







首先,当我们要实现这样一个功能的时候,应该怎么做呢??
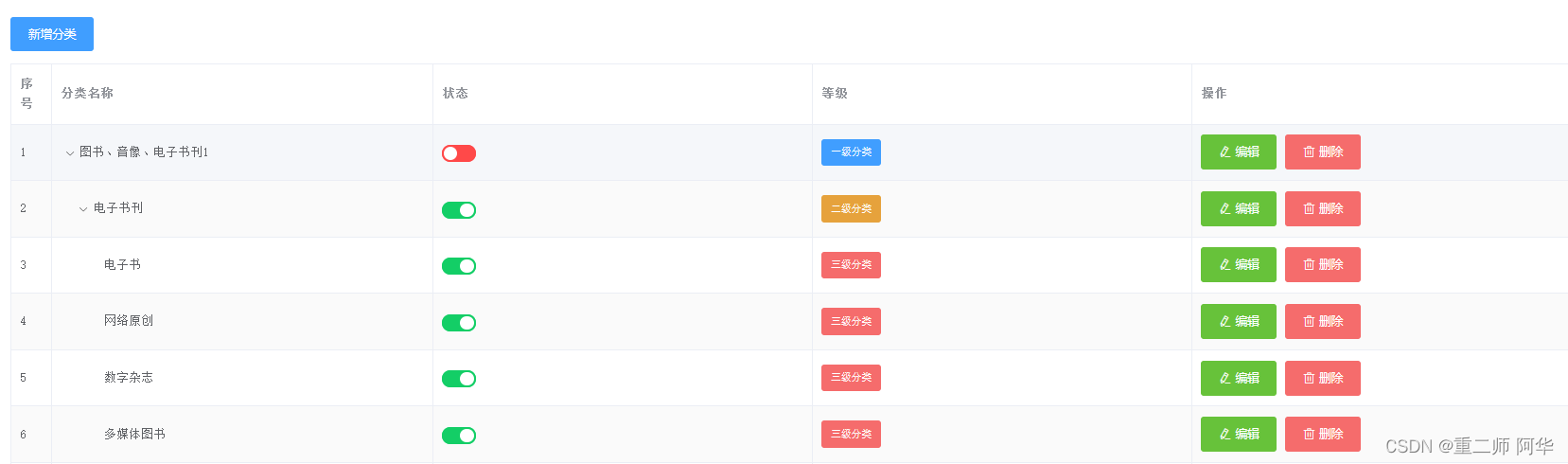 可以看到这是一个三级下拉列表,我们再来看看数据库的数据,要如何去获取封装
可以看到这是一个三级下拉列表,我们再来看看数据库的数据,要如何去获取封装
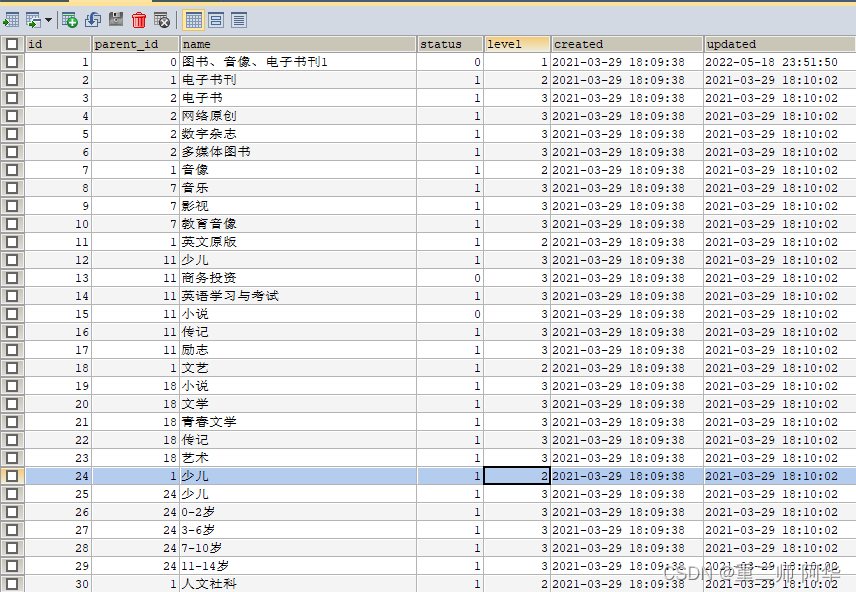 这里我们通过parent_id可以找到上级id,这样就可以实现分层了,level表示了当前是几级列表
这里我们通过parent_id可以找到上级id,这样就可以实现分层了,level表示了当前是几级列表
然后我们就开始来进行数据的封装了.
