







一、概述
在我们平时使用SQL操作数据库中,查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。
也确实SELECT是SQL语言的基础,最为重要。现在我们就把SELECT查询语法好好的捋一捋,相信看完本文你一定会玩转SELECT。
需要说明的是,下面很多SQL语句只需要注重语法就行,不必去纠结表名或字段名。
二、基本的SELECT语句
1. SELECT …
# 没有任何子句
SELECT 100;
SELECT 3 + 2;
2. SELECT … FROM
- 语法
SELECT 列名
FROM 表名
- 选中全部列
SELECT *
FROM student
- 选择特定列
SELECT id, name
FROM student
- 一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符
*。使用通配符虽然可以节省输入查询语句的时间,但是获取不需要的列数据通常会降低查询和所使用的应用程序的效率。通配符的优势是,当不知道所需要的列的名称时,可以通过它获取它们。- 在生产环境下,不推荐直接使用
SELECT *进行查询。
3. 列的别名
说明:
- 重命名一个列
- 便于计算
- 紧跟列名,也可以在列名和别名之间加入关键字
AS,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。AS可以省略
SELECT id AS stu_id, name stu_name
FROM student;
SELECT id AS "stu id", name "stu name"
FROM student;
4. 去除重复行
默认情况下,查询会返回全部行,包括重复行。
# 在SELECT语句中使用关键字DISTINCT去除重复行
SELECT DISTINCT department_id
FROM employees;
针对以以下这种情况:
SELECT DISTINCT department_id,salary
FROM employees;
这里有两点需要注意:
DISTINCT需要放到所有列名的前面,如果写成SELECT salary, DISTINCT department_id FROM employees会报错。- DISTINCT 其实是对后面所有列名的组合进行去重,即对它后面的每个列的值都要进行比较,只有每个字段的值都相同了才叫重复。
5. 空值参与计算
- 所有运算符或列值遇到
NULL值,运算的结果都为NULL
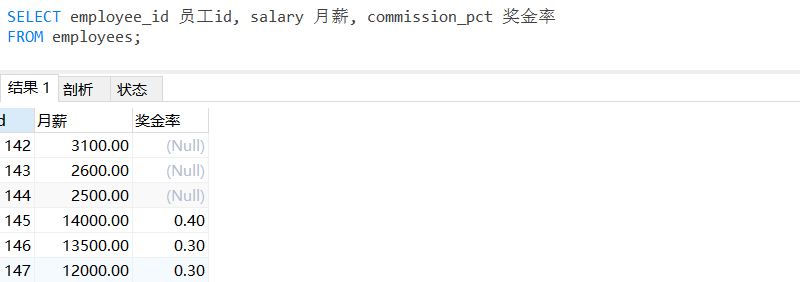
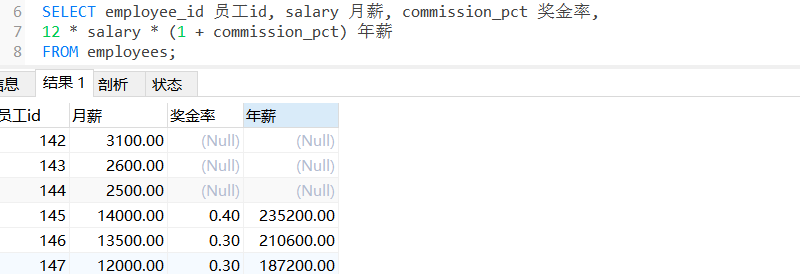
来个案例,在 employees 表中有员工id、月薪、奖金率三个字段(如下图),我们现在需要算出年薪
(12 * 月薪 * (1 + 奖金率))。
但当我们查询年薪时,就出问题了,以上奖金率为
NULL的同志不就是没有奖金吗,现在直接工资都为NULL了,这搁谁乐意。
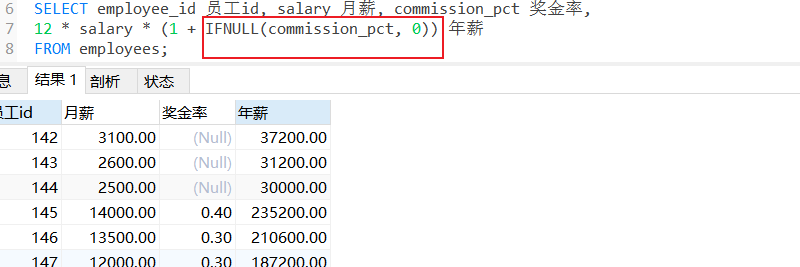
为了解决这个问题,我们可以使用
IFNULL()函数
IFNULL解析:
用于判断第一个表达式是否为NULL,如果为NULL,则返回第二个参数,否则返回第一个参数的值。
因此,我们可以按如下查询
6. 着重号的使用
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,那就使用一对 ``(着重号)引起来
错误
正确


7. 查询常数
SELECT 查询还可以对常数进行查询。对的,就是在 SELECT 查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。
比如说,我们想对 employees 数据表中增加一列字段 my_name,这个
字段固定值为“TYT”,可以这样写:
SELECT 'TYT' as my_name FROM employees
8. 数据过滤
- 语法
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
- 使用WHERE 子句,将不满足条件的行过滤掉
- WHERE 子句紧随 FROM 子句
SELECT employee_id, last_name, job_id, department_id
FROM employees
WHERE department_id = 90 ;
三、显示表结构
使用DESCRIBE 或 DESC 命令,表示表结构。
DESCRIBE employees;
# 或
DESC employees;
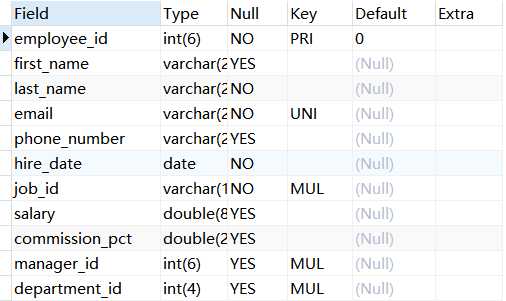
其中,各个字段的含义分别解释如下:
- Field:表示字段名称。
- Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
- Null:表示该列是否可以存储NULL值。
- Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
- Default:表示该列是否有默认值,如果有,那么值是多少。
- Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
四、运算符
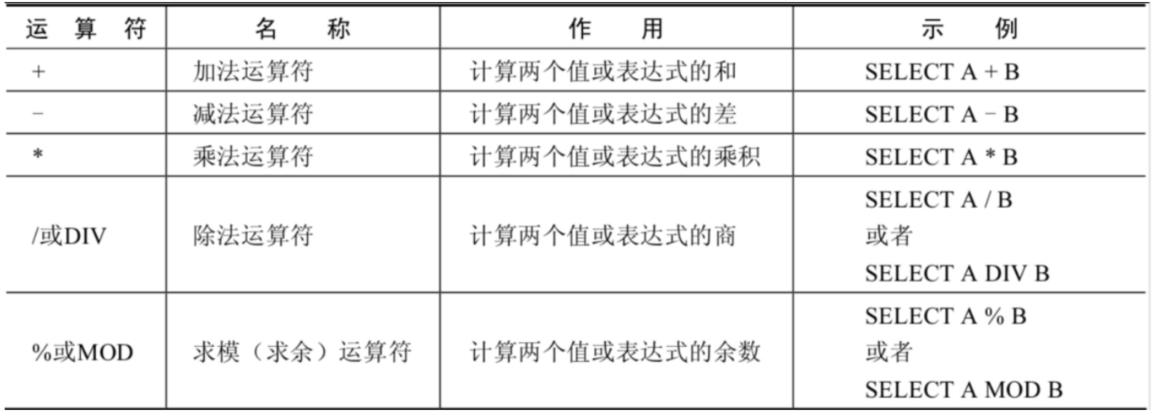
1. 算术运算符
算术运算符主要用于数学运算,其可以连接运算符前后的两个数值或表达式,对数值或表达式进行加(+)、减(-)、乘(*)、除(/)和取模(%)运算。
mysql> # 除法运算时,若分母为0,则结果为 NULL
mysql> SELECT 1, 1 + 1, 4 - 1, 3 + 2.5, 2 * 3, 8 / 3, 8 % 3, 100 / 0
-> FROM DUAL;
+---+-------+-------+---------+-------+--------+-------+---------+
| 1 | 1 + 1 | 4 - 1 | 3 + 2.5 | 2 * 3 | 8 / 3 | 8 % 3 | 100 / 0 |
+---+-------+-------+---------+-------+--------+-------+---------+
| 1 | 2 | 3 | 5.5 | 6 | 2.6667 | 2 | NULL |
+---+-------+-------+---------+-------+--------+-------+---------+
1 row in set, 1 warning (0.00 sec)
mysql> # SQL中 + 没有连接的作用,只表示加法运算。此时,会将子符串转换为数值(隐士转换)
mysql> SELECT 100 + '1'
-> FROM DUAL;
+-----------+
| 100 + '1' |
+-----------+
| 101 |
+-----------+
1 row in set (0.00 sec)
mysql> # 此时 a 当成 0 处理
mysql> SELECT 100 + 'a'
-> FROM DUAL;
+-----------+
| 100 + 'a' |
+-----------+
| 100 |
+-----------+
1 row in set, 1 warning (0.00 sec)
- 一个整数类型的值对整数进行加法和减法操作,结果还是一个整数;
- 一个整数类型的值对浮点数进行加法和减法操作,结果是一个浮点数;
- 在Java中,+的左右两边如果有字符串,那么表示字符串的拼接。但是在MySQL中+只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算。(补充:MySQL 中字符串拼接要使用字符串函数CONCAT()实现)
- 一个数除以另一个数,除不尽时,结果为一个浮点数,并保留到小数点后4位;
乘法和除法的优先级相同,进行先乘后除操作与先除后乘操作,得出的结果相同。- 在数学运算中,0不能用作除数,在MySQL中,一个数除以0为NULL。
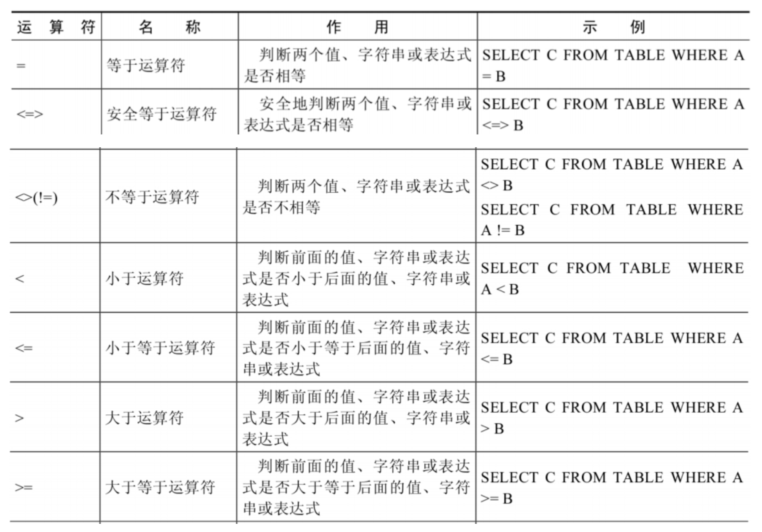
2. 比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。
等号运算符
- 等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回 0。
- 在使用等号运算符时,遵循如下规则:
- 如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等。
- 如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小。
- 如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。
- 如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL
mysql> SELECT 1 = 1, 1 = '1', 1 = 0, 'a' = 'a', (5 + 3) = (2 + 6), '' = NULL , NULL = NULL;
+-------+---------+-------+-----------+-------------------+-----------+-------------+
| 1 = 1 | 1 = '1' | 1 = 0 | 'a' = 'a' | (5 + 3) = (2 + 6) | '' = NULL | NULL = NULL |
+-------+---------+-------+-----------+-------------------+-----------+-------------+
| 1 | 1 | 0 | 1 | 1 | NULL | NULL |
+-------+---------+-------+-----------+-------------------+-----------+-------------+
1 row in set (0.00 sec)
安全等于运算符:
- 安全等于运算符(<=>)与等于运算符(=)的作用是相似的, 唯一的区别 是‘<=>’可 以用来对NULL进行判断。在两个操作数均为NULL时,其返回值为1,而不为NULL;当一个操作数为NULL时,其返回值为0,而不为NULL。
mysql> SELECT 1 <=> '1', 1 <=> 0, 'a' <=> 'a', (5 + 3) <=> (2 + 6), '' <=> NULL,NULL <=> NULL FROM dual;
+-----------+---------+-------------+---------------------+-------------+---------------+
| 1 <=> '1' | 1 <=> 0 | 'a' <=> 'a' | (5 + 3) <=> (2 + 6) | '' <=> NULL | NULL <=> NULL |
+-----------+---------+-------------+---------------------+-------------+---------------+
| 1 | 0 | 1 | 1 | 0 | 1 |
+-----------+---------+-------------+---------------------+-------------+---------------+
1 row in set (0.00 sec)
不等于运算符:
- 不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等, 如果不相等则返回1,相等则返回0。不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL, 或两边都为NULL,则结果为NULL。
mysql> SELECT 1 <> 1, 1 != 2, 'a' != 'b', (3+4) <> (2+6), 'a' != NULL, NULL <> NULL;
+--------+--------+------------+----------------+-------------+--------------+
| 1 <> 1 | 1 != 2 | 'a' != 'b' | (3+4) <> (2+6) | 'a' != NULL | NULL <> NULL |
+--------+--------+------------+----------------+-------------+--------------+
| 0 | 1 | 1 | 1 | NULL | NULL |
+--------+--------+------------+----------------+-------------+--------------+
1 row in set (0.00 sec)
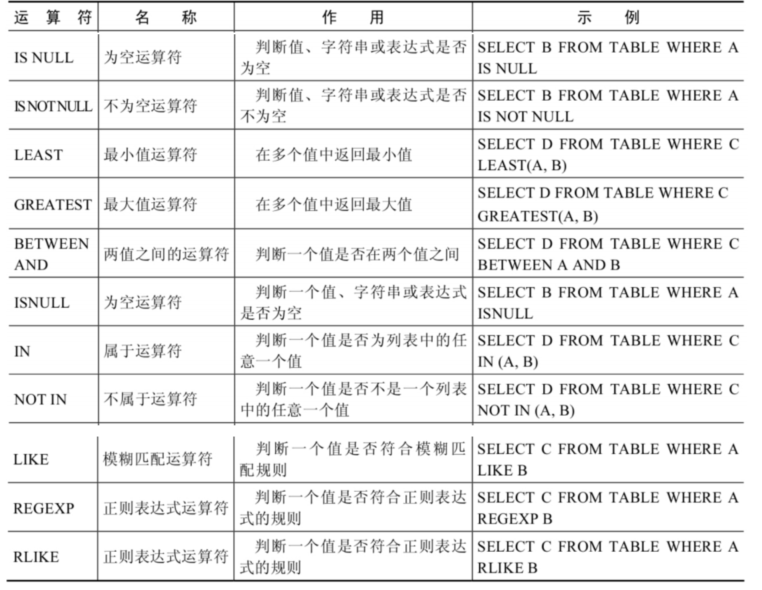
3. 非符号类型运算符
空运算符
- 空运算符(
IS NULL或者ISNULL)判断一个值是否为NULL,如果为NULL则返回1,否则返回0。
mysql> SELECT NULL IS NULL, ISNULL(NULL), ISNULL('a'), 1 IS NULL;
+--------------+--------------+-------------+-----------+
| NULL IS NULL | ISNULL(NULL) | ISNULL('a') | 1 IS NULL |
+--------------+--------------+-------------+-----------+
| 1 | 1 | 0 | 0 |
+--------------+--------------+-------------+-----------+
1 row in set (0.00 sec)
非空运算符
- 非空运算符(IS NOT NULL)判断一个值是否不为NULL,如果不为NULL则返回1,否则返回0。
mysql> SELECT NULL IS NOT NULL, 'a' IS NOT NULL, 1 IS NOT NULL;
+------------------+-----------------+---------------+
| NULL IS NOT NULL | 'a' IS NOT NULL | 1 IS NOT NULL |
+------------------+-----------------+---------------+
| 0 | 1 | 1 |
+------------------+-----------------+---------------+
1 row in set (0.00 sec)
最小值运算符
- 语法格式为:LEAST(值1,值2,…,值n)。其中,“值n”表示参数列表中有n个值。在有两个或多个参数的情况下,返回最小值。
mysql> SELECT LEAST (1,0,2), LEAST('b','a','c'), LEAST(1,NULL,2);
+---------------+--------------------+-----------------+
| LEAST (1,0,2) | LEAST('b','a','c') | LEAST(1,NULL,2) |
+---------------+--------------------+-----------------+
| 0 | a | NULL |
+---------------+--------------------+-----------------+
1 row in set (0.00 sec)
最大值运算符
- 语法格式为:
GREATEST(值1,值2,...,值n)。其中,n表示参数列表中有n个值。当有两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值为NULL。
mysql> SELECT GREATEST(1,0,2), GREATEST('b','a','c'), GREATEST(1,NULL,2);
+-----------------+-----------------------+--------------------+
| GREATEST(1,0,2) | GREATEST('b','a','c') | GREATEST(1,NULL,2) |
+-----------------+-----------------------+--------------------+
| 2 | c | NULL |
+-----------------+-----------------------+--------------------+
