







启动Spark集群
先启动hadoop,再启动Spark,具体参考链接
对Linux系统对Spark开发环境配置_Matrix70的博客-CSDN博客
运行Spark安装好以后自带的样例程序SparkPi
spark-submit --class org.apache.spark.examples.SparkPi
--master spark://master:7077 examples/jars/spark-examples_2.12-3.2.0.jar
100 2>&1 | grep "Pi is roughly"
运行结果:

在独立集群中运行spark-shell
创建测试文件testspark
#在/opt下新建一个文件testspark,滚键盘
vi testspark
#上传此文件至hadoop文件系统根目录
hadoop fs -put /opt/testspark /
#查看文件
hadoop fs -ls /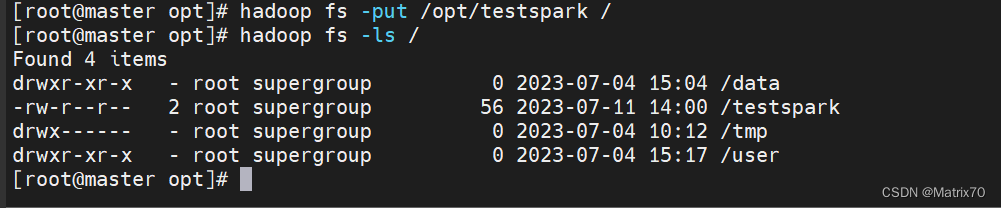
启动spark-shell
#进入bin
cd /usr/local/spark/bin/
#bin目录下启动spark-shell
spark-shell --master spark://master:7077
输入代码进行测试
#读文件
val textFile = sc.textFile("hdfs://master:9000/README.md")
#统计一下
textFile.count()
#查看
textFile.first()
独立集群管理Web界面查看应用的运行情况
浏览器进入下述链接















 2543
2543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









