






一、Redis分布式存储方案
1、哈希取余分区
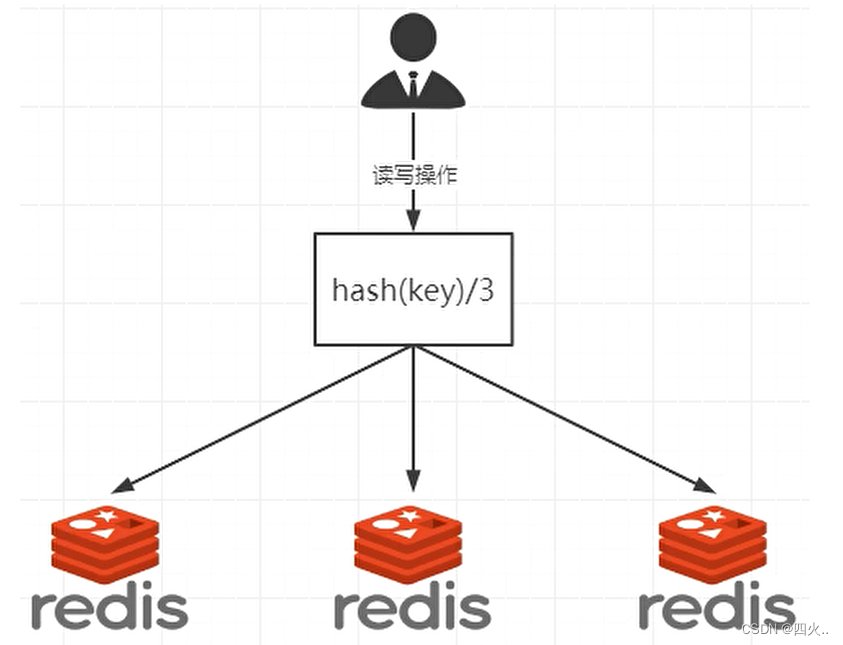
①、原理
- 哈希计算:首先,对每个键(key)进行哈希计算,得到一个整数哈希值(hash value)。
- 取余操作:将这个哈希值对服务器数量进行取余操作(modulus operation),得到一个余数。
- 分配服务器:这个余数就是服务器的索引,这样就可以确定这个键应该存储到哪一台服务器上。
- 公式:server_index=hash(key)%number_of_servers
②、示例
假设我们有 3 台 Redis 服务器,编号分别为 0、1 和 2。我们要存储以下键值对:
"user:1000"
"user:1001"
"user:1002"
假设我们使用简单的哈希函数(如 Python 中的 hash() 函数)来计算哈希值。
- 对 “user:1000” 进行哈希计算,假设哈希值为 2301。取余操作:2301 % 3 = 2,因此 “user:1000” 存储到服务器 2。
- 对 “user:1001” 进行哈希计算,假设哈希值为 5290。取余操作:5290 % 3 = 1,因此 “user:1001” 存储到服务器 1。
- 对 “user:1002” 进行哈希计算,假设哈希值为 7923。取余操作:7923 % 3 = 0,因此 “user:1002” 存储到服务器 0。
③、优点
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分雨治之的作用。
实现简单:哈希取余算法非常简单易实现,不需要复杂的配置和维护。
快速定位:可以快速计算出数据应该存储在哪台服务器上。
④、缺点
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)3会变成Hash(key)/?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
扩展性差:增加或删除服务器时,几乎所有的数据都需要重新分布。这是因为哈希取余算法高度依赖服务器数量的固定值。
数据倾斜:如果哈希函数不好,可能会导致部分服务器负载过重,而其他服务器几乎没有负载(数据分布不均)。
2、一致性哈希算法分区
①、原理
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。一致性哈希算法得目的就是为了解决当服务器数量发生变动时,减少影响客户端与服务器的映射关系
