







饼图
matplotlib
首先需要导入该模块的子模块pyplot,然后调用模块中的pie函数
pie(x, explode=None, labels=None, colors=None,
autopct=None, pctdistance=0.6, shadow=False,
labeldistance=1.1, startangle=None,
radius=None, counterclock=True, wedgeprops=None,
textprops=None, center=(0, 0), frame=False)
x:指定绘图的数据。
explode:指定饼图某些部分的突出显示,即呈现爆炸式。
labels:为饼图添加标签说明,类似于图例说明。
colors:指定饼图的填充色。
autopct:自动添加百分比显示,可以采用格式化的方法显示。
pctdistance:设置百分比标签与圆心的距离。
shadow:是否添加饼图的阴影效果。
labeldistance:设置各扇形标签(图例)与圆心的距离。
startangle:设置饼图的初始摆放角度。
radius:设置饼图的半径大小。
counterclock:是否让饼图按逆时针顺序呈现。
wedgeprops:设置饼图内外边界的属性,如边界线的粗细、颜色等。
textprops:设置饼图中文本的属性,如字体大小、颜色等。
center:指定饼图的中心点位置,默认为原点。
frame:是否要显示饼图背后的图框,如果设置为True的话,需要同时控制图框x轴、y轴
的范围和饼图的中心位置。
# 饼图的绘制
# 导入第三方模块
import matplotlib.pyplot as plt
%matplotlib
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 构造数据
edu = [0.2515,0.3724,0.3336,0.0368,0.0057]
labels = ['中专','大专','本科','硕士','其他']
# 绘制饼图
plt.pie(x = edu, # 绘图数据
labels=labels, # 添加教育水平标签
autopct='%.1f%%' # 设置百分比的格式,这里保留一位小数
)
# 添加图标题
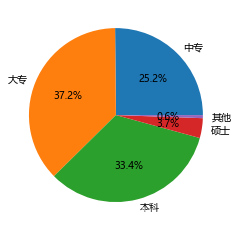
plt.title('失信用户的教育水平分布')
# 显示图形
plt.show()
# 添加修饰的饼图
explode = [0,0.1,0,0,0] # 生成数据,用于突出显示大专学历人群
colors=['#9999ff','#ff9999','#7777aa','#2442aa','#dd5555'] # 自定义颜色
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆
plt.axes(aspect='equal')
# 绘制饼图
plt.pie(x = edu, # 绘图数据
explode=explode, # 突出显示大专人群
labels=labels, # 添加教育水平标签
colors=colors, # 设置饼图的自定义填充色
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8, # 设置百分比标签与圆心的距离
labeldistance = 1.1, # 设置教育水平标签与圆心的距离
startangle = 180, # 设置饼图的初始角度
radius = 1.2, # 设置饼图的半径
counterclock = False, # 是否逆时针,这里设置为顺时针方向
wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'},# 设置饼图内外边界的属性值
textprops = {'fontsize':10, 'color':'black'}, # 设置文本标签的属性值
)
# 添加图标题
plt.title('失信用户的受教育水平分布')
# 显示图形
plt.show()
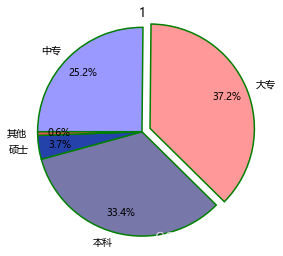
如上呈现的饼图,直观上要比之前的饼图好看很多,这些都是基于pie函数的灵活参数所实现的。饼图中突出显示大专学历的人群,是因为在这300万失信人群中,大专学历的人数比例最高,该功能就是通过explode参数完成的。另外,还需要对如上饼图的绘制说明几点:如果绘制的图形中涉及中文及数字中的负号,都需要通过rcParams进行控制。由于不加修饰的饼图更像是一个椭圆,所以需要pyplot模块中的axes函数椭圆强制为正圆。自定义颜色的设置,既可以使用十六进制的颜色,也可以使用具体的颜色名称,如red,black等。如果需要添加图形的标题,需要调用pyplot模块中的title函数。
代码plt.show()用来呈现最终的图形,无论是使用Jupyter或Pycharm编辑器,都需要使用这行代码呈现图形。
pandas
Series.plot(kind='line', ax=None, figsize=None, use_index=True, title=None,
grid=None, legend=False, style=None, logx=False, logy=False,
loglog=False, xticks=None, yticks=None, xlim=None, ylim=None,
rot=None, fontsize=None, colormap=None, table=False, yerr=None,
xerr=None, label=None, secondary_y=False, **kwds)
kind:指定一个字符串值,用于绘制图形的类型,默认为折线图line。还可以绘制垂直条
形图bar、水平条形图hbar、直方图hist、箱线图box、核密度图kde、面积图area和饼图pie。
ax:控制当前子图在组图中的位置。例如,在一个2×2的图形矩阵中,通过该参数控制当
前图形在矩阵中的位置。
figsize:控制图形的宽度和高度,以元组形式传递,即(width,hright)。
use_index:bool类型的参数,是否将序列的行索引用作x轴的刻度,默认为True。
title:用以添加图形的标题。
grid:bool类型的参数,是否给图形添加网格线,默认为False。
legend:bool类型的参数,是否添加子图的图例,默认为False。
style:如果kind为line,该参数可以控制折线图的线条类型。
logx:bool类型的参数,是否对x轴做对数变换,默认为False。
logy:bool类型的参数,是否对y轴做对数变换,默认为False。
loglog:bool类型的参数,是否同时对x轴和y轴做对数变换,默认为False。
xticks:用于设置x轴的刻度值。
yticks:用于设置y轴的刻度值。
xlim:以元组或列表的形式,设置x轴的取值范围,如(0,3)表示x轴落在0~3的范围之内。
ylim:以元组或列表的形式,设置y轴的取值范围。
rot:接受一个整数值,用于旋转刻度值的角度。
fontsize:接受一个整数,用于控制x轴与y轴刻度值的字体大小。
colormap:接受一个表示颜色含义的字符串,或者Python的色彩映射对象,该参数用于
设置图形的区域颜色。
table:该参数如果为True,表示在绘制图形的基础上再添加数据表;如果传递的是序列
或数据框,则根据数据添加数据表。
yerr:如果kind为bar或hbar,该参数表示在条形图的基础上添加误差棒。
xerr:含义同yerr参数。
label:用于添加图形的标签。
secondary_y:bool类型的参数,是否添加第二个y轴,默认为False。
**kwds:关键字参数,该参数可以根据不同的kind值,为图形添加更多的修饰性参数(依
赖于pyplot中的绘图函数)。
# 导入第三方模块
import pandas as pd
# 构建序列
data1 = pd.Series({'中专':0.2515,'大专':0.3724,'本科':0.3336,'硕士':0.0368,'其他':0.0057})
# 将序列的名称设置为空字符,否则绘制的饼图左边会出现None这样的字眼
data1.name = ''
# 控制饼图为正圆
plt.axes(aspect = 'equal')
# plot方法对序列进行绘图
data1.plot(kind = 'pie', # 选择图形类型
autopct='%.1f%%', # 饼图中添加数值标签
radius = 1, # 设置饼图的半径
startangle = 180, # 设置饼图的初始角度
counterclock = False, # 将饼图的顺序设置为顺时针方向
title = '失信用户的受教育水平分布', # 为饼图添加标题
wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'}, # 设置饼图内外边界的属性值
textprops = {'fontsize':10, 'color':'black'} # 设置文本标签的属性值
)
# 显示图形
plt.show()
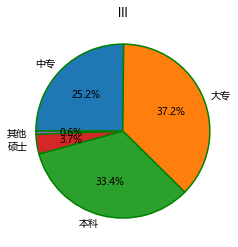
应用pandas模块中的plot方法,也可以得到一个比较好看的饼图。该方法中
除了kind参数和title参数属于plot方法,其他参数都是pyplot模块中pie函数的参数,并且以关键字参数的形式调用。
条形图
matplot;ib
bar(left, height, width=0.8, bottom=None, color=None, edgecolor=None,