第一种
long start = System.currentTimeMillis();
QueryWrapper<ItemCat> id = new QueryWrapper<ItemCat>().eq("parent_id", 0);
List<ItemCat> itemCats = itemCatMapper.selectList(id);
for (ItemCat cat : itemCats) {
id.clear();
QueryWrapper<ItemCat> parent_id = id.eq("parent_id", cat.getId());
List<ItemCat> sons = itemCatMapper.selectList(parent_id);
cat.setChildren(sons);
for (ItemCat son : sons) {
id.clear();
QueryWrapper<ItemCat> parent_id_son = id.eq("parent_id", son.getId());
List<ItemCat> grandson = itemCatMapper.selectList(parent_id_son);
son.setChildren(grandson);
}
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + "毫秒");//耗时:275毫秒 耗时:186毫秒 耗时:180毫秒 耗时:163毫秒 耗时:198毫秒
return itemCats;
第二种 优化版
@Override
public List<ItemCat> findItemCatList(Integer level) {
long start = System.currentTimeMillis();
Map<Integer, List<ItemCat>> map = getMap();
if (level == 1) {
//返回一级商品信息
return map.get(0);
}
//返回一二级商品信息
if (level == 2) {
return getTwoList(map);
}
if (level == 3) {
//获取1,2,3级商品信息
List<ItemCat> threeList = getThreeList(map);
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + "毫秒");// Total: 1032耗时:39毫秒 30毫秒 20毫秒
return threeList;
}
return null;
}
//获取三级菜单
private List<ItemCat> getThreeList(Map<Integer, List<ItemCat>> map) {
List<ItemCat> oneList = getTwoList(map);
//遍历一级菜单,获取二级菜单
for (ItemCat oenItemCat : oneList) {
List<ItemCat> twoList = oenItemCat.getChildren();
if (twoList == null || twoList.size() == 0) {
continue;
}
//遍历二级数据,查询三级信息
for (ItemCat twoItemCat : twoList) {
List<ItemCat> threeList = map.get(twoItemCat.getId());
twoItemCat.setChildren(threeList);
}
}
return oneList;
}
/**
* 将所有数据根据parent_id来分组合并显示,要哪一个父id就从map里面去找.
* <p>
* 优化手段:
* 思路:获取所有的数据库记录,之后按照父子级关系进行封装
* 数据结构: Map<k,v>
* Map<parentId,List当前父级的子级信息(不嵌套)>
* 例子: Map<0,List[{id=1,name="xx",children=null}.....]>
* <p>
* 封装数据规则:
* 1.遍历所有的数据.
* 2.获取parentId
* 3.判断parentId是否存在,之后实现数据封装
*/
public Map<Integer, List<ItemCat>> getMap() {
Map<Integer, List<ItemCat>> map = new HashMap<>();
//查询所有的数据库记录
List<ItemCat> list = itemCatMapper.selectList(null);
//1.遍历数据
for (ItemCat itemCat : list) {
int parentId = itemCat.getParentId();
if (map.containsKey(parentId)) {
//表示数据存在,将自己追加
map.get(parentId).add(itemCat);
} else {
//key不存在, 定义list集合,将自己作为第一个元素追加
List<ItemCat> childrenList = new ArrayList<>();
childrenList.add(itemCat);
//将数据保存到map集合中
map.put(parentId, childrenList);
}
}
return map;
}
//获取1-2级数据信息
public List<ItemCat> getTwoList(Map<Integer, List<ItemCat>> map) {
List<ItemCat> oneList = map.get(0);
for (ItemCat oneItemCat : oneList) {
//通过一级id去map查询得到二级数据
List<ItemCat> twoList = map.get(oneItemCat.getId());
oneItemCat.setChildren(twoList);
}
return oneList;
}
最后可以看到,第二种优化后的方式,查询效率比第一种快了大概十倍















 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