一致性哈希将所有的键和值以及服务器映射到一个虚拟的哈希环上。哈希环的基本原理如下:
- 哈希环:将哈希值空间组织成一个环形结构(通常是 0 到 2^32-1 的范围是一个线性空间,但是经过算法控制使0=2^32让他形成一个环形空间)。
- 节点哈希:对每个服务器节点进行哈希运算,并将其映射到环上的某一点。
- 数据哈希:对每个键进行哈希运算,并将其映射到环上的某一点。
- 顺时针查找:从数据的哈希值开始,顺时针查找第一个节点,这个节点就是数据应存储的位置。
②、示例
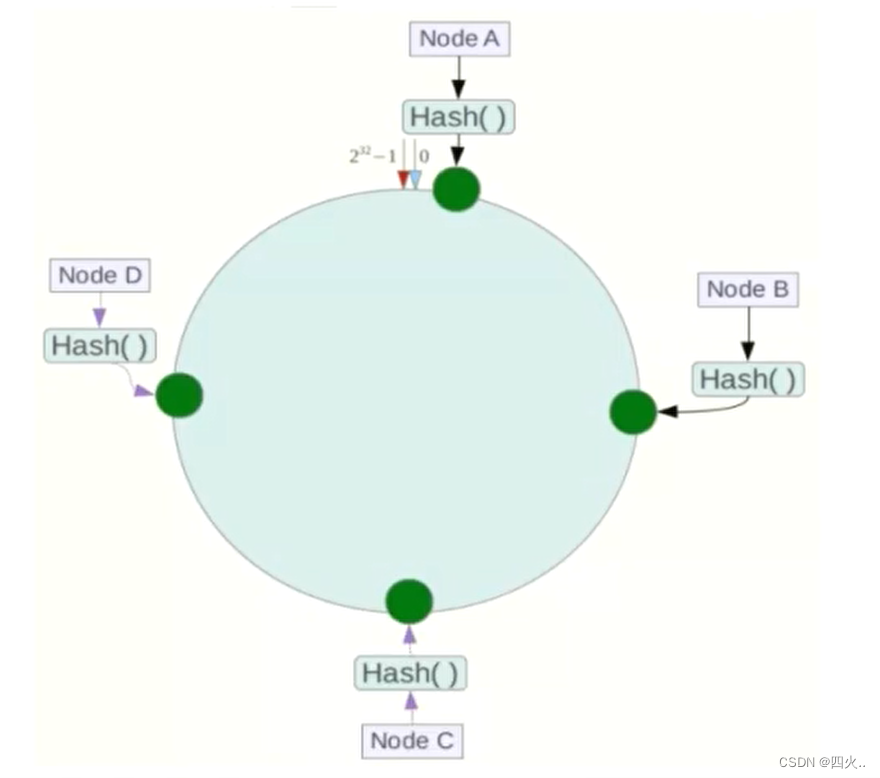
节点映射
将集群中各个IP节点映射到环上的某一个位置。将各个服务器使用Hash进行一个哈希值计算,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。
假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
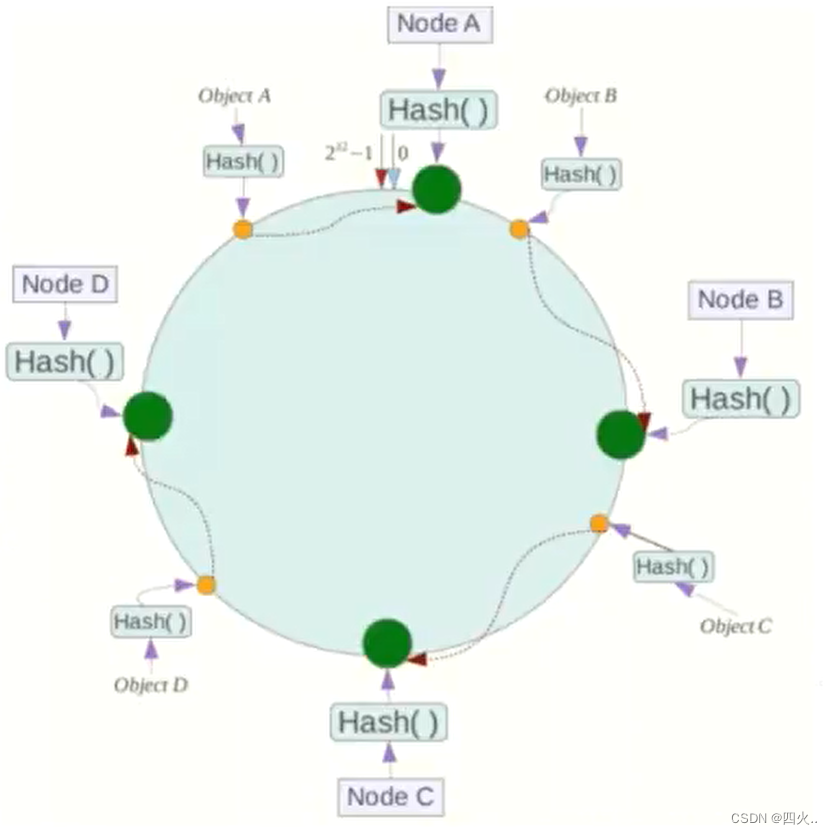
key落到哈希环的规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有ObiectA、ObiectB、Obiectc、ObiectD四个数据对象,经过哈希计算后,在环空间上的位置如下;根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到NodeC上,D被定为到Node D上。
③、优点
容错性:节点故障时的自愈能力
假设Node C宕机,可以看到此时对象A、B、D不受到影响,只有C对象被重定位到NodeD。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
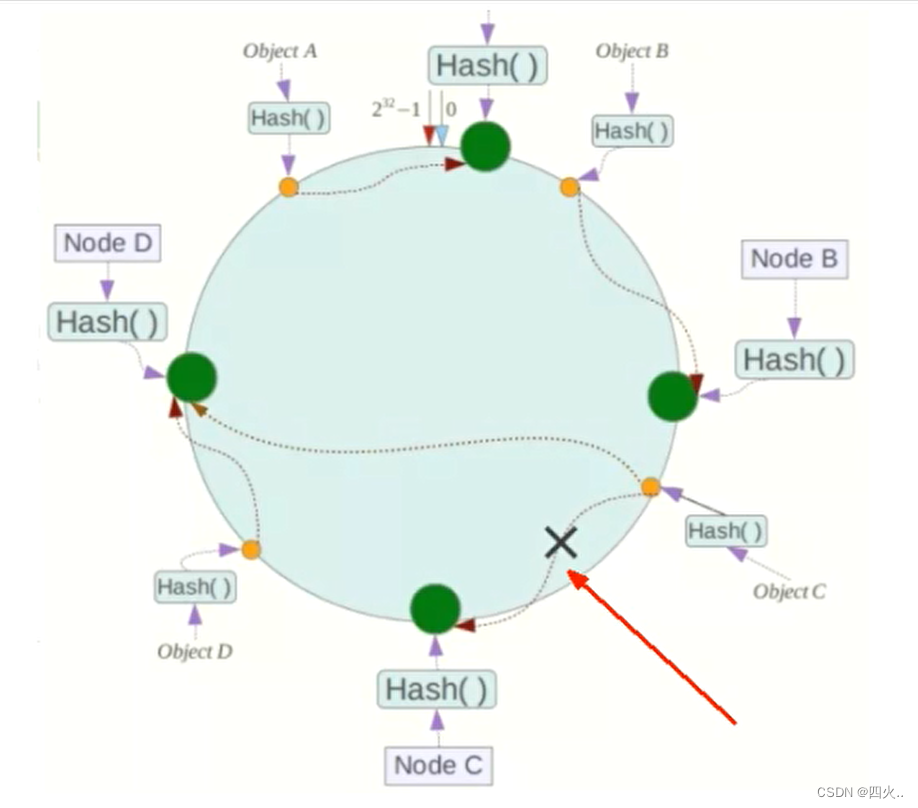
扩展性:平滑扩展
数据量增加了,需要增加一台节点NodeX的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
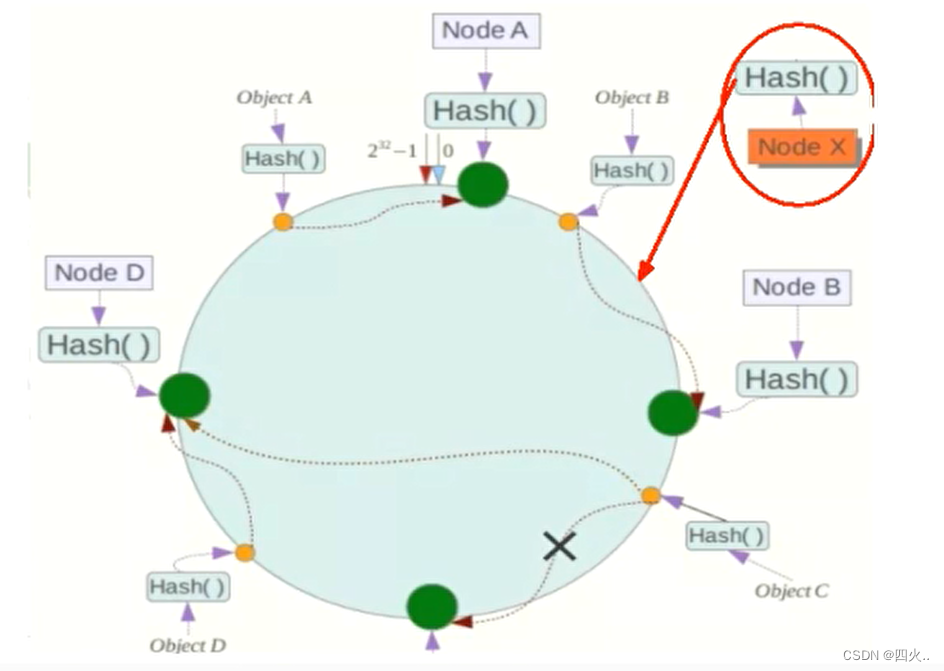
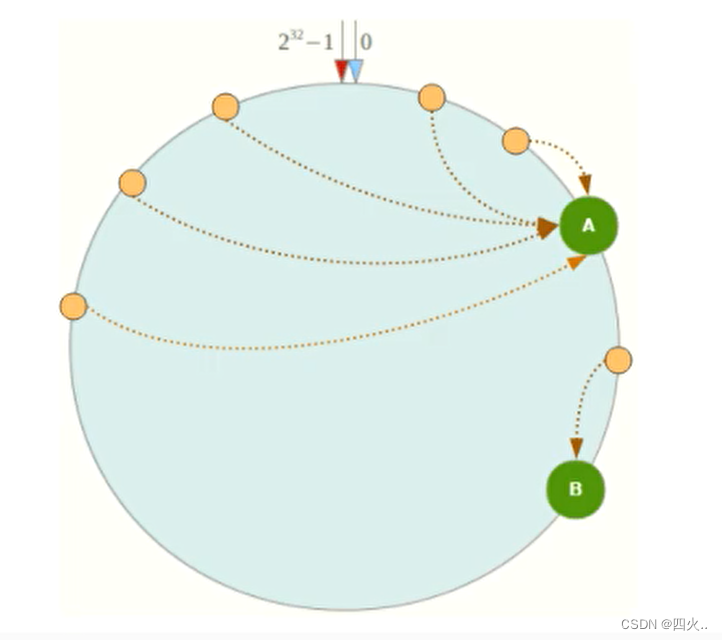
④、缺点
数据倾斜