linewidth=None, tick_label=None, xerr=None, yerr=None,
label = None, ecolor=None, align, log=False, **kwargs)
left:传递数值序列,指定条形图中x轴上的刻度值。
height:传递数值序列,指定条形图y轴上的高度。
width:指定条形图的宽度,默认为0.8。
bottom:用于绘制堆叠条形图。
color:指定条形图的填充色。
edgecolor:指定条形图的边框色。
linewidth:指定条形图边框的宽度,如果指定为0,表示不绘制边框。
tick_label:指定条形图的刻度标签。
xerr:如果参数不为None,表示在条形图的基础上添加误差棒。
yerr:参数含义同xerr。
label:指定条形图的标签,一般用以添加图例。
ecolor:指定条形图误差棒的颜色。
align:指定x轴刻度标签的对齐方式,默认为center,表示刻度标签居中对齐,如果设置
为edge,则表示在每个条形的左下角呈现刻度标签。
log:bool类型参数,是否对坐标轴进行log变换,默认为False。
**kwargs:关键字参数,用于对条形图进行其他设置,如透明度等。
垂直或水平条形图
# 条形图的绘制--垂直条形图
# 读入数据
GDP = pd.read_excel(r'Province GDP 2017.xlsx')
# 设置绘图风格(不妨使用R语言中的ggplot2风格)
plt.style.use('ggplot')
# 绘制条形图
plt.bar(x = range(GDP.shape[0]), # 指定条形图x轴的刻度值
height = GDP.GDP, # 指定条形图y轴的数值
tick_label = GDP.Province, # 指定条形图x轴的刻度标签
color = 'steelblue', # 指定条形图的填充色
)
# 添加y轴的标签
plt.ylabel('GDP(万亿)')
# 添加条形图的标题
plt.title('2017年度6个省份GDP分布')
# 为每个条形图添加数值标签
for x,y in enumerate(GDP.GDP):
plt.text(x,y+0.1,'%s' %round(y,1),ha='center')
# 显示图形
plt.show()
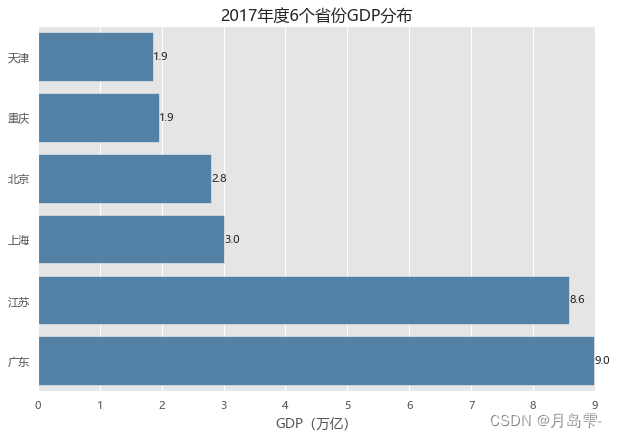
Province GDP
0 北京 2.80
1 上海 3.01
2 广东 8.99
3 江苏 8.59
4 重庆 1.95
5 天津 1.86
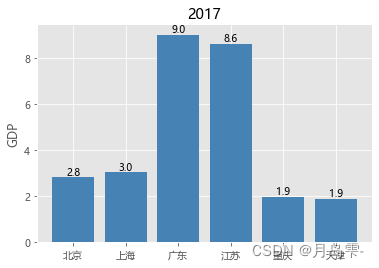
条形图中灰色网格的背景是通过代码plt.style.use(‘ggplot’)实现的,如果不添加该行代码,则条形图为白底背景。如果添加图形的x轴或y轴标签,需要调用pyplot子模块中的xlab和ylab函数。由于bar函数没有添加数值标签的参数,因此使用for循环对每一个柱体添加数值标签,使用的核心函数是pyplot子模块中的text。该函数的参数很简单,前两个参数用于定位字符在图形中的位置,第三个参数表示呈现的具体字符值,第四个参数为ha,表示字符的水平对齐方式为居中对齐。
# 条形图的绘制--水平条形图
# 对读入的数据作升序排序
GDP.sort_values(by = 'GDP', inplace = True)
# 绘制条形图
plt.barh(y = range(GDP.shape[0]), # 指定条形图y轴的刻度值
width = GDP.GDP, # 指定条形图x轴的数值
tick_label = GDP.Province, # 指定条形图y轴的刻度标签
color = 'steelblue', # 指定条形图的填充色
)
# 添加x轴的标签
plt.xlabel('GDP(万亿)')
# 添加条形图的标题
plt.title('2017年度6个省份GDP分布')
# 为每个条形图添加数值标签
for y,x in enumerate(GDP.GDP):
plt.text(x+0.1,y,'%s' %round(x,1),va='center')
# 显示图形
plt.show()
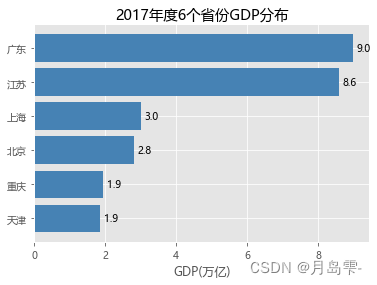
水平条形图的y轴刻度值是从下往上布置的,所以条形图从下往上是满足升序的。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数讲解:
by:要排序的名称或名称列表。(如果轴为 0 或“索引”,则 by 可能包含索引级别或列标签。如果轴为 1 或“列”,则 by 可能包含列级别或索引标签。
axis:要排序的轴。若axis=0或'index',则按照指定列中数据大小排序;若axis=1或'columns',则按照指定索引中数据大小排序,默认axis=0
ascending:bool或bool的列表,默认为True,即为升序排列。 为多个排序顺序指定列表。如果这是一个布尔值列表,则必须匹配by的长度。
inplace:是否用排序后的数据集替换原来的数据,默认为False,即不替换。
kind: 排序算法的选择。对于DataFrames,此选项仅在对单个列或标签排序时应用。
na_position:如果是第一个,则将NaNs放在开头;如果是最后一个,把NaNs放在最后。
ignore_index:如果为True,则结果轴将被标记为0,1,,n - 1。
key:在排序之前对值应用键函数。这类似于内置sorted()函数中的key参数,显著的区别是这个key函数应该是向量化的。它应该期望一个Series,并返回一个与输入具有相同形状的Series。它将被独立地应用到每一列。
堆叠
# 条形图的绘制--堆叠条形图
# 读入数据
Industry_GDP = pd.read_excel(r'Industry_GDP.xlsx')
# 取出四个不同的季度标签,用作堆叠条形图x轴的刻度标签
Quarters = Industry_GDP.Quarter.unique()
# 取出第一产业的四季度值
Industry1 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第一产业']
# 重新设置行索引
Industry1.index = range(len(Quarters))
# 取出第二产业的四季度值
Industry2 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第二产业']
# 重新设置行索引
Industry2.index = range(len(Quarters))
# 取出第三产业的四季度值
Industry3 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第三产业']
# 绘制堆叠条形图
# 各季度下第一产业的条形图
plt.bar(x = range(len(Quarters)), height=Industry1, color = 'steelblue', label = '第一产业', tick_label = Quarters)
# 各季度下第二产业的条形图
plt.bar(x = range(len(Quarters)), height=Industry2, bottom = Industry1, color = 'green', label = '第二产业')
# 各季度下第三产业的条形图
plt.bar(x = range(len(Quarters)), height=Industry3, bottom = Industry1 + Industry2, color = 'red', label = '第三产业')
# 添加y轴标签
plt.ylabel('生成总值(亿)')
# 添加图形标题
plt.title('2017年各季度三产业总值')
# 显示各产业的图例
plt.legend()
# 显示图形
plt.show()
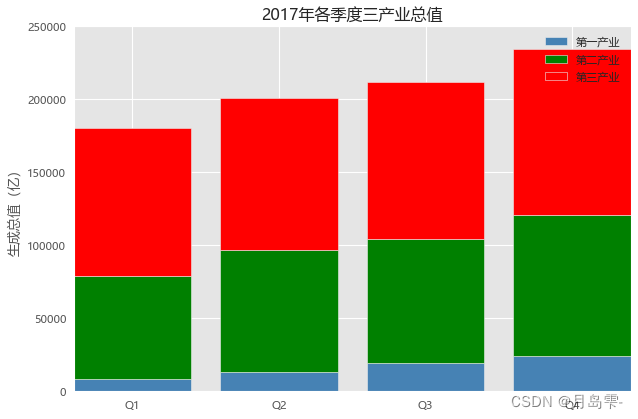
分别针对三种产业的产值绘制三次条形图。需要注意的是,第二产业的条形图是在第一产业的基础上做了叠加,故需要将bottom参数设置为Industry1;而第三产业的条形图又是叠加在第一和第二产业之上,所以需要将bottom参数设置为Industry1+ Industry2。
读者可能疑惑,通过条件判断将三种产业的值(Industry1、Industry2、Industry3)分别取出来后,为什么还要重新设置行索引?那是因为各季度下每一种产业值前的行索引都不相同,这就导致无法进行Industry1+ Industry2的和计算(读者不妨试试不改变序列Industry1和Industry2的行索引的后果)。
水平交错
# 条形图的绘制--水平交错条形图
# 导入第三方模块
import numpy as np
# 读入数据
HuRun = pd.read_excel(r'HuRun.xlsx')
# 取出城市名称
Cities = HuRun.City.unique()
# 取出2016年各城市亿万资产家庭数
Counts2016 = HuRun.Counts[HuRun.Year == 2016]
# 取出2017年各城市亿万资产家庭数
Counts2017 = HuRun.Counts[HuRun.Year == 2017]
# 绘制水平交错条形图
bar_width = 0.4
plt.bar(x = np.arange(len(Cities)), height = Counts2016, label = '2016', color = 'steelblue', width = bar_width)
