






什么是集合?
集合就是多个数据的组合(有各种存储数据的数据结构),每个数据都是集合的一个元素(就像是一个容器)。
这里要注意数组也可以看成一个容器,但是和集合是两个概念。它们有共同点,但是是有很大区别的。(个人理解,这是数据结构方面的,暂时不太了解)
Java集合分为两大类:
一类是单个方式存储元素:
单个方式存储元素,这一类集合中超级父类接口Java.util.Collection;
一类是以键值对的方式存储元素:
以键值对的方式存储元素,这一类集合中超级父类接口Java.util.Map;
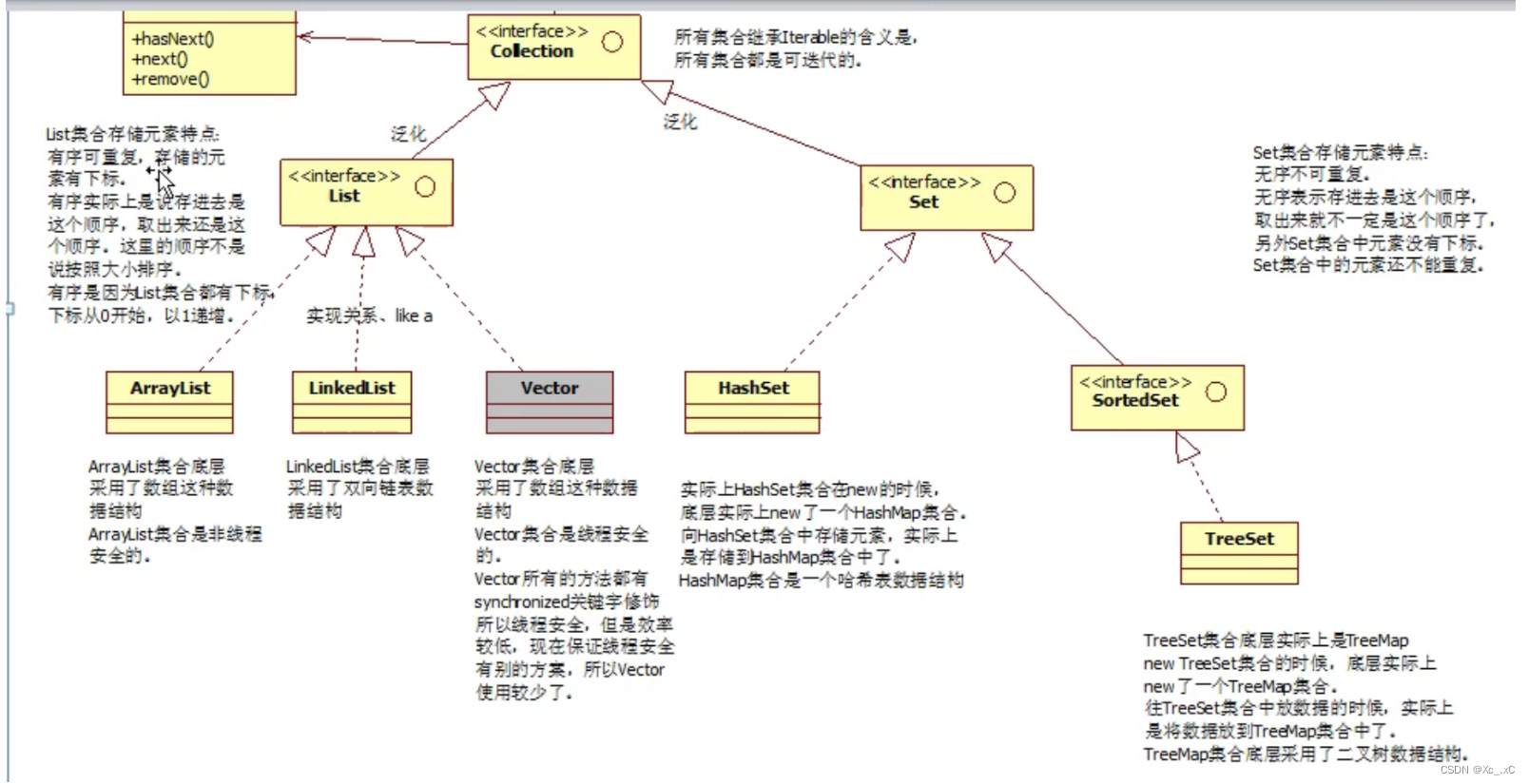
java集合框架的继承结构图:
注意:只是列出来最常用的接口和实现类(实际有很多)
Collection中的常用方法:
1,boolean add(Object e); 向集合中添加元素
2,int size(); 获取集合中元素的个数
3,void clear(); 清空集合
4,boolean contains(Object o); 判断当前集合中是否包含元素o,包含返回true,不包含返 会false
5,boolean isEmpty(); 判断集合中元素的个数是否为0
6,boolean remove(Object o); 删除集合中某个元素
7, Object[] toArray(); 调用这个方法可以把集合转换成数组。
Collection接口方法的代码测试:
public class CollectionTest01 {
public static void main(String[] args) {
//创建一个集合对象
//Collection collection = new Collection();//Collection是一个接口,无法实例化
//多态
Collection c=new ArrayList();
//测试Collection的常用方法
//添加数据
c.add(1200);//自动装箱(Java5的新特性),会把1200基本数据类型变成对象,之后细说。
c.add(3.14);//和上面一样,记住,集合只能存储引用数据类型
c.add(new Object());
c.add(true);//自动装箱
//获取集合中元素的个数
c.size();
System.out.println("集合当中的元素个数是"+c.size());
//判断集合是否包含某个元素,返回true或false
c.contains(1200);
c.contains(100);
System.out.println(c.contains(1200));
System.out.println(c.contains(100));
//转换成数组
Object[] obj= c.toArray();
for (int i=0;i<obj.length;i++){
Object o = obj[i];
System.out.print(o+" ");
}
}
}
结果:
集合当中的元素个数是4
true
false
1200 3.14 java.lang.Object@1540e19d true 对集合Collection进行遍历/迭代
注意:
1,当集合的结构发生了改变的时候,迭代器必须重新获取,如果还用老的迭代器会出现异常
2,使用迭代器存进去是什么类型,取出来还是什么类型。只不过在输出的时候会转换成字符串
第一步:获取集合对象的迭代器的对象。
第二步:通过获取的迭代器对象开始迭代/遍历集合。public interface Collection<E> extends Iterable<E>
Collection集合和Iterator对象的联系
public interface Collection<E> extends Iterable<E>{
}
//接口,Iterable不止这一个成员属性和方法
public interface Iterable<T>{
Iterator<T> iterator();
}
//迭代器对象,也是一个接口
public interface Iterator<E>{
boolean hasNext();
E next();
}
Iterator迭代器对象两个常用方法:
Boolean hashNext() 如果仍有对象可以迭代,返回true。
Object next()返回迭代的下一个元素。
