







基本运行流程(四步)
SparkContext对象,它代表了应用程序和集群之间的连接通道
 SparkContext
SparkContext
在解释器中,当我们进入spark-shell时,SparkContext的sc对象是系统自动创建的,可以通过sc对象访问。如果独立编程我们自己创建new一个
资源管理器
yarn,mesos,Spark自带的都行
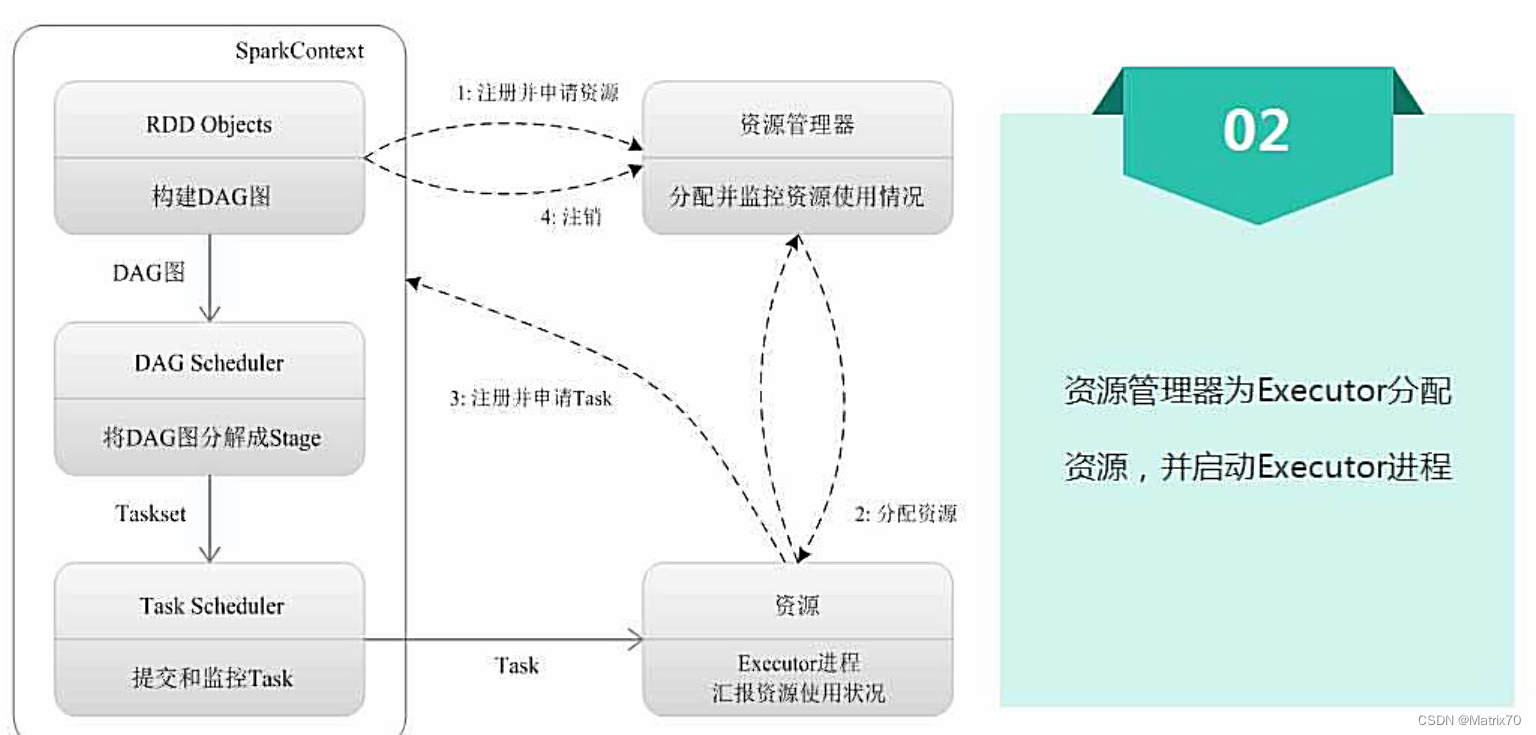
第三步,关键的一步
部分代码都是一次次对RDD的操作,比如我们平台的算子
划分Stage
TaskScheduler使用计算向数据靠拢原则,分配任务,因为移动计算比移动数据更好用!把任务发配到数据所在的机器即把代码在对应的Executor上.

第四步

Spark运行架构特点
系统会自动分配Executor进程的,并且多线程,启动时间快,以线程启动开销小
数据本地性:分发任务时,优先把任务扔到数据所在的地方,让数据本地,不需要来回的跨机器传输数据。
推测执行:数据在机器1上,但机器1已经满了,任务来了那怎么办,是等着还是转移呢,他自己衡量优劣
















 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