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。
例如系统中只有两台服务器:
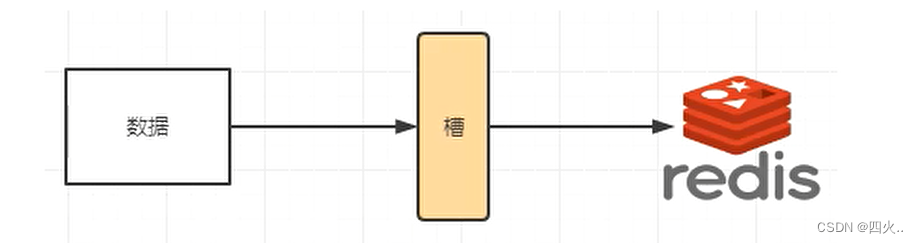
3、哈希槽分区(大企业)
①、原理
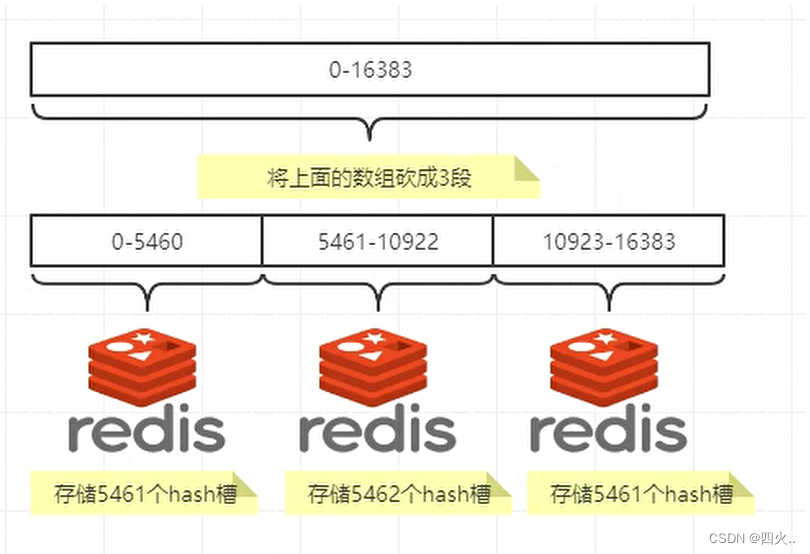
- 哈希槽:Redis Cluster 将所有可能的键空间分成 16384 个哈希槽。每个键通过哈希函数映射到一个槽,槽的范围是 0 到 16383。哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
- 节点:Redis 集群中的每个节点负责管理部分哈希槽。节点数量可以动态增加或减少,槽的分配也可以重新分配。
- 哈希函数:Redis 使用 CRC16 哈希函数计算键的哈希值,然后对 16384 取模,得到对应的哈希槽编号:slot=CRC16(key)%16384
哈希槽的出现是为了解决一致性哈希的数据倾斜问题。解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配
一个集群只能有16384个槽,编号0-16383(0-2^14-1) 。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给那个主节点。集群会记录节点和槽的对应关系。
解决了节点和槽的关系后,接下来就需要对kev求哈希值,然后对16384取余,余数是几key就落入对立的槽里。slot=CRC16(key)%16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
②、示例
redis集群中内置了 16384个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个key 都会对应一个编号在 0-16383之间的哈希槽,也就是映射到某个节点上。如下代码,key之A、B在Node2,key之C落在Node3上
二、3主3从redis集群配置(哈希槽分区)
1、关闭防火墙和启动Docker服务(Ubuntu)
systemctl stop ufw
systemctl start docker

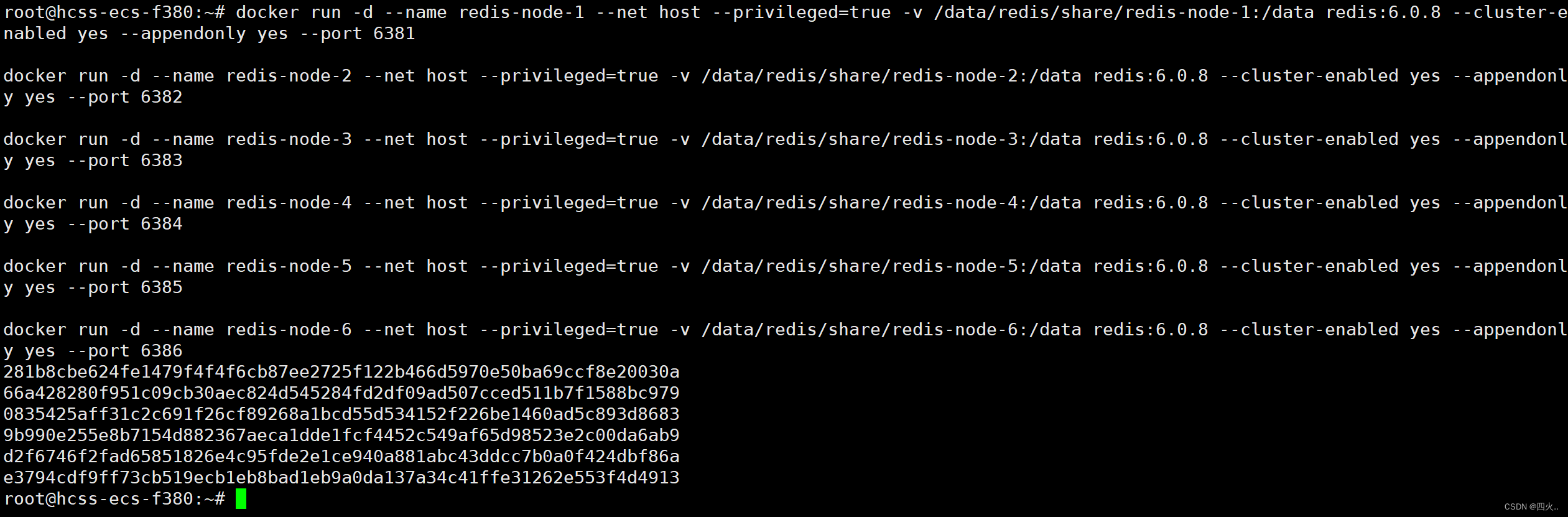
2、新建6个docker容器实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