代码演示:
public class CollectionTest02 {
public static void main(String[] args) {
//创建集合对象
Collection c= new ArrayList();
//往集合中添加元素
c.add(100);
c.add("张三");
c.add(true);
c.add(new Object());
//通过集合对象获取迭代器迭代对象
Iterator iterator = c.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.print(next+" ");
}
}
}
结果:
100 张三 true java.lang.Object@1540e19d 集合结构发生改变的时候,使用迭代器的情况(需要重新获取)
public class CollectionTest02 {
public static void main(String[] args) {
//创建集合对象
Collection c= new ArrayList();
//往集合中添加元素
c.add(100);
c.add("张三");
c.add(true);
c.add(new Object());
//通过集合对象获取迭代器迭代对象
Iterator iterator = c.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.print(next+" ");
}
//改变集合结构
c.remove(100);
while (iterator.hasNext()){
System.out.print(iterator.next()+" ");
}
}
}
List与Set的区别
List、Set都继承自Collection接口;
List的特点:元素有放入顺序,且可重复;
Set的特点:元素无放入顺序,且不可重复(注意:元素虽然无放入顺序,但是元素在Set中的位置是由该元素的HashCode决定的,其位置是固定的)。
List支持for循环,也就是通过下标来遍历,也可以用迭代器,但是Set只能用迭代器,因为他无序,无法使用下标取值; List接口有三个常用实现类:LinkedList,ArrayList,Vector。
Set接口有两个常用实现类:HashSet(底层由HashMap实现),TreeSet(底层由TreeMap实现)
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
List:
list作为Collection接口的子接口,是具有自己“特色”的方法的:
list接口特有的常用方法:
1,void add(int index,Object element); 在指定索引的位置添加元素,后面的元素后移
2,Object set (int index,Object element); 把指定索引位置的元素替换成element
3,Object get(int index); 获取指定索引位置的元素。
4,int indexOf(Object o); 获取指定元素第一次出现的索引(list可以重复)
5,int lastIndexOf(Object o); 获取指定元素最后一次出现的索引
6,Object remove(int index); 删除指定索引位置的元素
代码示例:
import java.util.ArrayList;
import java.util.List;
public class CollectionTest03 {
public static void main(String[] args) {
String a="1",b="12",c="123",d="1234",e="12345";
//注意这里是使用list接口的特有方法,不能用Collection接口
List<String> list = new ArrayList();//泛型下一章讲,先用
list.add(a);
list.add(b);
list.add(c);
list.add(b);//list集合是可以存储重复元素的
// 获取指定索引位置的元素。
System.out.println(" 索引为2的元素"+list.get(2));
// 获取指定元素第一次出现的索引(list可以重复)