1 row in set (0.11 sec)
由结果可以看到,当参数中是整数或者浮点数时,GREATEST将返回其中最大的值;当参数为字符串时,返回字母表中顺序最靠后的字符;当比较值列表中有NULL时,不能判断大小,返回值为NULL。
BETWEEN AND运算符
- BETWEEN运算符使用的格式通常为
SELECT D FROM TABLE WHERE CBETWEEN A AND B,此时,当C大于或等于A,并且C小于或等于B时,结果为1,否则结果为0
mysql> SELECT 1 BETWEEN 0 AND 1, 10 BETWEEN 11 AND 12, 'b' BETWEEN 'a' AND 'c';
+-------------------+----------------------+-------------------------+
| 1 BETWEEN 0 AND 1 | 10 BETWEEN 11 AND 12 | 'b' BETWEEN 'a' AND 'c' |
+-------------------+----------------------+-------------------------+
| 1 | 0 | 1 |
+-------------------+----------------------+-------------------------+
1 row in set (0.00 sec)
IN运算符
- IN运算符用于判断给定的值是否是IN列表中的一个值,如果是则返回1,否则返回0。如果给 定的值为NULL,或者IN列表中存在NULL,则结果为NULL。
mysql> SELECT 'a' IN ('a','b','c'), 1 IN (2,3), NULL IN ('a','b'), 'a' IN ('a', NULL);
+----------------------+------------+-------------------+--------------------+
| 'a' IN ('a','b','c') | 1 IN (2,3) | NULL IN ('a','b') | 'a' IN ('a', NULL) |
+----------------------+------------+-------------------+--------------------+
| 1 | 0 | NULL | 1 |
+----------------------+------------+-------------------+--------------------+
1 row in set (0.00 sec)
NOT IN运算符
- NOT IN运算符用于判断给定的值是否不是IN列表中的一个值,如果不是IN列表中的一个值,则返回1,否则返回0。
mysql> SELECT 'a' NOT IN ('a','b','c'), 1 NOT IN (2,3);
+--------------------------+----------------+
| 'a' NOT IN ('a','b','c') | 1 NOT IN (2,3) |
+--------------------------+----------------+
| 0 | 1 |
+--------------------------+----------------+
1 row in set (0.00 sec)
LIKE运算符
- LIKE运算符主要用来匹配字符串,通常用于模糊匹配,如果满足条件则返回1,否则返回 0。如果给定的值或者匹配条件为NULL,则返回结果为NULL。
LIKE运算符通常使用如下通配符:
"%":匹配0个或多个字符。
"_":只能匹配一个字符。
mysql> SELECT NULL LIKE 'abc', 'abc' LIKE NULL;
+-----------------+-----------------+
| NULL LIKE 'abc' | 'abc' LIKE NULL |
+-----------------+-----------------+
| NULL | NULL |
+-----------------+-----------------+
1 row in set (0.00 sec)
mysql> SELECT first_name
-> FROM employees
-> WHERE first_name LIKE 'S%';
+------------+
| first_name |
+------------+
| Steven |
| Shelley |
+------------+
2 rows in set (0.00 sec)
mysql> SELECT last_name
-> FROM employees
-> WHERE last_name LIKE '_o%';
+------------+
| last_name |
+------------+
| Kochhar |
| Jones |
+------------+
2 rows in set (0.00 sec)
ESCAPE
- 回避特殊符号的:使用转义符。例如:将
[%]转为[$%]、[]转为[$],然后再加上[ESCAPE '$']即可。
# 查询第2个字符是_且第3个字符是'a'的员工信息
# 需要使用转义字符: \
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%';
- 如果使用
\表示转义,要省略ESCAPE。如果不是\,则要加上ESCAPE。
SELECT last_name
FROM employees
WHERE last_name LIKE '_$_a%' ESCAPE '$';
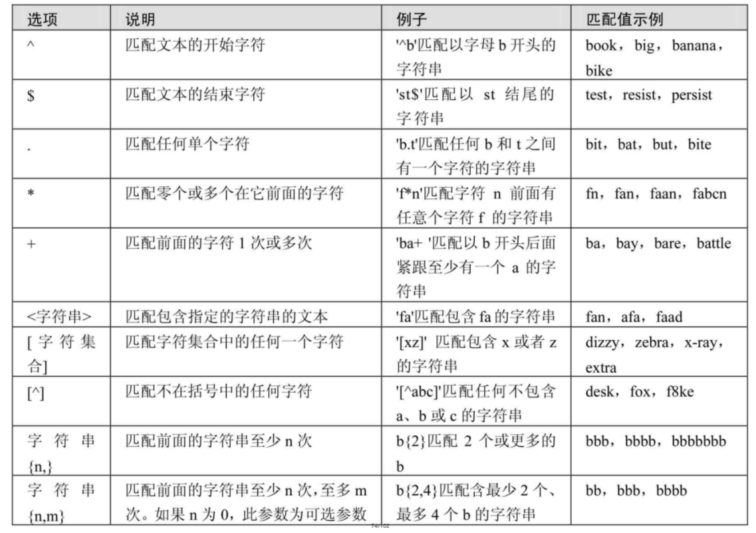
REGEXP运算符
REGEXP运算符用来匹配字符串,语法格式为: expr REGEXP 匹配条件 。如果expr满足匹配条件,返回1;如果不满足,则返回0。若expr或匹配条件任意一个为NULL,则结果为NULL。
REGEXP运算符在进行匹配时,常用的有下面几种通配符:
mysql> SELECT 'shkstart' REGEXP '^s', 'shkstart' REGEXP 't$', 'shkstart' REGEXP 'hk';
+------------------------+------------------------+------------------------+
| 'shkstart' REGEXP '^s' | 'shkstart' REGEXP 't$' | 'shkstart' REGEXP 'hk' |
+------------------------+------------------------+------------------------+
| 1 | 1 | 1 |
+------------------------+------------------------+------------------------+
1 row in set (2.04 sec)
mysql> SELECT 'Tangyitao' REGEXP 'an.yit', 'TYT' REGEXP '[ab]';
+-----------------------------+---------------------+
| 'Tangyitao' REGEXP 'an.yit' | 'TYT' REGEXP '[ab]' |
+-----------------------------+---------------------+
| 1 | 0 |
+-----------------------------+---------------------+
1 row in set (0.00 sec)
4. 逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL。
MySQL中支持4种逻辑运算符如下:

逻辑非运算符
- 逻辑非(NOT或!)运算符表示当给定的值为0时返回1;当给定的值为非0值时返回0;当给定的值为NULL时,返回NULL。
mysql> SELECT NOT 1, NOT 0, NOT(1+1), NOT !1, NOT NULL;
+-------+-------+----------+--------+----------+
| NOT 1 | NOT 0 | NOT(1+1) | NOT !1 | NOT NULL |
+-------+-------+----------+--------+----------+
| 0 | 1 | 0 | 1 | NULL |
+-------+-------+----------+--------+----------+
1 row in set (0.00 sec)
逻辑与运算符
- 逻辑与(AND或&&)运算符是当给定的所有值均为非0值,并且都不为NULL时,返回 1;当给定的一个值或者多个值为0时则返回0;否则返回NULL。
mysql> SELECT 1 AND -1, 0 AND 1, 0 AND NULL, 1 AND NULL;
+----------+---------+------------+------------+
| 1 AND -1 | 0 AND 1 | 0 AND NULL | 1 AND NULL |
+----------+---------+------------+------------+
| 1 | 0 | 0 | NULL |
+----------+---------+------------+------------+
1 row in set (0.02 sec)
逻辑或运算符
- 逻辑或(OR或||)运算符是当给定的值都不为NULL,并且任何一个值为非0值时,则返 回1,否则返回0;当一个值为NULL,并且另一个值为非0值时,返回1,否则返回NULL;当两个值都为 NULL时,返回NULL。
mysql> SELECT 1 OR -1, 1 OR 0, 1 OR NULL, 0 || NULL, NULL || NULL;
+---------+--------+-----------+-----------+--------------+
| 1 OR -1 | 1 OR 0 | 1 OR NULL | 0 || NULL | NULL || NULL |
+---------+--------+-----------+-----------+--------------+
| 1 | 1 | 1 | NULL | NULL |
+---------+--------+-----------+-----------+--------------+
1 row in set (0.00 sec)
注意:
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
逻辑异或运算符
- 逻辑异或(XOR)运算符是当给定的值中任意一个值为NULL时,则返回NULL;如果 两个非NULL的值都是0或者都不等于0时,则返回0;如果一个值为0,另一个值不为0时,则返回1。
mysql> SELECT 1 XOR -1, 1 XOR 0, 0 XOR 0, 1 XOR NULL, 1 XOR 1 XOR 1, 0 XOR 0 XOR 0;
+----------+---------+---------+------------+---------------+---------------+
| 1 XOR -1 | 1 XOR 0 | 0 XOR 0 | 1 XOR NULL | 1 XOR 1 XOR 1 | 0 XOR 0 XOR 0 |
+----------+---------+---------+------------+---------------+---------------+
| 0 | 1 | 0 | NULL | 1 | 0 |
+----------+---------+---------+------------+---------------+---------------+
1 row in set (0.00 sec)
5. 位运算符
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数。
MySQL支持的位运算符如下:
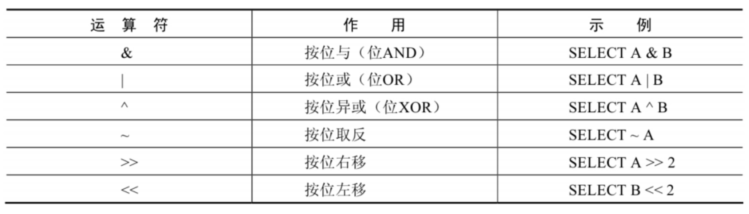
按位与运算符
- 按位与(&)运算符将给定值对应的二进制数逐位进行逻辑与运算。当给定值对应的二 进制位的数值都为1时,则该位返回1,否则返回0。
mysql> SELECT 1 & 10, 20 & 30;
+--------+---------+
| 1 & 10 | 20 & 30 |
+--------+---------+
| 0 | 20 |
+--------+---------+
1 row in set (0.00 sec)
1的二进制数为0001,10的二进制数为1010,所以1 & 10的结果为0000,对应的十进制数为0。20的二进制数为10100,30的二进制数为11110,所以20 & 30的结果为10100,对应的十进制数为20。
按位或运算符
- 按位或(|)运算符将给定的值对应的二进制数逐位进行逻辑或运算。当给定值对应的 二进制位的数值有一个或两个为1时,则该位返回1,否则返回0。
mysql> SELECT 1 | 10, 20 | 30;
+--------+---------+
| 1 | 10 | 20 | 30 |
+--------+---------+
| 11 | 30 |
+--------+---------+
1 row in set (0.00 sec)
按位异或运算符
- 按位异或(^)运算符将给定的值对应的二进制数逐位进行逻辑异或运算。当给定值 对应的二进制位的数值不同时,则该位返回1,否则返回0。
mysql> SELECT 1 ^ 10, 20 ^ 30;
+--------+---------+
| 1 ^ 10 | 20 ^ 30 |
+--------+---------+
| 11 | 10 |
+--------+---------+
1 row in set (0.00 sec)
1的二进制数为0001,10的二进制数为1010,所以1 ^ 10的结果为1011,对应的十进制数为11。20的二进制数为10100,30的二进制数为11110,所以20 ^ 30的结果为01010,对应的十进制数为10。
按位取反运算符
- 按位取反(~)运算符将给定的值的二进制数逐位进行取反操作,即将1变为0,将0变 为1。
mysql> SELECT 10 & ~1;
+---------+
| 10 & ~1 |
+---------+
| 10 |
+---------+
1 row in set (0.00 sec)
由于按位取反(~)运算符的优先级高于按位与(&)运算符的优先级,所以10 & ~1,首先,对数字1进行按位取反操作,结果除了最低位为0,其他位都为1,然后与10进行按位与操作,结果为10。
按位右移运算符
- 按位右移(>>)运算符将给定的值的二进制数的所有位右移指定的位数。右移指定的 位数后,右边低位的数值被移出并丢弃,左边高位空出的位置用0补齐。
mysql> SELECT 1 >> 2, 4 >> 2;
+--------+--------+
| 1 >> 2 | 4 >> 2 |
+--------+--------+
| 0 | 1 |
+--------+--------+
1 row in set (0.00 sec)
1的二进制数为0000 0001,右移2位为0000 0000,对应的十进制数为0。4的二进制数为0000 0100,右移2位为0000 0001,对应的十进制数为1。
按位左移运算符
- 按位左移(<<)运算符将给定的值的二进制数的所有位左移指定的位数。左移指定的 位数后,左边高位的数值被移出并丢弃,右边低位空出的位置用0补齐。
mysql> SELECT 1 << 2, 4 << 2;
+--------+--------+
| 1 << 2 | 4 << 2 |
+--------+--------+
| 4 | 16 |
+--------+--------+
1 row in set (0.00 sec)
1的二进制数为0000 0001,左移两位为0000 0100,对应的十进制数为4。4的二进制数为0000 0100,左移两位为0001 0000,对应的十进制数为16。
6. 运算符的优先级
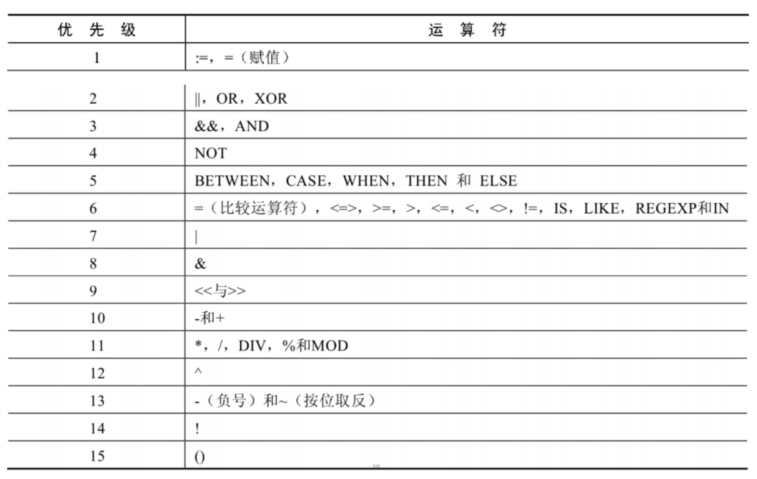 数字编号越大,优先级越高,优先级高的运算符先进行计算。可以看到,赋值运算符的优先级最低,使用“()”括起来的表达式的优先级最高。
数字编号越大,优先级越高,优先级高的运算符先进行计算。可以看到,赋值运算符的优先级最低,使用“()”括起来的表达式的优先级最高。