启动了一个名为 redis-node-1 的 Redis 容器,启用了集群模式和 AOF 持久化,并通过 6381 端口对外提供服务,同时将主机的 /data/redis/share/redis-node-1 目录挂载为容器内的 /data 目录。
docker run -d:以守护进程模式(后台运行)启动一个新的容器。
--name redis-node-1:给容器指定一个名字为 redis-node-1。这样你可以通过名字而不是容器 ID 来管理和访问这个容器。
--net host:让容器使用主机的网络堆栈。这样,容器将直接使用主机的 IP 地址和端口。需要注意的是,这可能会带来一些安全问题,因为容器将完全暴露在主机网络上。
--privileged=true:以特权模式运行容器。这样容器将拥有更高的权限,类似于主机上的 root 权限。这在某些需要高权限操作的应用中是必要的,但同样也增加了安全风险。
-v /data/redis/share/redis-node-1:/data:将主机的 /data/redis/share/redis-node-1 目录挂载到容器内的 /data 目录。这样,容器中的 Redis 可以使用主机上的存储来保存数据。
redis:6.0.8:使用 Redis 版本 6.0.8 的镜像来创建容器。
--cluster-enabled yes:启用 Redis 集群模式。这是 Redis 集群配置的一部分,用于实现数据分片和高可用性。
--appendonly yes:启用 AOF(Append Only File)持久化方式。这会将每一个写操作记录到日志文件中,以确保数据的持久性。
--port 6381:将 Redis 服务绑定到端口 6381。由于使用了 --net host,这个端口将直接绑定到主机的端口 6381。
查看容器是否运行
docker ps -a

3、创建集群关系
①、进入容器
随便进入一台redis容器
docker exec -it redis-node-1 bash
②、构建主从关系
构建主从关系(主动对应关系为随机,不固定)
redis-cli --cluster create 192.168.2.159:6381 192.168.2.159:6382 192.168.2.159:6383 192.168.2.159:6384 192.168.2.159:6385 192.168.2.159:6386 --cluster-replicas 1