plt.bar(x = np.arange(len(Cities))+bar_width, height = Counts2017, label = '2017', color = 'indianred', width = bar_width)
# 添加刻度标签(向右偏移0.225)
plt.xticks(np.arange(5)+0.2, Cities)
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
# 添加图形标题
plt.title('近两年5个城市亿万资产家庭数比较')
# 添加图例
plt.legend()
# 显示图形
plt.show()
Year Counts City
0 2016 15600 北京
1 2016 12700 上海
2 2016 11300 香港
3 2016 4270 深圳
4 2016 3620 广州
5 2017 17400 北京
6 2017 14800 上海
7 2017 12000 香港
8 2017 5200 深圳
9 2017 4020 广州
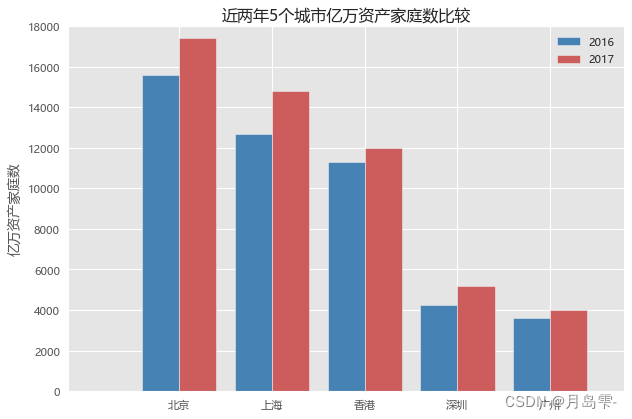
如上的水平交错条形图,其实质就是使用两次bar函数,所不同的是,第二次bar函数使得条形图往右偏了0.4个单位(left=np.arange(len(Cities))+bar_width),进而形成水平交错条形图的效果。每一个bar函数,都必须控制条形图的宽度(width=bar_width),否则会导致条形图的重叠。如果利用bar函数的tick_label参数添加条形图x轴上的刻度标签,会发现标签并不是居中对齐在两个条形图之间,为了克服这个问题,使用了pyplot子模块中的xticks函数,并且使刻度标签的位置向右移0.2个单位。
pandas
# Pandas模块之垂直或水平条形图
# 绘图(此时的数据集在前文已经按各省GDP做过升序处理)
GDP.GDP.plot(kind = 'bar', width = 0.8, rot = 0, color = 'steelblue', title = '2017年度6个省份GDP分布')
# 添加y轴标签
plt.ylabel('GDP(万亿)')
# 添加x轴刻度标签
plt.xticks(range(len(GDP.Province)), #指定刻度标签的位置
GDP.Province # 指出具体的刻度标签值
)
# 为每个条形图添加数值标签
for x,y in enumerate(GDP.GDP):
plt.text(x-0.1,y+0.2,'%s' %round(y,1),va='center')
# 显示图形
plt.show()
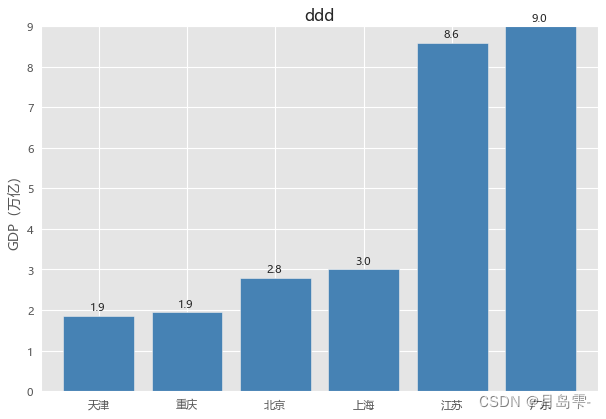
应用plot方法绘制水平交错条形图,必须更改原始数据集的形状,即将两
个离散型变量的水平值分别布置到行与列中(代码中采用透视表的方法实现)
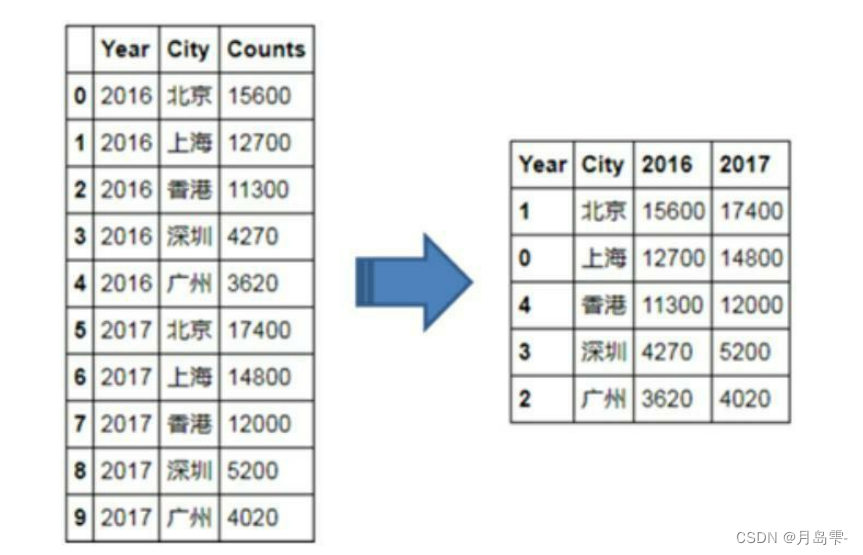
# Pandas模块之水平交错条形图
HuRun_reshape = HuRun.pivot_table(index = 'City', columns='Year', values='Counts').reset_index()
# 对数据集降序排序
HuRun_reshape.sort_values(by = 2016, ascending = False, inplace = True)
HuRun_reshape.plot(x = 'City', y = [2016,2017], kind = 'bar', color = ['steelblue', 'indianred'],
rot = 0, # 用于旋转x轴刻度标签的角度,0表示水平显示刻度标签
width = 0.8, title = '近两年5个城市亿万资产家庭数比较')
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
plt.xlabel('')
plt.show()
seaborn
# seaborn模块之垂直或水平条形图
# 导入第三方模块
import seaborn as sns
sns.barplot(y = 'Province', # 指定条形图x轴的数据
x = 'GDP', # 指定条形图y轴的数据
data = GDP, # 指定需要绘图的数据集
color = 'steelblue', # 指定条形图的填充色
orient = 'horizontal' # 将条形图水平显示
)
# 重新设置x轴和y轴的标签
plt.xlabel('GDP(万亿)')
plt.ylabel('')
# 添加图形的标题
plt.title('2017年度6个省份GDP分布')
# 为每个条形图添加数值标签
for y,x in enumerate(GDP.GDP):
plt.text(x,y,'%s' %round(x,1),va='center')
# 显示图形
plt.show()
sns.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
ci=95, n_boot=1000, orient=None, color=None, palette=None,
saturation=0.75, errcolor='.26', errwidth=None, dodge=True, ax=None, **kwargs)
x:指定条形图的x轴数据。
y:指定条形图的y轴数据。
hue:指定用于分组的另一个离散变量。
data:指定用于绘图的数据集。
order:传递一个字符串列表,用于分类变量的排序。
hur_order:传递一个字符串列表,用于分类变量hue值的排序。
ci:用于绘制条形图的误差棒(置信区间)。
n_boot:当指定ci参数时,可以通过n_boot参数控制自助抽样的迭代次数。
orient:指定水平或垂直条形图。
color:指定所有条形图所属的一种填充色。
palette:指定hue变量中各水平的颜色。
saturation:指定颜色的透明度。
errcolor:指定误差棒的颜色。
errwidth:指定误差棒的线宽。
capsize:指定误差棒两端线条的长度。
dodge:bool类型参数,当使用hue参数时,是否绘制水平交错条形图,默认为True。
ax:用于控制子图的位置。
**kwagrs:关键字参数,可以调用plt.bar函数中的其他参数。
# 读入数据
Titanic = pd.read_csv(r'titanic_train.csv')
# 绘制水平交错条形图
sns.barplot(x = 'Pclass', # 指定x轴数据
y = 'Age', # 指定y轴数据
hue = 'Sex', # 指定分组数据
data = Titanic, # 指定绘图数据集
palette = 'RdBu', # 指定男女性别的不同颜色
errcolor = 'blue', # 指定误差棒的颜色
errwidth=2, # 指定误差棒的线宽
saturation = 1, # 指定颜色的透明度,这里设置为无透明度
capsize = 0.05 # 指定误差棒两端线条的宽度
)
# 添加图形标题
plt.title('各船舱等级中男女乘客的年龄差异')
# 显示图形
plt.show()
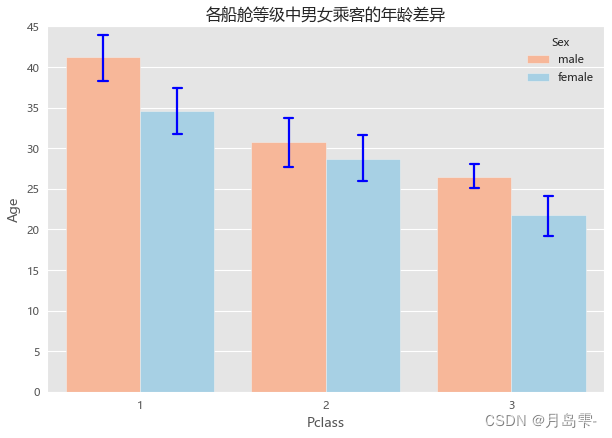
绘制的每一个条形图中都含有一条竖线,该竖线就是条形图的误差棒,即
各组别下年龄的标准差大小。从图6-13可知,三等舱的男性乘客年龄是最为接近的,因为标准差最小。
需要注意的是,数据集Titanic并非汇总好的数据,是不可以直接应用到matplotlib模块中的bar函数与pandas模块中的plot方法。如需使用,必须先对数据集进行分组聚合
直方图与核密度曲线
matplotlib
plt.hist(x, bins=10, range=None, normed=False,
weights=None, cumulative=False, bottom=None,
histtype='bar', align='mid', orientation='vertical',
rwidth=None, log=False, color=None,
label=None, stacked=False)
x:指定要绘制直方图的数据。
bins:指定直方图条形的个数。
range:指定直方图数据的上下界,默认包含绘图数据的最大值和最小值。
normed:是否将直方图的频数转换成频率。
weights:该参数可为每一个数据点设置权重。
cumulative:是否需要计算累计频数或频率。
bottom:可以为直方图的每个条形添加基准线,默认为0。
histtype:指定直方图的类型,默认为bar,除此之外,还有barstacked、step和stepfilled。
align:设置条形边界值的对齐方式,默认为mid,另外还有left和right。
orientation:设置直方图的摆放方向,默认为垂直方向。
rwidth:设置直方图条形的宽度。
log:是否需要对绘图数据进行log变换。
color:设置直方图的填充色。
edgecolor:设置直方图边框色。
label:设置直方图的标签,可通过legend展示其图例。
stacked:当有多个数据时,是否需要将直方图呈堆叠摆放,默认水平摆放。
# matplotlib模块绘制直方图
# 检查年龄是否有缺失
any(Titanic.Age.isnull())