五、排序与分页
1. 排序
(1)排序规则
- 使用
ORDER BY子句排序
ASC(ascend): 升序
DESC(descend):降序
ORDER BY子句在SELECT语句的结尾。
(2)单列排序
# 按照salary从高到低的顺序显示员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC;
# 如果在ORDER BY 后没有显式指名排序的方式的话,则默认按照升序排列。
# 我们可以使用列的别名,进行排序
# 列的别名只能在 ORDER BY 中使用,不能在WHERE中使用。
SELECT employee_id,salary,salary * 12 annual_sal
FROM employees
ORDER BY annual_sal;
# 强调格式:WHERE 需要声明在FROM后,ORDER BY之前。
SELECT employee_id,salary
FROM employees
WHERE department_id IN (50,60,70)
ORDER BY department_id DESC;
(3)多列排序
# 显示员工信息,按照department_id的降序排列,salary的升序排列
SELECT employee_id,salary,department_id
FROM employees
ORDER BY department_id DESC,salary ASC;
- 可以使用不在SELECT列表中的列排序。
- 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第 一列数据中所有值都是唯一的,将不再对第二列进行排序。
2. 分页
(1)实现规则
- 分页原理
所谓分页显示,就是将数据库中的结果集,一段一段显示出来需要的条件。 - MySQL中使用 LIMIT 实现分页
- 格式
LIMIT [位置偏移量,] 行数
第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移
量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是
1,以此类推);第二个参数“行数”指示返回的记录条数
- 例子
# 前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
或者
SELECT * FROM 表名 LIMIT 10;
# 第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
# 第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
- MySQL 8.0中可以使用
LIMIT 3 OFFSET 4,意思是获取从第5条记录开始后面的3条记录,和LIMIT 4,3返回的结果相同。
-
分页显式公式:
(当前页数-1)* 每页条数,每页条数 -
LIMIT子句必须放在整个SELECT语句的最后
使用 LIMIT 的好处
- 约束返回结果的数量可以 ==减少数据表的网络传输量 ,也可以 提升查询效率 ==。如果我们知道返回结果只有 1 条,就可以使用 LIMIT 1 ,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
(2)拓展
在不同的 DBMS 中使用的关键字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 关键字,而且需要放到 SELECT 语句的最后面。
- 如果是 SQL Server 和 Access,需要使用
TOP关键字
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
六、多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
- 前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
1. 笛卡尔积
(1)笛卡尔积说明
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。
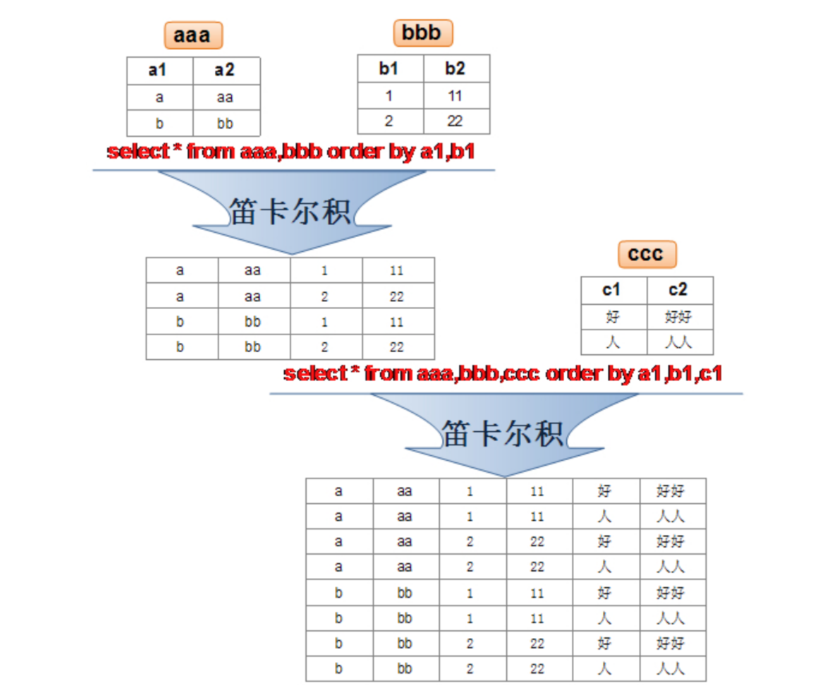
SQL92中,笛卡尔积也称为交叉连接 ,英文是 CROSS JOIN 。在 SQL99 中也是使用 CROSS JOIN表示交叉连接。它的作用就是可以把任意表进行连接,即使这两张表不相关。在MySQL中如下情况会出现笛卡尔积:
#查询员工姓名和所在部门名称
SELECT last_name,department_name FROM employees,departments;
SELECT last_name,department_name FROM employees CROSS JOIN departments;
SELECT last_name,department_name FROM employees INNER JOIN departments;
SELECT last_name,department_name FROM employees JOIN departments;
(2)笛卡尔积的分析与解决方法
笛卡尔积的错误会在下面条件下产生:
- 省略多个表的连接条件(或关联条件)
- 连接条件(或关联条件)无效
- 所有表中的所有行互相连接
为了避免笛卡尔积, 可以在 WHERE 加入有效的连接条件
加入连接条件后,查询语法:
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2; #连接条件
# 查询员工的姓名及其部门名称正确写法
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
在表中有相同列时,在列名之前加上表名前缀。
2. 内连接
语法说明:
- 可以使用 ON 子句指定额外的连接条件。
- 这个连接条件是与其它条件分开的。
- ON 子句使语句具有更高的易读性。
- 关键字 JOIN、INNER JOIN、CROSS JOIN 的含义是一样的,都表示内连接
- 语法
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
- 使用JOIN…ON子句创建连接的语法结构:
SELECT table1.column, table2.column,table3.column
FROM table1
JOIN table2 ON table1 和 table2 的连接条件
JOIN table3 ON table2 和 table3 的连接条件
它的嵌套逻辑类似我们使用的 FOR 循环:
for t1 in table1:
for t2 in table2:
if condition1:
for t3 in table3:
if condition2:
output t1 + t2 + t3
3. 外连接
(1)左外连接(LEFT OUTER JOIN)
- 语法
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
- 举例
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
(2)右外连接(RIGHT OUTER JOIN)
- 语法
#实现查询结果是B
SELECT 字段列表
FROM A表 RIGHT JOIN B表
ON 关联条件
WHERE 等其他子句;
- 举例
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
需要注意的是,LEFT JOIN 和 RIGHT JOIN 只存在于 SQL99 及以后的标准中,在 SQL92 中不存在,只能用 (+) 表示。
(3)满外连接(FULL OUTER JOIN)
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
- 需要注意的是,MySQL不支持FULL JOIN,但是可以用 LEFT JOIN UNION RIGHT join代替。
4. UNION的使用
合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
UNION操作符
- UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符
- UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
举例:
# 查询部门编号 > 90或邮箱包含 a 的员工信息
# 方式1
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
# 方式2
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
# 查询中国用户中男性的信息以及美国用户中年男性的用户信息
SELECT id,cname FROM t_chinamale WHERE csex='男'
UNION ALL
SELECT id,tname FROM t_usmale WHERE tGender='male';
5. 7种SQL JOINS的实现
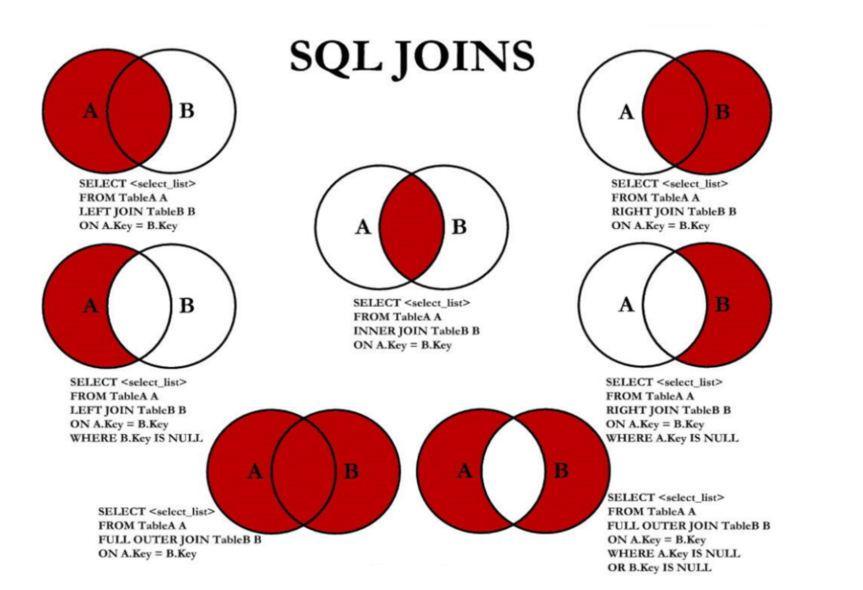
(1)语法格式
- 左中图
# 实现 A - A∩B
select 字段列表
from A表 left join B表
on 关联条件
where B表关联字段 is null and 等其他子句;
- 右中图
#实现 B - A∩B
select 字段列表
from A表 right join B表
on 关联条件
where A表关联字段 is null and 等其他子句;
- 左下图
# 实现查询结果是 A∪B
# 用左外的A,union 右外的B
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;
- 右下图
# 实现 A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B)
# 使用左外的 (A - A∩B) union 右外的(B - A∩B)
select 字段列表
from A表 left join B表
on 关联条件
where B表关联字段 is null and 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where A表关联字段 is null and 等其他子句
(2)代码实现
# 中图:内连接
SELECT employee_id,department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
# 左上图:左外连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id;
# 右上图:右外连接
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;
# 左中图:
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL;
# 右中图:
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
# 左下图:满外连接
# 方式1:左上图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
# 方式2:左中图 UNION ALL 右上图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;
# 右下图:左中图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
WHERE d.department_id IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
WHERE e.department_id IS NULL;
七、单行函数
MySQL提供了丰富的内置函数,这些函数使得数据的维护与管理更加方便,能够更好地提供数据的分析与统计功能,在一定程度上提高了开发人员进行数据分析与统计的效率。
MySQL提供的内置函数从 实现的功能角度可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取MySQL信息函数、聚合函数等。这些丰富的内置函数可分为两类: 单行函数 、 聚合函数(或分组函数) 。
单行函数
操作数据对象
接受参数返回一个结果
只对一行进行变换
每行返回一个结果
可以嵌套
参数可以是一列或一个值
1. 数值函数
(1)基本函数
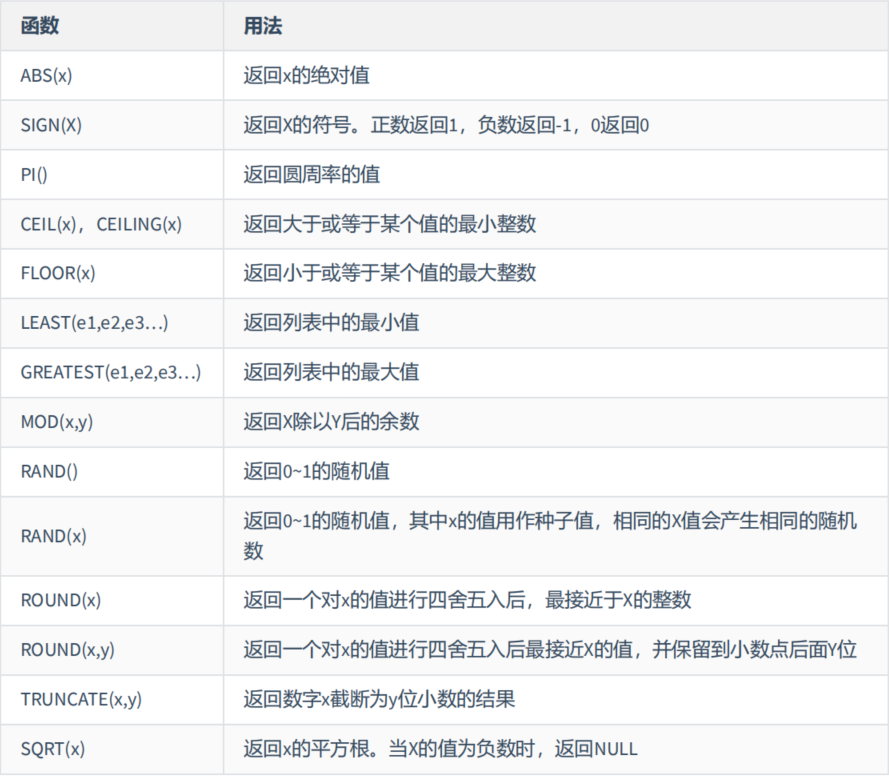
mysql> SELECT
-> ABS(-123),ABS(32),SIGN(-23),SIGN(43),PI(),CEIL(32.32),CEILING(-43.23),FLOOR(32.32),
-> FLOOR(-43.23),MOD(12,5)
-> FROM DUAL;
+-----------+---------+-----------+----------+----------+-------------+-----------------+--------------+---------------+-----------+
| ABS(-123) | ABS(32) | SIGN(-23) | SIGN(43) | PI() | CEIL(32.32) | CEILING(-43.23) | FLOOR(32.32) | FLOOR(-43.23) | MOD(12,5) |
+-----------+---------+-----------+----------+----------+-------------+-----------------+--------------+---------------+-----------+
| 123 | 32 | -1 | 1 | 3.141593 | 33 | -43 | 32 | -44 | 2 |
+-----------+---------+-----------+----------+----------+-------------+-----------------+--------------+---------------+-----------+
1 row in set (0.00 sec)
mysql> SELECT RAND(),RAND(),RAND(10),RAND(10),RAND(-1),RAND(-1)
-> FROM DUAL;
+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+
| RAND() | RAND() | RAND(10) | RAND(10) | RAND(-1) | RAND(-1) |
+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+
| 0.5148304584574238 | 0.5509940325757433 | 0.6570515219653505 | 0.6570515219653505 | 0.9050373219931845 | 0.9050373219931845 |
+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+
1 row in set (0.00 sec)
mysql> SELECT
-> ROUND(12.33),ROUND(12.343,2),ROUND(12.324,-1),TRUNCATE(12.66,1),TRUNCATE(12.66,-1)
-> FROM DUAL;
+--------------+-----------------+------------------+-------------------+--------------------+
| ROUND(12.33) | ROUND(12.343,2) | ROUND(12.324,-1) | TRUNCATE(12.66,1) | TRUNCATE(12.66,-1) |
+--------------+-----------------+------------------+-------------------+--------------------+
| 12 | 12.34 | 10 | 12.6 | 10 |
+--------------+-----------------+------------------+-------------------+--------------------+
1 row in set (0.00 sec)
