






引出自监督学习
问题:标记数据少
自监督学习(SSL)
- 思想:从没有标记的数据里学习到不同组织和器官的特征
- 应用:三维医学图像分割
自监督学习中的传统MIM存在问题
自监督学习(SSL)里的MIM
- 方法:重建 随机掩码图像(随机遮挡图像的某个部分)
- 功能:学习细节表示
- 问题:需要大量训练数据
对传统MIM进行改进
改进区域
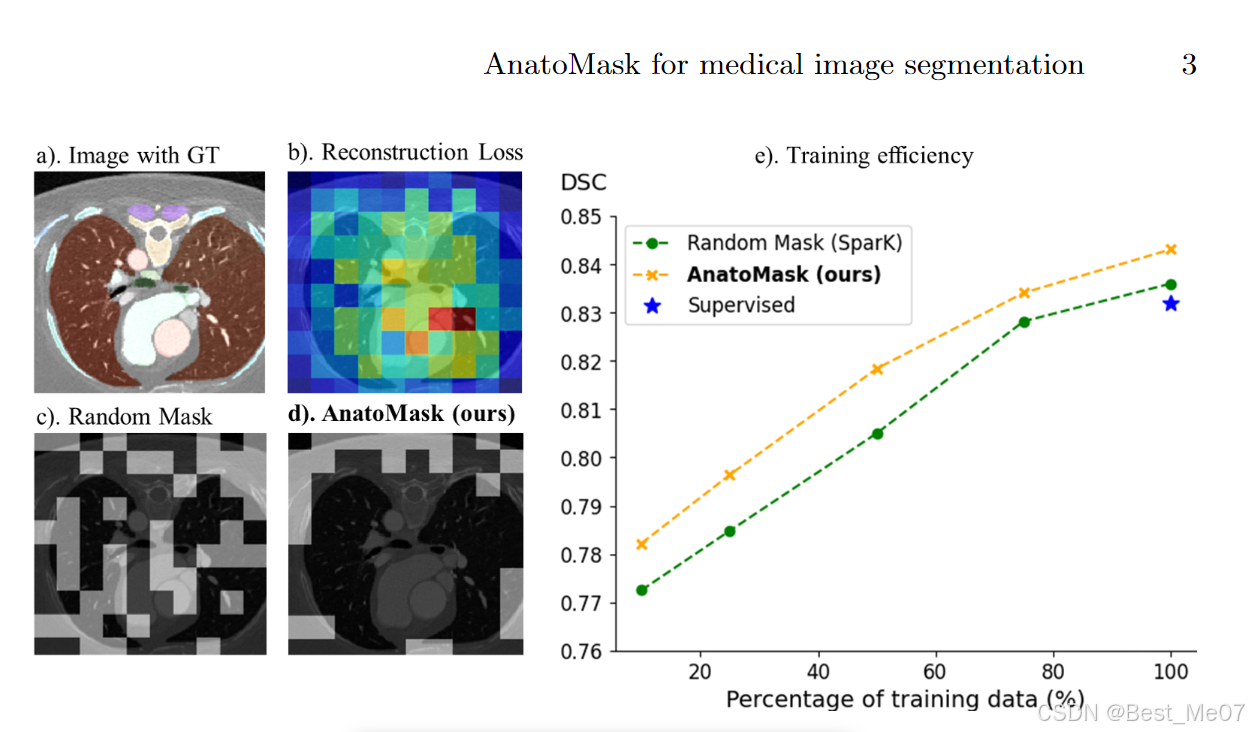
随机掩码
- 方法:均匀采样医学图像的所有区域
- 问题:如果随机掩盖重要区域(比如心,肺等)会学习不到关键的特征->降低预训练的效率
改进
新的MIM方法AnatoMask
- 方法:
- 计算机先重建图像的一部分,如果哪部分重建的不好(损失函数大),则那些区域很可能是重要的区域(因为重要的区域复杂难重建)
- 计算机记住这部分重建的不好的区域(重要区域),下一次优先掩盖这部分区域,让计算机专注于学习这部分区域的特征
其中利用的方法
自蒸馏方法
- 自蒸馏方法是一种训练技术,涉及到两个网络:
- 教师网络:处理输入数据,产生输出(比如哪部分区域是重要的,优先屏蔽)
- 学生网络:尝试复制教师网络的行为(比如尝试找到哪部分区域是重要的 和 尝试重建重要区域)
掩蔽动力学函数
- 作用:避免次优学习
**注释:**次优学习
-
指的是计算机学习的效果不是最理想的,可能学习的都是最简单的或最难的
-
在这里:计算机如果只学习重建简单区域,可能在遇到复杂区域时重建能力差
-
方法:用掩蔽动力学函数(这个函数就像是老师)会根据计算机的学习情况来调整训练难度。
结果
- 在4个具有多种成像模式(CT、MRI和PET)的公共数据集上评估
- 与现有的SSL方法相比,AnatoMask展示了卓越的性能和可扩展性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









