







前言
数据在两设备间的传输称为流,流的本质是数据传输,JAVA根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。在整个Java.io包中最重要的就是5个类和一个接口,5个类指的是File、OutputStream、InputStream、Writer、Reader,一个接口指的是Serializable,掌握了这些IO的核心操作那么对于Java中的IO体系也就有了一个初步的认识。
一、File类
File类:java.io包中很重要的一个类,File对象代表磁盘中实际存在的文件和目录,可以对文件或目录的属性进行操作,如:文件名、最后修改日期、文件 大小等。但不能直接对文件进行读/写操作。
那么要如何使用File类呢?
1.File类的构造方法
1.File(String pathname) 通过将给定的路径名字符串创建File实例。
2.File(String parent, String child) 从父路径名字符串和子路径名字符串创建File实例。
File f1=new File("D:/demo.txt");
File f2=new File("D:/","demo.txt");
2.File类的常用方法:判断方法、获取方法、创建和删除方法等。
boolean exists() 判断文件是否存在,存在返回true,否则返回false
boolean isFile() 判断是否为文件,是文件返回true,否则返回false
boolean isDirectory() 判断是否为目录,是目录返回true,否则返回false
String getName() 获得文件的名称
long length() 获得文件的长度(字节数)
boolean createNewFile() throws IOException 创建新文件,创建成功返回true,否则返回false,有可能抛出 IOException异常,必须捕捉。
boolean delete() 删除文件,删除成功返回true,否则返回false
public String[] list() 将目录下的子目录及文件的名字,返回到String数组中
public File[] listFiles() 将目录下的子目录及文件的实例返回到File数组中
public class FileDemo1 {
public static void main(String[] args){
File f1=new File("D:/demo.txt");
File f2=new File("D:/","demo.txt");
System.out.println(f1.canRead());
System.out.println(f1.exists());
System.out.println(f1.isFile());
System.out.println(f1.isDirectory());
System.out.println(f1.length());
System.out.println(f1.getAbsolutePath());
System.out.println(f1.getParent());
System.out.println(f1.getName());
System.out.println(new Date(f1.lastModified()));
}
}
二、输入及输出的概念
输入:把硬盘上的数据读到程序中,即数据的read操作。
输出:从程序往外部设备写数据,即数据的write操作。
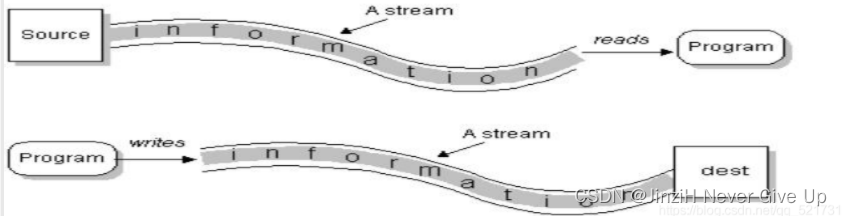

三、流的体系结构
流的概念:数据在两设备间的传输称为流,流的本质是数据传输。Java中将输入输出抽象称为流,就好像水管,将两个容器连接起来。
流按数据的传输方向可以分为:输入流和输出流。
1.输入流:把外界(键盘、文件、网络)的数据读入到程序中。
2.输入流:把程序中的数据输出到外界(显示器、打印机、文件、网络)。
流按数据的编码格式又可以分为:字节流和字符流。
1.字节流:读写二进制文件,处理单元为1个字节,主要处理音频、图片、歌曲。
2.字符流:主要处理字符或字符串,处理单位为1个字符。

四、字节流与字符流与转换流
1. 字节流:数据流中最小的数据单元是字节,常用类FileInputStream和FileOutputStream。
2. 字符流:数据流中最小的数据单元是字符, Java中的字符是Unicode编码,一个字符占用两个字节。常用类为FileReader和FileWriter。
字节流和字符流的区别:
1 读写单位不同:
字节流以字节(8bit)为单位,字符流以字符为单位。
2.处理对象不同:
字节流能处理所有类型的数据(如图片、视频等)
字符流只能处理字符类型的数据。
3.结论:只要是处理纯文本数据,就优先考虑使用字符流。除此之外都使用字节流。
转换流的特点:字符流和字节流之间的桥梁。
1.对读取到的字节数据经过指定编码转换成字符。
2.对读取到的字符数据经过指定编码转换成字节。
InputStreamReader(InputStream in):将字节流以字符流输入。
OutputStreamWriter(OutStream out):将字节流以字符流输出。
何时使用转换流?