(2)角度与弧度互换函数

mysql> SELECT RADIANS(30),RADIANS(60),RADIANS(90),DEGREES(2*PI()),DEGREES(RADIANS(90))
-> FROM DUAL;
+--------------------+--------------------+--------------------+-----------------+----------------------+
| RADIANS(30) | RADIANS(60) | RADIANS(90) | DEGREES(2*PI()) | DEGREES(RADIANS(90)) |
+--------------------+--------------------+--------------------+-----------------+----------------------+
| 0.5235987755982988 | 1.0471975511965976 | 1.5707963267948966 | 360 | 90 |
+--------------------+--------------------+--------------------+-----------------+----------------------+
1 row in set (0.00 sec)
(3)三角函数
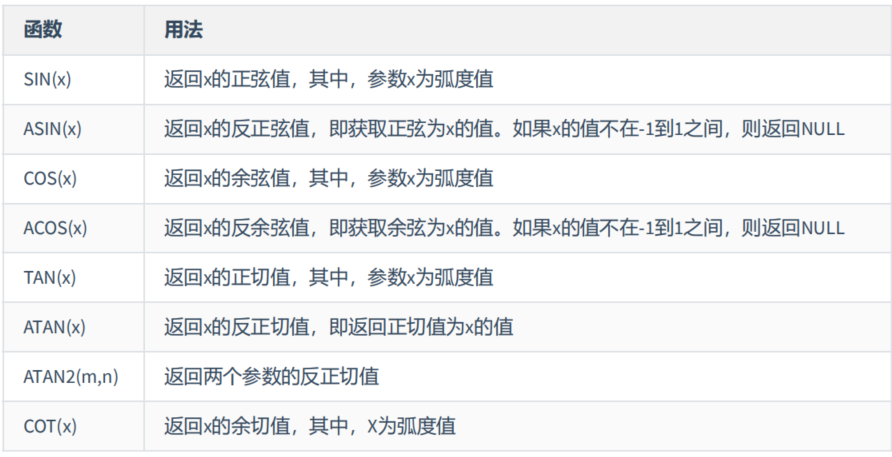
mysql> SELECT
-> SIN(RADIANS(30)),DEGREES(ASIN(1)),TAN(RADIANS(45)),
-> DEGREES(ATAN(1)),DEGREES(ATAN2(1,1))
-> FROM DUAL;
+---------------------+------------------+--------------------+------------------+---------------------+
| SIN(RADIANS(30)) | DEGREES(ASIN(1)) | TAN(RADIANS(45)) | DEGREES(ATAN(1)) | DEGREES(ATAN2(1,1)) |
+---------------------+------------------+--------------------+------------------+---------------------+
| 0.49999999999999994 | 90 | 0.9999999999999999 | 45 | 45 |
+---------------------+------------------+--------------------+------------------+---------------------+
1 row in set (0.09 sec)
(4)指数与对数
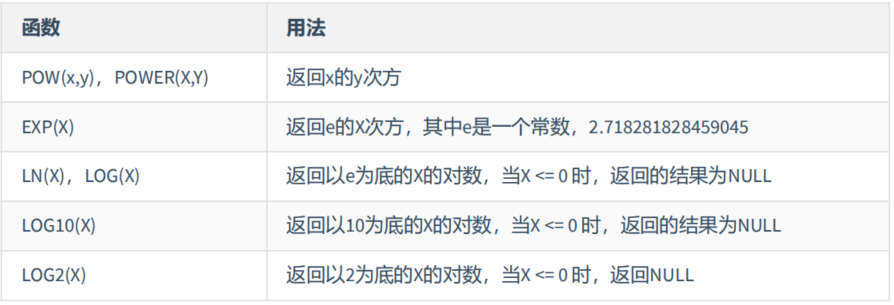
mysql> SELECT POW(2,5),POWER(2,4),EXP(2),LN(10),LOG10(10),LOG2(4)
-> FROM DUAL;
+----------+------------+------------------+-------------------+-----------+---------+
| POW(2,5) | POWER(2,4) | EXP(2) | LN(10) | LOG10(10) | LOG2(4) |
+----------+------------+------------------+-------------------+-----------+---------+
| 32 | 16 | 7.38905609893065 | 2.302585092994046 | 1 | 2 |
+----------+------------+------------------+-------------------+-----------+---------+
1 row in set (0.00 sec)
(5)进制间的转换
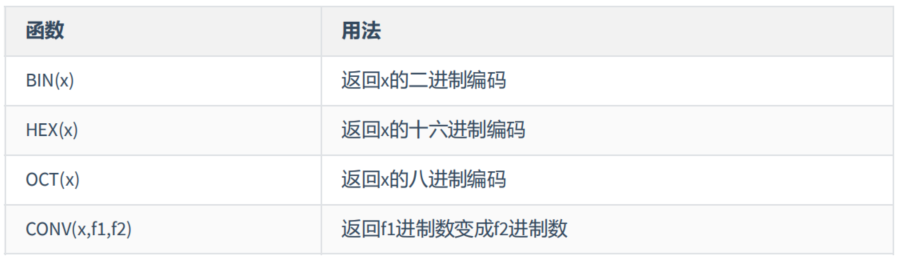
mysql> SELECT BIN(10),HEX(10),OCT(10),CONV(10,2,8)
-> FROM DUAL;
+---------+---------+---------+--------------+
| BIN(10) | HEX(10) | OCT(10) | CONV(10,2,8) |
+---------+---------+---------+--------------+
| 1010 | A | 12 | 2 |
+---------+---------+---------+--------------+
1 row in set (0.00 sec)
2. 字符串函数
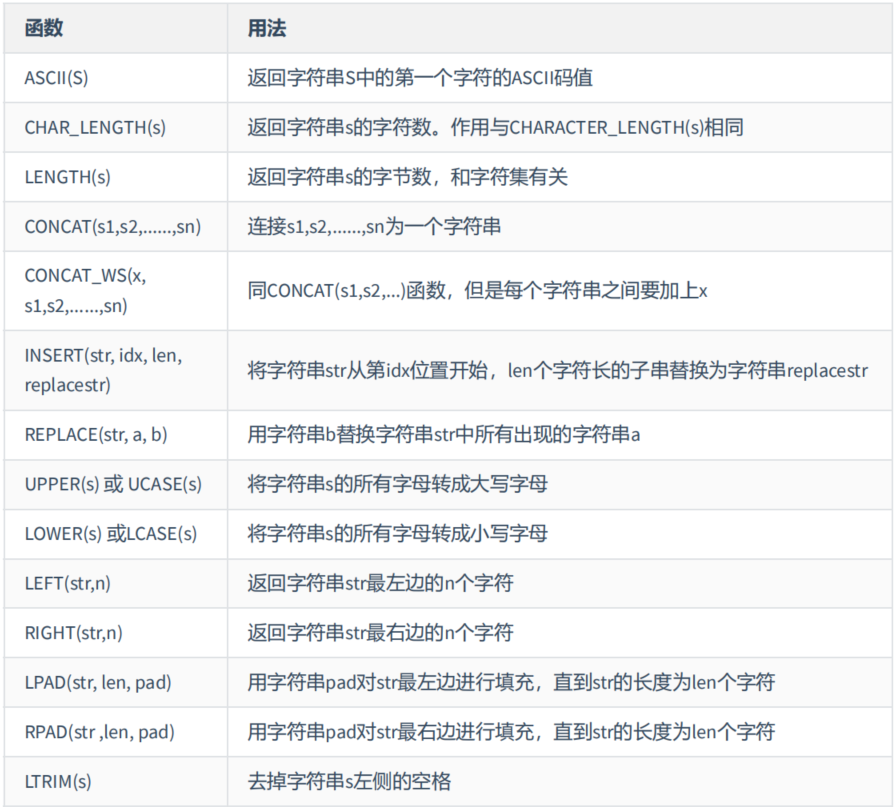
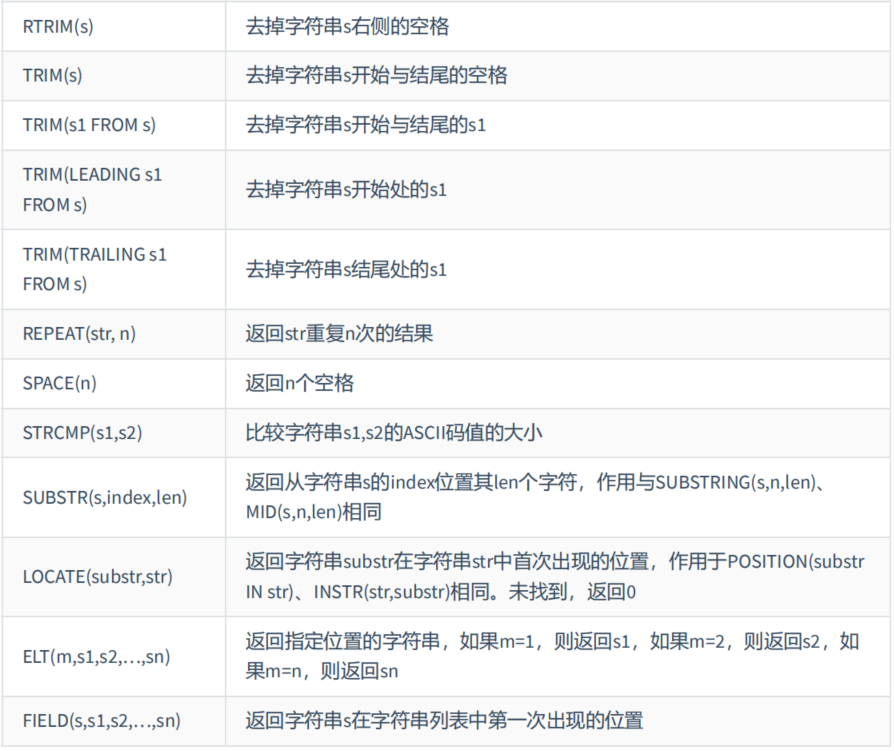

mysql> SELECT ASCII('Abcdfsf') a1,CHAR_LENGTH('hello') a2, CHAR_LENGTH('我们') a3,
-> LENGTH('hello'),LENGTH('我们')
-> FROM DUAL;
+----+----+----+-----------------+----------------+
| a1 | a2 | a3 | LENGTH('hello') | LENGTH('我们') |
+----+----+----+-----------------+----------------+
| 65 | 5 | 2 | 5 | 4 |
+----+----+----+-----------------+----------------+
1 row in set (0.00 sec)
mysql> SELECT CONCAT_WS('-','hello','world','hello','beijing') a1
-> FROM DUAL;
+---------------------------+
| a1 |
+---------------------------+
| hello-world-hello-beijing |
+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT INSERT('helloworld',2,3,'aaaaa') a1, REPLACE('hello','lol','mmm') a2
-> FROM DUAL;
+--------------+-------+
| a1 | a2 |
+--------------+-------+
| haaaaaoworld | hello |
+--------------+-------+
1 row in set (0.00 sec)
mysql> SELECT UPPER('HelLo') a1, LOWER('HelLo') a2
-> FROM DUAL;
+-------+-------+
| a1 | a2 |
+-------+-------+
| HELLO | hello |
+-------+-------+
1 row in set (0.00 sec)
mysql> SELECT LEFT('hello',2) a1, RIGHT('hello',3) a2, RIGHT('hello',13) a3
-> FROM DUAL;
+------+------+-------+
| a1 | a2 | a3 |
+------+------+-------+
| he | llo | hello |
+------+------+-------+
1 row in set (0.00 sec)
mysql> SELECT CONCAT('---',LTRIM(' h el lo '),'***') a1,
-> TRIM('oo' FROM 'ooheollo') a2
-> FROM DUAL;
+--------------------+--------+
| a1 | a2 |
+--------------------+--------+
| ---h el lo *** | heollo |
+--------------------+--------+
1 row in set (0.00 sec)
mysql> SELECT REPEAT('hello',4) a1, LENGTH(SPACE(5)),STRCMP('abc','abe') a2
-> FROM DUAL;
+----------------------+------------------+----+
| a1 | LENGTH(SPACE(5)) | a2 |
+----------------------+------------------+----+
| hellohellohellohello | 5 | -1 |
+----------------------+------------------+----+
1 row in set (0.00 sec)
mysql> SELECT SUBSTR('hello',2,2) a1, LOCATE('lll','hello') a2
-> FROM DUAL;
+------+----+
| a1 | a2 |
+------+----+
| el | 0 |
+------+----+
1 row in set (0.00 sec)
mysql> SELECT ELT(2,'a','b','c','d') a1, FIELD('mm','gg','jj','mm','dd','mm') a2,
-> FIND_IN_SET('mm','gg,mm,jj,dd,mm,gg') a3
-> FROM DUAL;
+------+----+----+
| a1 | a2 | a3 |
+------+----+----+
| b | 3 | 2 |
+------+----+----+
1 row in set (0.00 sec)
3. 日期和时间函数
(1)获取日期、时间
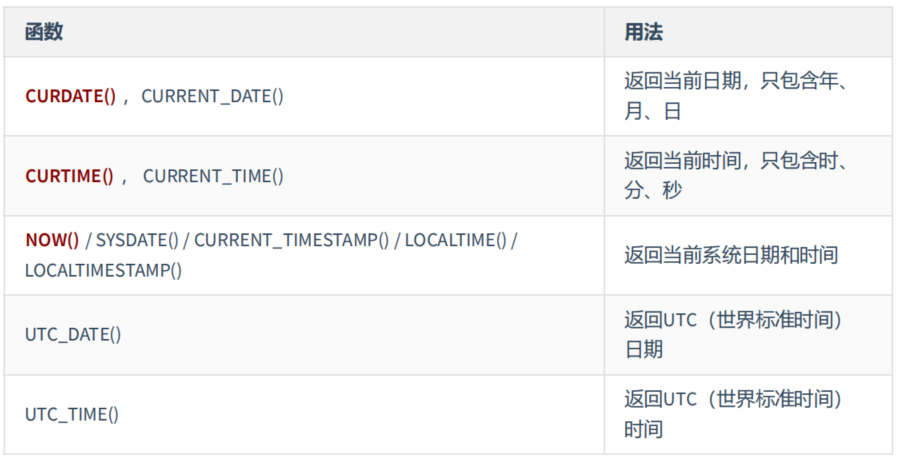
mysql> # 获取日期、时间
mysql> SELECT CURDATE(),CURRENT_DATE(),CURTIME(),NOW(),SYSDATE(),
-> UTC_DATE(),UTC_TIME()
-> FROM DUAL;
+------------+----------------+-----------+---------------------+---------------------+------------+------------+
| CURDATE() | CURRENT_DATE() | CURTIME() | NOW() | SYSDATE() | UTC_DATE() | UTC_TIME() |
+------------+----------------+-----------+---------------------+---------------------+------------+------------+
| 2022-10-19 | 2022-10-19 | 21:33:07 | 2022-10-19 21:33:07 | 2022-10-19 21:33:07 | 2022-10-19 | 13:33:07 |
+------------+----------------+-----------+---------------------+---------------------+------------+------------+
1 row in set (0.00 sec)
mysql> SELECT CURDATE(),CURDATE() + 0,CURTIME() + 0,NOW() + 0
-> FROM DUAL;
+------------+---------------+---------------+----------------+
| CURDATE() | CURDATE() + 0 | CURTIME() + 0 | NOW() + 0 |
+------------+---------------+---------------+----------------+
| 2022-10-19 | 20221019 | 213310 | 20221019213310 |
+------------+---------------+---------------+----------------+
1 row in set (0.00 sec)
(2)日期与时间戳的转换
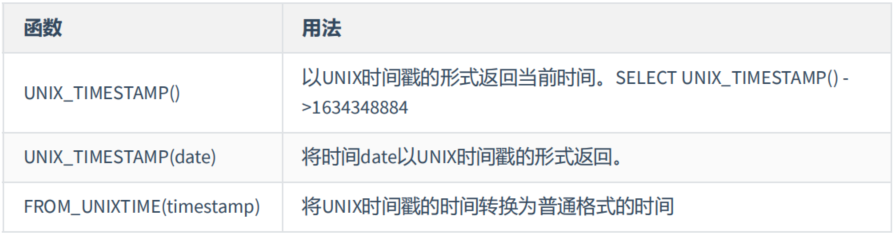
mysql> # 日期与时间戳的转换
mysql> SELECT UNIX_TIMESTAMP(now());
+-----------------------+
| UNIX_TIMESTAMP(now()) |
+-----------------------+
| 1576380910 |
+-----------------------+
1 row in set (0.01 sec)
mysql> SELECT UNIX_TIMESTAMP(CURDATE());
+---------------------------+
| UNIX_TIMESTAMP(CURDATE()) |
+---------------------------+
| 1576339200 |
+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT UNIX_TIMESTAMP(CURTIME());
+---------------------------+
| UNIX_TIMESTAMP(CURTIME()) |
+---------------------------+
| 1576380969 |
+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT UNIX_TIMESTAMP('2011-11-11 11:11:11')
+---------------------------------------+
| UNIX_TIMESTAMP('2011-11-11 11:11:11') |
+---------------------------------------+
| 1320981071 |
+---------------------------------------+
1 row in set (0.00 sec)
(3)获取月份、星期、星期数、天数等
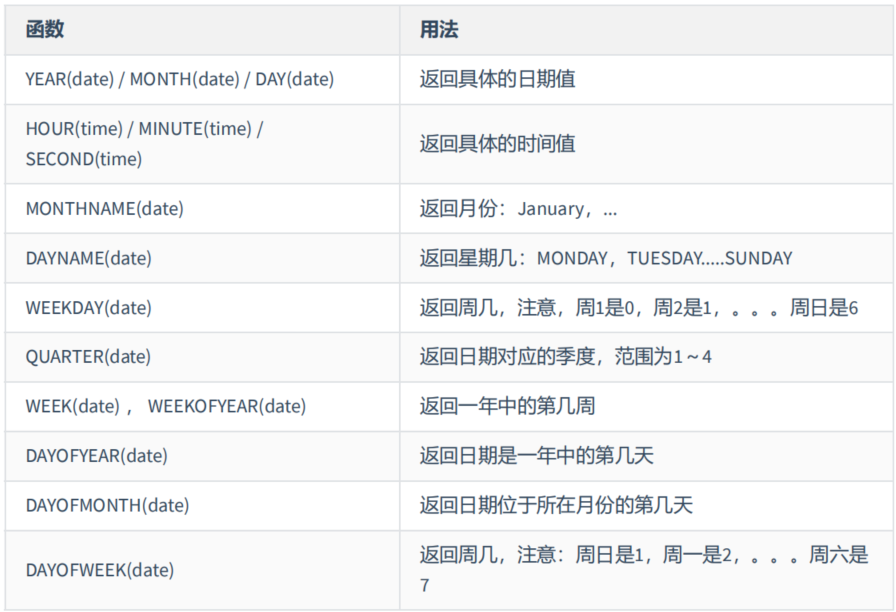
mysql> # 获取月份、星期、星期数、天数等函数
mysql> SELECT YEAR(CURDATE()),MONTH(CURDATE()),DAY(CURDATE()),
-> HOUR(CURTIME()),MINUTE(NOW()),SECOND(SYSDATE())
-> FROM DUAL;
+-----------------+------------------+----------------+-----------------+---------------+-------------------+
| YEAR(CURDATE()) | MONTH(CURDATE()) | DAY(CURDATE()) | HOUR(CURTIME()) | MINUTE(NOW()) | SECOND(SYSDATE()) |
+-----------------+------------------+----------------+-----------------+---------------+-------------------+
| 2022 | 10 | 19 | 21 | 37 | 16 |
+-----------------+------------------+----------------+-----------------+---------------+-------------------+
1 row in set (0.32 sec)
mysql> SELECT MONTHNAME('2021-10-26'),DAYNAME('2021-10-26'),WEEKDAY('2021-10-26'),
-> QUARTER(CURDATE()),WEEK(CURDATE()),DAYOFYEAR(NOW()),
-> DAYOFMONTH(NOW()),DAYOFWEEK(NOW())
-> FROM DUAL;
