






运行项目,可以看到警告信息

修改主路由和子路由(斜杠加在主路由路径的尾巴上)

再次运行项目,看看还有没有讨厌的警告信息

(一)删除数据
删除数据有3种方式:删除数据表的全部数据、删除一行数据和删除多行数据.
1、删除全部数据:all()与delete()
查看commodity_types表(14条记录)

导出数据库脚本 - babies.sql

在终端Shell模式下执行命令:Types.objects.all().delete(),删除全部记录

查看commodity_types表
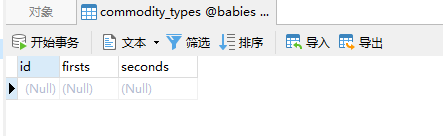
2、删除一行数据:get()与delete()
导入数据有两种方式:一种是运行SQL脚本,一种是使用loaddata命令
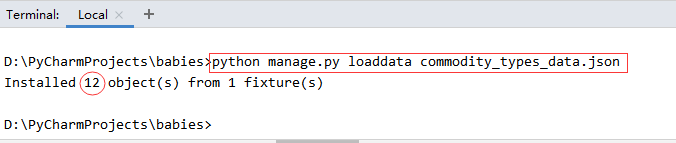
导入数据到表:python manage.py loaddata commodity_types_data.json

要将数据文件改成不带BOM的UTF-8编码格式

重新导入数据到表:python manage.py loaddata commodity_types_data.json
查看commodity_types表

在终端Shell模式下执行命令:Types.objects.get(id=1).delete(),删除id为1的记录

查看commodity_types表

3、删除多行数据:filter()与delete()

在终端Shell模式下执行命令:Types.objects.filter(firsts=‘儿童用品’).delete(),
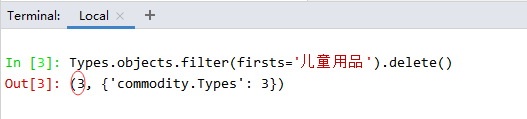
删除了3条记录,查看commodity_types表

4、删除有外键的数据:delete()
删除数据的过程中,如果删除的数据设有外键字段,就会同时删除外键关联的数据。
(1)准备模型和表
在index模块的models.py中定义以下2个模型类

第22行定义了name为外键,关联的是PeronInfo对象,而且是级联删除。从模型 Vocation 得知,外键字段的参数 on_delete 用于设置数据删除模式,比如模型 Vocation的外键字段name设为CASCADE模式,不同的删除模式会影响数据删除结果,说明如下:
– PROTECT 模式:如果删除的数据设有外键字段并且关联其他数据表的数据,就提示数据删除失败。
– SET_NULL模式:执行数据删除并把其他数据表的外键字段设为Null,外键字段必须将属性 Null 设为 True,否则提示异常。
– SET_DEFAULT 模式:执行数据删除并把其他数据表的外键字段设为默认值。
– SET 模式:执行数据删除并把其他数据表的外键字段关联其他数据。
– DO_NOTHING 模式,不做任何处理,删除结果由数据库的删除模式决定。
在终端执行数据迁移命令:python manage.py makemigrations,生成数据迁移文件

在终端执行数据迁移命令:python manage.py migrate index 0001_initial,生成相应的数据表

查看生成的两张表:index_personinfo和index_vocation

(2)为index_personinfo准备测试数据
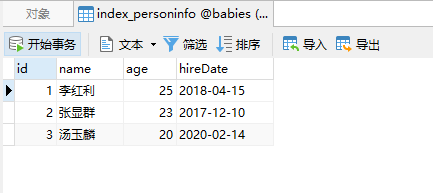
利用批量添加数据命令,添加三条记录

查看index_personinfo表
(3)为index_vocation准备测试数据
给“李红利”设置职业

使用select_related()实现关联查询
1、利用PersonInfo关联查询Vocation
查询人员姓名及薪资(姓名来自PersonInfo对象,薪资来自Vocation对象),对应逆向查询

不妨查看一下框架帮我们生成的关联查询语句
SELECT index_personinfo.name, index_vocation.payment FROM index_personinfo LEFT OUTER JOIN index_vocation ON (index_personinfo.id = index_vocation.name_id)

到Navicat里去运行上面的查询语句(采用的是左外连接)

多表关联查询 - select_related()
1、准备三个模型
在index的models.py里添加三个模型类

说明:Person通过city外键关联City,City通过province外键关联Province,删除都采用级联模式on_delete=models.CASCADE
在控制台执行数据迁移命令,生成数据迁移文件

