







先赞后看,养成习惯!!!❤️ ❤️ ❤️
码字不易,如果喜欢可以关注我哦!
如果本篇学习笔记对你有所启发,欢迎访问我的个人博客了解更多内容:链接地址
Spring是什么
Spring是一个开源Java框架,用于快速开发Java应用程序。它通过提供一组各种功能的库(如IoC、AOP、ORM等)和API简化了Java开发过程,从而提高了开发效率。
Spring 的核心理念是通过依赖注入、面向切面编程和松散耦合等机制,来提供灵活、可扩展、易于维护的企业级应用程序开发框架,这使得Spring应用程序更加灵活、可扩展和易于测试。Spring框架还提供了许多模块,如Spring MVC、Spring Boot、Spring Data等,可以根据需要选择使用。
Spring家族
- Spring能做什么:用以开发web、微服务以及分布式系统等。光这三块就已经占了JavaEE开发的九成多。
- Spring并不是单一的一个技术,而是一个大家族,可以从官网的Projects中查看其包含的所有技术。
- Spring发展到今天已经形成了一种开发的生态圈,Spring提供了若干个项目,每个项目用于完成特定的功能。
- Spring已形成了完整的生态圈。我们可以使用Spring技术完成整个项目的构建、设计与开发。
- Spring有若干个项目。可以根据需要自行选择,把这些个项目组合起来,起了一个名称叫全家桶
- Spring Framework:Spring框架,是Spring中最早最核心的技术,也是所有其他技术的基础。是Spring生态圈中最基础的项目,是其他项目的根基。
- SpringBoot:Spring是来简化开发,而SpringBoot是来帮助Spring在简化的基础上能更快速进行开发。
- SpringCloud:这个是用来做分布式之微服务架构的相关开发。
spring基础
- Spring在市场的占有率与使用率高,未使用Spring的项目一般都是些比较老的项目,大多都处于维护阶段。
- Spring在企业的技术选型命中率高,Spring是微服务架构基础,是传统开发主流技术。所以说,Spring技术是JavaEE开发必备技能
Spring框架主要的优势是在简化开发和框架整合上:
- 简化开发: Spring两大核心技术IOC、AOP。
- 事务处理属于Spring中AOP的具体应用,可以简化项目中的事务管理,也是Spring技术中的一大亮点。
概念:分层的轻量级开源框架,以IOC和AOP为内核,在不同的业务场景中Spring都为我们提供了相应的解决方案
优势:简化开发,降低企业级开发的复杂性
框架整合,正因为企业开发中使用的框架越来越多,无疑提高了项目的复杂度,Spring的出现实现了高效整合其他框架,提高了企业级应用开发与运行效率
- 实现简化开发:Ioc和AOP,事务处理
- 可整合主流框架包括:Mybatis(重点),Mybatis-plus,Struts,Struts2,Hibernate等
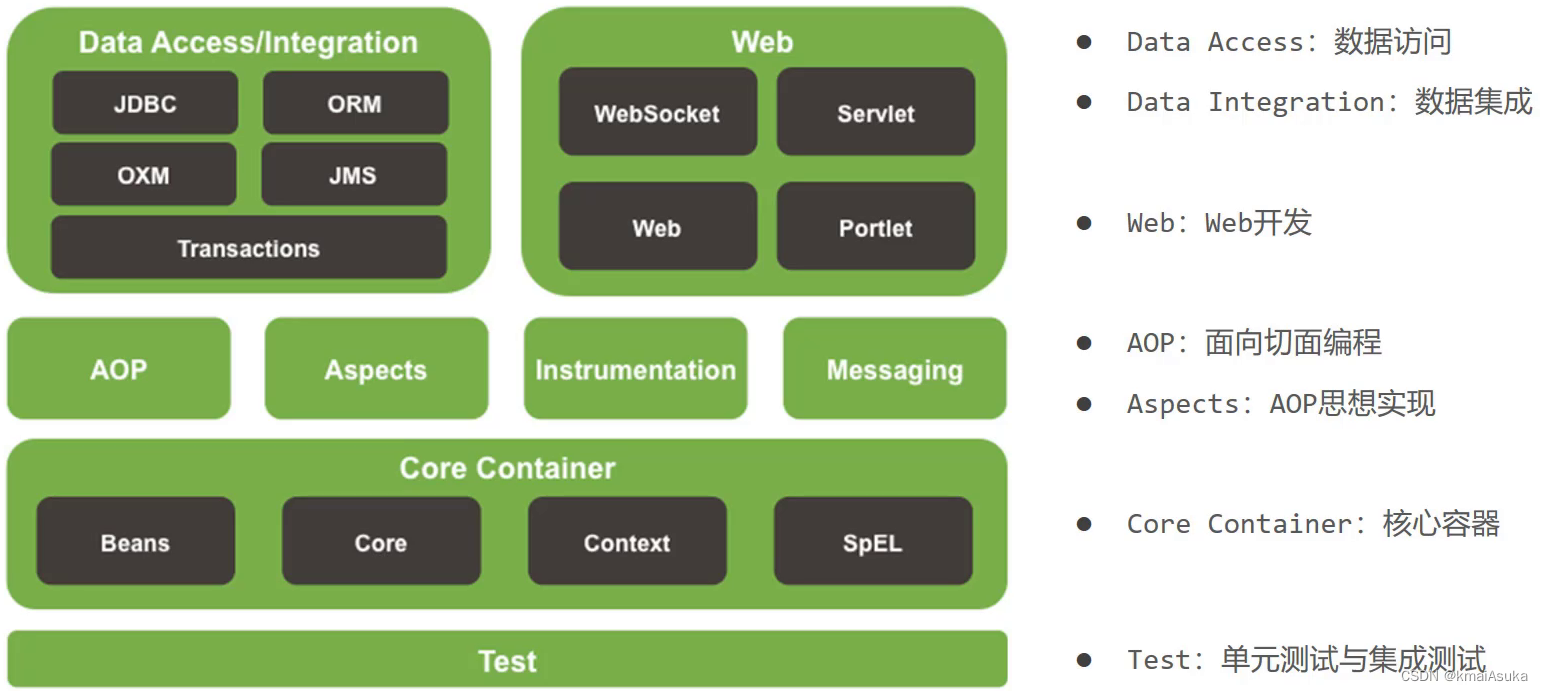
(1)核心层
- Core Container:核心容器,这个模块是Spring最核心的模块,其他的都需要依赖该模块
(2)AOP层
- AOP:面向切面编程,它依赖核心层容器,目的是==在不改变原有代码的前提下对其进行功能增强==
- Aspects:AOP是思想,Aspects是对AOP思想的具体实现
(3)数据层
- Data Access:数据访问,Spring全家桶中有对数据访问的具体实现技术
- Data Integration:数据集成,Spring支持整合其他的数据层解决方案,比如Mybatis
- Transactions:事务,Spring中事务管理是Spring AOP的一个具体实现,也是后期学习的重点内容
(4)Web层
- 这一层的内容将在SpringMVC框架具体学习
(5)Test层
- Spring主要整合了Junit来完成单元测试和集成测试
IOC、IOC容器、Bean、DI
==IOC(Inversion of Control)控制反转==
(1)什么是控制反转呢?