+-------------------------+-----------------------+-----------------------+--------------------+-----------------+------------------+-------------------+------------------+
| MONTHNAME('2021-10-26') | DAYNAME('2021-10-26') | WEEKDAY('2021-10-26') | QUARTER(CURDATE()) | WEEK(CURDATE()) | DAYOFYEAR(NOW()) | DAYOFMONTH(NOW()) | DAYOFWEEK(NOW()) |
+-------------------------+-----------------------+-----------------------+--------------------+-----------------+------------------+-------------------+------------------+
| October | Tuesday | 1 | 4 | 42 | 292 |
19 | 4 |
+-------------------------+-----------------------+-----------------------+--------------------+-----------------+------------------+-------------------+------------------+
1 row in set (0.11 sec)
(4)日期的操作函数

EXTRACT(type FROM date)函数中type的取值与含义
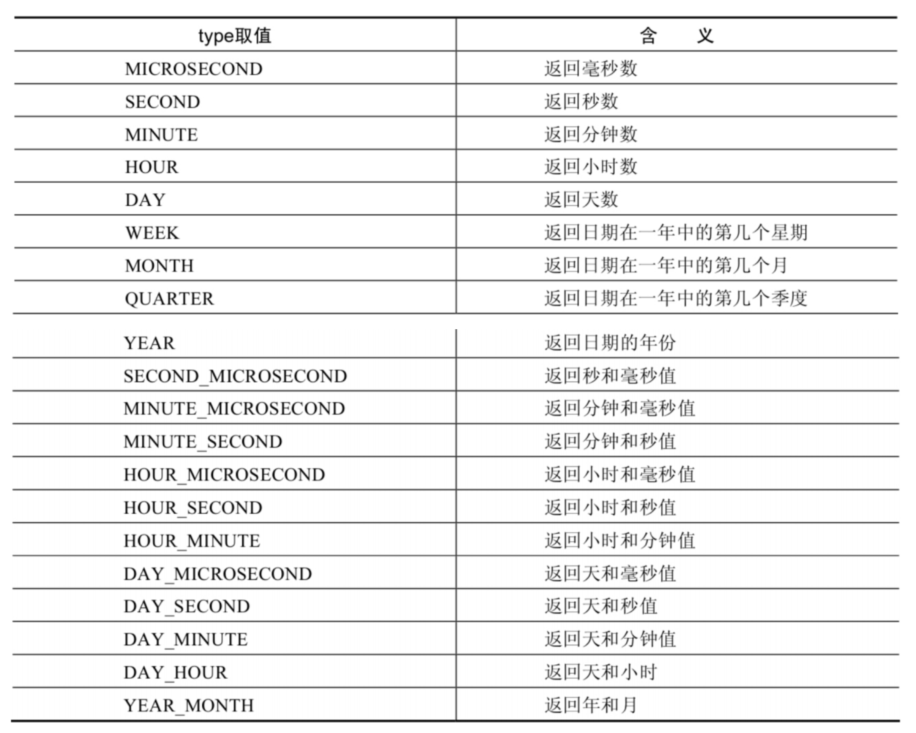
mysql> # 日期的操作函数
mysql> SELECT EXTRACT(SECOND FROM NOW()),EXTRACT(DAY FROM NOW()),
-> EXTRACT(HOUR_MINUTE FROM NOW()),EXTRACT(QUARTER FROM '2021-05-12')
-> FROM DUAL;
+----------------------------+-------------------------+---------------------------------+------------------------------------+
| EXTRACT(SECOND FROM NOW()) | EXTRACT(DAY FROM NOW()) | EXTRACT(HOUR_MINUTE FROM NOW()) | EXTRACT(QUARTER FROM '2021-05-12') |
+----------------------------+-------------------------+---------------------------------+------------------------------------+
| 12 | 19 | 2138 | 2 |
+----------------------------+-------------------------+---------------------------------+------------------------------------+
1 row in set (0.00 sec)
(5)时间和秒钟转换的函数
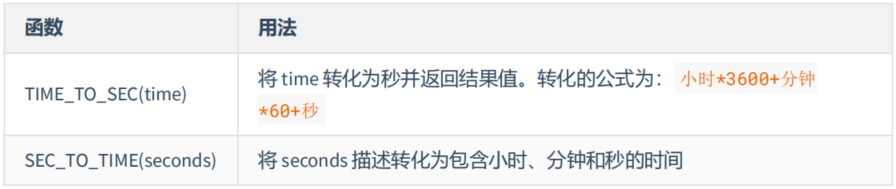
mysql> # 时间和秒钟转换的函数
mysql> SELECT TIME_TO_SEC(CURTIME()),
-> SEC_TO_TIME(83355)
-> FROM DUAL;
+------------------------+--------------------+
| TIME_TO_SEC(CURTIME()) | SEC_TO_TIME(83355) |
+------------------------+--------------------+
| 77951 | 23:09:15 |
+------------------------+--------------------+
1 row in set (0.00 sec)
(6)计算日期和时间的函数
第1组:
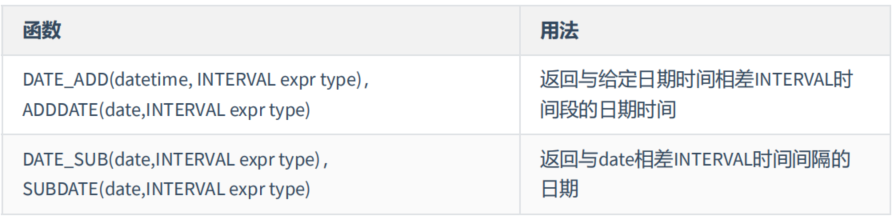
上述函数中type的取值:
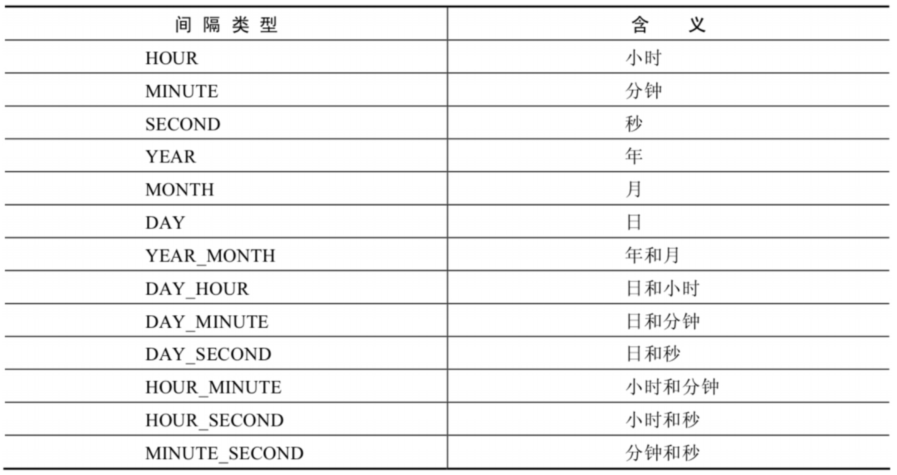
第2组:
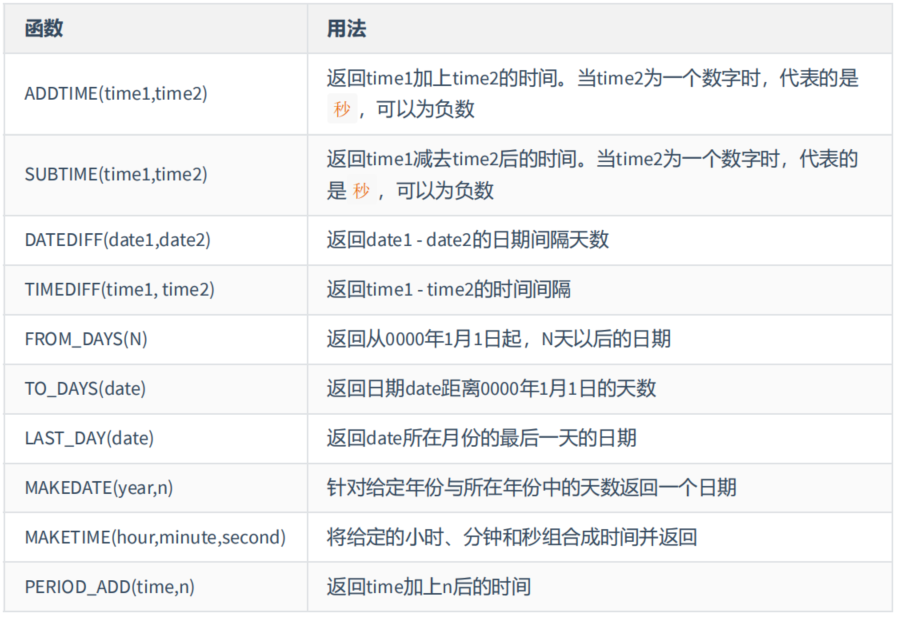
mysql> # 计算日期和时间的函数
mysql> SELECT NOW(),DATE_ADD(NOW(),INTERVAL 1 YEAR),
-> DATE_ADD(NOW(),INTERVAL -1 YEAR),
-> DATE_SUB(NOW(),INTERVAL 1 YEAR)
-> FROM DUAL;
+---------------------+---------------------------------+----------------------------------+---------------------------------+
| NOW() | DATE_ADD(NOW(),INTERVAL 1 YEAR) | DATE_ADD(NOW(),INTERVAL -1 YEAR) | DATE_SUB(NOW(),INTERVAL 1 YEAR) |
+---------------------+---------------------------------+----------------------------------+---------------------------------+
| 2022-10-19 21:41:55 | 2023-10-19 21:41:55 | 2021-10-19 21:41:55 | 2021-10-19 21:41:55 |
+---------------------+---------------------------------+----------------------------------+---------------------------------+
1 row in set (2.02 sec)
mysql> SELECT DATE_ADD(NOW(), INTERVAL 1 DAY) AS col1,DATE_ADD('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col2,
-> ADDDATE('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col3,
-> DATE_ADD('2021-10-21 23:32:12',INTERVAL '1_1' MINUTE_SECOND) AS col4,
-> DATE_ADD(NOW(), INTERVAL -1 YEAR) AS col5, #可以是负数
-> DATE_ADD(NOW(), INTERVAL '1_1' YEAR_MONTH) AS col6 #需要单引号
-> FROM DUAL;
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
| col1 | col2 | col3 | col4 | col5 | col6 |
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
| 2022-10-20 21:41:57 | 2021-10-21 23:32:13 | 2021-10-21 23:32:13 | 2021-10-21 23:33:13 | 2021-10-19 21:41:57 | 2023-11-19 21:41:57 |
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
1 row in set (0.00 sec)
mysql> SELECT ADDTIME(NOW(),20),SUBTIME(NOW(),30),SUBTIME(NOW(),'1:1:3'),DATEDIFF(NOW(),'2021-10-01'),
-> TIMEDIFF(NOW(),'2021-10-25 22:10:10'),FROM_DAYS(366),TO_DAYS('0000-12-25'),
-> LAST_DAY(NOW()),MAKEDATE(YEAR(NOW()),32),MAKETIME(10,21,23),PERIOD_ADD(20200101010101,10)
-> FROM DUAL;
+---------------------+---------------------+------------------------+------------------------------+---------------------------------------+----------------+-----------------------+-----------------+--------------------------+--------------------+-------------------------------+
| ADDTIME(NOW(),20) | SUBTIME(NOW(),30) | SUBTIME(NOW(),'1:1:3') | DATEDIFF(NOW(),'2021-10-01') | TIMEDIFF(NOW(),'2021-10-25 22:10:10') | FROM_DAYS(366) | TO_DAYS('0000-12-25') | LAST_DAY(NOW()) | MAKEDATE(YEAR(NOW()),32) | MAKETIME(10,21,23) | PERIOD_ADD(20200101010101,10) |
+---------------------+---------------------+------------------------+------------------------------+---------------------------------------+----------------+-----------------------+-----------------+--------------------------+--------------------+-------------------------------+
| 2022-10-19 21:42:17 | 2022-10-19 21:41:27 | 2022-10-19 20:40:54 | 383 | 838:59:59 | 0001-01-01 | 359 | 2022-10-31 | 2022-02-01 | 10:21:23 | 869817111 |
+---------------------+---------------------+------------------------+------------------------------+---------------------------------------+----------------+-----------------------+-----------------+--------------------------+--------------------+-------------------------------+
1 row in set, 1 warning (0.00 sec)
(7)日期的格式化与解析
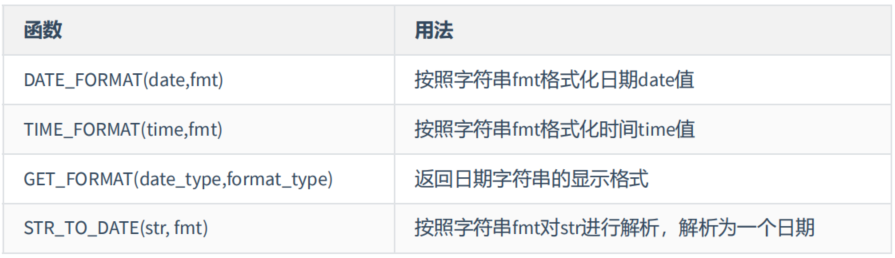
上述除了GET_FORMAT 函数中fmt参数常用的格式符:
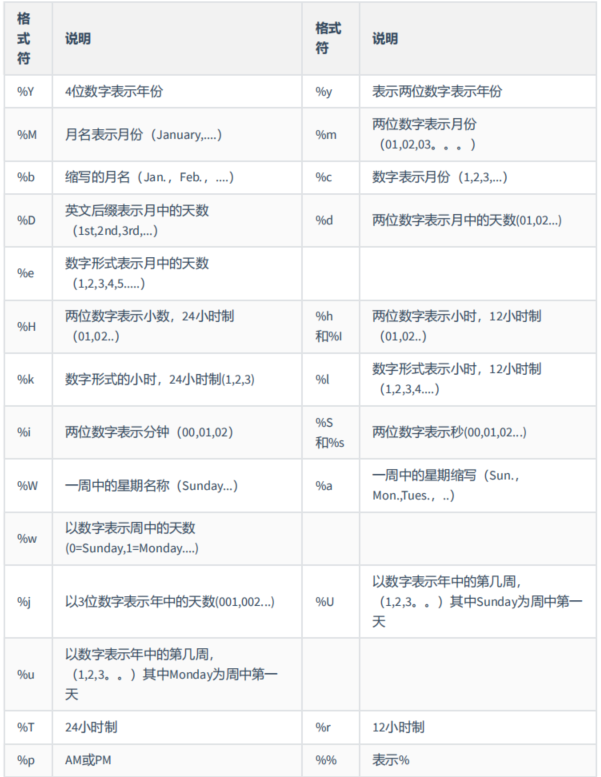
GET_FORMAT函数中date_type和format_type参数取值如下:
mysql> # 日期的格式化与解析
mysql> # 格式化:日期 ---> 字符串
mysql> # 解析: 字符串 ----> 日期
mysql> # 此时我们谈的是日期的显式格式化和解析
mysql>
mysql> # 格式化:
mysql> SELECT DATE_FORMAT(CURDATE(),'%Y-%M-%D'),
-> DATE_FORMAT(NOW(),'%Y-%m-%d'),TIME_FORMAT(CURTIME(),'%h:%i:%S'),
-> DATE_FORMAT(NOW(),'%Y-%M-%D %h:%i:%S %W %w %T %r')
-> FROM DUAL;
+-----------------------------------+-------------------------------+-----------------------------------+-------------------------------------------------------------+
| DATE_FORMAT(CURDATE(),'%Y-%M-%D') | DATE_FORMAT(NOW(),'%Y-%m-%d') | TIME_FORMAT(CURTIME(),'%h:%i:%S') | DATE_FORMAT(NOW(),'%Y-%M-%D %h:%i:%S %W %w %T %r') |
+-----------------------------------+-------------------------------+-----------------------------------+-------------------------------------------------------------+
| 2022-October-19th | 2022-10-19 | 09:47:03 | 2022-October-19th 09:47:03 Wednesday 3 21:47:03 09:47:03 PM |
+-----------------------------------+-------------------------------+-----------------------------------+-------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> # 解析:格式化的逆过程
mysql> SELECT STR_TO_DATE('2021-October-25th 11:37:30 Monday 1','%Y-%M-%D %h:%i:%S %W %w')
-> FROM DUAL;
+------------------------------------------------------------------------------+
| STR_TO_DATE('2021-October-25th 11:37:30 Monday 1','%Y-%M-%D %h:%i:%S %W %w') |
+------------------------------------------------------------------------------+
| 2021-10-25 11:37:30 |
+------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT GET_FORMAT(DATE,'USA')
-> FROM DUAL;
+------------------------+
| GET_FORMAT(DATE,'USA') |
+------------------------+
| %m.%d.%Y |
+------------------------+
1 row in set (0.00 sec)
mysql> SELECT DATE_FORMAT(CURDATE(),GET_FORMAT(DATE,'USA'))
-> FROM DUAL;
+-----------------------------------------------+
| DATE_FORMAT(CURDATE(),GET_FORMAT(DATE,'USA')) |
+-----------------------------------------------+
| 10.19.2022 |
+-----------------------------------------------+
1 row in set (0.00 sec)
