







数据库索引是一种数据结构,用于加速特定键的读取操作。索引在频繁查询的场景下尤为重要,能够显著提升查询性能。在这篇笔记中,我们将结合PPT和PDF的内容,详细探讨数据库索引,特别是B+树索引的结构和操作。
一、索引的基本概念
索引是一种用于加速数据读取的结构,尤其是在大规模数据查询中。索引可以大幅度提高查询效率,例如在用户登录过程中,通过用户名索引快速找到相应的用户记录。
索引的特性:
- 查询支持:索引允许的查询类别,如等值查询和范围查询。
- 搜索键的选择:影响可以使用索引的查询类型。
- 数据条目存储:影响索引的性能,考虑实际数据存储或指向数据的指针。
- 可变长度键技巧:影响索引的性能。
二、B+树的性质
B+树是一种广泛使用的索引结构,具备以下性质:
- 阶数(d):每个节点(除了根节点)必须有d到2d个条目,确保树的平衡性。
- 子节点指针:内部节点有最多2d+1个子节点指针,称为树的扇出。
- 键值排序:内部节点的键值排序决定了子节点的键值范围。
- 平衡树:所有从根到叶的路径长度相同,保证树的高度平衡。
- 叶节点:只有叶节点包含实际记录或指向记录的指针,内部节点仅用于导航。
三、B+树的操作
1. 插入操作
插入过程包括以下步骤:
- 找到合适的叶节点L,在L中插入键值和记录。
- 如果L溢出(超过2d个条目),则进行分裂:
- 分裂为L1和L2,L1保留d个条目,L2保留d+1个条目。
- 如果L是叶节点,将L2的第一个条目复制到父节点;如果L是内部节点,将L2的第一个条目移动到父节点。
- 调整指针。
- 如果父节点溢出,递归进行分裂。
示例:
假设我们有一个阶数为2的B+树,初始状态如下:
[10, 20]
/ | \
[5, 7] [15] [25, 30]
- 插入值19时,首先找到合适的叶节点,即包含15的叶节点,将19插入其中。
- 由于该叶节点溢出(包含3个条目),所以将其分裂成两个叶节点:[15]和[19],并将19复制到父节点。
- 父节点更新后变为:[10, 19, 20]
2. 删除操作
删除过程相对简单:
- 找到相应的叶节点,从中删除不需要的值。
- 叶节点删除后调整结构,但不删除内部节点键值,因为它们仅用于导航。
示例:
从上述B+树中删除值19:
- 找到叶节点,直接删除19,并更新父节点为:[10, 20]。
3. 批量加载
批量加载用于高效构建B+树:
- 按键对数据排序。
- 按填充因子填充叶节点。
- 添加父节点指针,如果父节点溢出,则进行分裂和指针调整。
示例:
要构建包含1到20的B+树:
- 首先对数据排序:[1, 2, …, 20]
- 按填充因子(例如3/4)填充叶节点:
[1, 2, 3, 4, 5] -> [6, 7, 8, 9, 10] -> [11, 12, 13, 14, 15] -> [16, 17, 18, 19, 20]
- 建立父节点,调整指针和分裂溢出节点:
[6, 11, 16]
/ | \
[1,2,3,4,5] [7,8,9,10] [12,13,14,15] [17,18,19,20]
四、数据存储方式