- 使用对象时,由主动new产生对象转换为由==外部==提供对象,此过程中对象创建控制权由程序转移到外部,此思想称为控制反转。
- 业务层要用数据层的类对象,以前是自己new的
- 现在自己不new了,交给别人[外部]来创建对象
- 别人[外部]就反转控制了数据层对象的创建权
- 这种思想就是控制反转
- 别人[外部]指定是什么呢?继续往下学
(2)Spring和IOC之间的关系是什么呢?
- Spring技术对IOC思想进行了实现
- Spring提供了一个容器,称为==IOC容器==,用来充当IOC思想中的"外部"
- IOC思想中的别人[外部]指的就是Spring的IOC容器
(3)IOC容器的作用以及内部存放的是什么?
- IOC容器负责对象的创建、初始化等一系列工作,其中包含了数据层和业务层的类对象
- 被创建或被管理的对象在IOC容器中统称为==Bean==
- IOC容器中放的就是一个个的Bean对象
(4)当IOC容器中创建好service和dao对象后,程序能正确执行么?
- 不行,因为service运行需要依赖dao对象
- IOC容器中虽然有service和dao对象
- 但是service对象和dao对象没有任何关系
- 需要把dao对象交给service,也就是说要绑定service和dao对象之间的关系
像这种在容器中建立对象与对象之间的绑定关系就要用到DI:
==DI(Dependency Injection)依赖注入==
(1)什么是依赖注入呢?
- 在容器中建立bean与bean之间的依赖关系的整个过程,称为依赖注入
- 业务层要用数据层的类对象,以前是自己new的
- 现在自己不new了,靠别人[外部其实指的就是IOC容器]来给注入进来
- 这种思想就是依赖注入
(2)IOC容器中哪些bean之间要建立依赖关系呢?
- 这个需要程序员根据业务需求提前建立好关系,如业务层需要依赖数据层,service就要和dao建立依赖关系
- 介绍完Spring的IOC和DI的概念后,我们会发现这两个概念的最终目标就是:==充分解耦==,具体实现靠:
- 使用IOC容器管理bean(IOC)
- 在IOC容器内将有依赖关系的bean进行关系绑定(DI)
- 最终结果为:使用对象时不仅可以直接从IOC容器中获取,并且获取到的bean已经绑定了所有的依赖关系.
IOC容器实现
Spring中的IoC容器就是IoC思想的一个落地产品实现。IoC容器中管理的组件也叫做bean。在创建bean之前,首先需要创建IoC容器,Spring提供了IoC容器的两种实现方式
- BeanFactory
这是IoC容器的基本实现,是Spring内部使用的接口,面向Spring本身,不提供给开发人员使用。
- ApplicationContext
BeanFactory的子接口,提供了更多高级特性,面向Spring的使用者,几乎所有场合都使用 ApplicationContext,而不使用底层的BeanFactory。
IOC相关:创建容器
注解方式
在对应的bean类上面添加注解@component
ApplicationContext context = new AnnotationConfigApplicationContext("cn.tedu.spring");
User u = context.getBean(User.class);在对应的basesPackage路径里加上包路径
xml配置文件方式
创建容器
//方式一∶类路径加载配置文件
ApplicationContext ctx = new classPathXmlApplicationContext("applicationContext.xml");
//方式二∶文件路径加载配置文件
ApplicationContext ctx = new FileSystemXmlApplicationContext("D:\lapplicationContext.xml");
//加载多个配置文件
ApplicationContext ctx = new ClassPathXm1ApplicationContext ("bean1.xm1" , "bean2.xml" );
获取bean
//方式一︰使用bean名称获取
BookDao bookDao = (BookDao) ctx.getBean( "bookDao" );
//方式二︰使用bean名称获取并指定类型
BookDao bookDao = ctx.getBean("bookDao" , BookDao.class);
//方式三∶使用bean类型获取
BookDao bookDao = ctx.getBean( BookDao.class);bean相关
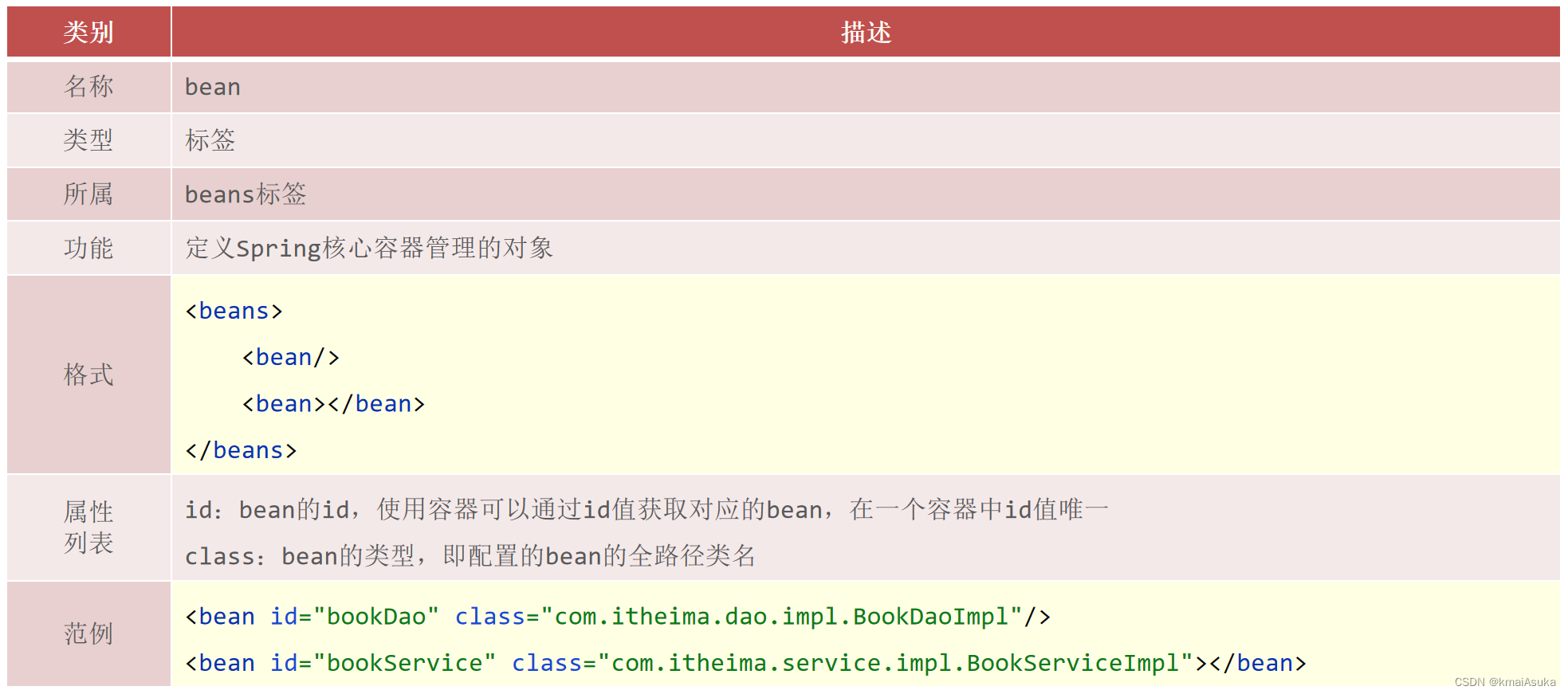
<bean
id="bookDao" bean的Id
name="dao bookDaoImpl daoImpl" bean别名
class="com.itheima.dao.impl.BookDaoImpl" bean类型,静态工厂类,FactoryBean类
scope="singleton" 控制bean的实例数量
init-method="init" 生命周期初始化方法
destroy-method="destory" 生命周期销毀方法
autowire="byType" 自动装配类型
factory-method="getInstance" bean工厂方法,应用于静态工厂或实例工厂
factory-bean="com.itheima.factory.BookDaoFactory" 实例工厂bean
lazy-init="true" 控制bean延迟加载
/>容器相关
- BeanFactory是IoC容器的顶层接口,初始化BeanFactory对象时,加载的bean延迟加载
- ApplicationContext接口是Spring容器的核心接口,初始化时bean立即加载
- ApplicationContext接口提供基础的bean操作相关方法,通过其他接口扩展其功能
- ApplicationContext接口常用初始化类
- ClassPathXmlApplicationContext
- FileSystemXmlApplicationContext
Bean
单实例与多实例
- 单实例
单实例(Singleton)是指某个类只能创建唯一的一个实例对象,并且该类提供一个全局的访问点(静态方法)来让外界获取这个实例,常常用在那些只需要一个实例来处理所有任务的场景下,例如数据库连接。
- 多实例
多实例(Multiple Instance)则是指可以在同一个类的定义下,创建多个实例对象。每个对象都是相互独立的,有自己的状态和行为;常常用于需要同时处理多个任务的场景。