# 不妨删除含有缺失年龄的观察
Titanic.dropna(subset=['Age'], inplace=True)
# 绘制直方图
plt.hist(x = Titanic.Age, # 指定绘图数据
bins = 20, # 指定直方图中条块的个数
color = 'steelblue', # 指定直方图的填充色
edgecolor = 'black', # 指定直方图的边框色
#cumulative=True
)
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('频数')
# 添加标题
plt.title('乘客年龄分布')
# 显示图形
plt.show()
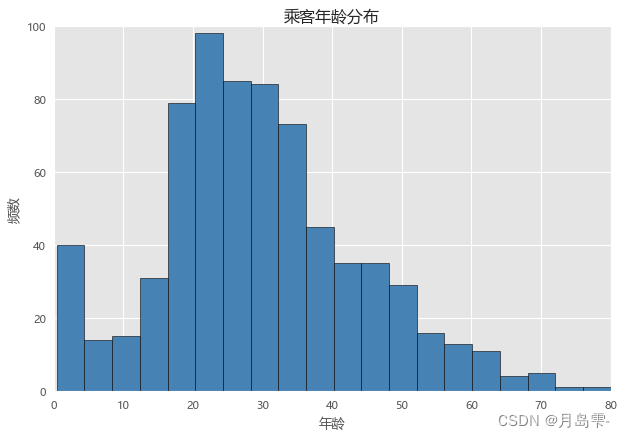
需要注意的是,如果原始数据集中存在缺失值,一定要对缺失观测进行删除或替换,否则无法绘制成功。如果在直方图的基础上再添加核密度图,通过matplotlib模块就比较吃力了,因为首先得计算出每一个年龄对应的核密值。为了简单起见,下面利用pandas模块中的plot方法将直方图和核密度图绘制到一起。
pandas
分别是利用plot方法绘制直方图和核密度图。需要注意的是,在直方图的基础上添加核密度图,必须将直方图的频数更改为频率,即normed参数设置为True。
# Pandas模块绘制直方图和核密度图
# 绘制直方图
#Titanic.Age.plot(kind = 'hist', bins = 20, color = 'steelblue', edgecolor = 'black', normed = True, label = '直方图')
# density,stacked=True
Titanic.Age.plot(kind = 'hist', bins = 20, color = 'steelblue', edgecolor = 'black', density = True,label = '直方图')
# 绘制核密度图
Titanic.Age.plot(kind = 'kde', color = 'red', label = '核密度图')
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('核密度值')
# 添加标题
plt.title('乘客年龄分布')
# 显示图例
plt.legend()
# 显示图形
plt.show()
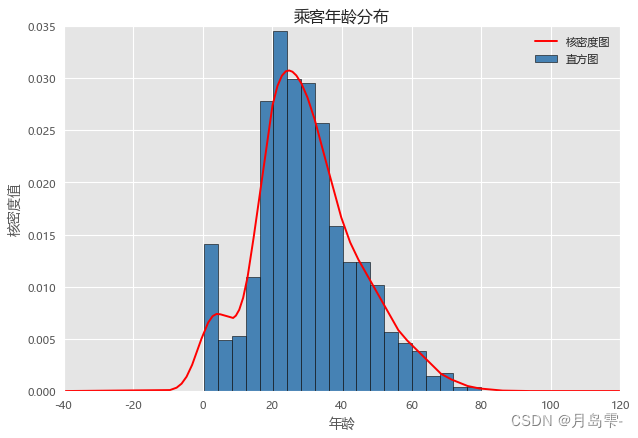
尽管这幅图满足了两种图形的合成,但其表达的是所有乘客的年龄分布,如果按性别分组,研究不同性别下年龄分布的差异,该如何实现?针对这个问题,使用matplotlib模块或pandas模块都会稍微复杂一些,推荐使用seaborn模块中的distplot函数
seaborn
sns.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,
hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,
color=None, vertical=False, norm_hist=False, axlabel=None,
label=None, ax=None)
a:指定绘图数据,可以是序列、一维数组或列表。
bins:指定直方图条形的个数。
hist:bool类型的参数,是否绘制直方图,默认为True。
kde:bool类型的参数,是否绘制核密度图,默认为True。
rug:bool类型的参数,是否绘制须图(如果数据比较密集,该参数比较有用),默认为
False。
fit:指定一个随机分布对象(需调用scipy模块中的随机分布函数),用于绘制随机分布的
概率密度曲线。
hist_kws:以字典形式传递直方图的其他修饰属性,如填充色、边框色、宽度等。
kde_kws:以字典形式传递核密度图的其他修饰属性,如线的颜色、线的类型等。
rug_kws:以字典形式传递须图的其他修饰属性,如线的颜色、线的宽度等。
fit_kws:以字典形式传递概率密度曲线的其他修饰属性,如线条颜色、形状、宽度等。
color:指定图形的颜色,除了随机分布曲线的颜色。
vertical:bool类型的参数,是否将图形垂直显示,默认为True。
norm_hist:bool类型的参数,是否将频数更改为频率,默认为False。
axlabel:用于显示轴标签。
label:指定图形的图例,需结合plt.legend()一起使用。
ax:指定子图的位置。
# seaborn模块绘制分组的直方图和核密度图
# 取出男性年龄
Age_Male = Titanic.Age[Titanic.Sex == 'male']
# 取出女性年龄
Age_Female = Titanic.Age[Titanic.Sex == 'female']
# 绘制男女乘客年龄的直方图
sns.distplot(Age_Male, bins = 20, kde = False, hist_kws = {'color':'steelblue'}, label = '男性')
# 绘制女性年龄的直方图
sns.distplot(Age_Female, bins = 20, kde = False, hist_kws = {'color':'purple'}, label = '女性')
plt.title('男女乘客的年龄直方图')
# 显示图例
plt.legend()
# 显示图形
plt.show()
# 绘制男女乘客年龄的核密度图
sns.distplot(Age_Male, hist = False, kde_kws = {'color':'red', 'linestyle':'-'},
norm_hist = True, label = '男性')
# 绘制女性年龄的核密度图
sns.distplot(Age_Female, hist = False, kde_kws = {'color':'black', 'linestyle':'--'},
norm_hist = True, label = '女性')
plt.title('男女乘客的年龄核密度图')
# 显示图例
plt.legend()
# 显示图形
plt.show()
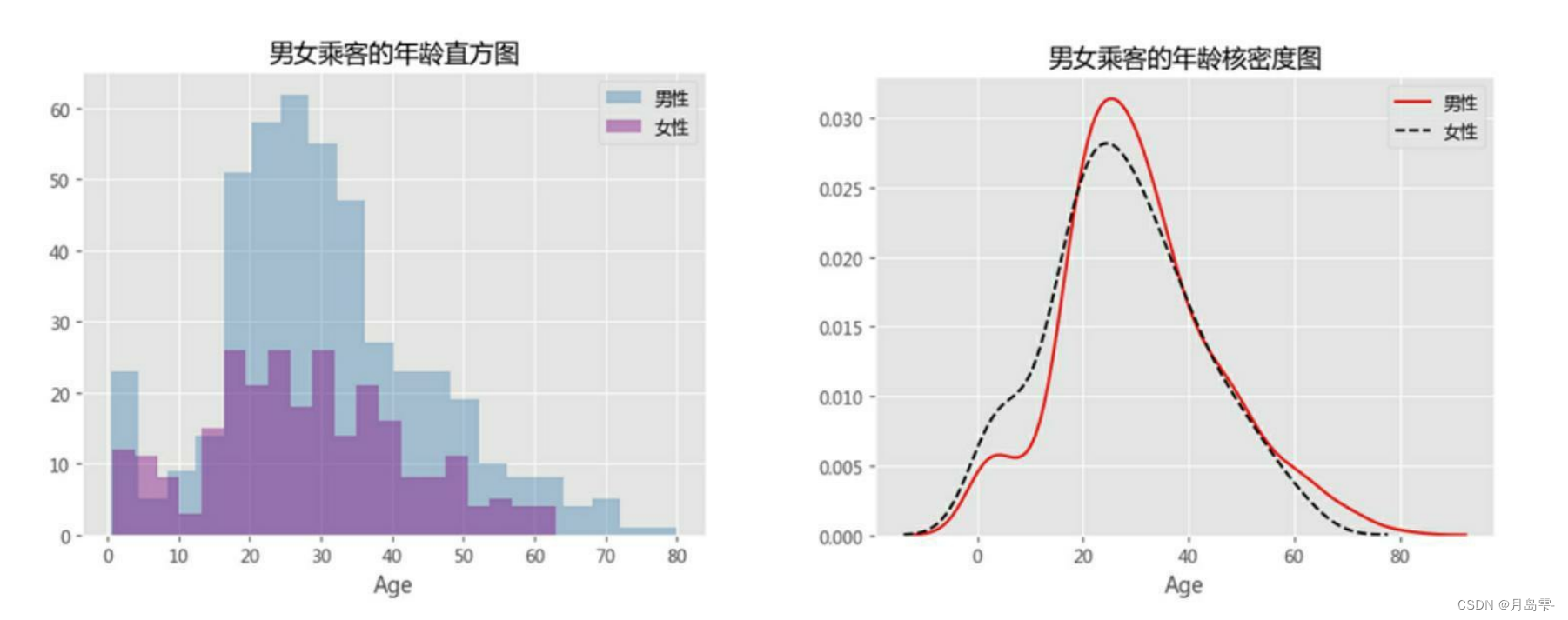
为了避免四个图形混在一起不易发现数据背后的特征,将直方图与核密度
图分开绘制。从直方图来看,女性年龄的分布明显比男性矮,说明在各年龄段下,男性乘客要比女性乘客多;再看核密度图,男女性别的年龄分布趋势比较接近,说明各年龄段下的男女乘客人数同步增加或减少。
箱线图
matplotlib
plt.boxplot(x, notch=None, sym=None, vert=None,
whis=None, positions=None, widths=None,
patch_artist=None, meanline=None, showmeans=None,
showcaps=None, showbox=None, showfliers=None,
boxprops=None, labels=None, flierprops=None,
medianprops=None, meanprops=None,
capprops=None, whiskerprops=None)
x:指定要绘制箱线图的数据。
notch:是否以凹口的形式展现箱线图,默认非凹口。
sym:指定异常点的形状,默认为+号显示。
vert:是否需要将箱线图垂直摆放,默认垂直摆放。
whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差。
positions:指定箱线图的位置,默认为[0,1,2…]。
widths:指定箱线图的宽度,默认为0.5。
patch_artist:bool类型参数,是否填充箱体的颜色;默认为False。
meanline:bool类型参数,是否用线的形式表示均值,默认为False。
showmeans:bool类型参数,是否显示均值,默认为False。
showcaps:bool类型参数,是否显示箱线图顶端和末端的两条线(即上下须),默认为
True。
showbox:bool类型参数,是否显示箱线图的箱体,默认为True。
showfliers:是否显示异常值,默认为True。
boxprops:设置箱体的属性,如边框色,填充色等。
labels:为箱线图添加标签,类似于图例的作用。
filerprops:设置异常值的属性,如异常点的形状、大小、填充色等。
medianprops:设置中位数的属性,如线的类型、粗细等。
meanprops:设置均值的属性,如点的大小、颜色等。
capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等。
whiskerprops:设置须的属性,如颜色、粗细、线的类型等。
block type size region height direction price built_date price_unit
0 梅园六街坊 2室0厅 47.72 浦东 低区/6层 朝南 500 1992年建 104777
1 碧云新天地(一期) 3室2厅 108.93 浦东 低区/6层 朝南 735 2002年建 67474
2 博山小区 1室1厅 43.79 浦东 中区/6层 朝南 260 1988年建 59374
3 金桥新村四街坊(博兴路986弄) 1室1厅 41.66 浦东 中区/6层 朝南北 280 1997年建 67210
4 博山小区 1室0厅 39.77 浦东 高区/6层 朝南 235 1987年建 59089
... ... ... ... ... ... ... ... ... ...