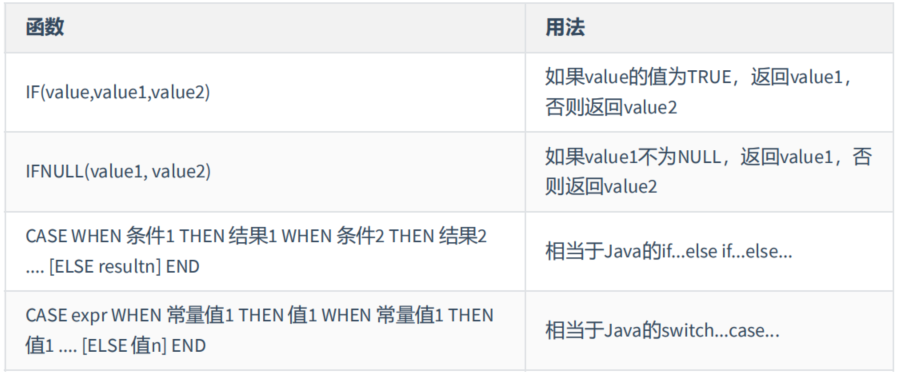
4. 流程控制函数
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数。
mysql> SELECT IF(1 > 0,'正确','错误');
+-------------------------+
| IF(1 > 0,'正确','错误') |
+-------------------------+
| 正确 |
+-------------------------+
1 row in set (0.30 sec)
mysql> SELECT IFNULL(null,'Hello Word');
+---------------------------+
| IFNULL(null,'Hello Word') |
+---------------------------+
| Hello Word |
+---------------------------+
1 row in set (0.00 sec)
mysql> SELECT CASE
-> WHEN 1 > 0 THEN 'hello 1'
-> WHEN 2 > 0 THEN 'hello 2'
-> ELSE 'hello 3'
-> END as myCase;
+---------+
| myCase |
+---------+
| hello 1 |
+---------+
1 row in set (0.00 sec)
mysql> SELECT CASE 1
-> WHEN 1 THEN '我是1'
-> WHEN 2 THEN '我是2'
-> ELSE '你是谁'
-> END myCase;
+--------+
| myCase |
+--------+
| 我是1 |
+--------+
1 row in set (0.00 sec)
5. 加密与解密函数
加密与解密函数主要用于对数据库中的数据进行加密和解密处理,以防止数据被他人窃取。这些函数在保证数据库安全时非常有用。
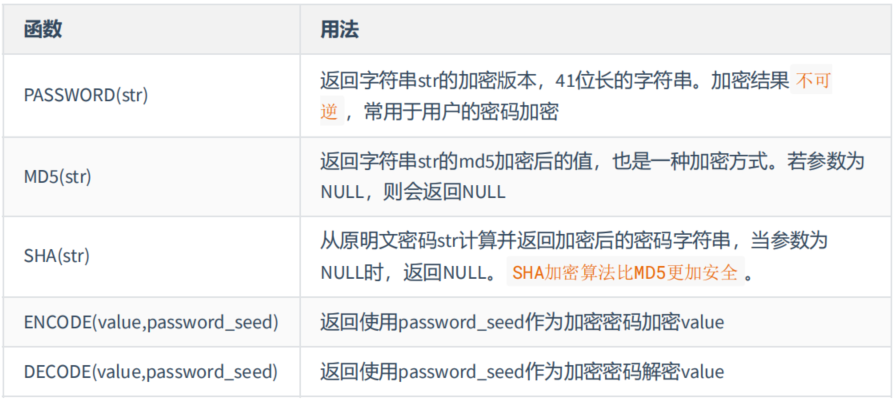
可以发现,ENCODE(value,password_seed)函数与DECODE(value,password_seed)函数互为反函数。
mysql> # 加密与解密的函数
mysql> # PASSWORD()在mysql8.0中弃用。
mysql> SELECT MD5('mysql'),SHA('mysql'),MD5(MD5('mysql'))
-> FROM DUAL;
+----------------------------------+------------------------------------------+----------------------------------+
| MD5('mysql') | SHA('mysql') | MD5(MD5('mysql')) |
+----------------------------------+------------------------------------------+----------------------------------+
| 81c3b080dad537de7e10e0987a4bf52e | f460c882a18c1304d88854e902e11b85d71e7e1b | 9b1c95c962f12d84f57c68e694274783 |
+----------------------------------+------------------------------------------+----------------------------------+
1 row in set (0.00 sec)
mysql> # ENCODE() \ DECODE() 在mysql8.0中弃用。
mysql> SELECT ENCODE('TYT','1'), DECODE(ENCODE('TYT','1'),'1')
-> FROM DUAL;
+-------------------+-------------------------------+
| ENCODE('TYT','1') | DECODE(ENCODE('TYT','1'),'1') |
+-------------------+-------------------------------+
| 肰 | TYT |
+-------------------+-------------------------------+
1 row in set, 3 warnings (0.00 sec)
6. MySQL信息函数
MySQL中内置了一些可以查询MySQL信息的函数,这些函数主要用于帮助数据库开发或运维人员更好地对数据库进行维护工作。
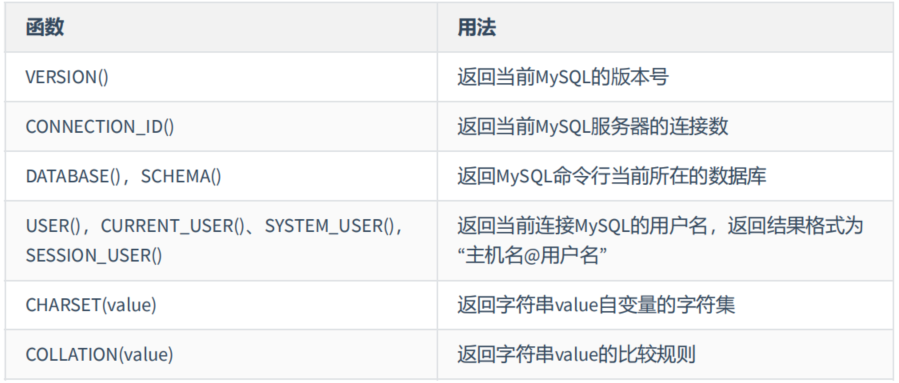
mysql> # MySQL信息函数
mysql> SELECT VERSION(),CONNECTION_ID(),DATABASE(),SCHEMA(),
-> USER(),CURRENT_USER(),CHARSET('划水艺术家'),COLLATION('划水艺术家')
-> FROM DUAL;
+------------+-----------------+------------+----------+--------+-----------------------------------+-----------------------+-------------------------+
| VERSION() | CONNECTION_ID() | DATABASE() | SCHEMA() | USER() | CURRENT_USER() | CHARSET('划水艺术家') | COLLATION('划水艺术家') |
+------------+-----------------+------------+----------+--------+-----------------------------------+-----------------------+-------------------------+
| 5.7.36-log | 14 | NULL | NULL | rooot@ | skip-grants user@skip-grants host | gbk | gbk_chinese_ci |
+------------+-----------------+------------+----------+--------+-----------------------------------+-----------------------+-------------------------+
1 row in set (0.00 sec)
7. 其他函数
MySQL中有些函数无法对其进行具体的分类,但是这些函数在MySQL的开发和运维过程中也是不容忽视的。
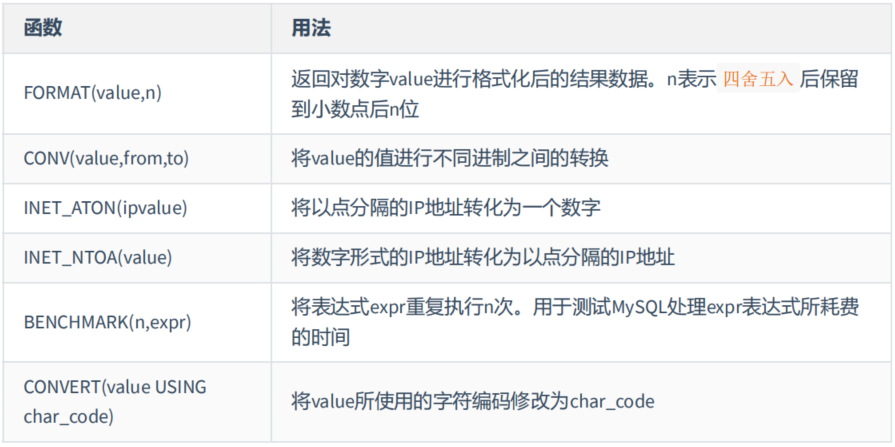
mysql> # 其他函数
mysql> # 如果n的值小于或者等于0,则只保留整数部分
mysql> SELECT FORMAT(123.125, 2),FORMAT(123.125, 0),FORMAT(123.125, -2)
-> FROM DUAL;
+--------------------+--------------------+---------------------+
| FORMAT(123.125, 2) | FORMAT(123.125, 0) | FORMAT(123.125, -2) |
+--------------------+--------------------+---------------------+
| 123.13 | 123 | 123 |
+--------------------+--------------------+---------------------+
1 row in set (0.00 sec)
mysql> SELECT CONV(16, 10, 2), CONV(8888,10,16), CONV(NULL, 10, 2)
-> FROM DUAL;
+-----------------+------------------+-------------------+
| CONV(16, 10, 2) | CONV(8888,10,16) | CONV(NULL, 10, 2) |
+-----------------+------------------+-------------------+
| 10000 | 22B8 | NULL |
+-----------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql> # 以“192.168.1.100”为例,计算方式为192乘以256的3次方,加上168乘以256的2次方,加上1乘以256,再加上100。
mysql> SELECT INET_ATON('192.168.1.100'),INET_NTOA(3232235876)
-> FROM DUAL;
+----------------------------+-----------------------+
| INET_ATON('192.168.1.100') | INET_NTOA(3232235876) |
+----------------------------+-----------------------+
| 3232235876 | 192.168.1.100 |
+----------------------------+-----------------------+
1 row in set (0.00 sec)
mysql>
mysql> # BENCHMARK()用于测试表达式的执行效率
mysql> SELECT BENCHMARK(100000,MD5('mysql'))
-> FROM DUAL;
+--------------------------------+
| BENCHMARK(100000,MD5('mysql')) |
+--------------------------------+
| 0 |
+--------------------------------+
1 row in set (0.02 sec)
mysql> # CONVERT():可以实现字符集的转换
mysql> SELECT CHARSET('atguigu'),CHARSET(CONVERT('atguigu' USING 'gbk'))
-> FROM DUAL;
+--------------------+-----------------------------------------+
| CHARSET('atguigu') | CHARSET(CONVERT('atguigu' USING 'gbk')) |
+--------------------+-----------------------------------------+
| gbk | gbk |
+--------------------+-----------------------------------------+
1 row in set (0.04 sec)
八、聚合函数
1. 聚合函数介绍
- 什么是聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
- 聚合函数类型
AVG()
SUM()
MAX()
MIN()
COUNT()
- 聚合函数语法
- 聚合函数不能嵌套调用。比如不能出现类似
AVG(SUM(字段名称))形式的调用。
(1)AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数。
mysql> SELECT AVG(salary),SUM(salary),AVG(salary) * COUNT(*)
-> FROM employees;
+-------------+-------------+------------------------+
| AVG(salary) | SUM(salary) | AVG(salary) * COUNT(*) |
+-------------+-------------+------------------------+
| 6461.682243 | 691400.00 | 691400.000000 |
+-------------+-------------+------------------------+
1 row in set (0.00 sec)
mysql> # 如下的操作没有意义
mysql> SELECT SUM(last_name),AVG(last_name),SUM(hire_date)
-> FROM employees;
+----------------+----------------+----------------+
| SUM(last_name) | AVG(last_name) | SUM(hire_date) |
+----------------+----------------+----------------+
| 0 | 0 | 2136929701 |
+----------------+----------------+----------------+
1 row in set, 214 warnings (0.00 sec)
(2)MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
mysql> # MAX / MIN :适用于数值类型、字符串类型、日期时间类型的字段(或变量)
mysql> SELECT MAX(salary),MIN(salary)
-> FROM employees;
+-------------+-------------+
| MAX(salary) | MIN(salary) |
+-------------+-------------+
| 24000.00 | 2100.00 |
+-------------+-------------+
1 row in set (0.00 sec)
mysql> SELECT MAX(last_name),MIN(last_name),MAX(hire_date),MIN(hire_date)
-> FROM employees;
+----------------+----------------+----------------+----------------+
| MAX(last_name) | MIN(last_name) | MAX(hire_date) | MIN(hire_date) |
+----------------+----------------+----------------+----------------+
| Zlotkey | Abel | 2000-04-21 | 1987-06-17 |
+----------------+----------------+----------------+----------------+
1 row in set (0.00 sec)
(3)COUNT函数
COUNT(*)返回表中记录总数,适用于任意数据类型。COUNT(expr)返回expr不为空的记录总数。
mysql> # 计算指定字段在查询结构中出现的个数(不包含NULL值的)
mysql> SELECT COUNT(employee_id),COUNT(salary),COUNT(2 * salary),COUNT(1),COUNT(2),COUNT(*)
-> FROM employees ;
+--------------------+---------------+-------------------+----------+----------+----------+
| COUNT(employee_id) | COUNT(salary) | COUNT(2 * salary) | COUNT(1) | COUNT(2) | COUNT(*) |
+--------------------+---------------+-------------------+----------+----------+----------+
| 107 | 107 | 107 | 107 | 107 | 107 |
+--------------------+---------------+-------------------+----------+----------+----------+
1 row in set (0.00 sec)
mysql> # 如果计算表中有多少条记录,如何实现?