redis-cli:Redis 命令行工具,用于与 Redis 服务器进行交互。
--cluster create:这是 redis-cli 提供的一个选项,用于创建一个 Redis 集群。
192.168.2.159:6381 192.168.2.159:6382 192.168.2.159:6383 192.168.2.159:6384 192.168.2.159:6385 192.168.2.159:6386:这是一系列 Redis 实例的地址和端口号,用来构建 Redis 集群。在这个命令中,共有六个节点,分别位于相同的 IP 地址 192.168.2.159 上的不同端口号。
--cluster-replicas 1:这个参数指定了集群中的副本数量。在这个命令中,指定了每个主节点都会有一个对应的从节点。副本数量的设置对于集群的可用性和容错性非常重要,它确保了在主节点故障时可以自动切换到从节点以保证服务的可用性。
确认配置
# 使用 redis-cli 工具创建 Redis 集群
redis-cli --cluster create 192.168.2.159:6381 192.168.2.159:6382 192.168.2.159:6383 192.168.2.159:6384 192.168.2.159:6385 192.168.2.159:6386 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
# 分配哈希槽到 6 个节点上...
# 为每个主节点分配哈希槽范围
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
# 为每个主节点添加副本
#192.168.2.159:6385 作为 192.168.2.159:6382 的从节点
#192.168.2.159:6386 作为 192.168.2.159:6383 的从节点
#192.168.2.159:6384 作为 192.168.2.159:6381 的从节点
Adding replica 192.168.2.159:6385 to 192.168.2.159:6381
Adding replica 192.168.2.159:6386 to 192.168.2.159:6382
Adding replica 192.168.2.159:6384 to 192.168.2.159:6383
