







一、实验目的
掌握关联规则的基本概念,理解Apriori算法的基本思想、算法步骤,用Apriori算法解决实际应用问题。
二、实验原理
①Apriori算法的基本思想:
Apriori算法是一种经典的关联规则挖掘算法,其基本思想是利用频繁项集的性质,逐层地挖掘出频繁项集,并根据频繁项集生成关联规则。该算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递推的方法。
②Apriori算法步骤:
具体来说,Apriori算法的基本流程如下:
扫描数据集,统计每个项的支持度(即在数据集中出现的次数)。
生成频繁1项集(即单个项的集合),也就是支持度不低于最小支持度阈值的项集。
依次生成频繁k+1项集(k>=1),具体步骤如下:
a. 从频繁k项集中生成候选k+1项集,具体方法是将所有包含k个项的项集两两组合,得到长度为k+1的项集,然后去掉不满足Apriori性质的项集。
b. 扫描数据集,统计候选k+1项集的支持度。
c. 生成频繁k+1项集,也就是支持度不低于最小支持度阈值的项集。
根据频繁项集生成关联规则,具体步骤如下:
a. 对于每个频繁项集,找到其所有非空子集,即可得到该项集的所有关联规则。
b. 对于每个关联规则,计算其支持度和置信度(即该规则在条件项出现的条件下,结果项出现的概率),并筛选出满足最小支持度和最小置信度阈值的规则。
Apriori算法的核心思想是利用频繁项集的性质,逐层地挖掘出频繁项集,从而避免了对数据集进行全局搜索,减少了计算量和时间复杂度。
三、实验内容和步骤
- 实验内容1
事务矩阵如表1所示,其中I1、I2、I3......代表项目,T100、T200、T300.......代表事务。为了便于对数据进行处理,首先对数据库中的事务进行一个映射,映射的方法是看每条事务中是否包含项集中的所有元素,如果包含对应的元素,则标记为1,否则为0,这样就可以得到由所有事务组成的0-1矩阵。
请利用Apriori算法,编写程序,设最小支持度为2,得到所有频繁项集。
表1 事务矩阵
| I1 | I2 | I3 | I4 | I5 | |
