






 https://github.com/ArrowLuo/CLIP4Clip
https://github.com/ArrowLuo/CLIP4Clip1) 创新点:
这个文章最主要的贡献就是把CLIP模型应用到文本视频检索领域,以及设计出了几种新型的相似函数。我们可以借鉴一下他的创新过程,可以感受到A+B的强大魅力。
1) 视频encoder 以及文本encoder 。
文本encoder 就是直接使用CLIP的文本编辑器。
视频encoder 主要是在编码上面花心思,然后参考的是这篇论文:ViViT: A Video Vision Transformer 。提出了两种编码方式,一个就是2D,另外一个就是3D。

self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
self.conv2 = nn.Conv3d(in_channels=3, out_channels=width, kernel_size=(3, patch_size, patch_size),
stride=(1, patch_size, patch_size), padding=(1, 0, 0), bias=False)
def forward(self, x: torch.Tensor, video_frame=-1):
if self.linear_patch == '3d':
assert video_frame != -1
x_3d = x.reshape(-1, video_frame, x.shape[-3], x.shape[-2], x.shape[-1])
x_3d = x_3d.permute(0, 2, 1, 3, 4)
x_3d = self.conv2(x_3d) # shape = [*, width, frame, grid, grid]
x_3d = x_3d.permute(0, 2, 1, 3, 4) # shape = [*, frame, width, grid, grid]
x = x_3d.reshape(-1, x_3d.shape[-3], x_3d.shape[-2], x_3d.shape[-1]).contiguous() # shape = [*, width, grid, grid]
else:
x = self.conv1(x) # shape = [*, width, grid, grid]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x, video_frame=video_frame)
x = x.permute(1, 0, 2) # LND -> NLD
return x2) 相似函数,提出了三种,其实严格意义来说,使用四种。我们来具体看看。
1. 前三种:
他们最后的方式都是一样,但是有一些在计算之前,对visul向量有不同的操作,分别是什么都不做,LSTM,Transformer-Enc
1.LSTM:
visual_output_original = visual_output
visual_output = pack_padded_sequence(visual_output, torch.sum(video_mask, dim=-1).cpu(),
batch_first=True, enforce_sorted=False)
# self.lstm_visual = nn.LSTM(input_size=cross_config.hidden_size, hidden_size=cross_config.hidden_size,
# batch_first=True, bidirectional=False, num_layers=1)
visual_output, _ = self.lstm_visual(visual_output) #lstm_visual 是一个LSTM网络
if self.training: self.lstm_visual.flatten_parameters()
visual_output, _ = pad_packed_sequence(visual_output, batch_first=True)
visual_output = torch.cat((visual_output, visual_output_original[:, visual_output.size(1):, ...].contiguous()), dim=1)
visual_output = visual_output + visual_output_original![]()
2.Transformer-Enc:
# Sequential type: Transformer Encoder
visual_output_original = visual_output
seq_length = visual_output.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=visual_output.device)
position_ids = position_ids.unsqueeze(0).expand(visual_output.size(0), -1)
#self.frame_position_embeddings = nn.Embedding(cross_config.max_position_embeddings, cross_config.hidden_size)
frame_position_embeddings = self.frame_position_embeddings(position_ids) #嵌入位置信息
visual_output = visual_output + frame_position_embeddings
extended_video_mask = (1.0 - video_mask.unsqueeze(1)) * -1000000.0
extended_video_mask = extended_video_mask.expand(-1, video_mask.size(1), -1)
visual_output = visual_output.permute(1, 0, 2) # NLD -> LND
visual_output = self.transformerClip(visual_output, extended_video_mask)
visual_output = visual_output.permute(1, 0, 2) # LND -> NLD
visual_output = visual_output + visual_output_original![]()
之后他们的才做都是一样的,
visual_output = visual_output / visual_output.norm(dim=-1, keepdim=True)
visual_output = self._mean_pooling_for_similarity_visual(visual_output, video_mask) #平均池化层
visual_output = visual_output / visual_output.norm(dim=-1, keepdim=True)
sequence_output = sequence_output.squeeze(1)
sequence_output = sequence_output / sequence_output.norm(dim=-1, keepdim=True)
logit_scale = self.clip.logit_scale.exp()
retrieve_logits = logit_scale * torch.matmul(sequence_output, visual_output.t())
return retrieve_logits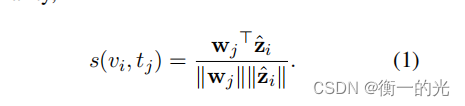
2. Tight type:
首先将字幕特征与序列特征拼接,再进行计算
def forward(self, concat_input, concat_type=None, attention_mask=None, output_all_encoded_layers=True):
if attention_mask is None:
attention_mask = torch.ones(concat_input.size(0), concat_input.size(1))
if concat_type is None:
concat_type = torch.zeros_like(attention_mask)
extended_attention_mask = self.build_attention_mask(attention_mask)
embedding_output = self.embeddings(concat_input, concat_type)
embedding_output = embedding_output.permute(1, 0, 2) # NLD -> LND
embedding_output = self.transformer(embedding_output, extended_attention_mask)
embedding_output = embedding_output.permute(1, 0, 2) # LND -> NLD
pooled_output = self.pooler(embedding_output, hidden_mask=attention_mask)
return embedding_output, pooled_output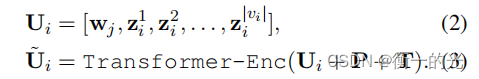
![]()
3) 损失函数:
class CrossEn(nn.Module):
def __init__(self,):
super(CrossEn, self).__init__()
def forward(self, sim_matrix):
logpt = F.log_softmax(sim_matrix, dim=-1)
logpt = torch.diag(logpt)
nce_loss = -logpt
sim_loss = nce_loss.mean()
return sim_loss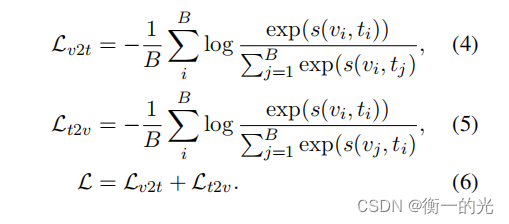


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