在Spring中可以通过 @Scope 注解来指定bean的作用域范围
| 取值 | 含义 |
| @Scope("singleton") 单例(默认) | 在IoC容器中,这个bean的对象为单实例 |
| @Scope("prototype") 多例 | 这个bean在IoC容器中有多个实例 |
在Spring中可以通过xml配置文件来指定bean的作用域范围
配置bean为非单例
在Spring配置文件中,配置scope属性来实现bean的非单例创建
- 在Spring的配置文件中,修改的scope属性
<bean id="bookDao" name="dao" class="com.itheima.dao.impl.BookDaoImpl" scope="xxx "/>- 将scope设置为singleton
<bean id="bookDao" name="dao" class="com.itheima.dao.impl.BookDaoImpl" scope="singleton"/>scope使用后续思考
介绍完scope属性以后,我们来思考几个问题:
- 为什么bean默认为单例?
- bean为单例的意思是在Spring的IOC容器中只会有该类的一个对象
- bean对象只有一个就避免了对象的频繁创建与销毁,达到了bean对象的复用,性能高
- bean在容器中是单例的,会不会产生线程安全问题?
- 如果对象是有状态对象,即该对象有成员变量可以用来存储数据的,
- 因为所有请求线程共用一个bean对象,所以会存在线程安全问题。
- 如果对象是无状态对象,即该对象没有成员变量没有进行数据存储的,
- 因方法中的局部变量在方法调用完成后会被销毁,所以不会存在线程安全问题。
- 哪些bean对象适合交给容器进行管理?
- 表现层对象
- 业务层对象
- 数据层对象
- 工具对象
- 哪些bean对象不适合交给容器进行管理?
- 封装实例的域对象,因为会引发线程安全问题,所以不适合。
bean实例化(容器是如何来创建对象)
调用无参构造
- 实例化bean的三种方式,构造方法,静态工厂和实例工厂
在讲解这三种创建方式之前,我们需要先确认一件事:
bean本质上就是对象,对象在new的时候会使用构造方法完成,那创建bean也是使用构造方法完成的。
构造方法
- 构造方法(常用)
- 静态工厂(了解)
- 实例工厂(了解)
- FactoryBean(实用)
这些方式中,重点掌握构造方法和FactoryBean即可。
需要注意的一点是,构造方法在类中默认会提供,但是如果重写了构造方法,默认的就会消失,在使用的过程中需要注意,如果需要重写构造方法,最好把默认的构造方法也重写下。
生命周期
(1)关于Spring中对bean生命周期控制提供了两种方式:
- 在配置文件中的bean标签中添加init-method和destroy-method属性
- 类实现InitializingBean与DisposableBean接口,这种方式了解下即可。
(2)对于bean的生命周期控制在bean的整个生命周期中所处的位置如下:
- 实例化阶段(bean对象创建)
- 在这个阶段中,IoC容器通过 构造方法创建一个Bean的实例,并为其分配空间。
- 属性赋值阶段
- 容器把通过 set方法 Bean中的属性值注入到Bean中
- 初始化阶段(bean对象初始化)
- 容器对Bean进行初始化操作;
- 使用阶段
- 执行业务操作,Bean可以被容器使用
- 销毁阶段
- 执行bean销毁方法,容器在关闭时会对所有的Bean进行销毁操作,释放资源。
在spring中,可以通过 @PostConstruct 和 @PreDestroy 注解实现 bean对象 生命周期的初始化和销毁时的方法。
- @PostConstruct注解
生命周期初始化方法,在对象构建以后执行。
- @PreDestroy注解
生命周期销毁方法,比如此对象存储到了spring容器,那这个对象在spring容器移除之前会先执行这个生命周期的销毁方法(注:prototype作用域对象不执行此方法)。
(3)关闭容器的两种方式:
- ConfigurableApplicationContext是ApplicationContext的子类
- close()方法
- registerShutdownHook()方法
//bean @Component public class Life { private String lifetime; public Life(){ System.out.println("1.实例化创建bean对象"); } @Value("青少年") public void setLifetime(String lifetime){ this.lifetime=lifetime; System.out.println("2.set方法属性赋值"); } @PostConstruct public void init() { System.out.println("3.初始化方法执行"); } @PreDestroy public void destory(){ System.out.println("5.销毁阶段"); } @Override public String toString() { return "Life{" + "lifetime='" + lifetime + '\'' + '}'; } } //test类 public class TestLife { public static void main(String[] args) { AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext("spring.life"); Life bean = ctx.getBean(Life.class); System.out.println("4.使用阶段"+bean); ctx.close(); } } 打印结果: 1.实例化创建bean对象 2.set方法属性赋值 3.初始化方法执行 4.使用阶段Life{lifetime='青少年'} 5.销毁阶段 Process finished with exit code 0
DI(依赖注入)
DI (Dependency Injection):依赖注入,依赖注入实现了控制反转的思想;
是指Spring创建对象的过程中,将对象依赖属性通过配置进行注入。
所以 IOC 是一种控制反转的思想,而依赖注入 DI 是对IOC 的一种具体实现。
xml文件方式
- 向一个类中传递数据的方式有几种?