System.out.println("元素第一次出现的索引"+list.indexOf("1"));
System.out.println("元素第一次出现的索引"+list.indexOf("2"));//如果没有该元素,直接返回-1
//获取指定元素最后一次出现的索引
System.out.println("元素最后一次出现的索引"+list.lastIndexOf("1"));
//list接口是存储有序的,可以直接用for循环遍历
for (String str:list ){
System.out.print(str+" ");
}
System.out.println("用索引添加元素前");
//在索引为0的位置添加字符串对象1
list.add(0,"1");
for (String str:list ){
System.out.print(str+" ");
}
System.out.println("用索引修改元素前");
//把索引为1的元素替换成000
list.set(1,"000");
for (String str:list ){
System.out.print(str+" ");
}
System.out.println("用索引删除元素前");
//删除指定索引位置的元素
list.remove(1);
for (String str:list ){
System.out.print(str+" ");
}
}
}
结果:
索引为2的元素123
元素第一次出现的索引0
元素第一次出现的索引-1
元素最后一次出现的索引0
1 12 123 12 用索引添加元素前
1 1 12 123 12 用索引修改元素前
1 000 12 123 12 用索引删除元素前
1 12 123 12 Arraylist:
list接口的一个常用实现类。上面代码都是以Arraylist作为例子,它的用法主要就是上面那些。
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList继承结构图:
ArrayList 继承了 AbstractList ,并实现了 List 接口。
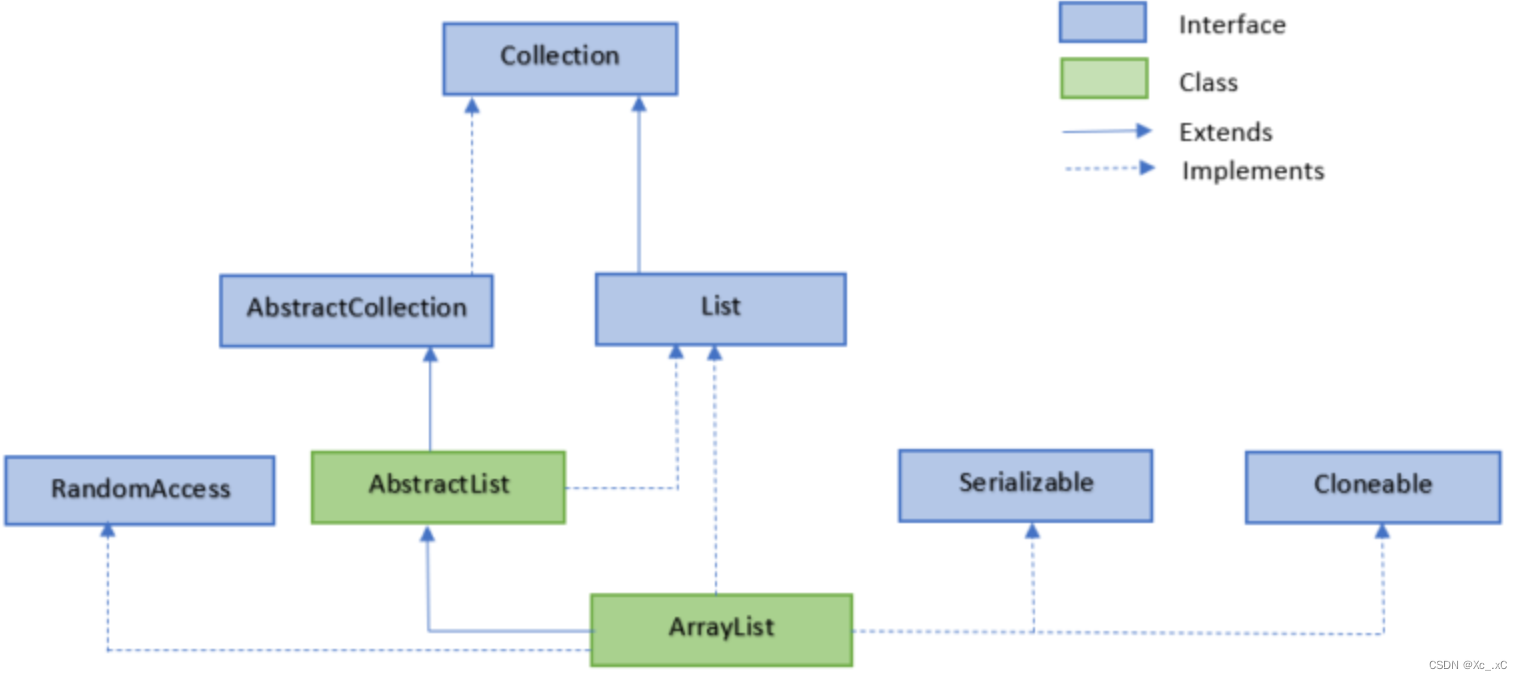
ArrayList特点:
注意:
1,ArrayList集合底层采用了数组这种数据结构
2,ArrayList集合是非线程安全的
3,ArrayList集合初始化容量是10
如果超过内存空间长度 ,会自动扩容至原来的1.5倍,
调用的Arrays.copyOf方法(其实就是自动进行数组的扩容)
4,ArrayList集合底层是Object类型的数组Object[]
5,建议给定一个预估价的初始化容量,减少数组的扩容次数,
这是ArrayList比较重要的优化策略。
初始化容量:List arrayList = new ArrayList(4);
LinkedList:
用法和ArrayList差不多,但是要主要一些地方
LinkedList继承结构
LinkedList特点:
1, 是双向链表,都有一个previous和next, 链表最开始的部分都有一个fiest和last 指向第一个元素,和最后一个元素。增加和删除的时候,只需要更改一个previous和next,就可以实现增加和删除,所以说,LinkedList对于数据的删除和增加相当的方便
2,LinkedList也是线程不安全的
3,LinkedList中元素在内存地址不是连续的,所以不存在初始化容量和扩容机制,所以在发生增删元素时是比较快的,但是每添加一个数据都要从第一个元素开始遍历(这里的时间复杂度随着链表的长度增加而增加)
注意:他和list集合演示的用法是差不多的,但是它因为存储数据的方式,就是底层的数据结构,使用他们时要考虑哪个更符合实际情况
Set:
Set集合也是Collection接口的子接口,可以使用Collection接口的方法。
Set接口有三个常用实现类:
HashSet, TreeSet, LinkedHashSet
Set集合的特点:
1,Set集合的存储特点是存储和无序的,元素是不能重复的。
2,用法和List差不多,但是Set因为是存储无序的,所以无法使用索引进行操作
3,Set集合也是线程不安全的。
4,使用HashSet,和LinkedHashSet 时,要注意equals()方法的问题(不可重复)。