mysql> # 方式1:COUNT(*)
mysql> # 方式2:COUNT(1)
mysql> # 方式3:COUNT(具体字段) : 不一定对!
mysql>
mysql> # 注意:计算指定字段出现的个数时,是不计算NULL值的。
mysql> SELECT count(*)
-> FROM employees
-> WHERE commission_pct IS NOT NULL;
+----------+
| count(*) |
+----------+
| 35 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT COUNT(commission_pct)
-> FROM employees;
+-----------------------+
| COUNT(commission_pct) |
+-----------------------+
| 35 |
+-----------------------+
1 row in set (0.00 sec)
mysql> # AVG = SUM / COUNT
mysql> SELECT AVG(salary), SUM(salary)/COUNT(salary),
-> AVG(commission_pct),SUM(commission_pct)/COUNT(commission_pct),
-> SUM(commission_pct)/COUNT(*)
-> FROM employees;
+-------------+---------------------------+---------------------+-------------------------------------------+------------------------------+
| AVG(salary) | SUM(salary)/COUNT(salary) | AVG(commission_pct) | SUM(commission_pct)/COUNT(commission_pct) | SUM(commission_pct)/COUNT(*) |
+-------------+---------------------------+---------------------+-------------------------------------------+------------------------------+
| 6461.682243 | 6461.682243 | 0.222857 | 0.222857 | 0.072897 |
+-------------+---------------------------+---------------------+-------------------------------------------+------------------------------+
1 row in set (0.00 sec)
mysql> # 需求:查询公司中平均奖金率
mysql> # 错误的!
mysql> SELECT AVG(commission_pct)
-> FROM employees;
+---------------------+
| AVG(commission_pct) |
+---------------------+
| 0.222857 |
+---------------------+
1 row in set (0.00 sec)
mysql> # 正确的:
mysql> SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct,0)),
-> AVG(IFNULL(commission_pct,0))
-> FROM employees;
+-------------------------------------------------------+-------------------------------+
| SUM(commission_pct) / COUNT(IFNULL(commission_pct,0)) | AVG(IFNULL(commission_pct,0)) |
+-------------------------------------------------------+-------------------------------+
| 0.072897 | 0.072897 |
+-------------------------------------------------------+-------------------------------+
1 row in set (0.00 sec)
- 如何需要统计表中的记录数,使用COUNT(*)、COUNT(1)、COUNT(具体字段) 哪个效率更高呢?
- 如果使用的是
MyISAM存储引擎,则三者效率相同,都是O(1)- 如果使用的是
InnoDB存储引擎,则三者效率:COUNT(*) = COUNT(1) > COUNT(字段)
2. GROUP BY
(1)基本使用
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
# 明确:WHERE一定放在FROM后面
mysql> # 需求:查询各个部门的平均工资,最高工资
mysql> SELECT department_id, AVG(salary), SUM(salary)
-> FROM employees
-> GROUP BY department_id;
+---------------+--------------+-------------+
| department_id | AVG(salary) | SUM(salary) |
+---------------+--------------+-------------+
| NULL | 7000.000000 | 7000.00 |
| 10 | 4400.000000 | 4400.00 |
| 20 | 9500.000000 | 19000.00 |
| 30 | 4150.000000 | 24900.00 |
| 40 | 6500.000000 | 6500.00 |
| 50 | 3475.555556 | 156400.00 |
| 60 | 5760.000000 | 28800.00 |
| 70 | 10000.000000 | 10000.00 |
| 80 | 8955.882353 | 304500.00 |
| 90 | 19333.333333 | 58000.00 |
| 100 | 8600.000000 | 51600.00 |
| 110 | 10150.000000 | 20300.00 |
+---------------+--------------+-------------+
12 rows in set (0.00 sec)
mysql> # 需求:查询各个工作的平均工资
mysql> SELECT job_id, AVG(salary)
-> FROM employees
-> GROUP BY job_id;
+------------+--------------+
| job_id | AVG(salary) |
+------------+--------------+
| AC_ACCOUNT | 8300.000000 |
| AC_MGR | 12000.000000 |
| AD_ASST | 4400.000000 |
| AD_PRES | 24000.000000 |
| AD_VP | 17000.000000 |
| FI_ACCOUNT | 7920.000000 |
| FI_MGR | 12000.000000 |
| HR_REP | 6500.000000 |
| IT_PROG | 5760.000000 |
| MK_MAN | 13000.000000 |
| MK_REP | 6000.000000 |
| PR_REP | 10000.000000 |
| PU_CLERK | 2780.000000 |
| PU_MAN | 11000.000000 |
| SA_MAN | 12200.000000 |
| SA_REP | 8350.000000 |
| SH_CLERK | 3215.000000 |
| ST_CLERK | 2785.000000 |
| ST_MAN | 7280.000000 |
+------------+--------------+
19 rows in set (0.00 sec)
(2)多个列分组
mysql> # 需求:查询各个department_id, job_id的平均工资
mysql> # 方式1:
mysql> SELECT department_id, job_id, AVG(salary)
-> FROM employees
-> GROUP BY department_id, job_id;
+---------------+------------+--------------+
| department_id | job_id | AVG(salary) |
+---------------+------------+--------------+
| NULL | SA_REP | 7000.000000 |
| 10 | AD_ASST | 4400.000000 |
| 20 | MK_MAN | 13000.000000 |
| 20 | MK_REP | 6000.000000 |
| 30 | PU_CLERK | 2780.000000 |
| 30 | PU_MAN | 11000.000000 |
| 40 | HR_REP | 6500.000000 |
| 50 | SH_CLERK | 3215.000000 |
| 50 | ST_CLERK | 2785.000000 |
| 50 | ST_MAN | 7280.000000 |
| 60 | IT_PROG | 5760.000000 |
| 70 | PR_REP | 10000.000000 |
| 80 | SA_MAN | 12200.000000 |
| 80 | SA_REP | 8396.551724 |
| 90 | AD_PRES | 24000.000000 |
| 90 | AD_VP | 17000.000000 |
| 100 | FI_ACCOUNT | 7920.000000 |
| 100 | FI_MGR | 12000.000000 |
| 110 | AC_ACCOUNT | 8300.000000 |
| 110 | AC_MGR | 12000.000000 |
+---------------+------------+--------------+
20 rows in set (0.00 sec)
mysql> # 方式2:
mysql> SELECT job_id, department_id, AVG(salary)
-> FROM employees
-> GROUP BY job_id, department_id;
+------------+---------------+--------------+
| job_id | department_id | AVG(salary) |
+------------+---------------+--------------+
| AC_ACCOUNT | 110 | 8300.000000 |
| AC_MGR | 110 | 12000.000000 |
| AD_ASST | 10 | 4400.000000 |
| AD_PRES | 90 | 24000.000000 |
| AD_VP | 90 | 17000.000000 |
| FI_ACCOUNT | 100 | 7920.000000 |
| FI_MGR | 100 | 12000.000000 |
| HR_REP | 40 | 6500.000000 |
| IT_PROG | 60 | 5760.000000 |
| MK_MAN | 20 | 13000.000000 |
| MK_REP | 20 | 6000.000000 |
| PR_REP | 70 | 10000.000000 |
| PU_CLERK | 30 | 2780.000000 |
| PU_MAN | 30 | 11000.000000 |
| SA_MAN | 80 | 12200.000000 |
| SA_REP | NULL | 7000.000000 |
| SA_REP | 80 | 8396.551724 |
| SH_CLERK | 50 | 3215.000000 |
| ST_CLERK | 50 | 2785.000000 |
| ST_MAN | 50 | 7280.000000 |
+------------+---------------+--------------+
20 rows in set (0.00 sec)
mysql> # 错误的!
mysql> SELECT department_id, job_id, AVG(salary)
-> FROM employees
-> GROUP BY department_id;
SELECT中出现的非组函数的字段必须声明在GROUP BY中。 反之,GROUP BY中声明的字段可以不出现在SELECT中。GROUP BY声明在FROM后面、WHERE后面,ORDER BY前面、LIMIT前面- MySQL中GROUP BY中使用
WITH ROLLUP
(3)GROUP BY中使用WITH ROLLUP
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
mysql> # 查询整个公司的平均工资
mysql> SELECT AVG(salary) FROM employees;
+-------------+
| AVG(salary) |
+-------------+
| 6461.682243 |
+-------------+
1 row in set (0.00 sec)
mysql> # 根据 GROUP BY 查询各个department_id的平均工资,最后一个字段就是整个公司的平均工资
mysql> SELECT department_id,AVG(salary)
-> FROM employees
-> GROUP BY department_id WITH ROLLUP;
+---------------+--------------+
| department_id | AVG(salary) |
+---------------+--------------+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 30 | 4150.000000 |
| 40 | 6500.000000 |
| 50 | 3475.555556 |
| 60 | 5760.000000 |
| 70 | 10000.000000 |
| 80 | 8955.882353 |
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
| NULL | 6461.682243 |
+---------------+--------------+
13 rows in set (0.00 sec)
mysql> # 说明:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
mysql> # 错误的:
mysql> SELECT department_id,AVG(salary) avg_sal
-> FROM employees
-> GROUP BY department_id WITH ROLLUP
-> ORDER BY avg_sal;
3. HAVING
(1)基本使用
过滤分组:HAVING子句
- 行已经被分组。
- 使用了聚合函数。
- 满足HAVING 子句中条件的分组将被显示。
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用
mysql> # 查询各个部门中最高工资比10000高的部门信息
mysql> # 错误的写法:
mysql> SELECT department_id,MAX(salary)
-> FROM employees
-> WHERE MAX(salary) > 10000
-> GROUP BY department_id;
mysql> # 要求1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则,报错。
mysql> # 要求2:HAVING 必须声明在 GROUP BY 的后面。
mysql> # 要求3:开发中,我们使用HAVING的前提是SQL中使用了GROUP BY。
mysql> # 正确的写法:
mysql> SELECT department_id,MAX(salary)
-> FROM employees
-> GROUP BY department_id
-> HAVING MAX(salary) > 10000;
+---------------+-------------+
| department_id | MAX(salary) |
+---------------+-------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
| 80 | 14000.00 |
| 90 | 24000.00 |
| 100 | 12000.00 |
| 110 | 12000.00 |
+---------------+-------------+
6 rows in set (0.00 sec)
mysql> # 查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
mysql> # 方式1:推荐,执行效率高于方式2.
