







遍历操作
列表遍历

映射遍历(很多)
for循环遍历
for循环+模式匹配

foreach遍历,case样例类来匹配,占位符来匹配(元组的表达方式)
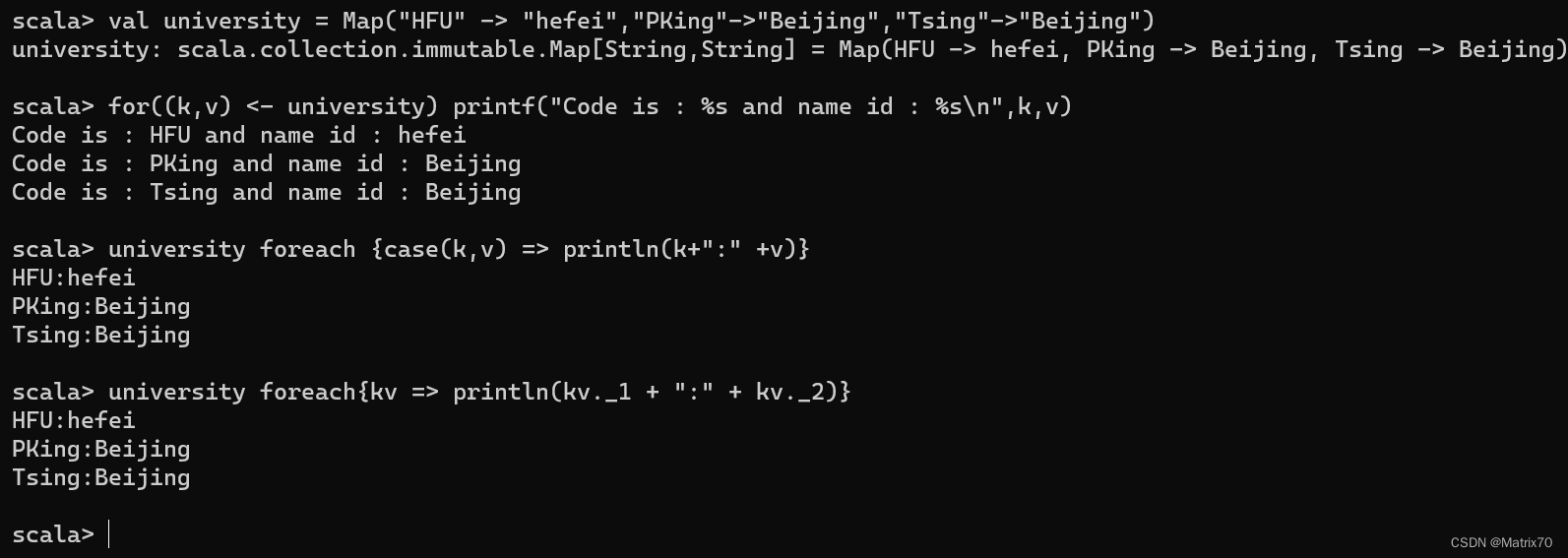
university.foreach{ }
a方法b a.方法(b )
朗母达表达式,匿名函数case模式匹配,kv._1表示匹配的键,kv._2表示的匹配的值,这是元组的表达方式,这些遍历方法都可以去尝试。

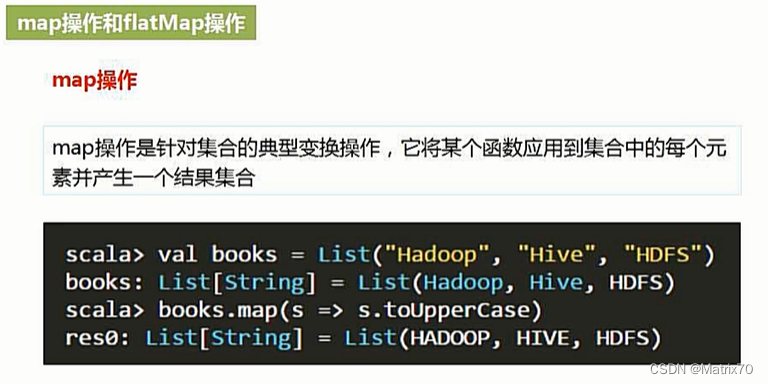
map操作
map非常典型,如下例子,我们调用map函数,对每一个元素依次遍历一遍,
对lambda表达式含义的解释--->遍历到的元素赋值给s,然后让s去执行后续方法,这样就可以一个一个转换掉,此例中,会把值给s,然后执行.toUpperCase方法,然后再遍历,再执行下去.
记住map一定是一一映射,给它几个元素,他就得到几个元素。
![]()
flatMap操作
flatMap函数与map不一样,它将原来单个的元素,经过flatMap后,就变成多个元素了。
为什么叫flatMap呢?
:flat在中文中意思是扁平,就相当于把一罐元素拍扁了,出来许多元素。这些元素就构成了很大的集合,得到非常多的元素构成的整体的集合,就是我们所要的结果。
代码解释:
books flatMap (s => s.toList) ,之前提到的a 方法 b 等价于 a.方法b ,
在这里等价于 books.flatMap(s => s.toList),只是写法不一样
下面的朗母达表达式(s => s.toList),s.toList是将字符串转换成一个列表。把Hadoop给s.toList......对词频统计很重要。

filter操作

1、如上代码,我们定义的是university变量,然后用filter去过滤
university filter {kv => kv._2 contains "Xiamen"} 等价于 university.filter()
给出的 {kv => kv._2 contains "Xiamen"} 是函数的具体值,为一个lambda表达式,含义为传递给filiter方法的参数,传递给filter方法什么样的参数,这个filter就用这个参数去过滤。
同理还可过滤如下

reduce函数归约

1、如上,示例中reduce是一个函数,list.reduceLeft( ) ,括号里面传递给它的一些函数,这里给的函数式 _ + _ , 下划线加下划线 等价于(x => x + y),因为只出现一次啊
然后开始归约求值,从左侧开始归约,默认情况下,

fold操作
fold操作需要给一个初始值,
list.fold(10)(_ * _), _ * _ 等价于 (s => s * y)
10 作为初始的s ,10 * 1,10 * 2, 20 * 3 ,60 * 4,240 *5















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