| T100 | 1 | 1 | 0 | 0 | 1 |
| T200 | 0 | 1 | 0 | 1 | 0 |
| T300 | 0 | 1 | 1 | 0 | 0 |
| T400 | 1 | 1 | 0 | 1 | 0 |
| T500 | 1 | 0 | 1 | 0 | 0 |
| T600 | 0 | 1 | 1 | 0 | 0 |
| T700 | 1 | 0 | 1 | 0 | 0 |
| T800 | 1 | 1 | 1 | 0 | 1 |
| T900 | 1 | 1 | 1 | 0 | 0 |
2.实验内容2
在股市中有一种根据行业选股的投资策略,其基本思想是基于这样的认识:从众多个股中选择具有增长潜力的个股难度较大,但行业数较少,所以选对行业的可能性更高,另外股市通常出现这样的现象,就是同行业的股票往往普涨或普跌,只要选对行业,无论怎么选个股,都可能盈利。有一种基于关联规则挖掘的选股方法-行业关联选股法,其基本思想是:从数据中寻找具有联动关联的行业,当某个行业出现涨势之后,而其关联行业还没有开始涨,则从其关联行业中选择典型个股买入。对于该方法,寻找关联行业是关键,而寻找关联行业,则正好可以用关联规则方法实现。首先我们需要有行业关联数据的事务。在交易系统或公共股票数据中,我们能得到交易日各行业的涨幅数据,但这样的数据不能直接应用,需对数据进行处理。而要定义一个标准,界定哪些行业算是涨势好的行业,比如可以定义10个交易日内,行业涨幅超过大盘涨幅5%的行业为好行业,这样就可以得到类似股市行业关联的事务数据,如表2所示。
请利用Apriori算法,编写程序,设最小支持度为3,得到所有频繁项集。
表2 股票行业关联事务矩阵
| 银行 | 券商 | 钢铁 | 能源 | 医药 | 化工 | |
| T1 | 1 | 1 | 0 | 0 | 1 | 0 |
| T2 | 0 | 0 | 0 | 1 | 0 | 1 |
| T3 | 1 | 1 | 1 | 0 | 0 | 0 |
| T4 | 1 | 1 | 0 | 1 | 0 | 1 |
| T5 | 0 | 0 | 1 | 0 | 1 | 0 |
| T6 | 0 | 1 | 1 | 0 | 0 | 0 |
