







1 准备环境
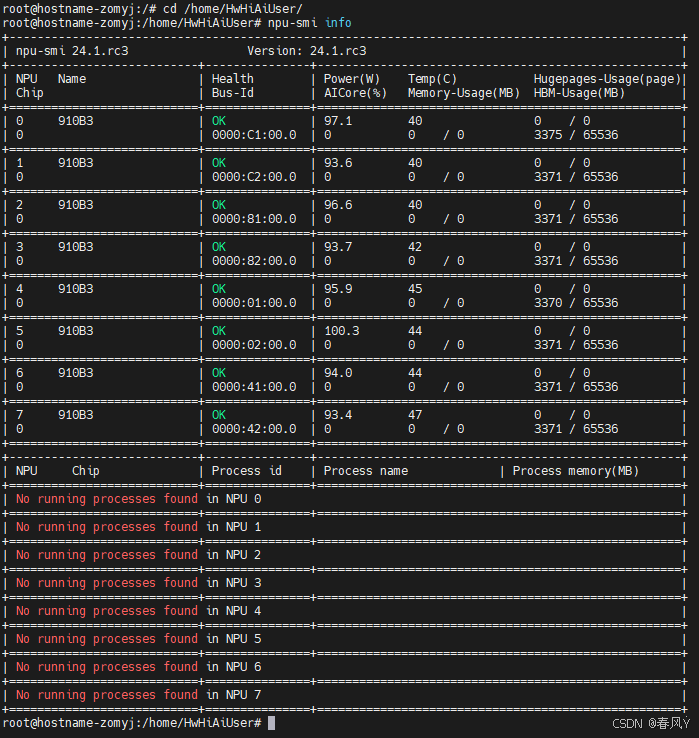
检查设备驱动:
npu-smi info
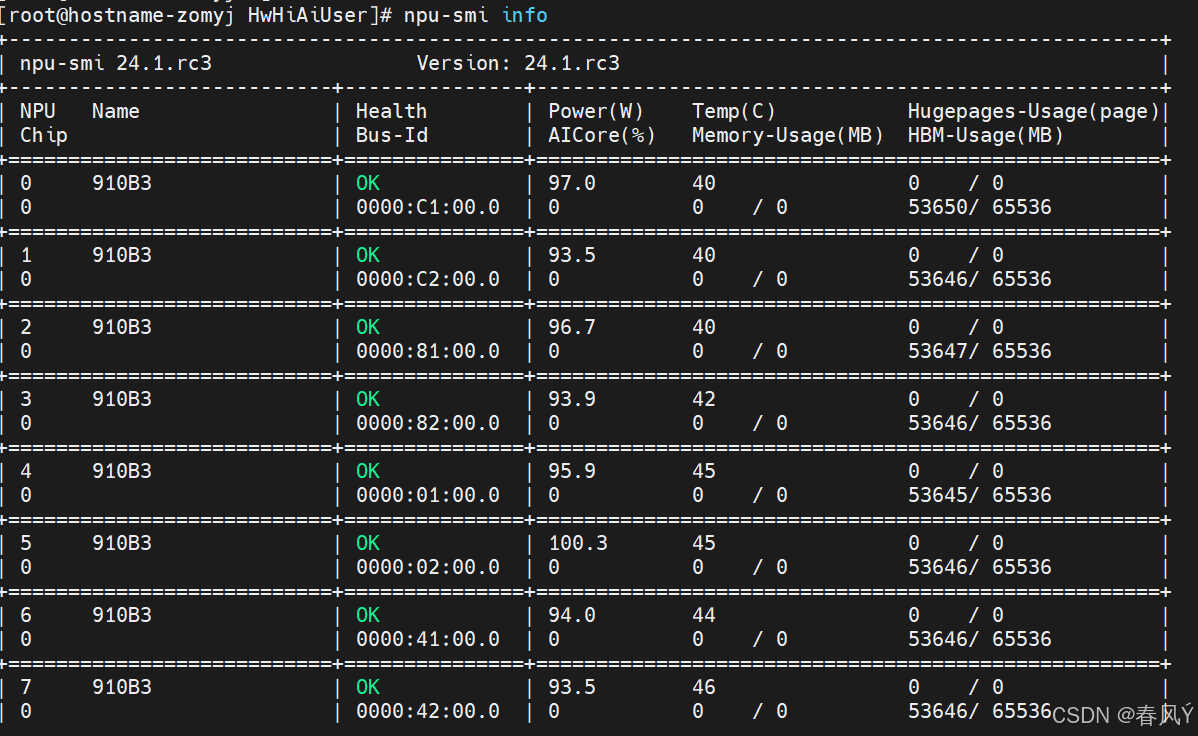
可以看到设备的驱动版本是24.1.rc3。
2 下载模型
进入ModelScope魔搭社区下载通义千问2-VL-7B-Instruct模型。
安装ModelScope包:
pip install modelscope
创建download.py文件:
touch download.py
或者编辑download.py文件:
vim download.py
# 模型下载
from modelscope import snapshot_download
# 可以根据需求修改下载模型的路径
model_dir = snapshot_download('Qwen/Qwen2-VL-7B-Instruct',cache_dir="/home/HwHiAiUser/")