mysql> SELECT department_id,MAX(salary)
-> FROM employees
-> WHERE department_id IN (10,20,30,40)
-> GROUP BY department_id
-> HAVING MAX(salary) > 10000;
+---------------+-------------+
| department_id | MAX(salary) |
+---------------+-------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
+---------------+-------------+
2 rows in set (0.00 sec)
mysql> # 方式2:
mysql> SELECT department_id,MAX(salary)
-> FROM employees
-> GROUP BY department_id
-> HAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
+---------------+-------------+
| department_id | MAX(salary) |
+---------------+-------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
+---------------+-------------+
2 rows in set (0.09 sec)
- 当过滤条件中有聚合函数时,则此过滤条件必须声明在
HAVING中。- 当过滤条件中没有聚合函数时,则此过滤条件声明在
WHERE中或HAVING中都可以。但是,建议大家声明在WHERE中。
(2)WHERE和HAVING的对比
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另 外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。

- WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了HAVING可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
4. SELECT的执行过程
(1)查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
(3)SELECT执行顺序
- 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
- SELECT 语句的执行顺序:
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
九、子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL 4.1开始引入。SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
1. 子查询引入

现有解决方式:
mysql> # 方式一:
mysql> SELECT salary
-> FROM employees
-> WHERE last_name = 'Abel';
+----------+
| salary |
+----------+
| 11000.00 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT last_name,salary
-> FROM employees
-> WHERE salary > 11000;
+-----------+----------+
| last_name | salary |
+-----------+----------+
| King | 24000.00 |
| Kochhar | 17000.00 |
| De Haan | 17000.00 |
| Greenberg | 12000.00 |
| Russell | 14000.00 |
| Partners | 13500.00 |
| Errazuriz | 12000.00 |
| Ozer | 11500.00 |
| Hartstein | 13000.00 |
| Higgins | 12000.00 |
+-----------+----------+
10 rows in set (0.00 sec)
mysql> # 方式二:自连接
mysql> SELECT e2.last_name,e2.salary
-> FROM employees e1,employees e2
-> WHERE e1.last_name = 'Abel'
-> AND e1.salary < e2.salary;
+-----------+----------+
| last_name | salary |
+-----------+----------+
| King | 24000.00 |
| Kochhar | 17000.00 |
| De Haan | 17000.00 |
| Greenberg | 12000.00 |
| Russell | 14000.00 |
| Partners | 13500.00 |
| Errazuriz | 12000.00 |
| Ozer | 11500.00 |
| Hartstein | 13000.00 |
| Higgins | 12000.00 |
+-----------+----------+
10 rows in set (0.00 sec)
mysql> # 方式三:子查询
mysql> SELECT last_name,salary
-> FROM employees
-> WHERE salary > (
-> SELECT salary
-> FROM employees
-> WHERE last_name = 'Abel'
-> );
+-----------+----------+
| last_name | salary |
+-----------+----------+
| King | 24000.00 |
| Kochhar | 17000.00 |
| De Haan | 17000.00 |
| Greenberg | 12000.00 |
| Russell | 14000.00 |
| Partners | 13500.00 |
| Errazuriz | 12000.00 |
| Ozer | 11500.00 |
| Hartstein | 13000.00 |
| Higgins | 12000.00 |
+-----------+----------+
10 rows in set (0.30 sec)
2. 子查询的基本使用
- 子查询的基本语法结构:
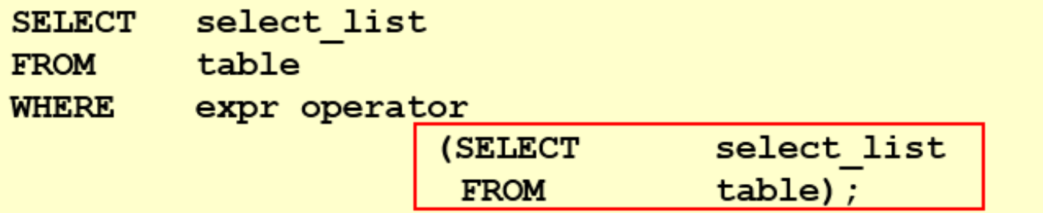
- 子查询(内查询)在主查询之前一次执行完成。
- 子查询的结果被主查询(外查询)使用 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
3. 单行子查询
(1)单行比较操作符

mysql> # 需求:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
mysql> SELECT last_name,job_id,salary
-> FROM employees
-> WHERE job_id = (
-> SELECT job_id
-> FROM employees
-> WHERE employee_id = 141
-> )
-> AND salary > (
-> SELECT salary
-> FROM employees
-> WHERE employee_id = 143
-> );
+-------------+----------+---------+
| last_name | job_id | salary |
+-------------+----------+---------+
| Nayer | ST_CLERK | 3200.00 |
| Mikkilineni | ST_CLERK | 2700.00 |
| Bissot | ST_CLERK | 3300.00 |
| Atkinson | ST_CLERK | 2800.00 |
| Mallin | ST_CLERK | 3300.00 |
| Rogers | ST_CLERK | 2900.00 |
| Ladwig | ST_CLERK | 3600.00 |
| Stiles | ST_CLERK | 3200.00 |
| Seo | ST_CLERK | 2700.00 |
| Rajs | ST_CLERK | 3500.00 |
| Davies | ST_CLERK | 3100.00 |
+-------------+----------+---------+
11 rows in set (0.10 sec)
mysql> # 要求:查询与141号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id。
mysql> SELECT employee_id,manager_id,department_id
-> FROM employees
-> WHERE (manager_id,department_id) = (
-> SELECT manager_id,department_id
-> FROM employees
-> WHERE employee_id = 141
-> )
-> AND employee_id <> 141;
+-------------+------------+---------------+
| employee_id | manager_id | department_id |
+-------------+------------+---------------+
| 142 | 124 | 50 |
| 143 | 124 | 50 |
| 144 | 124 | 50 |
| 196 | 124 | 50 |
| 197 | 124 | 50 |
| 198 | 124 | 50 |
| 199 | 124 | 50 |
+-------------+------------+---------------+
7 rows in set (0.00 sec)
(2)HAVING中的子查询
- 首先执行子查询。
- 向主查询中的HAVING 子句返回结果。
mysql> # 需求:查询最低工资大于110号部门最低工资的部门id和其最低工资
mysql> SELECT department_id,MIN(salary)
-> FROM employees
-> WHERE department_id IS NOT NULL
-> GROUP BY department_id
-> HAVING MIN(salary) > (
-> SELECT MIN(salary)
-> FROM employees
-> WHERE department_id = 110
-> );
+---------------+-------------+
| department_id | MIN(salary) |
+---------------+-------------+
| 70 | 10000.00 |
| 90 | 17000.00 |
+---------------+-------------+
2 rows in set (0.00 sec)
(3)CASE中的子查询
mysql> # 需求:显式员工的employee_id,last_name和location。
mysql> # 其中,若员工department_id与location_id为1800的department_id相同,
mysql> # 则location为’Canada’,其余则为’USA’,只显示前面3条数据。
mysql> SELECT employee_id,last_name,
-> CASE department_id
-> WHEN (SELECT department_id FROM departments WHERE location_id = 1800) THEN 'Canada'
-> ELSE 'USA'
-> END "location"
-> FROM employees
-> LIMIT 0, 3;
+-------------+-----------+----------+
| employee_id | last_name | location |
+-------------+-----------+----------+
| 100 | King | USA |
| 101 | Kochhar | USA |
| 102 | De Haan | USA |
+-------------+-----------+----------+
3 rows in set (0.00 sec)
4. 多行子查询
- 也称为集合比较子查询
- 内查询返回多行
- 使用多行比较操作符
(1)多行比较操作符
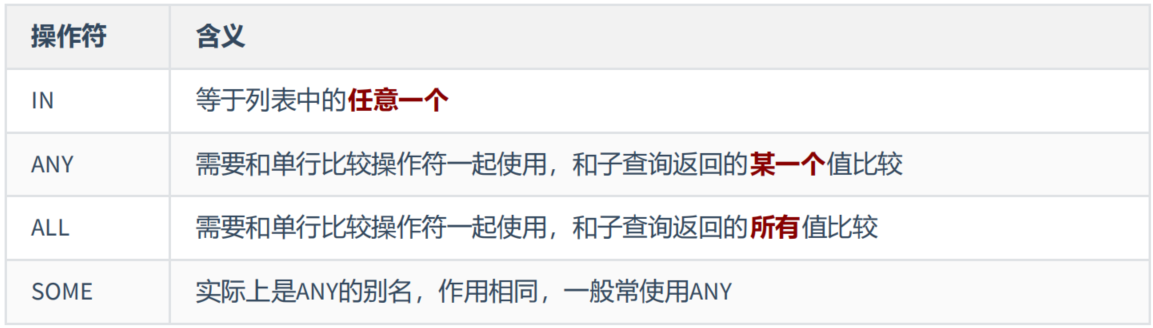
mysql> # IN:
mysql> SELECT employee_id, last_name
-> FROM employees
-> WHERE salary IN(
-> SELECT MIN(salary)
-> FROM employees
-> GROUP BY department_id)
-> LIMIT 0, 3;
+-------------+-----------+
| employee_id | last_name |
+-------------+-----------+
| 101 | Kochhar |
| 102 | De Haan |
| 104 | Ernst |
+-------------+-----------+
3 rows in set (0.00 sec)
mysql> # ANY / ALL:
mysql> # 需求:返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
mysql> # 返回前 3 条
mysql> SELECT employee_id,last_name,job_id,salary
-> FROM employees
-> WHERE job_id <> 'IT_PROG'
-> AND salary < ANY (
-> SELECT salary
-> FROM employees
-> WHERE job_id = 'IT_PROG'
-> )
-> LIMIT 0, 3;
+-------------+-----------+------------+---------+
| employee_id | last_name | job_id | salary |
+-------------+-----------+------------+---------+
| 206 | Gietz | AC_ACCOUNT | 8300.00 |
| 200 | Whalen | AD_ASST | 4400.00 |
| 110 | Chen | FI_ACCOUNT | 8200.00 |
+-------------+-----------+------------+---------+
3 rows in set (0.00 sec)
mysql> # 需求:返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、姓名、job_id 以及salary
mysql> # 返回前 3 条
mysql> SELECT employee_id,last_name,job_id,salary
-> FROM employees
-> WHERE job_id <> 'IT_PROG'
-> AND salary < ALL (
-> SELECT salary
-> FROM employees
-> WHERE job_id = 'IT_PROG'
-> )
-> LIMIT 0, 3;
+-------------+-----------+----------+---------+
| employee_id | last_name | job_id | salary |
+-------------+-----------+----------+---------+
| 115 | Khoo | PU_CLERK | 3100.00 |
| 116 | Baida | PU_CLERK | 2900.00 |
| 117 | Tobias | PU_CLERK | 2800.00 |
+-------------+-----------+----------+---------+
3 rows in set (0.00 sec)
(2)聚合函数下的子查询
mysql> # 需求:查询平均工资最低的部门id
mysql> # MySQL中聚合函数是不能嵌套使用的
mysql> # 错误!!!
mysql> SELECT MIN(AVG(salary)) avg_sal
-> FROM employees
-> GROUP BY department_id;
ERROR 1111 (HY000): Invalid use of group function
mysql> # 方式1:
mysql> SELECT department_id
-> FROM employees
-> GROUP BY department_id
-> HAVING AVG(salary) = (
-> SELECT MIN(avg_sal)
-> FROM(
-> SELECT AVG(salary) avg_sal
-> FROM employees
-> GROUP BY department_id
-> ) t_dept_avg_sal
-> );
+---------------+
| department_id |
+---------------+
| 50 |
+---------------+
1 row in set (0.00 sec)
mysql> #方式2:
mysql> SELECT department_id
-> FROM employees
-> GROUP BY department_id
-> HAVING AVG(salary) <= ALL(
-> SELECT AVG(salary) avg_sal
-> FROM employees
-> GROUP BY department_id
-> );
+---------------+
| department_id |
+---------------+
| 50 |
+---------------+
1 row in set (0.00 sec)
5. 相关子查询
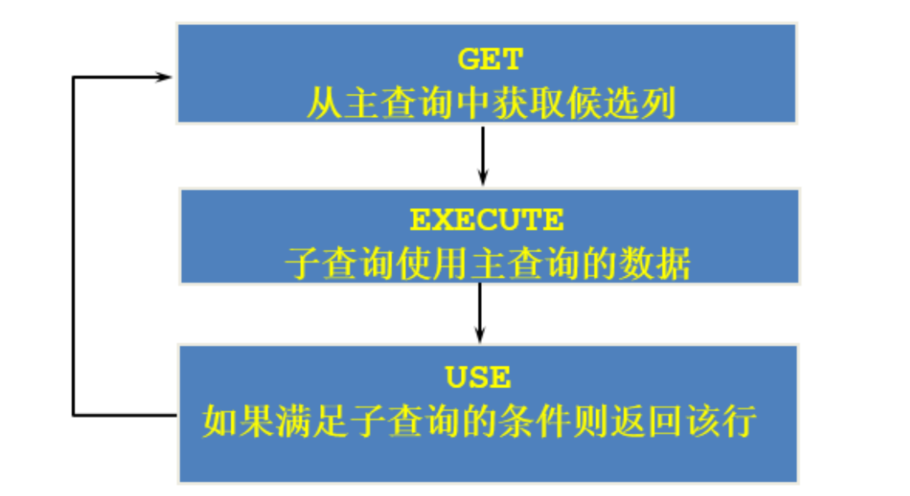
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询。相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
相关子查询执行流程图:
(1)代码示例
mysql> # 需求:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
mysql> # 方式1:使用相关子查询
mysql> SELECT last_name,salary,department_id
-> FROM employees e1
-> WHERE salary > (
-> SELECT AVG(salary)
-> FROM employees e2
-> WHERE department_id = e1.department_id
-> )
-> LIMIT 3;
+-----------+----------+---------------+
| last_name | salary | department_id |
+-----------+----------+---------------+
| King | 24000.00 | 90 |
| Hunold | 9000.00 | 60 |
| Ernst | 6000.00 | 60 |
+-----------+----------+---------------+
3 rows in set (0.00 sec)
mysql> # 方式2:在FROM中声明子查询
mysql> SELECT e.last_name,e.salary,e.department_id
-> FROM employees e,(
-> SELECT department_id,AVG(salary) avg_sal
-> FROM employees
-> GROUP BY department_id) t_dept_avg_sal
-> WHERE e.department_id = t_dept_avg_sal.department_id
-> AND e.salary > t_dept_avg_sal.avg_sal
-> LIMIT 3;
+-----------+----------+---------------+
| last_name | salary | department_id |
+-----------+----------+---------------+
| Hartstein | 13000.00 | 20 |
| Raphaely | 11000.00 | 30 |
| Weiss | 8000.00 | 50 |
+-----------+----------+---------------+
3 rows in set (0.00 sec)
mysql> # 需求:查询员工的id,salary,按照department_name 排序
mysql> SELECT employee_id,salary
-> FROM employees e
-> ORDER BY (
-> SELECT department_name
-> FROM departments d
-> WHERE e.department_id = d.department_id
-> ) ASC
-> LIMIT 3;
+-------------+----------+
| employee_id | salary |
+-------------+----------+
| 178 | 7000.00 |
| 205 | 12000.00 |
| 206 | 8300.00 |
+-------------+----------+
3 rows in set (0.00 sec)
(2)EXISTS 与 NOT EXISTS关键字
- 关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
- 如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
- 如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
- NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
mysql> # 需求:查询公司管理者的employee_id,last_name,job_id,department_id信息
mysql> SELECT employee_id,last_name,job_id,department_id
-> FROM employees e1
-> WHERE EXISTS (
-> SELECT *
-> FROM employees e2
-> WHERE e1.employee_id = e2.manager_id
-> )
-> LIMIT 3;
+-------------+-----------+---------+---------------+
| employee_id | last_name | job_id | department_id |
+-------------+-----------+---------+---------------+
| 100 | King | AD_PRES | 90 |
| 101 | Kochhar | AD_VP | 90 |
| 102 | De Haan | AD_VP | 90 |
+-------------+-----------+---------+---------------+
3 rows in set (0.00 sec)
mysql> # 需求:查询departments表中,不存在于employees表中的部门的department_id和department_name
mysql> SELECT department_id,department_name
-> FROM departments d
-> WHERE NOT EXISTS (
-> SELECT *
-> FROM employees e
-> WHERE d.department_id = e.department_id
-> )
-> LIMIT 3;
+---------------+--------------------+
| department_id | department_name |
+---------------+--------------------+
| 120 | Treasury |
| 130 | Corporate Tax |
| 140 | Control And Credit |
+---------------+--------------------+
3 rows in set (0.00 sec)














 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