| T7 | 1 | 0 | 1 | 0 | 0 | 0 |
| T8 | 1 | 1 | 1 | 0 | 1 | 1 |
| T9 | 1 | 1 | 1 | 0 | 0 | 0 |
| T10 | 1 | 1 | 0 | 1 | 0 | 0 |
四、实验过程原始记录(数据、图表、计算、代码等)
实验一,实验二:
实验一主函数:
%% 读取数据
clc, clear all, close all
data = xlsread('c5_data1.xlsx','Sheet1','B2:F10')
%% 调用Apriori算法
disp('频繁项集为:')
apriori(data,2)
实验二主函数:
%% 读取数据
clc, clear all, close all
data = xlsread('c5_data2.xlsx','Sheet1','B2:G11')
%% 调用Apriori算法
disp('频繁项集为:')
apriori(data,3)
function [L]=apriori(D,min_sup)
[L, A]=init(D,min_sup); % 调用init获取初始频繁项集
% A为1-频繁项集,L中为包含1-频繁项集以及对应的支持度
k=1;
C=apriori_gen(A,k); %产生2项的集合
while ~(size(C,1)==0)
[M, C]=get_k_itemset(D,C,min_sup); %产生k-频繁项集 M是带支持度 C不带
if ~(size(M,1)==0)
L=[L;M];
end
k=k+1;
C=apriori_gen(C,k); %产生组合及剪枝后的候选集
end
function [C]=apriori_gen(A,k) %产生Ck(实现组内连接及剪枝 )
%A表示第k-1次的频繁项集 k表示第k-频繁项集
[m,n]=size(A);
C=zeros(0,n);
%组内连接
for i=1:1:m
for j=i+1:1:m
flag=1;
for t=1:1:k-1
if ~(A(i,t)==A(j,t))
flag=0;
break;
end
end
