







《An extensible plug-and-play method for multi-aspect controllable text generation》论文解读
文章的主要工作
(1)提出了一种可扩展的即插即用方法,PROMPT GATING,用于多方面可控文本生成,它能够通过简单地连接插件来控制训练时未见的方面组合。
(2)为相互干扰问题提供了理论下界和实证分析,我这将有助于未来的研究。
(3)实验表明,我们的方法相互干扰较低,在文本质量、约束准确性和可扩展性方面优于强基线。
总体架构
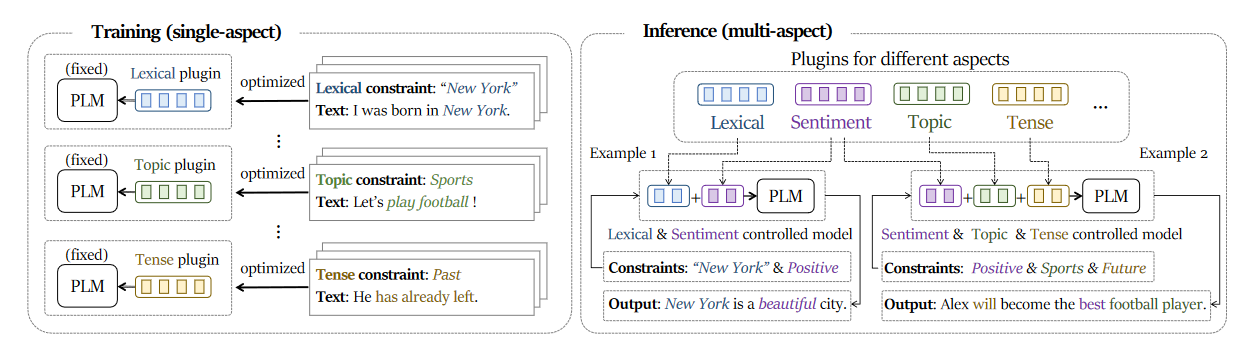
图1:概述我们提出的用于多方面可控文本生成的可扩展即插即用方法。首先,插件分别在单方面标记数据上进行训练(左)。然后,可以通过简单的串联来组合任意插件,并将其插入到预训练模型中以满足相应的约束组合(右)。由于不同插件的单独训练,扩展新约束的成本相对较低。此外,我们的方法抑制了相互干扰的积累,减轻了约束的退化。
背景
一般来说,前缀调整将轻量级连续向量前置到每个 Transformer 层的多头注意力子层:
H = Att ( Q , [ P K ; K ] , [ P V ; V ] ) (1) H = \text{Att}(Q, [P^K; K], [P^V; V])\tag{1} H=Att(Q,[PK;K],[PV;V])(1)
Att ( ⋅ ) \text{Att}(·) Att(⋅) 是注意力函数, Q Q Q 是输入查询, K K K 和 V V V 是输入的激活值, P K P^K PK 和 P V P^V PV 是可训练的前缀, [ ; ] [;] [;] 表示串联操作, H H H 是注意力子层的输出。我们使用 ϕ \phi ϕ 来表示所有 Transformer 层中的前缀集合。
具体而言,对于多方面可控文本生成,我们假设存在 N N N 个方面的约束。
ϕ ^ i = arg max ϕ i { P ( y ∣ x ; θ , ϕ i ) } , 1 ≤ i ≤ N (2) \hat{\phi}_i = \underset{\phi_i}{\arg\max} \{ P(y|x; \theta, \phi_i) \}, 1 \leq i \leq N\tag{2} ϕ^i=ϕiargmax{
P(y∣x;θ,ϕi)},1≤i≤N(2)
其中 θ \theta θ是预训练模型的固定参数, y y y是受控的目标句子, x x x是输入句子, P ( y ∣ x ; θ , ϕ i ) P(y|x; \theta, \phi_i) P(y∣x;θ,ϕi)是在给定 x x x的条件下 y y y的概率, ϕ ^ i \hat{\phi}_i ϕ^i是第 i i i个方面的前缀的学习参数。
在推理过程中,对于多个方面的组合,相应的前缀被选择并通过连接(Qian et al., 2022; Yang et al., 2022)或找到它们的交集(Gu et al., 2022)来合成,然后生成过程基于这种合成进行。在不失一般性的情况下,我们以两个方面为例。条件概率可以表示为
P ( y ^ ∣ x ; θ , syn ( ϕ ^ 1 , ϕ ^ 2 ) ) , ( 3 ) P(\hat{y}|x; \theta, \text{syn}(\hat{\phi}_1, \hat{\phi}_2)),\quad (3) P(y^∣x;θ,syn(ϕ^1,ϕ^2)),(3)
其中, syn ( ⋅ ) \text{syn}(\cdot) syn(⋅) 是一个合成函数, y ^ \hat{y} y^ 是候选句子, ϕ ^ 1 \hat{\phi}_1 ϕ^1 和 ϕ ^ 2 \hat{\phi}_2 ϕ^2 是两组对应于两个方面(例如,对于情感是“positive”,对于话题是“sports”)的前缀。
相互干扰的分析
定义