- 普通方法(set方法)
- 构造方法
- 依赖注入描述了在容器中建立bean与bean之间的依赖关系的过程,如果bean运行需要的是数字或字符串呢?
- 引用类型
- 简单类型(基本数据类型与String)
Spring就是基于上面这些知识点,为我们提供了两种注入方式,分别是:
- setter注入
- 简单类型
- ==引用类型==
- 构造器注入
- 简单类型
- 引用类型
setter注入
- 配置中使用==property==标签==ref==属性注入引用类型对象
- 在bean中定义引用类型属性,并提供可访问的==set==方法
对于引用数据类型使用的是
对于简单数据类型使用的是
构造器注入
标签中
- name属性对应的值为构造函数中方法形参的参数名,必须要保持一致。
- ref属性指向的是spring的IOC容器中其他bean对象。
依赖注入方式选择
1.强制依赖使用构造器进行,使用setter注入有概率不进行注入导致null对象出现2.可选依赖使用setter注入进行,灵活性强
3.Sprng框架倡导使用构造器,第三方框架内部大多数采用构造器注入的形式进行数据初始化,相对严谨
4.如果有必要可以两者同时使用,使用构造器注入完成强制依赖的注入,使用setter注入完成可选依赖的注入
5.实际开发过程中还要根据实际情况分析,如果受控对象没有提供setter方法就必须使用构造器注入
6.自己开发的模块推荐使用setter注入
注解方式
@Value注解
@Value注入是将属性值直接注入到bean中,主要用于注入一些简单类型的属性(如字符串、基本类型等);
使用时需要注意属性的类型和格式,否则会导致注入失败。
@Autowired注解(自动装配)
属于spring框架,根据类型注入,如果有相同类型的再使用Qualifier注解根据名称注入
@Autowired注入是将对象类型或者接口类型注入到bean中,并且在注入对象时会根据依赖注入容器中 bean的类型 进行匹配。
如果容器中有多个类型匹配的bean存在,则会抛出异常。
因此,@Autowired注入常用于注入复杂对象、接口类型的属性或其他bean实例。
依赖自动装配特征
- 自动装配用于引用类型依赖注入,不能对简单类型进行操作
- 使用按类型装配时( byType )必须保障容器中相同类型的bean唯一,推荐使用
- 使用按名称装配时( byName )必须保障容器中具有指定名称的bean,因变量名与配置耦合,不推荐使用
- 自动装配优先级低于setter注入与构造器注入,同时出现时自动装配配置失效
@Qualifier注解
根据IOC容器中,Spring Bean对象的名称进行装配
如果一个接口有多个实现类,@Autowired一定会装配失败,会报错NoUniqueBeanDefinitionException(不是唯一的bean定义异常)
可以指定bean名称@Component("名称"),使用@Qualifier注解,通过名称指定要装配的bean
@Repository public class UserMapper { @Autowired @Qualifier(value = "名称1") private Cache cache; } //对应Bean @Component("名称1") public class MapperImpl1(){...} //对应Bean @Component("名称2") public class MapperImpl2(){...}
@Resource注解
根据名称注入,名称不一样根据属性注入,属性不一样根据类型注入。
与@Autowired作用类似,但该注解是jkd拓展包的,也属于jdk的一部分
- 指定@Resource中的name参数,则根据Bean名称[name参数](首字母小写)装配
@Repository public class ControllerMapper { @Resource(name = "mapperImpl") private Mapper mapper; } //对应Bean @Component public class MapperImpl(){...}
- 未指定名称[name参数],则把属性名称mapperImpl(首字母小写)作为Bean对象名称装配