20270 棕榈湾花园 3室2厅 118.31 金山 低区/6层 朝南 330 2004年建 27892
20271 绿舟星城 3室2厅 102.77 崇明 低区/6层 朝南 180 2011年建 17514
20272 明珠花苑(崇明) 2室2厅 101.59 崇明 中区/6层 朝南北 205 2004年建 20179
20273 凤辰乐苑 2室1厅 81.43 崇明 高区/6层 朝南北 210 2008年建 25789
20274 富源花苑 2室2厅 90.61 崇明 高区/6层 朝南北 120 2004年建 13243
# 读取数据
Sec_Buildings = pd.read_excel(r'sec_buildings.xlsx')
# 绘制箱线图
plt.boxplot(x = Sec_Buildings.price_unit, # 指定绘图数据
patch_artist=True, # 要求用自定义颜色填充盒形图,默认白色填充
showmeans=True, # 以点的形式显示均值
boxprops = {'color':'black','facecolor':'steelblue'}, # 设置箱体属性,如边框色和填充色
# 设置异常点属性,如点的形状、填充色和点的大小
flierprops = {'marker':'o','markerfacecolor':'red', 'markersize':3},
# 设置均值点的属性,如点的形状、填充色和点的大小
meanprops = {'marker':'D','markerfacecolor':'indianred', 'markersize':4},
# 设置中位数线的属性,如线的类型和颜色
medianprops = {'linestyle':'--','color':'orange'},
labels = [''] # 删除x轴的刻度标签,否则图形显示刻度标签为1
)
# 添加图形标题
plt.title('二手房单价分布的箱线图')
# 显示图形
plt.show()
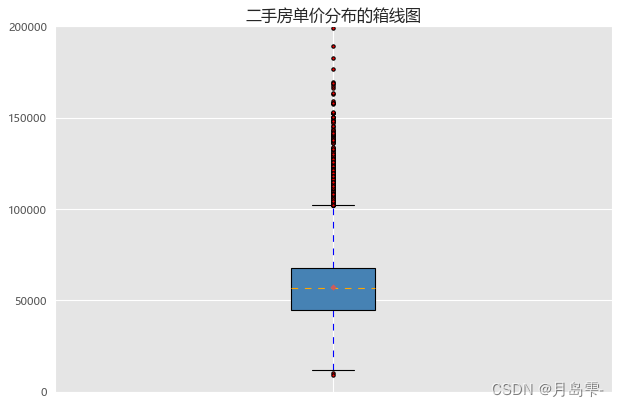
图中的上下两条横线代表上下须、箱体的上下两条横线代表上下四分位
数、箱体中的虚线代表中位数、箱体中的点则为均值、上下须两端的点代表异常值。通过图中均值和中位数的对比就可以得知数据微微右偏(判断标准:如果数据近似正态分布,则众数=中位数=均值;如果数据右偏,则众数<中位数<均值;如果数值左偏,则众数>中位数>均值)。
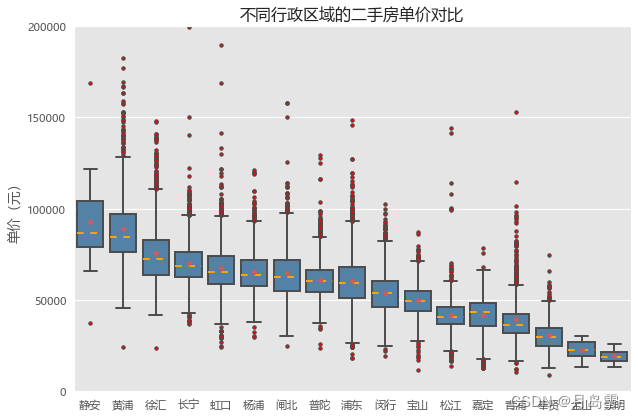
如上绘制的是二手房整体单价的箱线图,这样的箱线图可能并不常见,更多的是分组箱线图,即二手房的单价按照其他分组变量(如行政区域、楼层、朝向等)进行对比分析。下面继续使用matplotlib模块对二手房的单价绘制分组箱线图
# 二手房在各行政区域的平均单价
group_region = Sec_Buildings.groupby('region')
avg_price = group_region.aggregate({'price_unit':np.mean}).sort_values('price_unit', ascending = False)
# 通过循环,将不同行政区域的二手房存储到列表中
region_price = []
for region in avg_price.index:
region_price.append(Sec_Buildings.price_unit[Sec_Buildings.region == region])
# 绘制分组箱线图
plt.boxplot(x = region_price,
patch_artist=True,
labels = avg_price.index, # 添加x轴的刻度标签
showmeans=True,
boxprops = {'color':'black', 'facecolor':'steelblue'},
flierprops = {'marker':'o','markerfacecolor':'red', 'markersize':3},
meanprops = {'marker':'D','markerfacecolor':'indianred', 'markersize':4},
medianprops = {'linestyle':'--','color':'orange'}
)
# 添加y轴标签
plt.ylabel('单价(元)')
# 添加标题
plt.title('不同行政区域的二手房单价对比')
# 显示图形
plt.show()
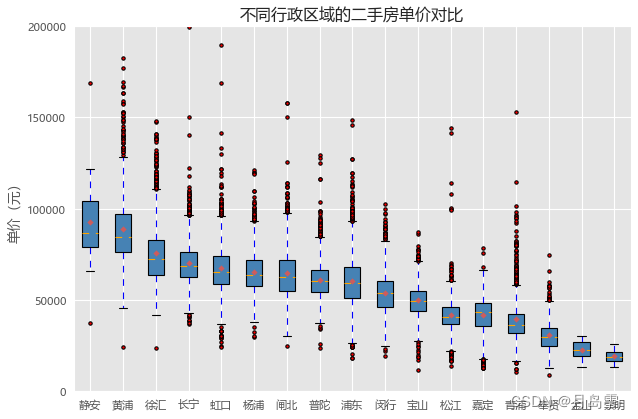
应用matplotlib模块绘制如上所示的分组箱线图会相对烦琐一些,由于boxplot函数每次只能绘制一个箱线图,为了能够实现多个箱线图的绘制,对数据稍微做了一些变动,即将每个行政区域下的二手房单价汇总到一个列表中,然后基于这个大列表应用boxplot函数。在绘图过程中,首先做了一个“手脚”,那就是统计各行政区域二手房的平均单价,并降序排序,这样做的目的就是让分组箱线图能够降序呈现。
虽然pandas模块中的plot方法可以绘制分组箱线图,但是该方法是基于数据框执行的,并且数据框的每一列对应一个箱线图。对于二手房数据集来说,应用plot方法绘制分组箱线图不太合适,因为每一个行政区的二手房数量不一致,将导致无法重构一个新的数据框用于绘图。
seaborn
sns.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
orient=None, color=None, palette=None, saturation=0.75, width=0.8,
dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
x:指定箱线图的x轴数据。
y:指定箱线图的y轴数据。
hue:指定分组变量。
data:指定用于绘图的数据集。
order:传递一个字符串列表,用于分类变量的排序。
hue_order:传递一个字符串列表,用于分类变量hue值的排序。
orient:指定箱线图的呈现方向,默认为垂直方向。
color:指定所有箱线图的填充色。
palette:指定hue变量的区分色。
saturation:指定颜色的透明度。
width:指定箱线图的宽度。
dodge:bool类型的参数,当使用hue参数时,是否绘制水平交错的箱线图,默认为True。
fliersize:指定异常值点的大小。
linewidth:指定箱体边框的宽度。
whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差。
notch:bool类型的参数,是否绘制凹口箱线图,默认为False。
ax:指定子图的位置。
**kwargs:关键字参数,可以调用plt.boxplot函数中的其他参数。
# 绘制分组箱线图
sns.boxplot(x = 'region', y = 'price_unit', data = Sec_Buildings,
order = avg_price.index, showmeans=True,color = 'steelblue',
flierprops = {'marker':'o','markerfacecolor':'red', 'markersize':3},
meanprops = {'marker':'D','markerfacecolor':'indianred', 'markersize':4},
medianprops = {'linestyle':'--','color':'orange'}
)
# 更改x轴和y轴标签
plt.xlabel('')
plt.ylabel('单价(元)')
# 添加标题
plt.title('不同行政区域的二手房单价对比')
# 显示图形
plt.show()
小提琴图
它将数值型数据的核密度图与箱线图融合在一起,进而得到一个形似小提琴的图形。尽管matplotlib模块也提供了绘制小提琴图的函数violinplot,但是绘制出来的图形中并不包含一个完整的箱线图,所以本节将直接使用seaborn
模块中的violinplot函数绘制小提琴图
sns.violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100,
width=0.8, inner='box', split=False, dodge=True, orient=None,
linewidth=None, color=None, palette=None, saturation=0.75, ax=None)
x:指定小提琴图的x轴数据。
y:指定小提琴图的y轴数据。
hue:指定一个分组变量。
data:指定绘制小提琴图的数据集。
order:传递一个字符串列表,用于分类变量的排序。
hue_order:传递一个字符串列表,用于分类变量hue值的排序。
bw:指定核密度估计的带宽,带宽越大,密度曲线越光滑。
scale:用于调整小提琴图左右的宽度,如果为area,则表示每个小提琴图左右部分拥有
相同的面积;如果为count,则表示根据样本数量来调节宽度;如果为width,则表示每个
小提琴图左右两部分拥有相同的宽度。
scale_hue:bool类型参数,当使用hue参数时,是否对hue变量的每个水平做标准化处理,
默认为True。
width:使用hue参数时,用于控制小提琴图的宽度。
inner:指定小提琴图内部数据点的形态,如果为box,则表示绘制微型的箱线图;如果为
quartiles,则表示绘制四分位的分布图;如果为point或stick,则表示绘制点或小竖条。
split:bool类型参数,使用hue参数时,将小提琴图从中间分为两个不同的部分,默认为
False。
dodge:bool类型的参数,当使用hue参数时,是否绘制水平交错的小提琴图,默认为
True。
orient:指定小提琴图的呈现方向,默认为垂直方向。
linewidth:指定小提琴图的所有线条宽度。
color:指定小提琴图的颜色,该参数与palette参数一起使用时无效。
palette:指定hue变量的区分色。
saturation:指定颜色的透明度。
ax:指定子图的位置。
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
... ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
244 rows × 7 columns
# 读取数据
tips = pd.read_csv(r'tips.csv')
# 绘制分组小提琴图
sns.violinplot(x = "total_bill", # 指定x轴的数据
y = "day", # 指定y轴的数据
hue = "sex", # 指定分组变量
data = tips, # 指定绘图的数据集
order = ['Thur','Fri','Sat','Sun'], # 指定x轴刻度标签的顺序
scale = 'count', # 以男女客户数调节小提琴图左右的宽度
split = True, # 将小提琴图从中间割裂开,形成不同的密度曲线;
palette = 'RdBu' # 指定不同性别对应的颜色(因为hue参数为设置为性别变量)
)
# 添加图形标题
plt.title('每天不同性别客户的消费额情况')
# 设置图例
plt.legend(loc = 'upper center', ncol = 2)
# 显示图形
plt.show()
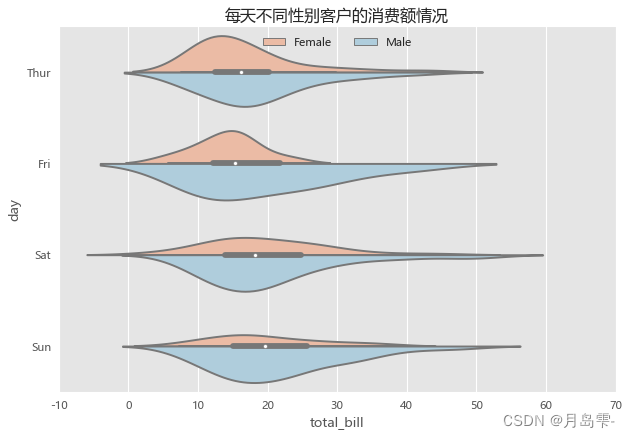
小提琴图的左右两边并不对称,是因为同时使用了hue参数和split参数,两边的核密度图代表了不同性别客户的消费额分布。从这张图中,一共可以反映四个维度的信息,y轴表示客户的消费额、x轴表示客户的消费时间、颜色图例表示客户的性别、左右核密度图的宽度代表了样本量。以周五和周六两天为例,周五的男女客户数量差异不大,而周六男性客户要比女性客户多得多,那是因为右半边的核密度图更宽一些。
折线图
matplotlib
plt.plot(x, y, linestyle, linewidth, color, marker,
markersize, markeredgecolor, markerfactcolor,
markeredgewidth, label, alpha)
x:指定折线图的x轴数据。
y:指定折线图的y轴数据。
linestyle:指定折线的类型,可以是实线、虚线、点虚线、点点线等,默认为实线。
linewidth:指定折线的宽度。
marker:可以为折线图添加点,该参数是设置点的形状。
markersize:设置点的大小。
markeredgecolor:设置点的边框色。
markerfactcolor:设置点的填充色。
markeredgewidth:设置点的边框宽度。
label:为折线图添加标签,类似于图例的作用。
Date Counts Times
0 2017-10-01 399 763
1 2017-10-02 126 345
2 2017-10-03 76 249
3 2017-10-04 59 182
4 2017-10-05 60 165
... ... ... ...