“相互干扰(MI)”是指在推理阶段(即零样本设置)时,多个单独训练但同时指导预训练模型的插件之间的干扰。然而,由于深度神经网络的复杂性,确切的干扰分析是困难的。直观上,如果在训练期间多个插件是同时优化的,这需要多方面标记的数据,它们的干扰将被最小化,因为它们已经学会在监督下合作地工作(即在监督设置中)。因此,我们使用在监督和零样本设置下隐藏状态的差异来近似估计多个插件的相互干扰。具体来说,让 ϕ ^ i \hat{\phi}_i ϕ^i 和 ϕ ~ i \tilde{\phi}_i ϕ~i 分别是从单方面和多方面标记数据中学习的插件的参数。以双方面控制为例,Transformer层的输出由 H ( x , ϕ ^ 1 , ϕ ^ 2 ) H(x, \hat{\phi}_1, \hat{\phi}_2) H(x,ϕ^1,ϕ^2)给出,其中 x 是层输入,那么相互干扰可以定义为:
M I ≈ ∥ H ( x , ϕ ^ 1 , ϕ ^ 2 ) − H ( x , ϕ ~ 1 , ϕ ~ 2 ) ∥ . (4) MI \approx \left\| H(x, \hat{\phi}_1, \hat{\phi}_2) - H(x, \tilde{\phi}_1, \tilde{\phi}_2) \right\|.\tag{4} MI≈
H(x,ϕ^1,ϕ^2)−H(x,ϕ~1,ϕ~2)
.(4)
实证分析
由于互相干扰已被定义为零样本和有监督设置中隐藏状态间差距的范数,我们可以在真实数据集上对其进行实证估计。通过计算Yelp数据集(Lample et al., 2019)上的平均范数,我们在图2中绘制了Prompt-tuning(Lester et al., 2021)和Prefix-tuning(Li and Liang, 2021)中互相干扰随Transformer层数变化的趋势。我们发现,随着可训练参数的插入,干扰逐渐累积。此外,最后一个Transformer层(即图2中的第12层)的互相干扰幅度与性能差距一致,性能差距是单一方面和多方面设置中约束满足度之间的差异(见表1)。同时,过少的可训练参数无法有效指导预训练模型。总结来说,为了在零样本设置中保持有效,关键是在提供足够的可训练参数以提高有监督性能的同时,限制互相干扰的增长(以降低性能差距)。
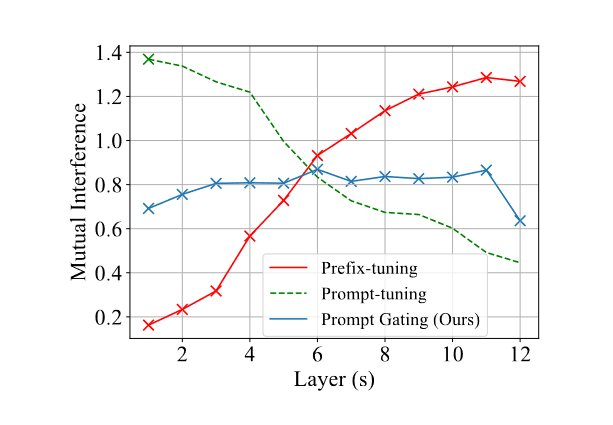
图2:互干扰随Transformer层数的变化。注意,“×”表示连续向量的插入。 Prompt-tuning 仅在嵌入层之后将向量插入到模型中,而其他两种方法将向量插入到每个 Transformer 层中。我们的方法(Prompt Gating)抑制相互干扰的增长,同时插入足够的可训练参数。
理论分析
为了找到减轻相互干扰的方法,我们进行了理论分析。
由于前馈和 Layernorm 子层是位置操作,不会引入插件的干扰,因此我们重点分析多头注意力(MHA)子层。
根据之前的研究,具有前缀的单个注意力头的输出,即第i个插件的输出,可以表示为:
h i = λ ( x i ) h ˉ i + ( 1 − λ ( x i ) ) Δ h i = s i h ˉ i + t i Δ h i , ( 8 ) h_i = \lambda(x_i)\bar{h}_i + (1 - \lambda(x_i))\Delta h_i \\ = s_i\bar{h}_i + t_i\Delta h_i, \quad (8) hi=λ(xi)hˉi+(1−λ(xi))Δhi=sihˉi+tiΔhi,(8)
其中, h ˉ i \bar{h}_i hˉi 表示预训练的生成模型以 x i x_i xi作为输入的原始输出。 λ ( x i ) \lambda(x_i) λ(xi) 是与注意力权重相关的标量,其中 λ ( x i ) = s i \lambda(x_i) = s_i λ(xi)=s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