@Repository public class ControllerMapper { @Resource private Mapper mapperImpl; } //对应Bean @Component public class MapperImpl(){...}
- 属性名和Bean对象名称也不一致,则会根据类型进行装配
注解开发
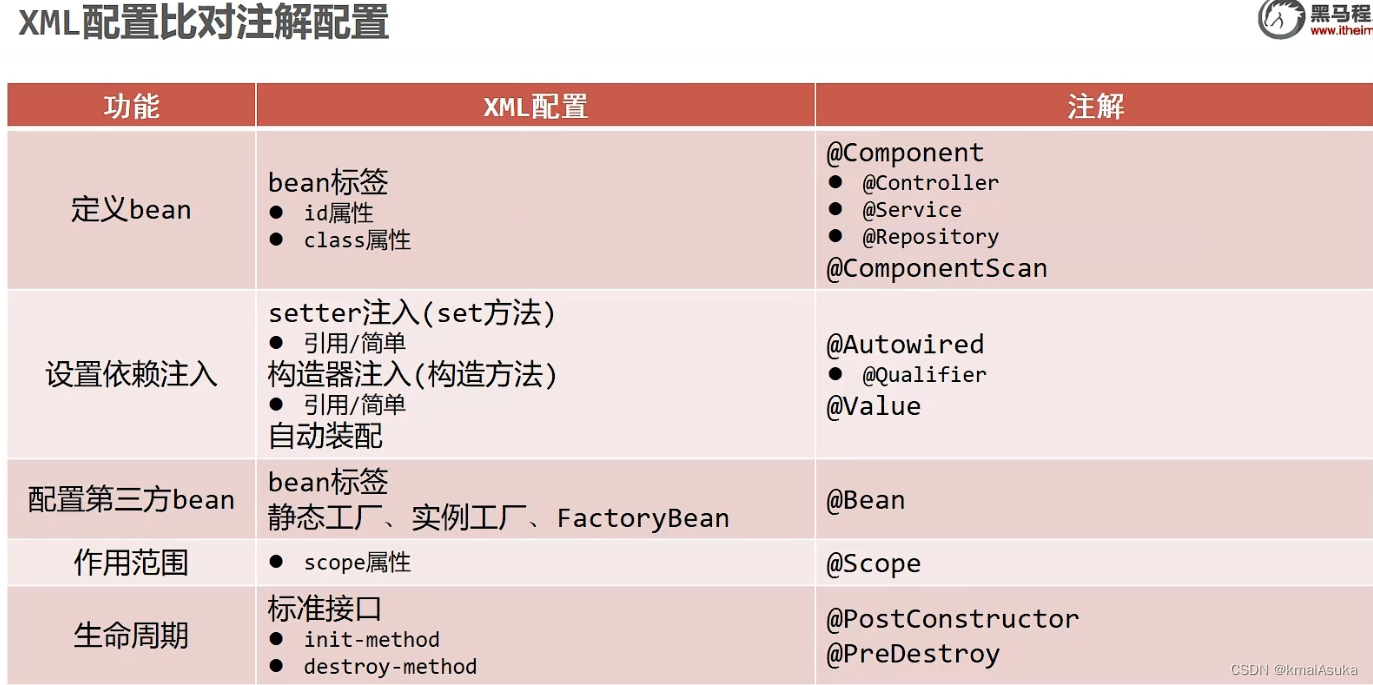
- 使用@Component注解开发定义bean
@Component ("bookDao")
public class BookDaoImpl implements BookDao {
@Component
public class BookServiceImpl implements BookService {}- 核心配置文件中通过组件扫描加载bean
<context:component-scan base-package="com.itheima"/>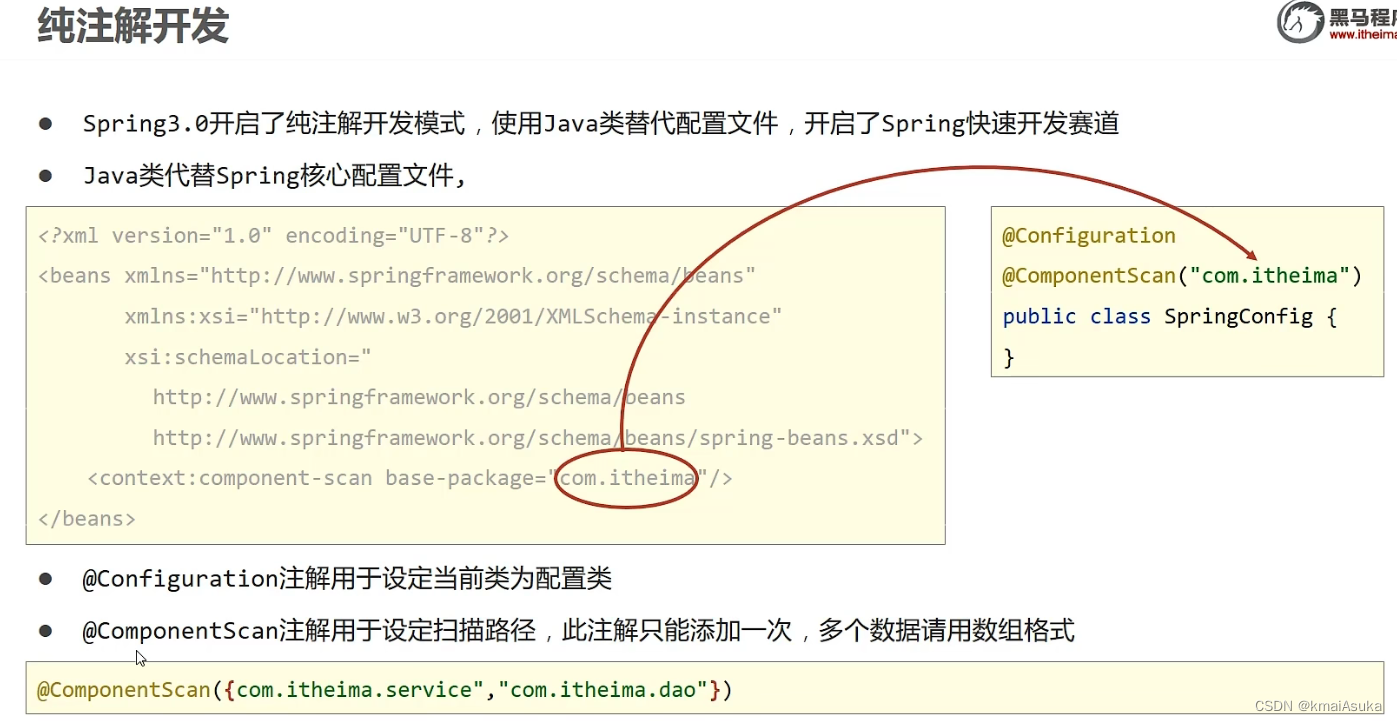

管理第三方bean
加载properties文件
- 不加载系统属性
<context:property-placeholder location="jdbc.properties" system-properties-mode="NEVER"/>- 加载多个properties文件
<context:property-placeholder location="jdbc.properties,msg.properties"/>- 加载所有properties文件
<context:property-placeholder location="*.properties"/>- 加载properties文件标准格式
<context:property-placeholder location="classpath:*.properties"/>- 从类路径或jar包中搜索并加载properties文件
<context:property-placeholder location="classpath*:*.properties"/>引用外部属性文件
实际开发中,很多情况下我们需要对一些变量或属性进行动态配置,而这些配置可能不应该硬编码到我们的代码中,因为这样会降低代码的可读性和可维护性。
我们可以将这些配置放到外部属性文件中,比如database.properties文件,然后在代码中引用这些属性值,例如jdbc.url和jdbc.username等。这样,我们在需要修改这些属性值时,只需要修改属性文件,而不需要修改代码,这样修改起来更加方便和安全。
而且,通过将应用程序特定的属性值放在属性文件中,我们还可以将应用程序的配置和代码逻辑进行分离,这可以使得我们的代码更加通用、灵活。
使用流程
- 创建外部属性文件(在resources目录下创建文件,命名为:"xxx.properties")
- 引入外部属性文件(使用 @PropertySource("classpath:外部属性文件名") 注解)
- 获取外部属性文件中的变量值 (使用 ${变量名} 方式)
- 进行属性值注入
自动扫描配置
说明
自动扫描配置是 Spring 框架提供的一种基于注解(Annotation)的配置方式,用于自动发现和注册 Spring 容器中的组件。当我们使用自动扫描配置的时候,只需要在需要被 Spring 管理的组件(比如 Service、Controller、Repository 等)上添加对应的注解,Spring 就会自动地将这些组件注册到容器中,从而可以在其它组件中使用它们。
在 Spring 中,通过 @ComponentScan 注解来实现自动扫描配置。
@ComponentScan 注解用于指定要扫描的包或类。
Spring 会在指定的包及其子包下扫描所有添加 @Component(或 @Service、@Controller、@Repository 等)注解的类,把这些类注册为 Spring Bean,并纳入 Spring 容器进行管理。
/**
* 设置自动扫描
* Configuration注解: 标识此类为Spring的配置类,Spring在启动时会自动加载此类;
* ComponentScan注解: 自动扫描注解;