1.当字节和字符之间有转换动作时。
2.流操作的数据需要编码或解码时。
五、输入输出字节流
1.InputStream:字节输入流,用来将文件中的数据读取到java程序中,最常用的子类FileInputStream。
FileInputStream类的常用方法如下:
1.abstract int read() :
读取一个字节数据,并返回读到的数据,如果返回-1,表示读到了输入流的末尾。
2.int read(byte[]b) :
将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。
3.int read(byte[]b, int off, int len) :
将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。
off指定在数组b中存放数据的起始偏移位置;len指定读取的最大字节数。
4.流结束的判断:方法read()的返回值为-1时;readLine()的返回值为null时。
2.OutputStream:字节输出流,用来将程序中的数据输出到文件中,最常用的子类FileOutputStream。
FileOutputStream的常用方法:
1.abstract void write(int b):
往输出流中写入一个字节。
2.void write(byte[] b)
往输出流中写入数组b中的所有字节。
3.void write(byte[] b, int off, int len)
往输出流中写入数组b中从偏移量off开始的len个字节的数据。
其它方法
void flush() :刷新输出流,强制缓冲区中的输出字节被写出。
void close() :关闭输出流,释放和这个流相关的系统资源。
关于输入输出字节流的代码如下所示,代码较长,建议结合文字观看。
public class StreamDemo2 {
public static void main(String[] args) {
FileInputStream in=null;
FileOutputStream out=null;
//首先我们告诉java输入流去读写计算机哪个文件
try {
in=new FileInputStream("D:/demo.txt");
out=new FileOutputStream("D:/test.txt");
int b;
while((b=in.read())!=-1){ //从该输入流读取一个字节的数据。
out.write(b);
}
} catch (FileNotFoundException e) { //
e.printStackTrace();
} catch (IOException e) { //读写文件时可能会有异常
e.printStackTrace();
}
finally {
if(in!=null){
try {
in.close(); //关闭流,撤销管道,供其他使用
} catch (IOException e) { //关闭流时可能会发生异常
e.printStackTrace();
}
}
if(out!=null){
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
public class StreamDemo3 {
public static void main(String[] args) {
FileInputStream in=null;
FileOutputStream out=null;
try {
//先告诉计算机要去读写哪个文件
in=new FileInputStream("D:/demo.txt");
out=new FileOutputStream("D:/test.txt");
byte[]b=new byte[1024]; //定义一个数组用来存储读入的数据
int length=0; //记录每次读取实际的个数
while((length=in.read(b))!=-1){ //当读到结尾时返回-1
out.write(b,0,length); //将 len字节从位于偏移量 off的指定 byte阵列写入此输出流。
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in!=null){
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(out!=null){
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
六、输入输出字符流
1.Reader:字符输入流,其常用的子类为FileReader。
2.Writer:字符输出流,其常用的子类为FileWriter。
public class CharDemo1 {
public static void main(String[] args) {
try {
FileReader f1=new FileReader("D:/1.txt");
BufferedReader b1=new BufferedReader(f1);
//构造一个FileWriter对象,给出一个带有布尔值的文件名,表示是否附加写入的数据。
FileWriter f2=new FileWriter("D:/2.txt",true); //往后面追加
BufferedWriter b2=new BufferedWriter(f2);
/* char[]b=new char[5];
int length=0;
while((length=b1.read(b))!=-1){ //读取一个字符并以整数的形式返回, 如果返回-1已到输入流的末尾
b2.write(b,0,length);
}*/
String line=null;
while((line=b1.readLine())!=null){ //每次读入一行,读到结尾时返回null
b2.write(line); //往目标中写入一行
b2.newLine(); //写入一个换行符
}
b1.close();
b2.flush();
b2.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
七、缓冲流
缓冲流:令输入输出流具有1个缓冲区, 显著减少与外部设备的IO次数, 而且提供一些额外的方法,常用的缓冲流有
1.缓冲字节输入流:BufferedInputStream
2.缓冲字节输出流:BufferedOutputStream
3.缓冲字符输入流:BufferedReader
4.缓冲字符输出流:BufferedWriter
缓冲流其高效的原因是什么?