87 2017-12-27 1199 2282
88 2017-12-28 1833 2839
89 2017-12-29 1820 2992
90 2017-12-30 323 1096
91 2017-12-31 1894 2710
# 数据读取
wechat = pd.read_excel(r'wechat.xlsx')
# 绘制单条折线图
plt.plot(wechat.Date, # x轴数据
wechat.Counts, # y轴数据
linestyle = '-', # 折线类型
linewidth = 2, # 折线宽度
color = 'steelblue', # 折线颜色
marker = 'o', # 折线图中添加圆点
markersize = 6, # 点的大小
markeredgecolor='black', # 点的边框色
markerfacecolor='brown') # 点的填充色
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数趋势')
# 显示图形
plt.show()
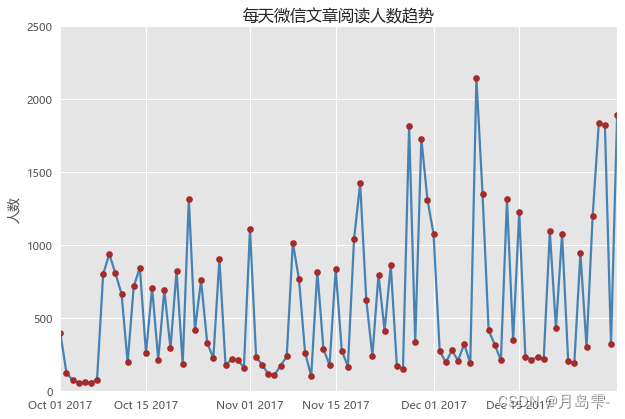
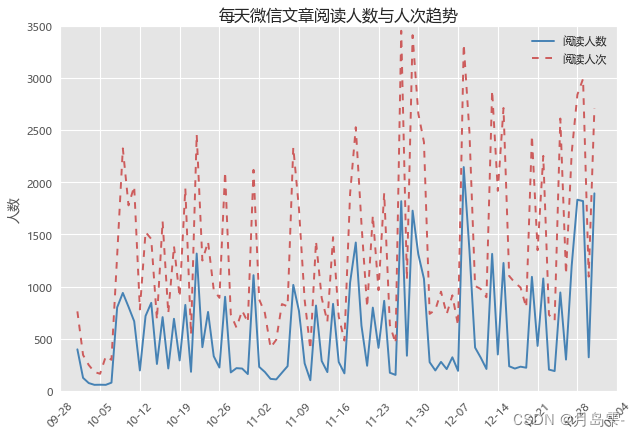
如何将微信文章的阅读人数和阅读人次同时呈现在图中。
对于x轴的刻度标签,是否可以只保留月份和日期,并且以7天作为间隔
# 绘制两条折线图
# 导入模块,用于日期刻度的修改
import matplotlib as mpl
# 绘制阅读人数折线图
plt.plot(wechat.Date, # x轴数据
wechat.Counts, # y轴数据
linestyle = '-', # 折线类型,实心线
color = 'steelblue', # 折线颜色
label = '阅读人数'
)
# 绘制阅读人次折线图
plt.plot(wechat.Date, # x轴数据
wechat.Times, # y轴数据
linestyle = '--', # 折线类型,虚线
color = 'indianred', # 折线颜色
label = '阅读人次'
)
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴显示多少个日期刻度
# xlocator = mpl.ticker.LinearLocator(10)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 为了避免x轴刻度标签的紧凑,将刻度标签旋转45度
plt.xticks(rotation=45)
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数与人次趋势')
# 添加图例
plt.legend()
# 显示图形
plt.show()
pandas
date year month day low high
0 2015-01-01 2015 1 1 -1 4
1 2015-01-02 2015 1 2 0 8
2 2015-01-03 2015 1 3 4 11
3 2015-01-04 2015 1 4 5 16
4 2015-01-05 2015 1 5 9 19
... ... ... ... ... ... ...
1091 2017-12-27 2017 12 27 6 12
1092 2017-12-28 2017 12 28 10 12
1093 2017-12-29 2017 12 29 9 13
1094 2017-12-30 2017 12 30 9 12
1095 2017-12-31 2017 12 31 3 10
# 读取天气数据
weather = pd.read_excel(r'weather.xlsx')
# 统计每月的平均最高气温
data = weather.pivot_table(index = 'month', columns='year', values='high')
# 绘制折线图
data.plot(kind = 'line',
style = ['-','--',':'] # 设置折线图的线条类型
)
# 修改x轴和y轴标签
plt.xlabel('月份')
plt.ylabel('气温')
# 添加图形标题
plt.title('每月平均最高气温波动趋势')
# 显示图形
plt.show()
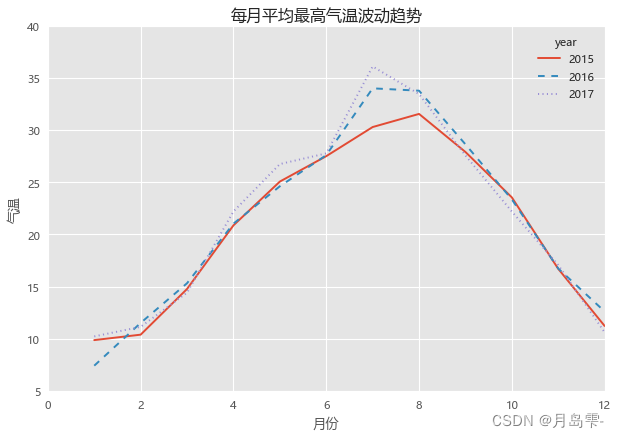
year 2015 2016 2017
month
1 9.870968 7.419355 10.225806
2 10.392857 11.517241 11.142857
3 14.774194 15.322581 14.419355
4 20.866667 21.033333 22.200000
5 25.064516 24.612903 26.741935
6 27.500000 27.600000 27.766667
7 30.290323 34.000000 36.096774
8 31.548387 33.774194 33.451613
9 27.900000 28.633333 27.566667
10 23.548387 23.354839 22.193548
11 16.700000 16.733333 17.066667
12 11.225806 12.612903 10.612903
图中表示的是各年份中每月平均最高气温的走势,虽然绘图的核心部分(plot过程)很简单,但是前提需要将原始数据集转换成可以绘制多条折线图的格式,即构成三条折线图的数据分别为数据框的三个字段。为了构造特定需求的数据集,使用了数据框的pivot_table方法,形成一张满足条件的透视表
散点图
matplotlib
scatter(x, y, s=20, c=None, marker='o', cmap=None, norm=None, vmin=None,
vmax=None, alpha=None, linewidths=None, edgecolors=None)
x:指定散点图的x轴数据。
y:指定散点图的y轴数据。
s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘
制。
c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色
阶表示数值大小。
marker:指定散点图点的形状,默认为空心圆。
cmap:指定某个Colormap值,只有当c参数是一个浮点型数组时才有效。
norm:设置数据亮度,标准化到0~1,使用该参数仍需要参数c为浮点型的数组。
vmin、vmax:亮度设置,与norm类似,如果使用norm参数,则该参数无效。
alpha:设置散点的透明度。
linewidths:设置散点边界线的宽度。
edgecolors:设置散点边界线的颜色。
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
... ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
# 读入数据
iris = pd.read_csv(r'iris.csv')
# 绘制散点图
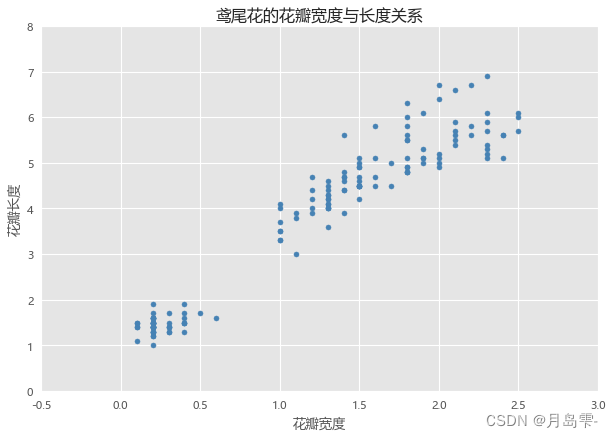
plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据
y = iris.Petal_Length, # 指定散点图的y轴数据
color = 'steelblue' # 指定散点图中点的颜色
)
# 添加x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
# 显示图形
plt.show()
pandas
# Pandas模块绘制散点图
# 绘制散点图
iris.plot(x = 'Petal_Width', y = 'Petal_Length', kind = 'scatter', title = '鸢尾花的花瓣宽度与长度关系')
# 修改x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 显示图形
plt.show()
seaborn
lmplot(x, y, data, hue=None, col=None, row=None, palette=None, col_wrap=None,
size=5, aspect=1, markers='o', sharex=True, sharey=True, hue_order=None,
col_order=None, row_order=None, legend=True, legend_out=True, scatter=True,
fit_reg=True, ci=95, n_boot=1000, order=1, logistic=False, lowess=False,
robust=False, logx=False, x_partial=None, y_partial=None, truncate=False,
x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None)
x,y:指定x轴和y轴的数据。
data:指定绘图的数据集。
hue:指定分组变量。
col,row:用于绘制分面图形,指定分面图形的列向与行向变量。
palette:为hue参数指定的分组变量设置颜色。
col_wrap:设置分面图形中每行子图的数量。
size:用于设置每个分面图形的高度。
aspect:用于设置每个分面图形的宽度,宽度等于size*aspect。
markers:设置点的形状,用于区分hue参数指定的变量水平值。
sharex,sharey:bool类型参数,设置绘制分面图形时是否共享x轴和y轴,默认为True。
hue_order,col_order,row_order:为hue参数、col参数和row参数指定的分组变量设值水平
值顺序。
legend:bool类型参数,是否显示图例,默认为True。
legend_out:bool类型参数,是否将图例放置在图框外,默认为True。
scatter:bool类型参数,是否绘制散点图,默认为True。
fit_reg:bool类型参数,是否拟合线性回归,默认为True。
ci:绘制拟合线的置信区间,默认为95%的置信区间。
n_boot:为了估计置信区间,指定自助重抽样的次数,默认为1000次。