5,使用TreeSet时,要注意比较器的问题(不可重复,以及排序)
代码演示:
public class CollectionTest04 {
public static void main(String[] args) {
//创建一个Set对象
Set set= new HashSet<>();
//存放元素
set.add(10);//自动装箱
set.add("22");
set.add(new Object());
//查看集合元素个数
System.out.println(set.size());
//直接输出Set对象
System.out.println(set);
//使用增强for循环遍历(foreach循环,内部调用了迭代器)
System.out.println("使用增强for循环遍历:");
for (Object o:set){
System.out.print(o+" ");
}
//使用迭代器对象遍历
System.out.println();
System.out.println("使用迭代器对象遍历:");
Iterator iterator = set.iterator();
while (iterator.hasNext()){
System.out.print(iterator.next()+" ");
}
}
}
结果:
3
[22, 10, java.lang.Object@1540e19d]
使用增强for循环遍历:
22 10 java.lang.Object@1540e19d
使用迭代器对象遍历:
22 10 java.lang.Object@1540e19dHashSet:
HashSet集合的特点:
HashSet 基于 HashMap(map集合后面细说) 来实现的,
是一个不允许有重复元素的集合。
其实是因为Hashcode和equals方法对元素进行了比较。(String类和包装类是重写了这两个方法的,如果是其他引用需要手动重写)在HashMap细讲。
HashSet 允许有 null 值。但只能有一个null值(重复的会被剔除)
HashSet 是无序的,即不会记录插入的顺序。
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
HashSet 实现了 Set 接口。
代码示例:
public class CollectionTest05 {
public static void main(String[] args) {
//创建HashSet对象
Set set= new HashSet();
//添加元素
set.add("张三");
set.add("李四");
set.add("王五");
set.add(null);//存入Null值
set.add(null);//再次存入null值会被自动剔除
set.add("张三");//存入重复元素,会被自动剔除
System.out.println(set);
}
}
结果:[null, 李四, 张三, 王五]没有重写Hashcode和equals方法:
public class MapTest03 {
public static void main(String[] args) {
Set set= new HashSet<>();
set.add(new Student("张三"));
set.add(new Student("张三"));
System.out.println(set);
}
}
class Student{
private String name;
public Student(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
结果:
[Student{name='张三'}, Student{name='张三'}]重写了Hashcode和equals方法
public class MapTest03 {
public static void main(String[] args) {
Set set= new HashSet<>();
set.add(new Student("张三"));
set.add(new Student("张三"));
System.out.println(set);
}
}
class Student{