针对上述数据迁移文件执行迁移命令,生成相应的数据表

在Navicat里查看刚刚通过迁移生成的数据表

2、在三张表里添加数据
给index_province表添加记录

给index_city表添加记录

给index_person表添加记录

3、多表查询
我们可以使用select_related()和get()来实现三表关联查询
查询“李文丽”所在城市与省份

说明:select_related()函数的参数值为city__province,其中city是Person模型的外键字段,该字段指向City模型;province是City模型的外键字段,该字段指向Province模型。 两个外键字段之间使用双下划线连接。在查询过程中,Person模型的外键字段 city指向City模型,再从City模型的外键字段province指向Province模型,从而实现三张表的关联查询。以此类推,可以实现三张以上的表的关联查询。
(七)多表关联查询 - prefetch_related()
prefetch_related 和 select_related 的设计目的很相似,都是为了减少 SQL查询的次数,但 是实现的方式不一样。select_related 是由SQL的JOIN 语句实现的,但是对于多对多关系,使 用select_related会增加数据查询时间和内存占用;而prefetch_related是分别查询每张数据表, 然后由 Python语法来处理它们之间的关系,因此对于多对多关系的查询,prefetch_related更有优势。
1、准备两个模型
在index的models.py里添加两个模型

表演者Performer和节目Program是多对多关系,通过Program中的models.ManyToManyField体现出来。
2、做数据迁移,生成三张数据表
执行python manage.py makemigrations,生成迁移文件

执行python manage.py migrate index 0003_performer_program,生成数据表

在Navicat里去查看刚才生成的数据表

说明:自动生成了index_performer表和index_program表,同时还生成了多对多的中间表index_program_performer表,其表结构如下图所示。

3、准备数据
给index_performer表添加数据

给index_program表添加数据

给index_program_performer表添加数据

3、使用prefetch_related()实现关联查询
查询“我爱你中国”节目有哪些表演者参加

查询“李文丽”参加的节目

4、小结两种关联查询
从上述例子看到,prefetch_related 的使用与 select_related 有一定的相似之处。如果是查询一对多关系的数据信息,那么两者皆可实现,但select_related 的查询效率更佳。如果是查询多对多关系的数据信息,就只能使用prefetch_related()函数才实现,使用select_related()函数要报错。
(八)原生SQL查询
Django在查询数据时,大多数查询都能使用ORM 提供的API方法,但对于一些复杂的查询可能难以使用ORM的 API方法实现,因此 Django引入了SQL 语句的执行方法,有以下3种实现方法。
extra:结果集修改器,一种提供额外查询参数的机制。
raw:执行原始SQL并返回模型实例对象。
execute:直接执行自定义SQL语句。
1、extra查询
(1)extra查询概述
extra 适合用于ORM难以实现的查询条件,将查询条件使用原生 SQL 语法实现,此方法需要依靠模型对象,在某程度上可防止 SQL 注入。extra共定义了 6 个参数,每个参数说明如下:
select:添加新的查询字段,即新增并定义模型之外的字段。
select_params:如果 select 设置字符串格式化%s,那么该参数为 select 提供数值。
where:设置查询条件。
params:如果 where 设置了字符串格式化%s,那么该参数为 where 提供数值。
tables:连接其他数据表,实现多表查询。
order_by:设置数据的排序方式。
(2)extra查询实例
任务:针对职业表,查询“软件开发”的记录
旧的方法:

新的方法:

针对职业表,查询“软件开发”的薪资在10000以上的记录
使用extra()函数实现

使用filter()函数实现

针对职业表的查询,添加一个查询字段“country”,值都是“中国”

针对职业表,按薪资(payment)降序查询全部记录

针对职业表,先按工作(job)降序排列,再按薪资(payment)升序排列,查询全部记录

关联职业表与人员信息表进行查询

上面的记录有重复,去重显示

2、raw查询
(1)raw查询概述
raw和extra所实现的功能是相同的,只能实现数据查询操作,并且也要依靠模型对象,但从使用角度来说,raw更为直观易懂。raw一共定义了 4 个参数,每个参数说明如下:
raw_query:SQL 语句。
params:如果 raw_query 设置字符串格式化%s,那么该参数为 raw_query 提供数值。
translations:为查询的字段设置别名。
using:数据库对象,即 Django 所连接的数据库。
(2)raw查询实例
查询职业表全部记录

查询职业表“软件开发”的记录
方法一:利用raw_query参数搞定

方法二:利用raw_query与params参数搞定(注意params参数值必须是列表)

查询职业表“软件开发”记录,显示id字段(主键不能取别名),显示job字段,别名“工作”,显示payment字段,别名“薪资”

方法一、利用as关键字来给查询字段指定别名

虽然指定了别名,但还是可以用原来的字段名来访问

方法二、利用translations参数给查询字段指定别名

3、execute查询
(1)execute查询概述
以游标的方式获取数据,通过游标去查询和获取数据。execute 能够执行所有的 SQL 语句,但很容易受到 SQL 注入攻击,一般情况下不建议使用这种方式实现数据操作。尽管如此,它能补全 ORM 框架所缺失的功能,如执行数据库的存储过程。
(2)execute查询实例
通过游标查询职业表全部记录

通过游标查询指标薪资在10000以上的软件开发的记录
















 9021
9021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









