







获取网页后,如何使用Xpath解析html界面。
解析html文件两种方式
html = etree.HTML(res2.text) # 读取程序里的,变成可解析的层级对象
etree.parse(‘名字.html’,etree.HTMLParser()) #读取文件里的
string(.)
这个图是截屏的下面链接文章作者的
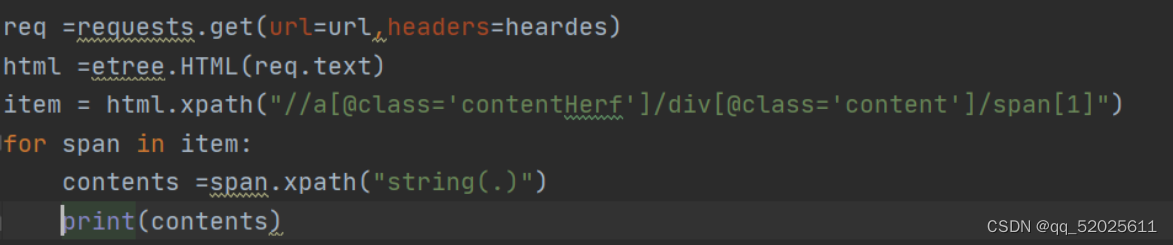
获取某页面以及用Xpath解析后数据(代码详情,如果有可优化的地方,希望看到的大佬可以帮我指出)
url2 = "略"
headers2 = {略}
res2 = requests.get(url=url,headers=headers2)
res2.encoding = 'utf-8'
time.sleep(5)
#print(res2.url)
#print(res2.status_code)
#房屋价格
html = etree.HTML(res2.text) # 读取程序里的,变成可解析的层级对象
house_price = html.xpath('//div[@class="property-price"]/p[@class="property-price-total"]/span[@class="property-price-total-num"]/text()')
print("房屋价格:", house_price)
house_price_m = html.xpath('//div[@class="property-price"]/p[@class="property-price-average"]/text()')
print("房屋每平米价格:", house_price_m)
# time.sleep(5)
#房子地址
house_dizhiqian = html.xpath('//section[@class="list-left"]//section[2]//div[@class="property-content"]//div['
'@class="property-content-info property-content-info-comm"]/p/text()')
house_dizhihou = html.xpath('//section[@class="list-left"]//section[2]//div[@class="property-content"]//div['
'@class="property-content-info property-content-info-comm"]/p/span/text()')
print("house_dizhiqian:", house_dizhiqian)
print("house_dizhihou:", house_dizhihou)
#存储数据
house_info = {
'house_name':house_name,
'house_hx_qian': house_hx_qian,
'house_hx_hou': house_hx_hou,
'house_price':house_price,
'house_price_m':house_price_m,
'house_dizhiqian':house_dizhiqian,
'house_dizhihou':house_dizhihou
}
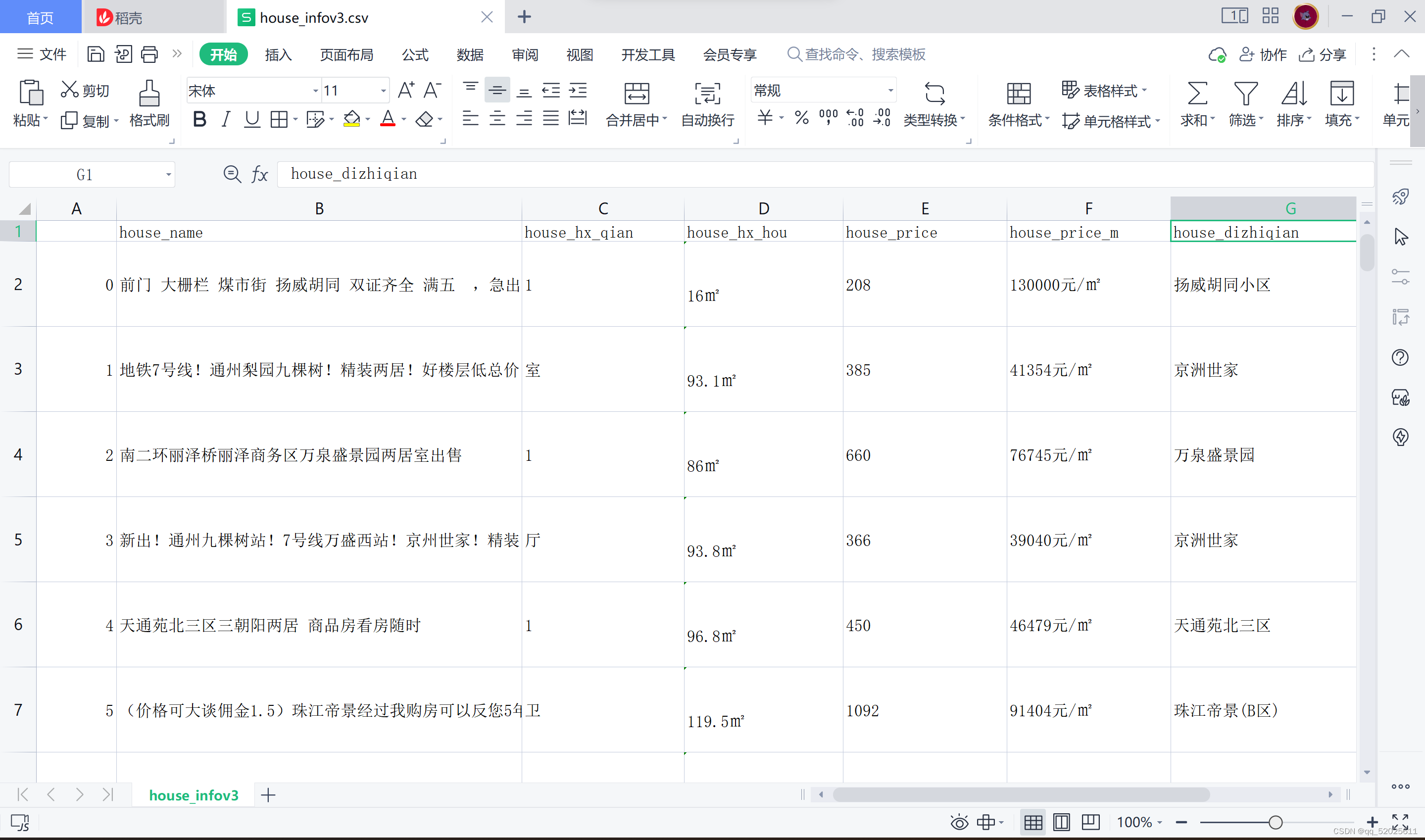
fd = pd.DataFrame.from_dict(house_info,orient='index')
fd = fd.T
fd.to_csv("文件名.csv",header=True)
数据展示















 8603
8603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