if flag==0
break;
end
c=A(i,:)|A(j,:);
flag=isExit(c,A); %剪枝
if(flag==1)
C=[C;c];
end
end
end
function [L C]=get_k_itemset(D,C,min_sup)
%D为数据集,C为第K次剪枝后的候选集获得第k次的频繁项集
m=size(C,1);
M=zeros(m,1);
t=size(D,1);
i=1;
while i<=m
C(i,:);
H=ones(t,1);
ind=find(C(i,:)==1);
n=size(ind,2);
for j=1:1:n
D(:,ind(j));
H=H&D(:,ind(j));
end
x=sum(H');
if x<min_sup
C(i,:)=[];
M(i)=[];
m=m-1;
else
M(i)=x;
i=i+1;
end
end
L=[C M];
function [L,A]=init(D,min_sup) %D表示数据集,min_sup 最小支持度
[~,n]=size(D);
A=eye(n,n);
B=sum(D,1);
for i=1:n
if B(i)<min_sup
B(i)=[];
A(i,:)=[];
end
end
L=[A B'];
function flag=isExit(c,A)
%判断c串的子串在A中是否存在
[m, n]=size(A);
b=c;
% flag=0;
for i=1:1:n
c=b;
if c(i)==0
continue;
end
c(i)=0;
flag=0;
for j=1:1:m
A(j,:);
a=sum(xor(c,A(j,:)));
if a==0
flag=1;
break;
end
end
if flag==0
return
end
end
五、实验结果及分析(仿真结果等)
实验一:
仿真结果:

频繁项集为:
| I1 | I2 | I3 | I4 | I5 | 支持度 |
| 1 | 0 | 0 | 0 | 0 | 6 |
| 0 | 1 | 0 | 0 | 0 | 7 |
| 0 | 0 | 1 | 0 | 0 | 6 |