1、BufferedInputStream高效的原理:创建一个较大的byte数组(8192byte),一次性从底层输入流中读取多个字节来填充byte数组,当程序读取一个或多个字节时,可直接从byte数组中获取(在内存中而不是硬盘,所以效率高),当内存中的byte读取完后,会再次用底层输入流填充缓冲区数组。
2、BufferedOutputStream高效的原理:也是准备了一个数组,当外界调用write方法想写出一个字节的时候,将这个字节存储到数组中,一直到该数组所有8192个位置全都占满,才把这个数组中的所有数据一次性写出到目标文件中。如果最后一次循环过程中,没有将数组写满,最终在关闭流对象的时候,也会将该数组中的数据刷新到文件中。
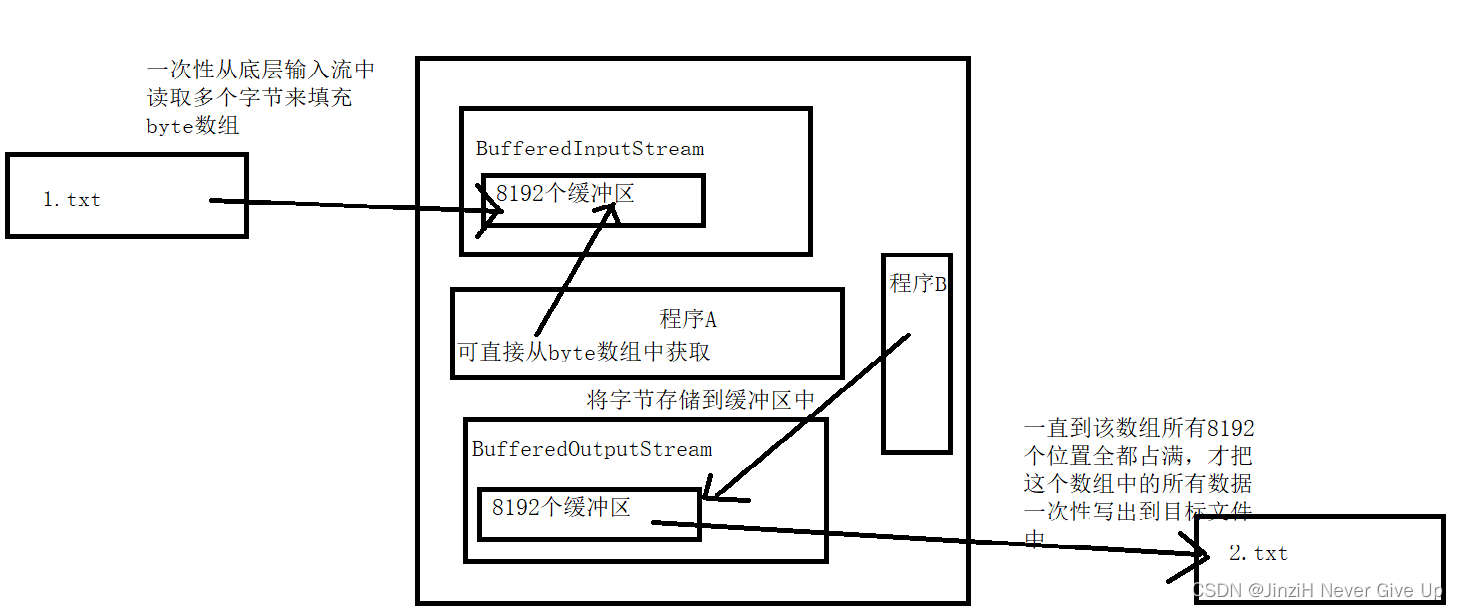
拿缓存输入流举个例子:现在有8192个快递在仓库(硬盘),如果我们一个一个的拿(每读取一个字节就要访问一次硬盘),效率非常的低。即便使用麻袋(read(byte b[]))一次拿多个快递,也会频繁的对磁盘操作。我们可以一次性把8192个快递放到驿站中(利用底层输入流),当我们需要取一个或者多个快递时可直接从驿站(内存,速度快)中获取。
同理,缓存输出流可以理解为:现在要往一个地方发一堆快递,如果一件一件或者拿麻袋发,效率非常低。可以把收到的快递暂时存到一个大卡车(数组缓冲区)上面,等到快递数量到达8192时一次性将快递发送过去(写出到目标文件中)。
关于缓冲流怎么使用如下面代码所示:
public class BufferedDemo1 {
public static void main(String[] args) {
try {
FileInputStream in=new FileInputStream("D:/1.mp3");
//套上一层更高级的管道
BufferedInputStream b1=new BufferedInputStream(in);
FileOutputStream out=new FileOutputStream("D:/2.mp3");
//套上一层更高级的管道
BufferedOutputStream b2=new BufferedOutputStream(out);
/* 里面有个缓冲区,可以自定义大小,默认大小为8192,当缓冲区满时往外写
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}*/
byte[]b=new byte[1024];
int length=0;
while((length=b1.read(b))!=-1){
b2.write(b,0,length);
}
/*public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) { //当传进来的元素个数长度大于缓冲区长度,直接往外写
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer(); //当缓冲区满时调用
}
System.arraycopy(b, off, buf, count, len); //先把数据拷贝到缓冲区中
count += len;
}*/
/* private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count); //往外写数据
count = 0; //重置count
}
}*/
b1.close();
b2.flush();
b2.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
补充:缓冲流实际上是设计模式中装饰模式的一种实现。字节流和字符流,都是装满时自动写出,或者没满时手动flush写出,或close时刷新写出。
八、Print流
Print打印流:只做输出流,没有输入流,可以分为字节打印输出流和字符打印输出流。
public class PrintWriterDemo1 {
public static void main(String[] args) {
try {
//PrintWriter 是字符类型的打印输出流,它继承于Writer。
//将对象的格式表示打印到文本输出流。 这个类实现了全部在发现print种方法PrintStream 。
// 它不包含用于编写原始字节的方法,程序应使用未编码的字节流。
PrintWriter myPrint=new PrintWriter("D:/my.html");
