 和 1。
这样一来,不仅仅问题比 10 个分类的情况简化了,同样也会减少 80% 的训练数据,这样就多出了 5 倍的加速。同时也可以保证更快的实验,也能给予你关于如何构建好的网络更快的洞察。
通过更加频繁的监控验证准确率来获得反馈
这个方法调的其实是输出:
if i % 200 == 0: timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time())) print('{}[VALID]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy()))对模型本身并没有任何关系,但是,你能得到更多并且更快地得到反馈,从而快速地实验其他的超参数,或者甚至近同步地进行不同参数的组合的评比。
这一点看似不重要,但对于超参数的调整来说,是很重要的一步
因为在实际的应用中,很容易会遇到神经网络学习不到任何知识的情况。你可能要花费若干天在调整参数上,仍然没有进展。所以在前期的时候,就应该从实验中尽可能早的获得快速反馈。直觉上看,这看起来简化问题和架构仅仅会降低你的效率。而实际上,这样能够将进度加快,因为你能够更快地找到传达出有意义的信号的网络。⼀旦你获得这些信号,你可以尝试通过微调超参数获得快速的性能提升。
-
小批量数据(mini-batchsize)大小不必最优
- 小批量数据太小会加长训练时间;而小批量数据太大是不能够足够频繁地更新权重的。
- 选择一个折中值
-
效果展示
-
直接可视化输入与输出
-
巧用VisualDL
-
权重可视化
- 注意力机制
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