* 1.指定包路径为:cn.tedu.spring, 扫描该包及子孙包中所有的类,把所有添加相关注解的类注册为Spring Bean;
* 2.未指定包路径,则扫描该配置文件[SpringConfig.java]所在包以及子孙包中的类;
*/
@Configuration
@ComponentScan("cn.tedu.spring")
public class SpringConfig {
}SpringAOP(关于AOP我会再出一期文章单独介绍)
- 概念︰AOP(Aspect Oriented Programming)面向切面编程,一种编程范式
- 作用︰在不惊动原始设计的基础上为方法进行功能增强
- 核心概念
- 代理( Proxy ) : SpringAoP的核心本质是采用代理模式实现的
- 连接点( JoinPoint ) :在SpringAoP中,理解为任意方法的执行
- 切入点( Pointcut ) :匹配连接点的式子,也是具有共性功能的方法描述
- 通知(Advice )︰若干个方法的共性功能,在切入点处执行,最终体现为一个方法
- 切面( Aspect )︰描述通知与切入点的对应关系
- 目标对象( Target )︰被代理的原始对象成为目标对象
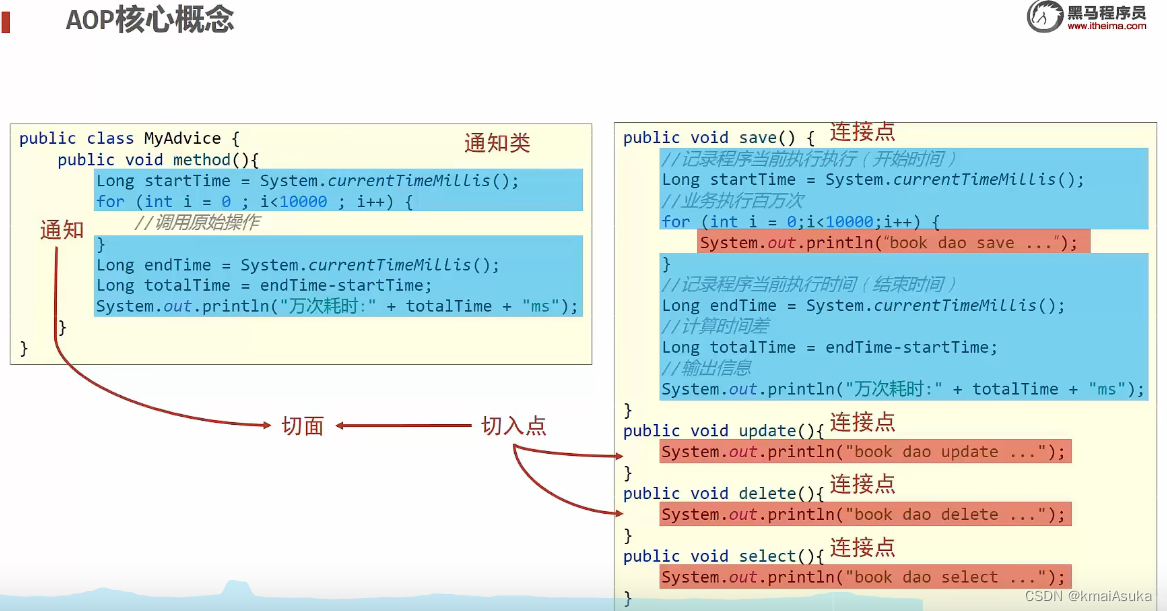
AOP核心概念
- 目标对象(Target )︰原始功能去掉共性功能对应的类产生的对象,这种对象是无法直接完成最终工作的
- 代理(Proxy )︰目标对象无法直接完成工作,需要对其进行功能回填,通过原始对象的代理对象实现
- 连接点( JoinPoint)︰程序执行过程中的任意位置,粒度为执行方法、抛出异常、设置变量等
- 在SpringAoP中,理解为方法的执行
- 切入点(Pointcut ) :匹配连接点的式子
- 在springAoP中,一个切入点可以只描述一个具体方法,也可以匹配多个方法
- 一个具体方法: com.itheima. dao包下的BookDao接口中的无形参无返回值的save方法
- 匹配多个方法:所有的save方法,所有的get开头的方法,所有以Dao结尾的接口中的任意方法,所有带有一个参数的方法
- 在springAoP中,一个切入点可以只描述一个具体方法,也可以匹配多个方法
- 通知(Advice ):在切入点处执行的操作,也就是共性功能
- 在SpringAOP中,功能最终以方法的形式呈现
- 通知类:定义通知的类
- 切面(Aspect ):描述通知与切入点的对应关系
AOP工作流程
- Spring容器启动
- 读取所有切面配置中的切入点
- 初始化bean,判定bean对应的类中的方法是否匹配到任意切入点
- 匹配失败,创建对象
- 匹配成功,创建原始对象(目标对象)的代理对象
- 获取bean执行方法
- 获取bean,调用方法并执行,完成操作
- 获取的bean是代理对象时,根据代理对象的运行模式运行原始方法与增强的内容,完成操作
AOP切入点表达式
可以使用通配符描述切入点,快速描述
- * :单个独立的任意符号,可以独立出现,也可以作为前缀或者后缀的匹配符出现
匹配com.itheima包下的任意包中的UserService类或接口中所有find开头的带有一个参数的方法
execution (public * com.itheima.*.UserService.find*(*))- .. :多个连续的任意符号,可以独立出现,常用于简化包名与参数的书写
匹配com包下的任意包中的UserService类或接口中所有名称为findByld的方法
execution (public User com..UserService.findById (..))- +︰专用于匹配子类类型
execution(* *..*Service+.*(..))书写技巧
- 所有代码按照标准规范开发,否则以下技巧全部失效
- 描述切入点通常描述接口,而不描述实现类
- 访问控制修饰符针对接口开发均采用public描述(可省略访问控制修饰符描述)
- 返回值类型对于增删改类使用精准类型加速匹配,对于查询类使用*通配快速描述
- 包名书写尽量不使用..匹配,效率过低,常用*做单个包描述匹配,或精准匹配
- 接口名/类名书写名称与模块相关的采用*匹配,例如UserService书写成*Service,绑定业务层接口名