private String name;
public Student(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
结果:
[Student{name='张三'}]TreeSet:
treeSet集合的特点:
1.TreeSet是一个有序的集合,它的作用是提供有序的Set集合。它继承了AbstractSet抽象类,实现了NavigableSet,Cloneable,Serializable接。
2,它是非线程安全的,TreeSet是基于TreeMap实现的
3,同样是不可重复的‘
4,不允许有null值,会出现空指针异常。
5,遍历元素是需要使用比较器的,String对象和包装类对象不需要,它们内部已经使用了。要不然会出现类型转换异常。
代码示例:
存入String对象的元素:
public class CollectionTest06 {
public static void main(String[] args) {
//创建TreeSet对象
Set set= new TreeSet();
//添加元素
set.add("张三");
set.add("李四");
set.add("王五");
set.add("张三");//存入重复元素,会被自动剔除
System.out.println(set);
}
}
结果:[张三, 李四, 王五]但是如果存储的是其他对象的话,会出现以下情况:
public class CollectionTest07 {
public static void main(String[] args) {
Set set= new TreeSet();
set.add(new Student("张三",10));
set.add(new Student("李四",10));
set.add(new Student("王五",10));
System.out.println(set);
}
}
class Student{
private String name;
private int id;
public Student(){}
public Student(String name, int id) {
this.name = name;
this.id = id;
}
}
解决方法1:
对象实现Comarable接口,重写compareTo方法。
public class CollectionTest07 {
public static void main(String[] args) {
Set set= new TreeSet();
set.add(new Student("张三",10));
set.add(new Student("李四",10));
set.add(new Student("王五",10));
for (Object o:set){
System.out.println(o);
}
}
}
//实现Comparable
class Student implements Comparable{
private String name;
private int id;
public Student(){}
public Student(String name, int id) {
this.name = name;
this.id = id;
}
//重写Comparable的compareTo方法
@Override
public int compareTo(Object o) {
Student student=(Student) o;
//根据name来进行排序
return String.CASE_INSENSITIVE_ORDER.compare(this.name,student.name);
}
//重写toString方法
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
结果:
Student{name='张三', id=10}
Student{name='李四', id=10}
Student{name='王五', id=10}解决方法2:
用匿名内部类,创建Comparator对象,重写compare方法。
public class CollectionTest08 {