order:指定多项式回归,默认指数为1。
logistic:bool类型参数,是否拟合逻辑回归,默认为False。
lowess:bool类型参数,是否拟合局部多项式回归,默认为False。
robust:bool类型参数,是否拟合鲁棒回归,默认为False。
logx:bool类型参数,是否对x轴做对数变换,默认为False。
x_partial,y_partial:为x轴数据和y轴数据指定控制变量,即排除x_partial和y_partial变量
的影响下绘制散点图。
truncate:bool类型参数,是否根据实际数据的范围对拟合线做截断操作,默认为False。
x_jitter,y_jitter:为x轴变量或y轴变量添加随机噪声,当x轴数据与y轴数据比较密集时,
可以使用这两个参数。
scatter_kws:设置点的其他属性,如点的填充色、边框色、大小等。
line_kws:设置拟合线的其他属性,如线的形状、颜色、粗细等。
# seaborn模块绘制分组散点图
sns.lmplot(x = 'Petal_Width', # 指定x轴变量
y = 'Petal_Length', # 指定y轴变量
hue = 'Species', # 指定分组变量
data = iris, # 指定绘图数据集
legend_out = False, # 将图例呈现在图框内
truncate=True # 根据实际的数据范围,对拟合线作截断操作
)
# 修改x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
# 显示图形
plt.show()
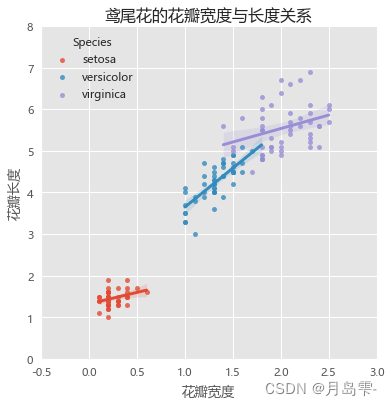
lmplot函数不仅可以绘制分组散点图,还可以对每个组内的散点添加回归线(图6-25默认拟合线性回归线)。分组效果的体现是通过hue参数设置的,如果需要拟合其他回归线,可以指定lowess参数(局部多项式回归)、logistic参数(逻辑回归)、order参数(多项式回归)和robust参数(鲁棒回归)。
气泡图
散点图都是反映两个数值型变量的关系,如果还想通过散点图添加第三个数值型变量的信息,一般可以使用气泡图。气泡图的实质就是通过第三个数值型变量控制每个散点的大小,点越大,代表的第三维数值越高,反之亦然。
应用matplotlib模块中的scatter函数绘制了散点图,本节将继续使用该函数绘制气泡图。要实现气泡图的绘制,关键的参数是s,即散点图中点的大小,如果将数值型变量传递给该参数,就可以轻松绘制气泡图了。
Category Sub_Category Profit Sales Profit_Ratio std_ratio
0 办公用品 信封 49241.560000 176861.520 0.278419 0.839328
1 办公用品 剪刀,尺子,锯 -7953.570000 80800.030 -0.098435 0.001000
2 办公用品 夹子及其配件 306455.289500 1026410.560 0.298570 0.884155
3 办公用品 家用电器 100258.320000 742663.390 0.134998 0.520283
4 办公用品 容器,箱子 10068.210000 1112252.530 0.009052 0.240110
5 办公用品 标签 13752.630000 39170.670 0.351095 1.001000
6 办公用品 橡皮筋 -76.840000 14906.260 -0.005155 0.208506
7 办公用品 笔、美术用品 8061.270000 169631.080 0.047522 0.325689
8 办公用品 纸张 46494.040000 455633.140 0.102043 0.446972
9 家具产品 书架 -35849.713500 835008.460 -0.042933 0.124466
10 家具产品 办公装饰品 104009.074000 709263.700 0.146644 0.546189
11 家具产品 桌子 -100006.371219 1911402.746 -0.052321 0.103583
12 家具产品 椅子 146337.545000 1826720.720 0.080109 0.398180
13 技术产品 办公机器 318648.157100 2180548.680 0.146132 0.545051
14 技术产品 复印机、传真机 176189.034000 1157199.770 0.152255 0.558671
15 技术产品 电脑配件 94659.240000 812668.390 0.116480 0.479087
16 技术产品 电话通信产品 318802.106000 1903478.610 0.167484 0.592549
# 读取数据
Prod_Category = pd.read_excel(r'SuperMarket.xlsx')
# 将利润率标准化到[0,1]之间(因为利润率中有负数),然后加上微小的数值0.001
range_diff = Prod_Category.Profit_Ratio.max()-Prod_Category.Profit_Ratio.min()
Prod_Category['std_ratio'] = (Prod_Category.Profit_Ratio-Prod_Category.Profit_Ratio.min())/range_diff + 0.001
# 绘制办公用品的气泡图
plt.scatter(x = Prod_Category.Sales[Prod_Category.Category == '办公用品'],
y = Prod_Category.Profit[Prod_Category.Category == '办公用品'],
s = Prod_Category.std_ratio[Prod_Category.Category == '办公用品']*1000,
color = 'steelblue', label = '办公用品', alpha = 0.6
)
# 绘制技术产品的气泡图
plt.scatter(x = Prod_Category.Sales[Prod_Category.Category == '技术产品'],
y = Prod_Category.Profit[Prod_Category.Category == '技术产品'],
s = Prod_Category.std_ratio[Prod_Category.Category == '技术产品']*1000,
color = 'indianred' , label = '技术产品', alpha = 0.6
)
# 绘制家具产品的气泡图
plt.scatter(x = Prod_Category.Sales[Prod_Category.Category == '家具产品'],
y = Prod_Category.Profit[Prod_Category.Category == '家具产品'],
s = Prod_Category.std_ratio[Prod_Category.Category == '家具产品']*1000,
color = 'black' , label = '家具产品', alpha = 0.6
)
# 添加x轴和y轴标签
plt.xlabel('销售额')
plt.ylabel('利润')
# 添加标题
plt.title('销售额、利润及利润率的气泡图')
# 添加图例
plt.legend()
# 显示图形
plt.show()
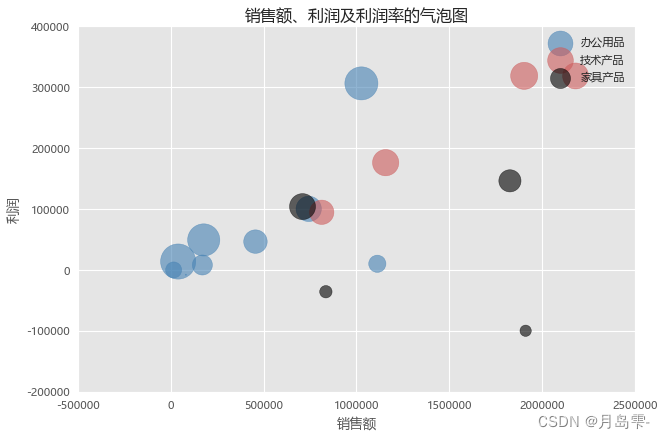
应用scatter函数绘制了分组气泡图,从图中可知,办公用品和家具产品的利润率波动比较大(因为这两类圆点大小不均)。从代码角度来看,绘图的核心部分是使用三次scatter函数,而且代码结构完全一样,如果读者对for循环掌握得比较好,完全可以使用循环的方式替换三次scatter函数的重复应用。
需要说明的是,如果s参数对应的变量值小于等于0,则对应的气泡点是无法绘制出来的。这里提供一个解决思路,就是先将该变量标准化为[0,1],再加上一个非常小的值,如0.001。如上代码所示,最后对s参数扩大500倍的目的就是凸显气泡的大小。遗憾的是,pandas模块和seaborn模块中没有绘制气泡图的方法或函数,故这里就不再衍生了。如果读者确实需要绘制气泡图,又觉得matplotlib模块中的scatter函数用起来比较灿琐,可以使用Python的bokeh模块,有关该模块的详细内容,可以查看官方文档。
热力图
seaborn
heatmap(data, vmin=None, vmax=None, cmap=None, center=None, annot=None, fmt='.2g',
annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws = None,
square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None)
data:指定绘制热力图的数据集。
vmin,vmax:用于指定图例中最小值与最大值的显示值。
cmap:指定一个colormap对象,用于热力图的填充色。
center:指定颜色中心值,通过该参数可以调整热力图的颜色深浅。
annot:指定一个bool类型的值或与data参数形状一样的数组,如果为True,就在热力图的
每个单元上显示数值。
fmt:指定单元格中数据的显示格式。
annot_kws:有关单元格中数值标签的其他属性描述,如颜色、大小等。
linewidths:指定每个单元格的边框宽度。
linecolor:指定每个单元格的边框颜色。
cbar:bool类型参数,是否用颜色条作为图例,默认为True。
square:bool类型参数,是否使热力图的每个单元格为正方形,默认为False。
cbar_kws:有关颜色条的其他属性描述。
xticklabels,yticklabels:指定热力图x轴和y轴的刻度标签,如果为True,则分别以数据框
的变量名和行名称作为刻度标签。
mask:用于突出显示某些数据。
ax:用于指定子图的位置。
Date Sales
0 2010-10-13 261.5400
1 2012-02-20 6.0000
2 2011-07-15 2808.0800
3 2011-07-15 1761.4000
4 2011-07-15 160.2335
... ... ...
