







Datawhale打卡活动 Kaggle Spaceship Titanic
尝试了一个coggle科学的打卡活动(Coggle 30 Days of ML(22年10月)),记录一下学习过程!
Day6 高阶树模型
步骤1:安装LightGBM,并学习基础的使用方法;
LGB简介
LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。由于前面的代码已经使用到了lgb,所以安装步骤这里省略(直接pip,不懂的可以查一查lgb的安装方法)。
LGB主要参数
详情见:LightGBM中文文档
核心参数
**boosting:**也就是boost,默认值为gbdt,除此之外还有rf、dart、doss,但是gbdt效果较为稳定。
**num_thread:**也就是nthread,用来指定线程个数。
**application:**默认为regression,也称objective,app,这里指的是任务目标。
-
regression
- regression_l2, L2 loss, alias=regression, mean_squared_error, mse
- regression_l1, L1 loss, alias=mean_absolute_error, ma
- huber, Huber loss
- fair, Fair loss
- poisson, Poisson regression
- quantile, Quantile regressionquantile_l2, 类似于 quantile, 但是使用了 L2 loss
-
binary, binary log loss classification application
-
multi-class classification
- multiclass, softmax 目标函数, 应该设置好num_class
- `multiclassova, One-vs-All 二分类目标函数, 应该设置好 num_class
-
cross-entropy application
- xentropy, 目标函数为 cross-entropy (同时有可选择的线性权重), alias=cross_entropy
- xentlambda, 替代参数化的 cross-entropy, alias=cross_entropy_lambda
- 标签是 [0, 1] 间隔内的任意值
-
lambdarank, lambdarank application
- 在 lambdarank 任务中标签应该为 int type, 数值越大代表相关性越高 (e.g. 0:bad, 1:fair, 2:good, 3:perfect)
- label_gain` 可以被用来设置 int 标签的增益 (权重)
**valid:**验证集选用,也称test,valid_data, test_data.支持多验证集,以,分割
**learning_rate:**也称shrinkage_rate,梯度下降的步长。默认设置成0.1,我们一般设置成0.05-0.2之间
**num_leaves:**也称num_leaf,新版lgb将这个默认值改成31,这代表的是一棵树上的叶子数
**device:**default=cpu, options=cpu, gpu
- 为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度
- Note: 建议使用较小的 max_bin (e.g. 63) 来获得更快的速度
- Note: 为了加快学习速度, GPU 默认使用32位浮点数来求和. 你可以设置 gpu_use_dp=true 来启用64位浮点数, 但是它会使训练速度降低
- Note: 请参考 安装指南 来构建 GPU 版本
步骤2:将训练集20%划分为验证集,使用LightGBM完成训练,精度是否有提高?
对于此步骤,划分验证集,我们选用sklearn中的train_test_split
from sklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test =train_test_split(x_train,label,test_size=0.2, random_state=42)
训练之后线下的效果如下:

步骤3:将步骤2预测的结果文件提交到比赛,截图分数;
进入kaggle中的比赛界面,由于预测出来的是为1的概率,但是提交的为True/False,于是我们设置了阈值(0.5),然后提交结果。
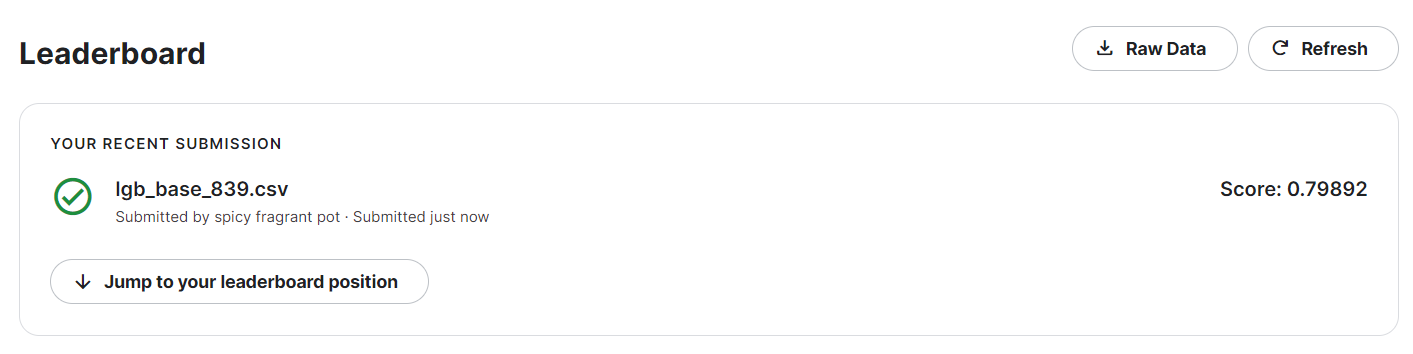
步骤4:尝试调节搜索LightGBM的参数;
这里在网上找了一份代码(使用gridsearch):
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import GridSearchCV # Perforing grid search
from sklearn.model_selection import train_test_split
train = lgb.Dataset(X_train, label=y_train)
valid = lgb.Dataset(X_test, label=y_test)
parameters = {
'max_depth': [15, 20, 25, 30, 35],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'feature_fraction': [0.6, 0.7, 0.8, 0.9, 0.95],
'bagging_fraction': [0.6, 0.7, 0.8, 0.9, 0.95],
'bagging_freq': [2, 4, 5, 6, 8],
'lambda_l1': [0, 0.1, 0.4, 0.5, 0.6],
'lambda_l2': [0, 10, 15, 35, 40],
'cat_smooth': [1, 10, 15, 20, 35]
}
gbm = lgb.LGBMClassifier(boosting_type='gbdt',
objective = 'binary',
metric = 'auc',
verbose = 0,
learning_rate = 0.01,
num_leaves = 35,
feature_fraction=0.8,
bagging_fraction= 0.9,
bagging_freq= 8,
lambda_l1= 0.6,
lambda_l2= 0)
# 有了gridsearch我们便不需要fit函数
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='accuracy', cv=3)
gsearch.fit(X_train, y_train)
print("Best score: %0.3f" % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
但是通过上述代码,一直没有跑出来结果,所以开始尝试贝叶斯优化
# bayes_opt
from bayes_opt import BayesianOptimization
from sklearn.model_selection import cross_val_score
import lightgbm as lgb
# 自己处理好train_x, train_y
train_x=X_train
train_y=y_train
# lgb_cv 函数定义了要去调哪些参数,并且使用交叉验证去计算特定指标的值(例子中用的是roc_auc)。
# 实际调参的时候也不可能所有参数一起调整,最好是分批次调参。
# 而且调参的时候可以观察本轮最优参数是否逼近了设定的搜索阈值,下一次调参的时候可以把搜索的范围扩大。
def lgb_cv(n_estimators,min_gain_to_split,subsample, max_depth,colsample_bytree, min_child_samples,reg_alpha,reg_lambda,num_leaves,learning_rate):
model = lgb.LGBMClassifier(boosting_type='gbdt', objective='binary',n_jobs=-1,
colsample_bytree=float(colsample_bytree),
min_child_samples=int(min_child_samples),
n_estimators=int(n_estimators),
num_leaves=int(num_leaves),
reg_alpha=float(reg_alpha),
reg_lambda=float(reg_lambda),
max_depth=int(max_depth),
subsample=float(subsample),
min_gain_to_split = float(min_gain_to_split),
learning_rate=float(learning_rate),
)
cv_score = cross_val_score(model, train_x, train_y, scoring="roc_auc", cv=5).mean()
return cv_score
# 实例化BayesianOptimization类,参数靠自己去定义取值范围
lgb_bo = BayesianOptimization(
lgb_cv,
{
'colsample_bytree': (0.5,1),
'min_child_samples': (2, 200),
'num_leaves': (5, 1000),
'subsample': (0.6, 1),
'max_depth':(2,10),
'n_estimators': (10, 1000),
'reg_alpha':(0,10),
'reg_lambda':(0,10),
'min_gain_to_split':(0,1),
'learning_rate':(0,1)
},
)
# 训练
lgb_bo.maximize()
# 可以输出最优的值以及最优参数等等
print(lgb_bo.max)
步骤5:将步骤4调参之后的模型重新训练,将最新预测的结果文件提交到比赛,截图分数;
经过贝叶斯优化之后线下结果为:

线上结果如下:
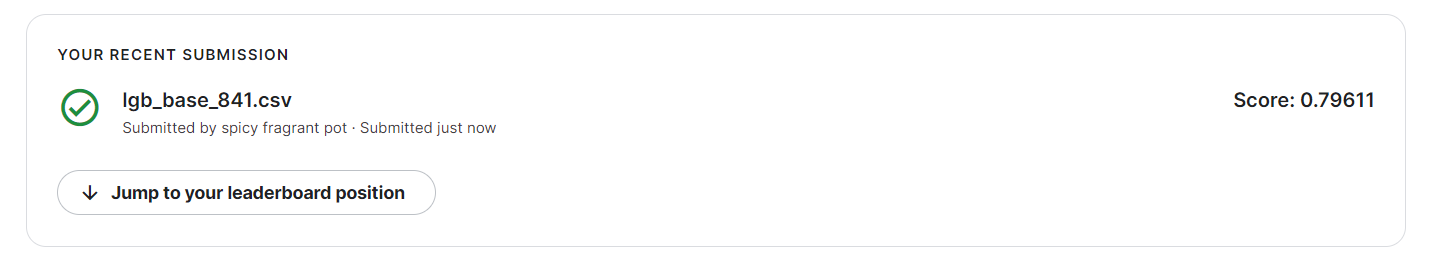
可以发现,虽然线下的效果有所提升,但是线上的效果却有些下降,没找到原因,但是对于调参这一部分一直没有仔细的学习,自动调参或许还是有些问题。在后续的学习中继续完善吧。















 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