public static void main(String[] args) {
Set set= new TreeSet(new Comparator<Students>() {
@Override
public int compare(Students o1, Students o2) {
return String.CASE_INSENSITIVE_ORDER.compare(o1.name,o2.name);
}
});
set.add(new Students("张三",10));
set.add(new Students("李四",10));
set.add(new Students("王五",10));
for (Object o:set){
System.out.println(o);
}
}
}
//实现Comparable
class Students {
String name;
int id;
public Students(){}
public Students(String name, int id) {
this.name = name;
this.id = id;
}
//重写toString方法
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
结果:
Student{name='张三', id=10}
Student{name='李四', id=10}
Student{name='王五', id=10}LinkedHashSet :
使用和HashSet基本一样,但是使用它们时都要注意效率问题。然后决定使用哪一个。
1、LinkedHashSet是HashSet的子类
2、LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组+双向链表
3,添加第一次时,直接将数组table扩容到16,存放的结点类型是 LinkedHashMap$Entry
4、LinkedHashSet根据元素的hashCode值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的
5,LinkedHashSet不允许添加重复元素
代码示例:
import java.util.LinkedHashSet;
import java.util.Objects;
public class LinkedHashSetExercise01 {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(new Car("奥拓",1000));
linkedHashSet.add(new Car("奥迪",30000));
linkedHashSet.add(new Car("法拉利",1000));
linkedHashSet.add(new Car("宝马",1000));
linkedHashSet.add(new Car("奥迪",30000));
System.out.println(linkedHashSet);
}
}
class Car{
private String name;
private double price;
//重写equals方法和hashCode
//当name和price相同时,就返回相同的hashCode值,equals返回T
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
public Car(String name, double price) {
this.name = name;
this.price = price;
}
}
结果:
[Car{name='奥拓', price=1000.0}, Car{name='奥迪', price=30000.0},
Car{name='法拉利', price=1000.0}, Car{name='宝马', price=1000.0}]Map集合:
1,Map是一个接口,java.util.Map包下
2,Map和Collection没有继承关系
3,Map集合一key-value的方式存储数据(键值对)
key和value都是引用数据类型。
key和value都是存储对象的内存地址
key起主导作用,value是key的附属品。
4,Map集合是存储无序,且不可重复的。