| 0 | 0 | 0 | 1 | 0 | 2 |
| 0 | 0 | 0 | 0 | 1 | 2 |
| 1 | 1 | 0 | 0 | 0 | 4 |
| 1 | 0 | 1 | 0 | 0 | 4 |
| 1 | 0 | 0 | 0 | 1 | 2 |
| 0 | 1 | 1 | 0 | 0 | 4 |
| 0 | 1 | 0 | 1 | 0 | 2 |
| 0 | 1 | 0 | 0 | 1 | 2 |
| 1 | 1 | 1 | 0 | 0 | 2 |
| 1 | 1 | 0 | 0 | 1 | 2 |
| 1 | 0 | 1 | 0 | 1 | 2 |
实验二:
仿真结果:

频繁项集为:
| I1 | I2 | I3 | I4 | I5 | I6 | 支持度 |
| 1 | 1 | 0 | 0 | 1 | 0 | 7 |
| 0 | 1 | 0 | 0 | 0 | 0 | 7 |
| 0 | 0 | 1 | 0 | 0 | 0 | 6 |
| 0 | 0 | 0 | 1 | 0 | 0 | 3 |
| 0 | 0 | 0 | 0 | 1 | 0 | 3 |
| 0 | 0 | 0 | 0 | 0 | 1 | 3 |
| 1 | 1 | 0 | 0 | 0 | 0 | 6 |
| 1 | 0 | 1 | 0 | 0 | 0 | 4 |
| 0 | 1 | 1 | 0 | 0 | 0 | 4 |
| 1 | 1 | 1 | 0 | 0 | 0 | 3 |
六、思考题
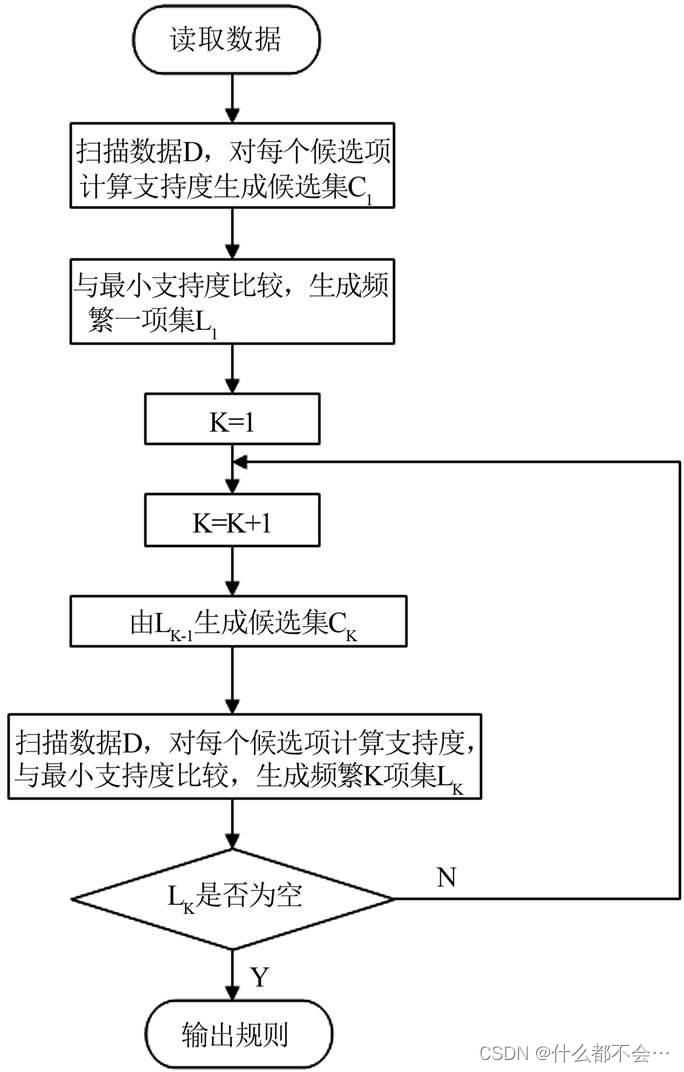
- 在第1个实验内容中,根据实验代码,绘出代码对应的流程图。
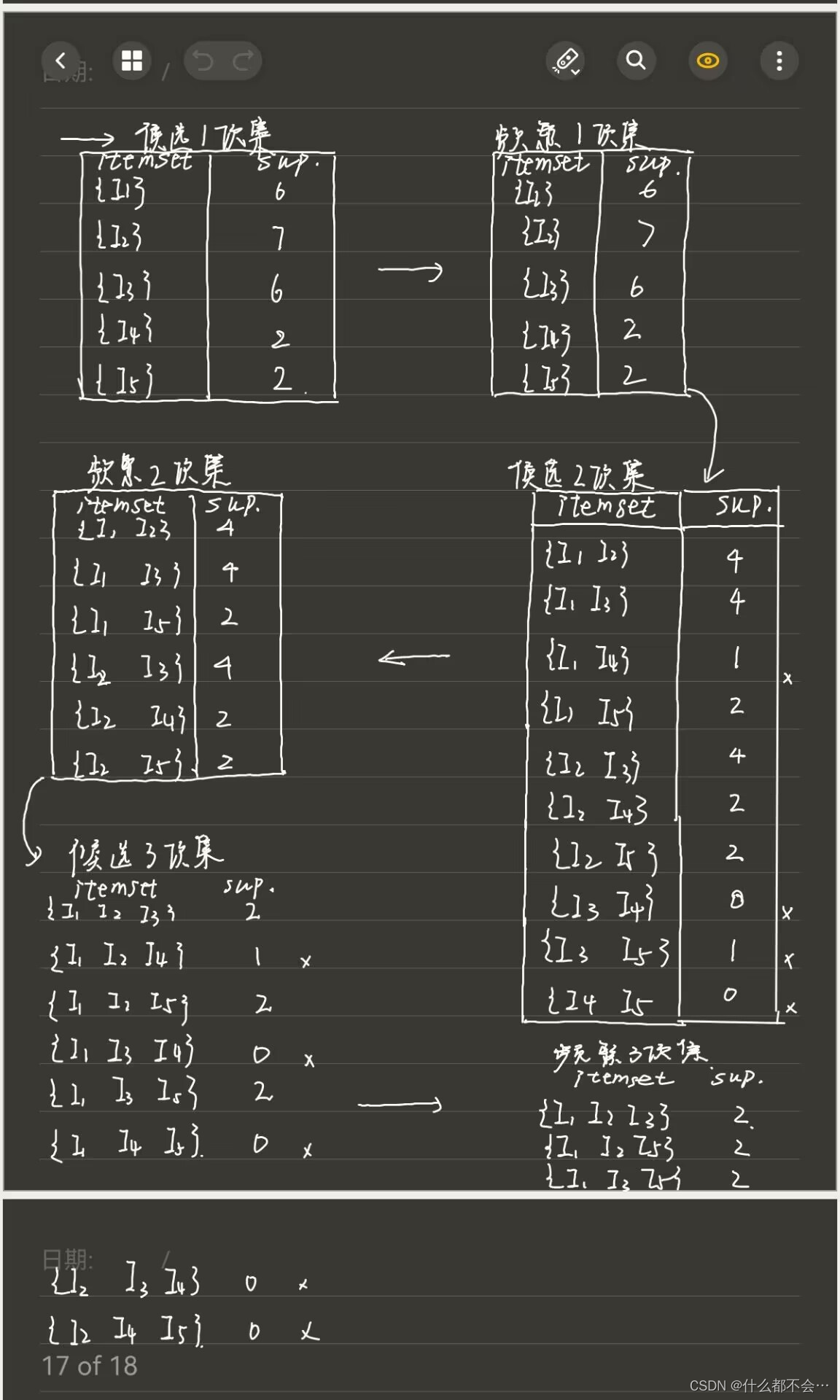
2.设最小支持度为2,列出第1个实验的频繁项集,写出推导过程。
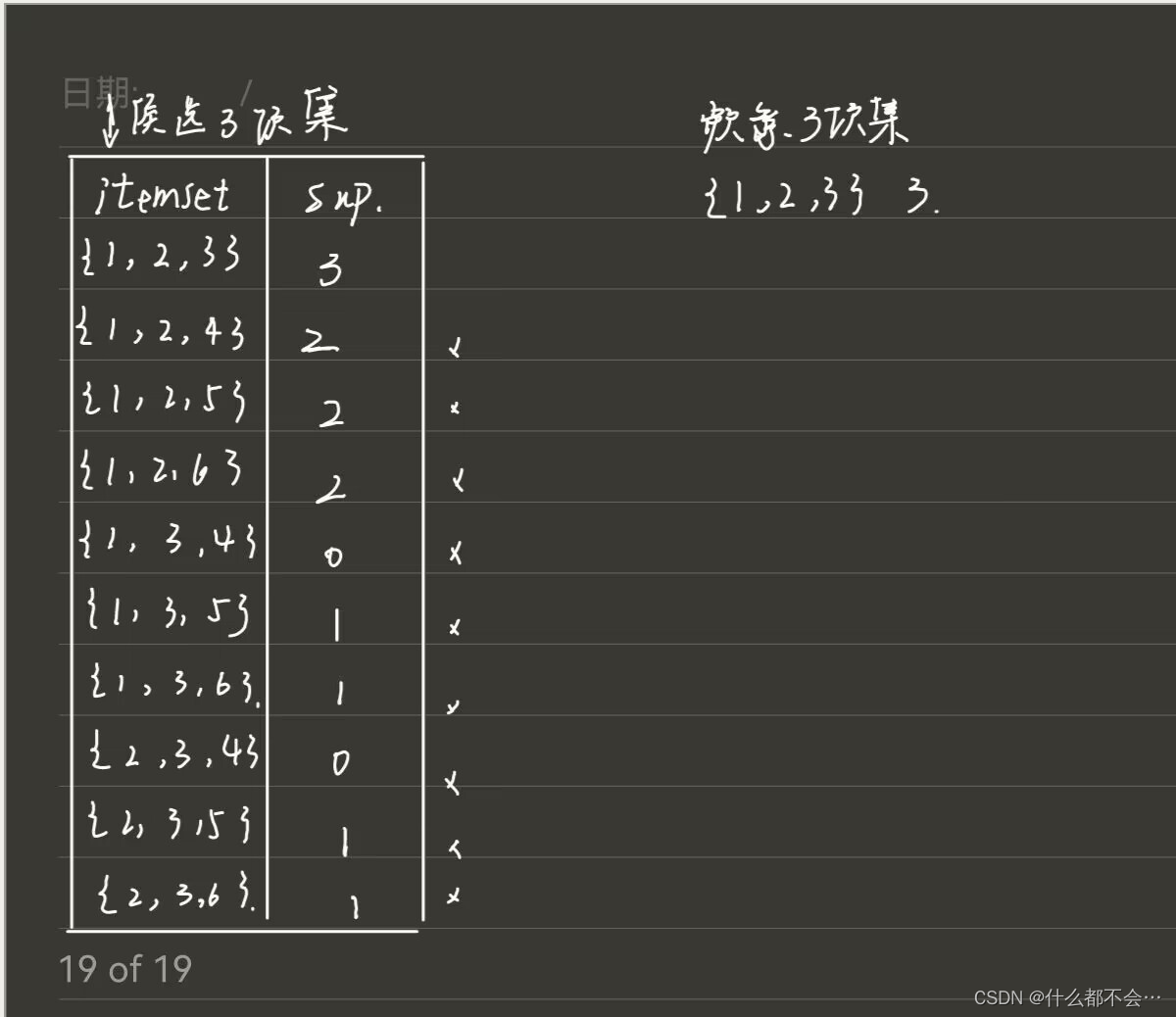
3.设最小支持度为3,列出第2个实验的频繁项集,写出推导过程。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