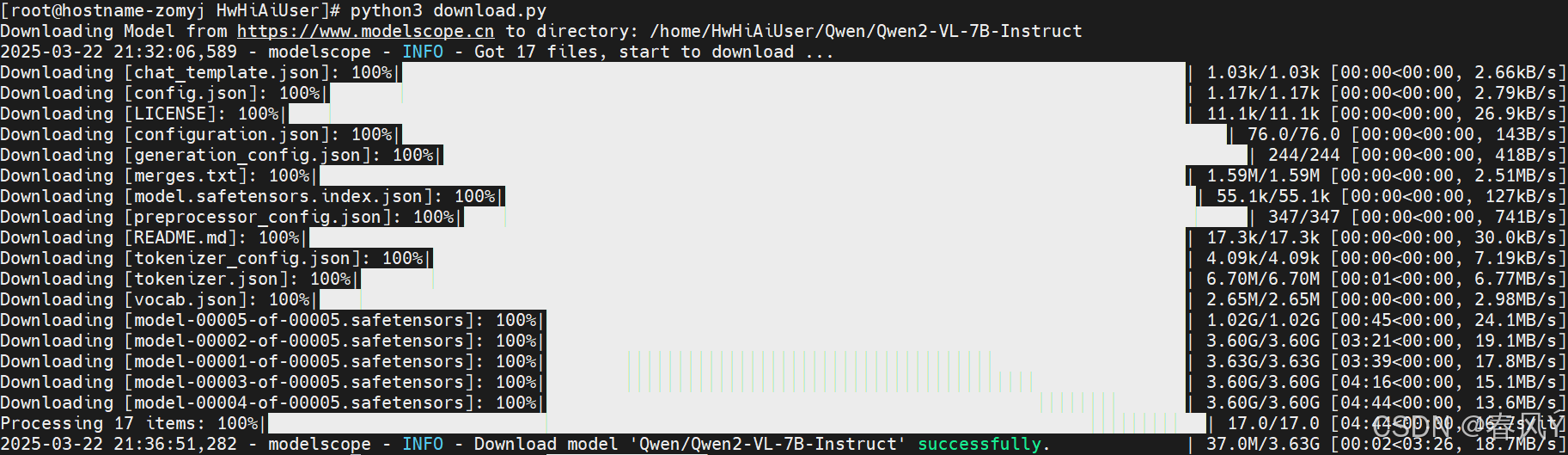
运行download.py,将模型下载到指定目录/home/HwHiAiUser/。
python3 download.py
3 构建昇腾mindie环境
3.1 获取800I A2镜像
方法1:从昇腾镜像仓库的官方路径获取800I A2镜像。
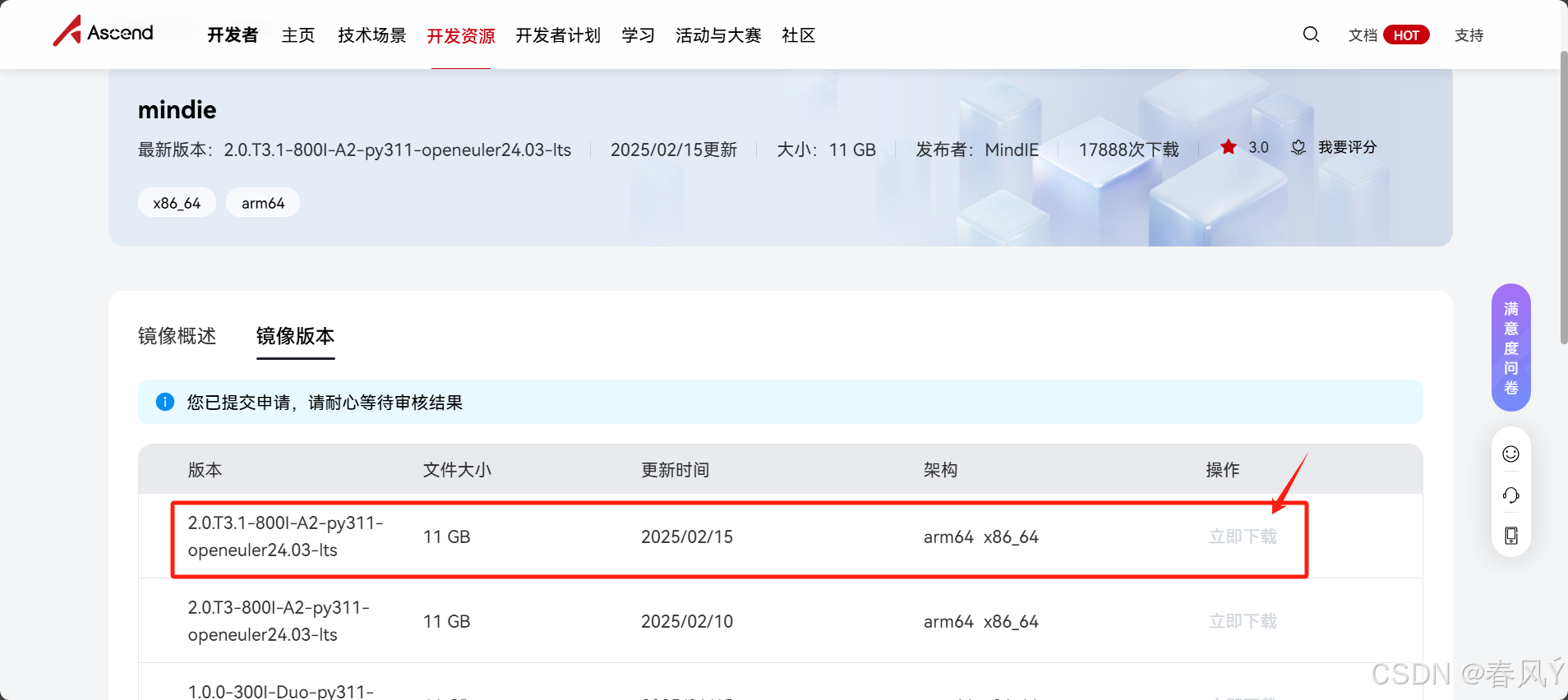
方法2:从docker获取800I A2镜像。
- 安装docker
yun install docker
- 拉取镜像
docker pull swr.cn-east-317.qdrgznjszx.com/sxj731533730/mindie:1.0.T71-800I-A2-py311-ubuntu22.04-arm64
报错:

修改配置文件/ect/docker/daemon.json,修改配置源,并添加mindie的镜像源,同时将下载路径修改在/home/HwHiAiUser/docker中。
{
"data-root": "/home/HwHiAiUser/docker",
"insecure-registries": ["https://swr.cn-east-317.qdrgznjszx.com"],
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
重新启动docker服务,后继续拉取镜像:
systemctl restart docker.service

3.2 检查并编辑镜像启动脚本
查看docker的本地镜像,获取其中的REPOSITORY和TAG字段。

编辑快速启动Docker容器并配置运行环境的Shell脚本docker_run.sh,将其中的REPOSITORY和TAG字段以冒号的形式分隔,并填写到docker_images字段。(以下启动的是8卡容器)
#!/bin/bash
docker_images=swr.cn-east-317.qdrgznjszx.com/sxj731533730/mindie:1.0.T71-800I-A2-py311-ubuntu22.04-arm64
model_dir=/home/HwHiAiUser # 可自定义挂载目录
docker run -it -u root --ipc=host --net=host \
--name mindie_1 \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/bin/hccn_tool:/usr/bin/hccn_tool \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/common \
-v /usr/local/Ascend/driver/lib64/driver:/usr/local/Ascend/driver/lib64/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/vnpu.cfg:/etc/vnpu.cfg \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v ${model_dir}:${model_dir} \
-v /var/log/npu:/usr/slog \
${docker_images} /bin/bash
3.3 启动镜像并进入容器查看环境是否可用
bash docker_run.sh

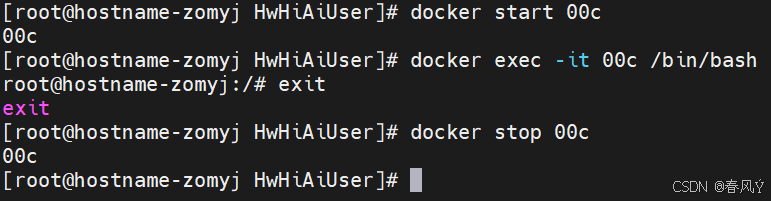
查看所有容器:
docker ps -a

启动容器:
docker start 00c
进入容器:
docker exec -it 00c /bin/bash
退出容器:
exit
停止容器:
docker stop 00c
4 使用LLaMa-Factory训练
4.1 下载并配置LLaMa-Factory环境
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e '.[torch,metrics]'

4.2 编辑配置文件
- 从模板中拷贝配置文件:
cp examples/train_lora/llama3_lora_sft.yaml examples/train_lora/qwen2_VL_7B_Instruct_lora_sft.yaml

2. 修改配置文件:
去LLaMA-Factory官网查找template。

### model
model_name_or_path: /home/HwHiAiUser/Qwen/Qwen2-VL-7B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity,alpaca_en_demo
template: qwen2_vl
cutoff_len: 2048
max_samples: 1000
ove 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