- 方法名书写以动词进行精准匹配,名词采用*匹配,例如getByld书写成getBy* ,selectAll书写成selectAll
- 参数规则较为复杂,根据业务方法灵活调整
- 通常不使用异常作为匹配规则
通知类型
AOP通知描述了抽取的共性功能,根据共性功能抽取的位置不同,最终运行代码时要将其加入到合理的位置
AOP通知共分为5种类型
- 前置通知
- 后置通知
- 环绕通知(重点)
- 环绕通知依赖形参ProceedingJoinPoint才能实现对原始方法的调用
- 环绕通知可以隔离原始方法的调用执行
- 环绕通知返回值设置为object类型
- 环绕通知中可以对原始方法调用过程中出现的异常进行处理
- 返回后通知
- 抛出异常后通知
@Around注意事项
1.环绕通知必须依赖形参ProceedingloinPoint才能实现对原始方法的调用,进而实现原始方法调用前后同时添加通知2通知中如果未使用ProceedingJoinPoint对原始方法进行调用将跳过原始方法的执行
3.对原始方法的调用可以不接收返回值,通知方法设置成void即可,如果接收返回值,必须设定为Object类型
4.原始方法的返回值如果是void类型,通知方法的返回值类型可以设置成void,也可以设置成Object
5. 由于无法预知原始方法运行后是否会抛出异常,因此环绕通知方法必须抛出Throwable对象
@Around("pt()"")
public object around(ProceedingJoinPoint pjp)throws Throwable{
System.out.println("around before advice ...");
Object ret = pjp.proceed();
system.out.println("around after advice ...");
return ret;
}spring事务
相关概念介绍
- 事务作用:在数据层保障一系列的数据库操作同成功同失败
- Spring事务作用:在数据层或==业务层==保障一系列的数据库操作同成功同失败数据层有事务我们可以理解,为什么业务层也需要处理事务呢?举个简单的例子,转账业务会有两次数据层的调用,一次是加钱一次是减钱
- 把事务放在数据层,加钱和减钱就有两个事务
- 没办法保证加钱和减钱同时成功或者同时失败
- 这个时候就需要将事务放在业务层进行处理。
- 问题:例如当我们执行转账操作时,如果加钱减钱的方法途中遭遇异常,会导致账户金额出现问题
==>解决方法:事务
事务作用:在数据层保障一系列的数据库操成功或失败
Spring事务作用:在数据层或业务层保障一系列的数据库操成功或失败
==>之所以加上业务层是因为业务层也不过是数据层的不同组合,一次业务层事务的提交要么全部失败要么全部成功
spring实现的方式:
1.在配置类里添加事务的Bean
2.在Spring配置类里添加@EnableTransactionManagement标签
3.在需要添加事务管理的接口方法上添加@Transactional注解(该注解也可以写在接口类上,表示该接口所有方法都开启事务)
概念:
->事务管理员:一般是带有@Transactional标签的接口方法,可以将其他事务纳入自己的事务中(最终变成自己的一个事务)
->事务协调员:一般是被收纳的接口方法
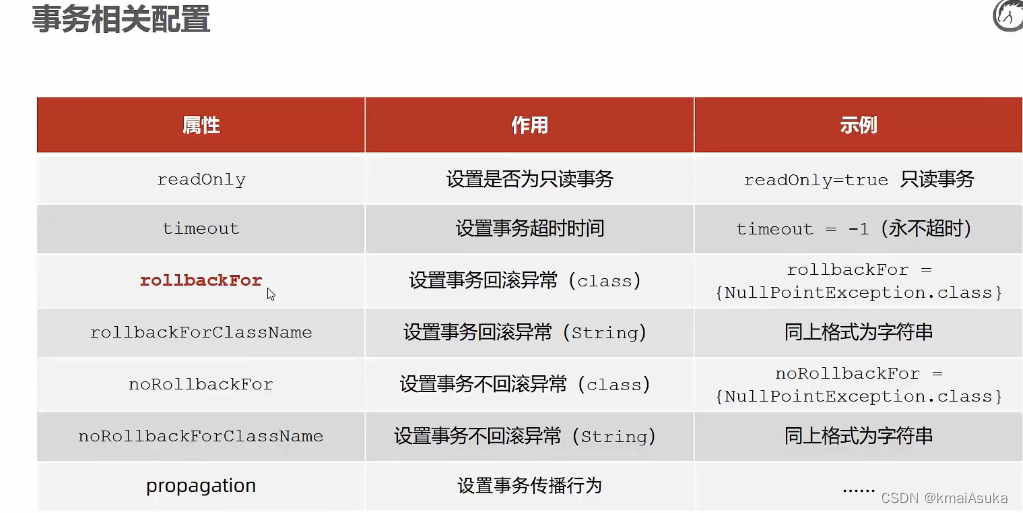
我们可以通过在@Transactional注解里添加属性实现对事物的进一步管理
例: @Transactional(rollbackFor = IOException.class) //并不是遇到所有的异常事物都会回滚,所以我们要将那些特例的异常指定出来回滚
- 问题:同样是转账操作.我们需要在加钱减钱的功能上再加入一个记录日志的功能,并且要满足无论转账是否成功都要记录,这个时候如果还是用上文的方式(同成功同失败)就无法实现
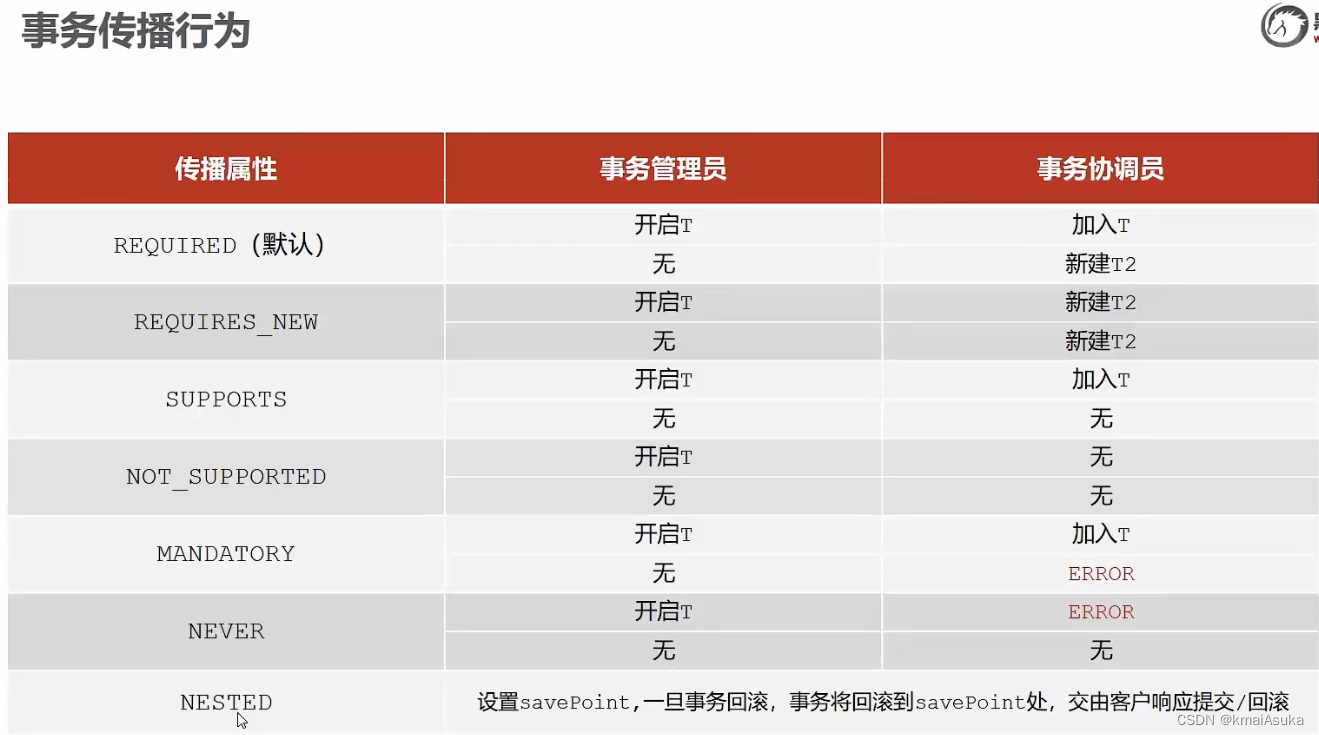
==>解决方法:让事务协调员新建一个事务,不被管理员统一管理(事务传播行为)
实现:在该事务协调员(接口方法)上添加@Transactional(propagation = Propagation.REQUIRES_NEW) ->表示协调员不参与管理员事务(默认的参数是Propagation.REQUIRES,表示管理员涵盖了该事务就自动加入)
