








两个数组的交集

难度 简单 题目链接
这道题的难度不大,我们可以把数组里的数据存到set里面。这样就完成了排序和去重,然后我们再把一个set里面的数据和另外一个set数据进行比较。如果相同就插入到数组里。
代码如下:
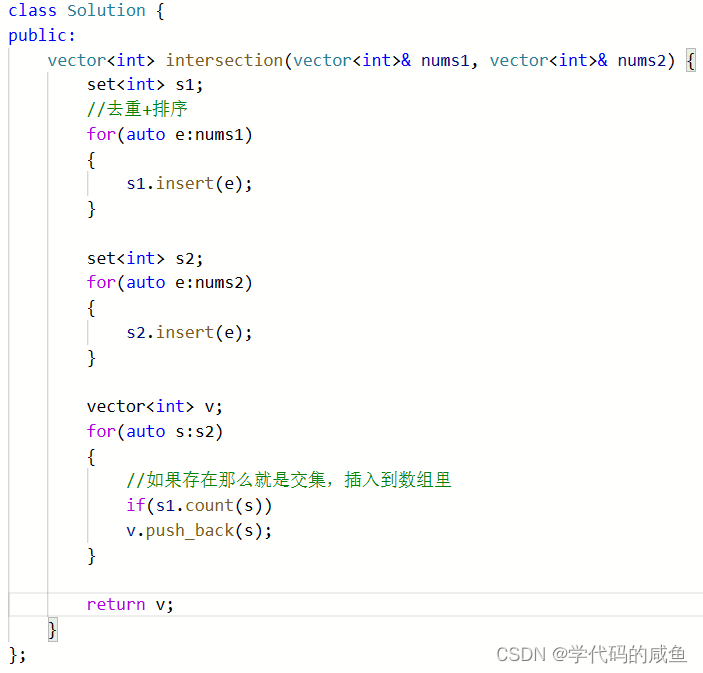
但是这个算法的时间复杂度为O(N*logN),我们有什么办法改进一下呢?
两个数组里面的元素相比较,小的++,相等就是交集,然后同时++。
大致思路:
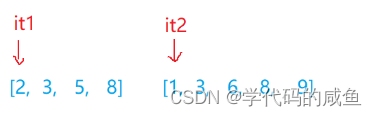
根据上面的思路,1<2那么it2++。

2<3it1++。

此时it1和it2相等,那么就同时++,当某一个数组结束,交集就找完了。
代码如下:
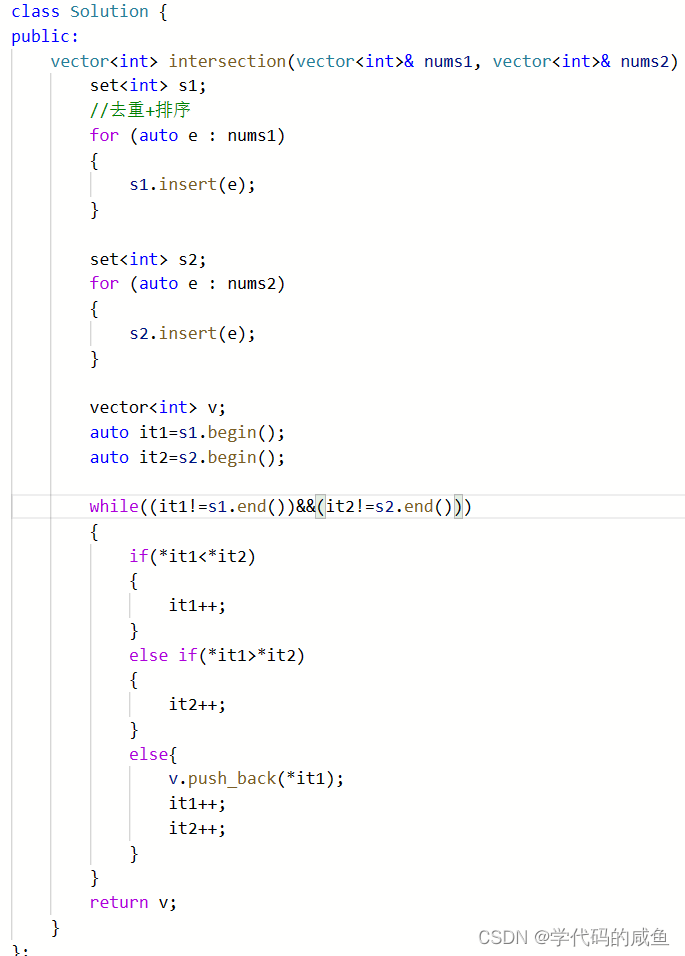
这个时间复杂度是O(N)。如果我们想求差集,方法是:相比较,小的就是差集,然后小的++。如果相等了,就同时++。
前K个高频单词

难度 中等 题目链接
方法一
首先,我们把words里面的单词个数统计一下:

因为map里面是按照key(string)排序,但我们需要按照次数排序。
但在标准库里面sort:

要传随机迭代器,map是双向迭代器,所以不能直接传。
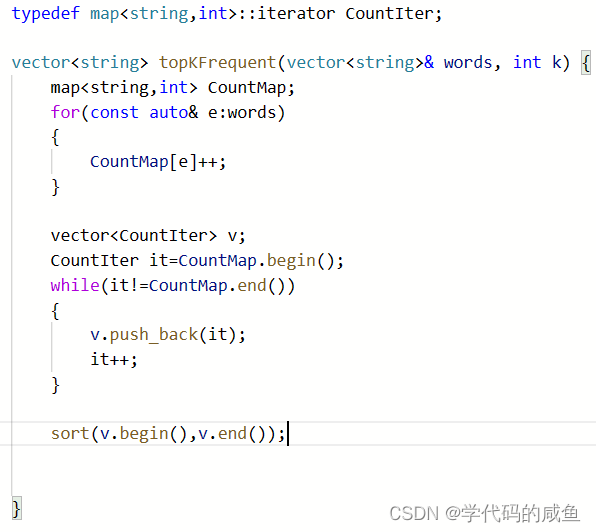
这里数组迭代器解引用后是map迭代器,迭代器不支持排序。所以我们需要写仿函数来让里面的迭代器按照次数来排序:
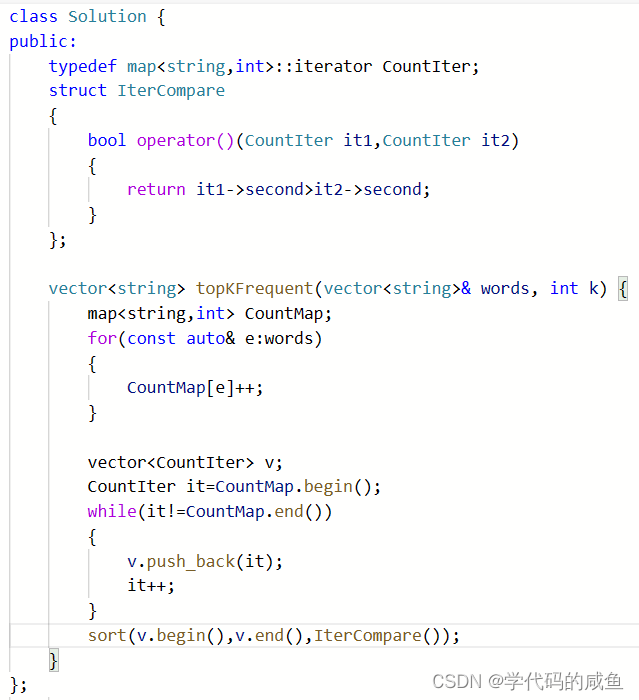
但是还是存在一些问题:因为题目上还要求了,如果不同的单词有相同出现频率, 按字典顺序排序。但是标准库里面sort是不稳定的:

可能让某些小的单词放在前面。所以标准库里面还提供了稳定的排序:stable_sort。最后,我们再把前k个单词找出来就行了:

其实如果我们不使用stable_sort,我们可以在仿函数比较的时候加上一些条件:

意思就是如果次数相同,就比较它们的ASCII码。
方法二
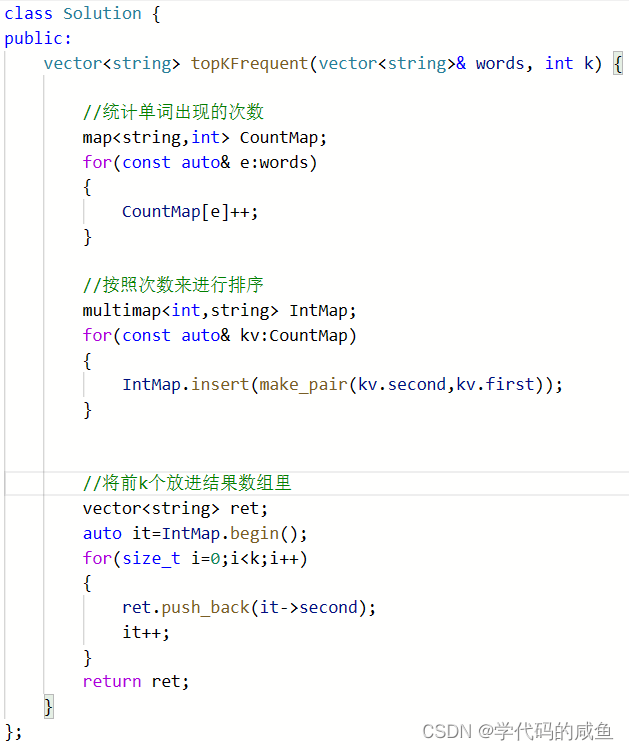
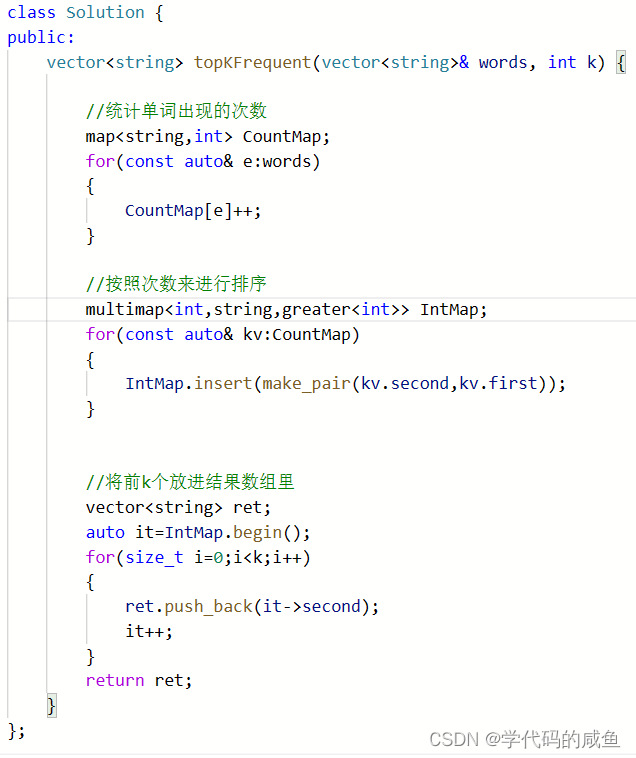
方法二并不采用sort来排序,而是采用multimap来排序。但是这里还不行,因为multimap默认是升序,而我们要降序的方式。
















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











