







树模型一直以来都颇受学界和业界的重视。目前无论是各大比赛各种大杀器的 XGBoost、lightgbm还是像随机森林、Adaboost等典型集成学习模型,都是以决策树模型为基础的。传统的经典决策树算法包括ID3算法、C4.5算法以及GBDT的基分类器CART算法.
本篇讲解较为详细,特来分享一下:
ID3算法理论
这里的关键在于如何选择最优特征对数据集进行划分。答案就是信息增益、信息增益比和Gini指数。因为本篇针对的是ID3算法,所以仅对信息增益进行详细的表述。
在讲信息增益之前,这里我们必须先介绍下熵的概念。在信息论里面,熵是一种表示随机变量不确定性的度量方式。若离散随机变量X的概率分布为:
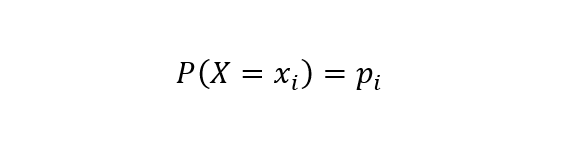
则随机变量X的熵定义为:
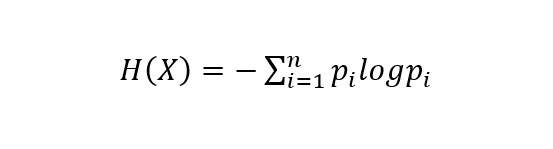
同理,对于连续型随机变量Y,其熵可定义为:
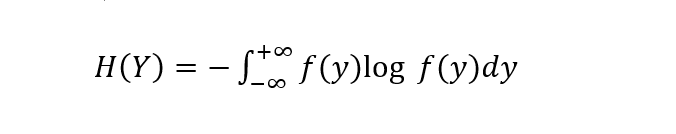
当给定随机变量X的条件下随机变量Y的熵可定义为条件熵H(Y|X):
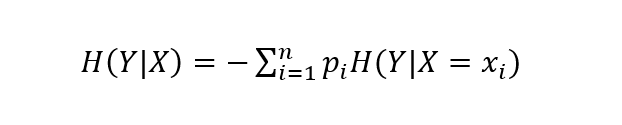
所谓信息增益就是数据在得到特征X的信息时使得类Y的信息不确定性减少的程度。假设数据集D的信息熵为H(D),给定特征A之后的条件熵为H(D|A),则特征A对于数据集的信息增益g(D,A)可表示为:
g(D,A) = H(D) - H(D|A)
信息增益越大,则该特征对数据集确定性贡献越大,表示该特征对数据有较强的分类能力。信息增益的计算示例如下:
1).计算目标特征的信息熵。

2).计算加入某个特征之后的条件熵。
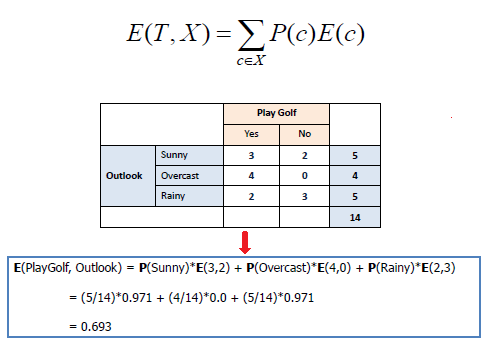
3).计算信息增益。

以上就是ID3算法的核心理论部分
对文章具体内容感兴趣的话,点击下面链接进行阅读:
















 3486
3486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