意思就是说通过这种方式,虽然记录日志,加钱减钱的方法还是写在了同一个事务里,但是记录日志的方法在前两者发生异常时也会执行(回滚事务),不和他们同成功同失败
web开发三层架构
- 数据访问:负责业务数据的维护操作,包括增、删、改、查等操作。
- 逻辑处理:负责业务逻辑处理的代码。
- 请求处理、响应数据:负责,接收页面的请求,给页面响应数据。
按照上述的三个组成部分,在我们项目开发中呢,可以将代码分为三层:

- Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
- Service:业务逻辑层。处理具体的业务逻辑。
- Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。

控制反转和依赖注入
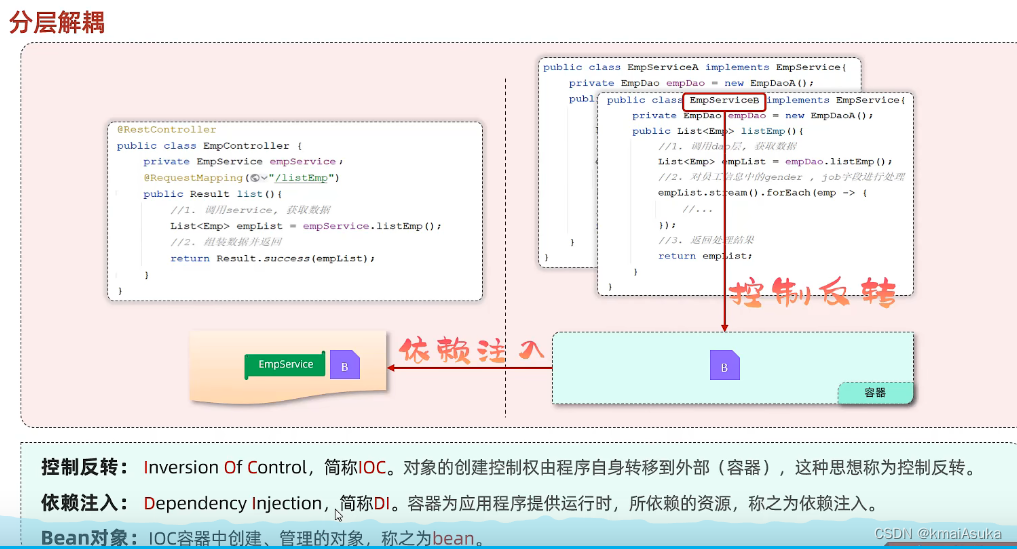
在之前的入门案例中,要把某个对象交给IOC容器管理,需要在类上添加一个注解:
- @Component (用于将类标识为Bean组件,使得Spring能够自动扫描并将其实例化为Bean对象,并进行依赖注入)
而Spring框架为了更好的标识web应用程序开发当中,bean对象到底归属于哪一层,又提供了@Component的衍生注解:
- @Controller (标注在控制层类上)
- @Service (标注在业务层类上)
- @Repository (标注在数据访问层类上)
如果在IOC容器中,存在多个相同类型的bean对象,会出现什么情况呢?
程序运行会报错
如何解决上述问题呢?Spring提供了以下几种解决方案:
- @Primary
- @Qualifier
- @Resource
- 1.在@Service上面使用@Primary注解:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。
- 使用@Qualifier注解:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。@Qualifier注解不能单独使用,必须配合@Autowired使用
- 使用@Resource注解:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。
面试题 :
@Autowird 与 @Resource的区别?
@Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
@Autowired 默认是按照类型注入,而@Resource是按照名称注入
spring整合Junit
使用 Junit 能让我们快速的完成单元测试。
->通常我们写完代码想要测试这段代码的正确性,那么必须新建一个类,然后创建一个 main() 方法,然后编写测试代码。如果需要测试的代码很多呢?
那么要么就会建很多main() 方法来测试,要么将其全部写在一个 main() 方法里面。这也会大大的增加测试的复杂度,降低程序员的测试积极性。
而JUnit能很好的解决这个问题,简化单元测试,写一点测一点,在编写以后的代码中如果发现问题可以较快的追踪到问题的原因,减小回归错误的纠错难度。
用法:在需要测试类上方添加
@RunWith(SpringJUnit4ClassRunner.class)和
@Configuration(SpringConfig.class)标签,并在方法上面添加@Test注解,需要测试时直接右键运行即可
如何在Spring内集成JUnit:
1.导入坐标(JUnit坐标以及Spring集成JUnit的坐标)
2.编写测试类
编写配置类原则
①测试方法上必须使用@Test进行修饰
②测试方法必须使用public void 进行修饰,不能带任何的参数
③新建一个源代码目录来存放我们的测试代码,即将测试代码和项目业务代码分开
④测试类所在的包名应该和被测试类所在的包名保持一致
⑤测试单元中的每个方法必须可以独立测试,测试方法间不能有任何的依赖















 1208
1208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