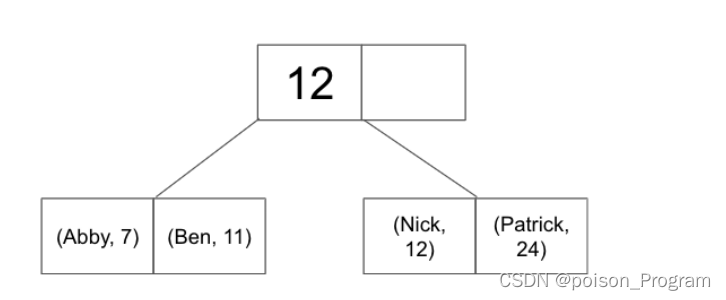
B+树的叶节点有三种记录存储方式:
-
直接存储记录:叶节点直接包含记录。
-
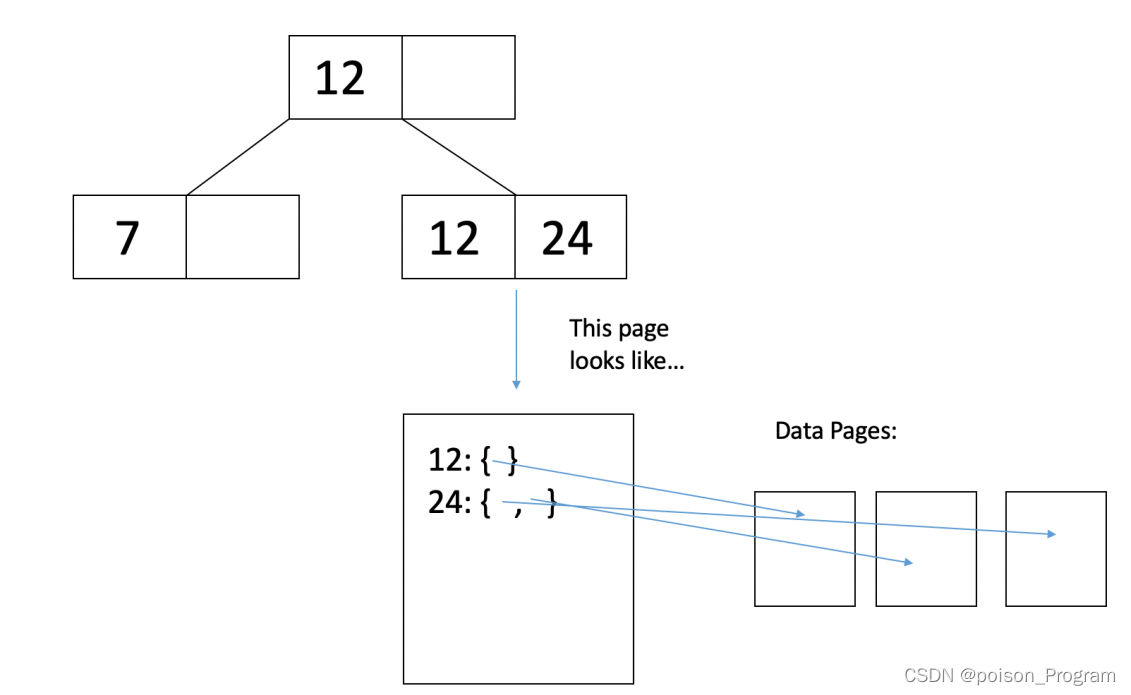
存储指向记录的指针:叶节点包含指向记录的指针。

-
存储指向记录列表的指针:叶节点包含指向记录列表的指针,对于相同键值的多条记录更加紧凑。
五、聚类与非聚类索引
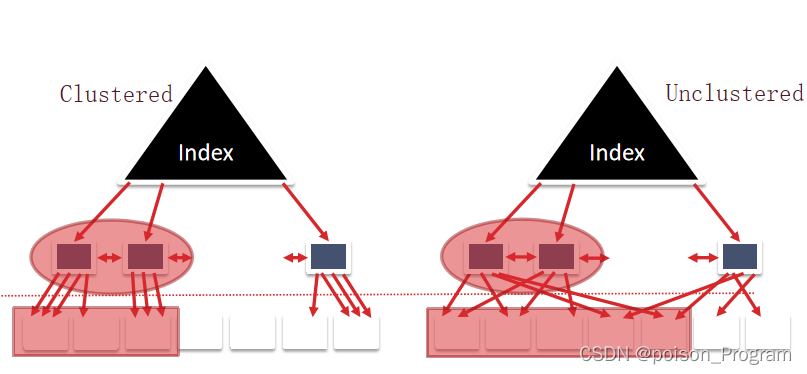
聚类索引和非聚类索引影响数据存储的组织方式:
- 聚类索引:数据页按索引键排序,通常读取一个数据页即可获取所有相关记录,I/O效率高。
- 非聚类索引:数据页无序,每条记录可能需要单独读取一个数据页,I/O效率较低。
示例:
对于聚类索引,若索引键为年龄,则数据页可能按年龄排序:
[20, 21, 22, 23, 24] -> [25, 26, 27, 28, 29] -> [30, 31, 32, 33, 34]
对于非聚类索引,数据页可能无序:
[20, 25, 30, 35, 40] -> [21, 26, 31, 36, 41] -> [22, 27, 32, 37, 42]
六、B+树成本模型
不同操作的I/O成本包括:
- 全表扫描:读取所有数据页的成本。
- 等值查询:通过索引快速定位记录的成本。
- 范围查询:通过索引定位起始记录并扫描后续记录的成本。
- 插入操作:定位插入位置并调整结构的成本。
- 删除操作:定位删除位置并调整结构的成本。
示例:
假设B+树高度为2,插入一条新记录的I/O成本:
- 搜索插入位置,需访问根节点、内部节点和叶节点,共3次I/O。
- 插入新记录,更新叶节点和可能的内部节点,共2次I/O。
通过具体示例可以看出,B+树在大多数情况下比其他索引结构更优,特别是在处理大量插入和删除操作时。
七、总结
B+树是一种动态平衡的索引结构,能够高效地处理大量数据的插入、删除和查询操作。它通过内部节点的导航和叶节点的数据存储,确保了查询的高效性和数据的有序性。通过对B+树的深入理解,可以更好地设计和优化数据库索引结构,提高数据库系统的整体性能。
最终示例:
假设我们有一个包含以下记录的用户表:
用户名 | 年龄
-----------------
Alice | 25
Bob | 30
Charlie | 35
David | 40
Eve | 45
构建一个基于年龄的B+树索引,初始状态如下:
[30]
/ \
[25] [35, 40, 45]
- 插入新的记录(Frank, 50),找到合适的叶节点并插入:
[30, 40]
/ | \
[25] [35] [45, 50]
- 删除记录(Charlie, 35),找到叶节点并删除:
[30, 40]
/ \
[25] [45, 50]
通过这些示例,我们可以清晰地理解B+树的结构和操作方式,以及它在数据库索引中的重要性。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