//使用指定的文件创建一个新的PrintWriter,而不需要自动的线路刷新。
myPrint.write("<h1>这是我自己设置的服务器");
myPrint.write("<h1>这是我自己设置的服务器");
myPrint.write("<h1>这是我自己设置的服务器");
myPrint.write("<h1>这是我自己设置的服务器");
myPrint.write("<h1>这是我自己设置的服务器");
myPrint.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
九、对象输入输出流
对象输入输出流:作用是持久化保存对象,用对象输出流保存对象(对象的序列化过程),需要使用时用对象输入流恢复使用(对象的反序列化过程)。
如果需要序列化对象,需要实现生成一个序列化id号,实现Serializable接口后默认生成一个版本号,一旦类中信息发生改变,版本号自动变化,所以可以显性的定义一个版本号。
注意:使用transient关键字加到属性上,可以不把该属性写进序列化文件。
public class ObjectOutputStreamDemo1 {
public static void main(String[] args) {
try {
//要将序列化之后的对象保存下来,需要通过对象输出流(ObjectOutputStream) 将对象状态保存
//对象的输出流将指定的对象写入到文件的过程,就是将对象序列化的过程
FileOutputStream out=new FileOutputStream("D:/myFile.txt");
// Date d=new Date();
ObjectOutputStream myOut=new ObjectOutputStream(out); //处理流封装了一个节点流
// myOut.writeObject(d); //用writeObject()方法可以直接将对象保存到输出流中
Student s1=new Student("金子豪",21);
Student s2=new Student("张三",22);
myOut.writeObject(s1);
myOut.writeObject(s2);
out.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public class ObjectInputStreamDemo1 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//对象 的输入流将指定序列化好的文件读出来的过程,就是对象反序列化的过程
FileInputStream in=new FileInputStream("D:/myFile.txt");
ObjectInputStream myInput=new ObjectInputStream(in);
// Object obj= myInput.readObject(); //readObject()方法可以直接读取一个对象,
/* if(obj instanceof Date){
Date d=(Date)obj; //向下转型,父类转换成子类
System.out.println(d.toString());
}*/
System.out.println(myInput.readObject());
System.out.println(myInput.readObject());
}
}
public class Student implements Serializable {
//如果需要将一个类的对象信息序列化到文件中,需要生成一个序列化id号,
//实现接口后默认生成一个版本号,一旦类中信息发生改变,版本号自动变化
//所以可以显性的定义一个版本号。
private static final long serialVersionUID = -8244863449082098647L;
transient String name; //可以不把该属性写进序列化文件,忽略该属性
int age;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
总结
在Java语言中使用字节流和字符流的步骤基本相同,以输入流为例,首先创建一个与数据源相关的流对象,然后利用流对象的方法从流输入数据,最后执行close()方法关闭流。
















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