8563 2012-11-15 18.9100
8564 2012-11-15 685.7000
8565 2012-11-15 1024.1650
8566 2009-01-23 1383.2000
8567 2011-05-27 211.4200
Date Sales year month
0 2010-10-13 261.5400 2010 10
1 2012-02-20 6.0000 2012 2
2 2011-07-15 2808.0800 2011 7
3 2011-07-15 1761.4000 2011 7
4 2011-07-15 160.2335 2011 7
... ... ... ... ...
8563 2012-11-15 18.9100 2012 11
8564 2012-11-15 685.7000 2012 11
8565 2012-11-15 1024.1650 2012 11
8566 2009-01-23 1383.2000 2009 1
8567 2011-05-27 211.4200 2011 5
year 2009 2010 2011 2012
month
1 520452.5595 334535.0605 255919.2030 341339.2470
2 333909.5565 271881.9480 299890.1410 281270.1790
3 411628.7290 217808.0065 296151.7510 387093.7650
4 406848.7620 266968.5890 290384.4670 278402.9940
5 228025.5680 287796.5150 264673.6260 384588.0615
6 273758.8780 293600.7750 196918.1455 316775.7855
7 412797.4600 240297.1585 287905.1865 275160.0495
8 329754.7150 205789.6440 275211.3295 306671.2835
9 325292.3145 419689.7785 278230.1660 319675.1765
10 347173.8005 368544.9250 305660.4510 351438.0925
11 253867.1960 295010.9555 385452.7300 261206.4290
12 420420.2355 368093.9540 328898.4945 351756.4180
多个图形的合并
关于多种图形的组合,可以使用matplotlib模块中的subplot2grid函数。这个函数的灵活性非常高,构成的组合图既可以是m×n的矩阵风格,也可以是跨行或跨列的矩阵风格。
subplot2grid(shape, loc, rowspan=1, colspan=1, **kwargs)
shape:指定组合图的框架形状,以元组形式传递,如2×3的矩阵可以表示成(2,3)。
loc:指定子图所在的位置,如shape中第一行第一列可以表示成(0,0)。
rowspan:指定某个子图需要跨几行。
colspan:指定某个子图需要跨几列。
Date Order_Class Sales Transport Trans_Cost Region Category Box_Type year month
0 2010-10-13 低级 261.5400 火车 35.00 华北 办公用品 大型箱子 2010 10
1 2012-02-20 其它 6.0000 火车 2.56 华南 办公用品 小型包裹 2012 2
2 2011-07-15 高级 2808.0800 火车 5.81 华南 家具产品 中型箱子 2011 7
3 2011-07-15 高级 1761.4000 大卡 89.30 华北 家具产品 巨型纸箱 2011 7
4 2011-07-15 高级 160.2335 火车 5.03 华北 技术产品 中型箱子 2011 7
... ... ... ... ... ... ... ... ... ... ...
8563 2012-11-15 高级 18.9100 火车 7.01 华东 办公用品 小型箱子 2012 11
8564 2012-11-15 高级 685.7000 火车 20.79 华南 家具产品 大型箱子 2012 11
8565 2012-11-15 高级 1024.1650 火车 5.99 华南 技术产品 小型箱子 2012 11
8566 2009-01-23 中级 1383.2000 火车 12.14 华南 技术产品 小型箱子 2009 1
8567 2011-05-27 其它 211.4200 火车 9.45 华南 办公用品 小型箱子 2011 5
# 读取数据
Prod_Trade = pd.read_excel(r'Prod_Trade.xlsx')
# 衍生出交易年份和月份字段
Prod_Trade['year'] = Prod_Trade.Date.dt.year
Prod_Trade['month'] = Prod_Trade.Date.dt.month
# 设置大图框的长和高
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0))
# 统计2012年各订单等级的数量
Class_Counts = Prod_Trade.Order_Class[Prod_Trade.year == 2012].value_counts()
Class_Percent = Class_Counts/Class_Counts.sum()
# 将饼图设置为圆形(否则有点像椭圆)
ax1.set_aspect(aspect = 'equal')
# 绘制订单等级饼图
ax1.pie(x = Class_Percent.values, labels = Class_Percent.index, autopct = '%.1f%%')
# 添加标题
ax1.set_title('各等级订单比例')
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1))
# 统计2012年每月销售额
Month_Sales = Prod_Trade[Prod_Trade.year == 2012].groupby(by = 'month').aggregate({'Sales':np.sum})
# 绘制销售额趋势图
Month_Sales.plot(title = '2012年各月销售趋势', ax = ax2, legend = False)
# 删除x轴标签
ax2.set_xlabel('')
# 设置第三个子图的布局
ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2)
# 绘制各运输方式的成本箱线图
sns.boxplot(x = 'Transport', y = 'Trans_Cost', data = Prod_Trade, ax = ax3)
# 添加标题
ax3.set_title('各运输方式成本分布')
# 删除x轴标签
ax3.set_xlabel('')
# 修改y轴标签
ax3.set_ylabel('运输成本')
# 设置第四个子图的布局
ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2)
# 2012年客单价分布直方图
sns.distplot(Prod_Trade.Sales[Prod_Trade.year == 2012], bins = 40, norm_hist = True, ax = ax4, hist_kws = {'color':'steelblue'}, kde_kws=({'linestyle':'--', 'color':'red'}))
# 添加标题
ax4.set_title('2012年客单价分布图')
# 修改x轴标签
ax4.set_xlabel('销售额')
# 调整子图之间的水平间距和高度间距
plt.subplots_adjust(hspace=0.6, wspace=0.3)
# 图形显示
plt.show()
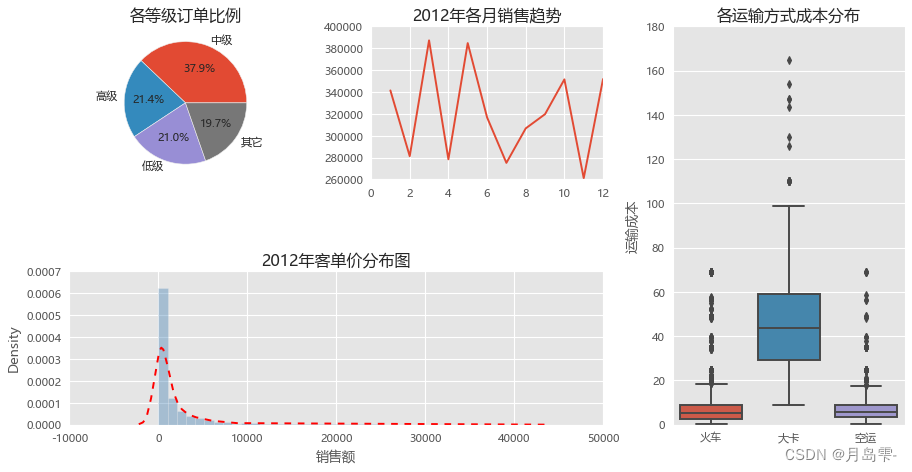
构成了2×3风格的组合图,其中两幅子图是跨行和跨列的,而且这里特地选了matplotlib模块、pandas模块和seabron模块绘制子图,目的是让读者能够掌握不同模块图形的组合。针对如上代码,需要讲解几个重要的知识点:在绘制每一幅子图之前,都需要运用subplot2grid函数控制子图的位置,并传递给一个变量对象(如代码中的ax1、ax2等)为了使子图位置(ax1、ax2等)产生效果,不同的绘图模块需要应用不同的方法。如果通过matplotlib模块绘制子图,则必须使用ax1.plot_function的代码语法(如上代码中,绘制饼图的过程);如果通过pandas模块或seaborn模块绘制子图,则需要为绘图“方法”或函数指定ax参数(如上代码中,绘制折线图、直方图和箱线图的过程)。如果为子图添加标题、坐标轴标签、刻度值标签等,不能直接使用plt.title、plt.xlabel、plt.xticks等函数,而是换成ax1.set_*的形式(可参考如上代码中对子图标题、坐标轴标签的设置)。由于子图之间的默认宽间距和高间距不太合理,故需要通过subplots_adjust函数重新修改子图之间的水平间距和垂直间距(如倒数第二行代码所示)。
AGE CDRSB ADAS11 ADAS13 MMSE RAVLT_immediate Hippocampus Ventricles WholeBrain Entorhinal MidTemp Fusiform DX
0 74.3 0.0 10.67 18.67 28 44 8336.0 118233.0 1229740 4177 27936 16559 CN
1 81.3 4.5 22.00 31.00 20 22 5319.0 84599.0 1129830 1791 18422 15506 AD
2 81.3 6.0 19.00 30.00 24 19 5446.0 88580.0 1100060 2427 16972 14400 AD
3 81.3 3.5 24.00 35.00 17 31 5157.0 90099.0 1095640 1596 17330 14617 AD
4 81.3 8.0 25.67 37.67 19 23 5139.0 97420.0 1088560 1175 16398 14033 AD
... ... ... ... ... ... ... ... ... ... ... ... ... ...
7008 61.8 0.0 7.33 12.33 28 42 7733.5 19821.5 977562 3538 21445 18455 CN
7009 58.7 0.0 5.33 8.33 29 34 8034.4 20189.8 1103550 4145 20169 20072 CN
7010 80.4 6.0 29.33 41.33 21 24 3913.4 42920.1 827456 2252 14528 11523 AD
7011 66.9 0.5 16.00 24.00 25 12 7574.4 62441.4 968034 3867 19609 16159 MCI
7012 67.3 0.0 1.67 1.67 30 59 6796.7 9473.6 989992 4500 17825 18872 CN
















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