key值是不允许为null值的,但是value是可以有null值。
注意只要key-value一个或两个不同都是代表不同的两个元素。
5,Map接口中常用的方法:
V put(K key, V value); 向Map集合中添加键值对(前面的V是泛型)
V get(Object key); 通过key获取value
int size(); 获取Map键值对的个数
boolean isEmpty(); 判断Map集合中元素个数是否为0
boolean containsKey(Object key); 判断Map集合中是否包含某个key
boolean containsValue(Object value); 判断Map集合中是否包含某个value
V remove(Object key); 通过key删除简直对
void clear(); 清空Map集合
Set<K> keySet(); 获取Map集合所有的key(所有的键组成一个Set集合)
Collection<V> values(); 获取Map集合所有的value(所有的键组成一个Collection集合)
Set<Map.Entry<K, V>> entrySet();
//取的是键和值的映射关系,就是把一个键值对存储到一个Set元素中。
Map集合方法代码示例:
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTest01 {
public static void main(String[] args) {
//创建一个Map集合对象
Map map= new HashMap<>();
//往集合当中添加元素,key-value,都是引用数据类型
map.put("key","value");
map.put("张三",10);
map.put("李四",null);//value可以为null
map.put(new Object(),"这是Object类的value");
//获取Map集合的元素个数map.size()
System.out.println("map集合元素的个数为:"+map.size());
//获取Map对象是会自动在key-value中间添加=号连接
System.out.println(map);
//根据key值获取value,如果没有对应的元素,返回null值
System.out.println("key对应的value为:"+map.get("key"));
System.out.println("张三对应的value为:"+map.get("张三"));
System.out.println("李四对应的value为:"+map.get("李四"));
System.out.println("输入的key没有则输出:"+map.get("王五"));
// 获取Map集合所有的key(所有的键组成一个Set集合)
Set set = map.keySet();
System.out.println("map集合中所有的key:"+set);
//获取Map集合所有的value(所有的value组成一个Collection集合)
Collection values = map.values();
System.out.println("map集合中所有的value:"+values);
//取的是键和值的映射关系,就是把一个键值对存储到一个Set元素中。
Set set1 = map.entrySet();
System.out.println(set1);
}
}
结果:
map集合元素的个数为:4
{李四=null, 张三=10, java.lang.Object@1540e19d=这是Object类的value, key=value}
key对应的value为:value
张三对应的value为:10
李四对应的value为:null
输入的key没有则输出:null
map集合中所有的key:[李四, 张三, java.lang.Object@1540e19d, key]
map集合中所有的value:[null, 10, 这是Object类的value, value]
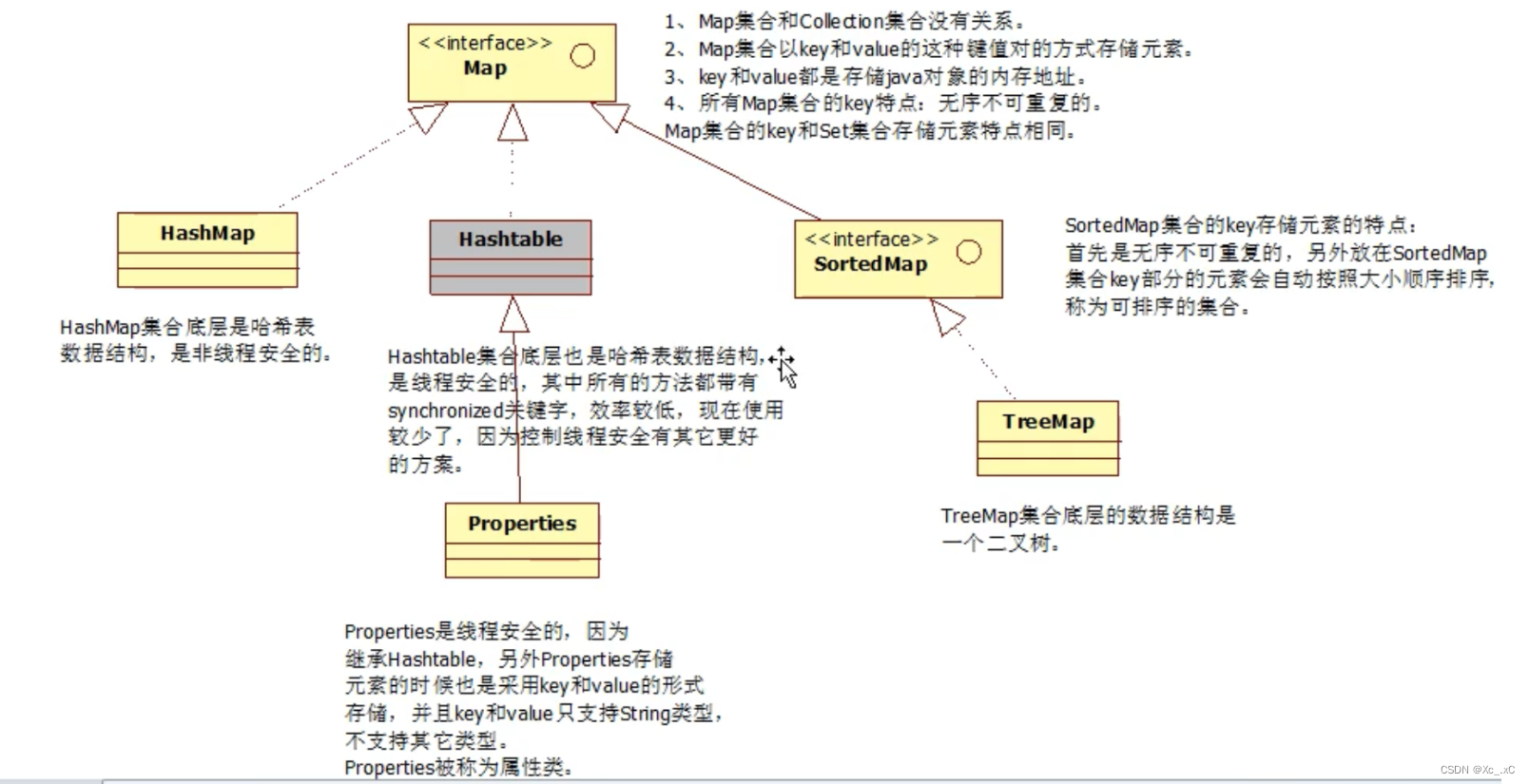
[李四=null, 张三=10, java.lang.Object@1540e19d=这是Object类的value, key=value]Map集合的继承关系:
这只是列举出常用的接口和实现类:
Map集合的遍历:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTest02 {
public static void main(String[] args) {
//创建一个Map集合对象
Map map= new HashMap<>();
//往集合当中添加元素,key-value,都是引用数据类型
map.put("key","value");
map.put("张三",10);
map.put("李四",null);//value可以为null
map.put(new Object(),"这是Object类的value");
//遍历Map集合
//注意Map集合没有获取迭代器对象的方法
//获取所有的key,通过key获取value
Set set = map.keySet();
Iterator it = set.iterator();
while (it.hasNext()){
Object key= it.next();
Object value = map.get(key);
System.out.println(key+"="+value);
}
System.out.println("=============");
//通过增强for循环遍历
for (Object key:set){
System.out.println(key+"="+map.get(key));
}
}
}
结果:
李四=null
张三=10
java.lang.Object@1540e19d=这是Object类的value
key=value
=============
李四=null
张三=10
java.lang.Object@1540e19d=这是Object类的value
key=valueMap集合主要的实现类:
1,HashMap
2, HashTable(后面做解释)
3, TreeMap
4,Proporties
注意:他们的用法和上面的Map集合的示例是差不多的,但是他们使用的时候都有自己的特点。就是他们的存储原理,数据结构的特点是不同的。
需要注意的是:
在HashMap中:
1,放在HashMap集合的Key部分的元素,以及放在HashSet集合的元素,
需要同时重写hashCode和equals方法。
2,HashMap集合初始化默认是16,默认加载因子是0.75.
默认加载因子就是当HashMap底层数组的容量达到75%,数组开始扩容
3,如果一个类的equals方法重写了那么hashCode方法必须重写
如果使用equals方法返回的值是true,那么hashCode方法返回的值一定是一样的.
在TreeMap中:
1,底层使用的是二叉树的数据结果存储数据的.
2,TreeMap和TreeSet中数据存储是有序的
TreeMap集合中的key和TreeSet中元素需要使用比较器进行排序
Proporties:
Java.util.Properties。
以键值对的方式存储数据,key和value都是String类型。
一般和IO流一起使用,用于读取配置文件。
需要注意它的独有的存储数据和读取数据:
代码演示:
public class MapTest05 {
public static void main(String[] args) {
//第一种方法创建Properties对象
Map map=new Properties();
//第一种方法添加对象。
map.put("url","jdbc");
//第一种通过key来获取value对象
System.out.println(map.get("url"));
//第二种方法创建Properties对象
Properties pro= new Properties();
//第二种方法添加对象。
pro.setProperty("username","root");
//第二种通过key来获取value对象
System.out.println(pro.getProperty("username"));
}
}
结果:
jdbc
root














 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