>>> Trying to optimize slaves allocation for anti-affinity
# 尝试优化从节点的分配以避免同一主机上有主从节点
[WARNING] Some slaves are in the same host as their master
# 警告:某些从节点与其主节点在同一主机上
# 显示节点分配情况
#192.168.2.159:6381 负责哈希槽 0 到 5460
#192.168.2.159:6382 负责哈希槽 5461 到 10922
#192.168.2.159:6383 负责哈希槽 10923 到 16383
M: a421f32820b0924ec50a3a064d284817a629d91d 192.168.2.159:6381
slots:[0-5460] (5461 slots) master
M: ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b 192.168.2.159:6382
slots:[5461-10922] (5462 slots) master
M: 1b6d461fa6f3af02c88a519cda9ab8caed80699d 192.168.2.159:6383
slots:[10923-16383] (5461 slots) master
S: 851835d6b208dfee42cfecd6385c9eedf11437cd 192.168.2.159:6384
replicates a421f32820b0924ec50a3a064d284817a629d91d
S: 1c97e82bbaaee20f1c39768fff522a0087e40e5c 192.168.2.159:6385
replicates ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b
S: 0ec13cdb76d3c5af9abc4f20679e6ef005a98af0 192.168.2.159:6386
replicates 1b6d461fa6f3af02c88a519cda9ab8caed80699d
# 确认是否应用上述配置,输入 'yes' 确认
Can I set the above configuration? (type 'yes' to accept): yes
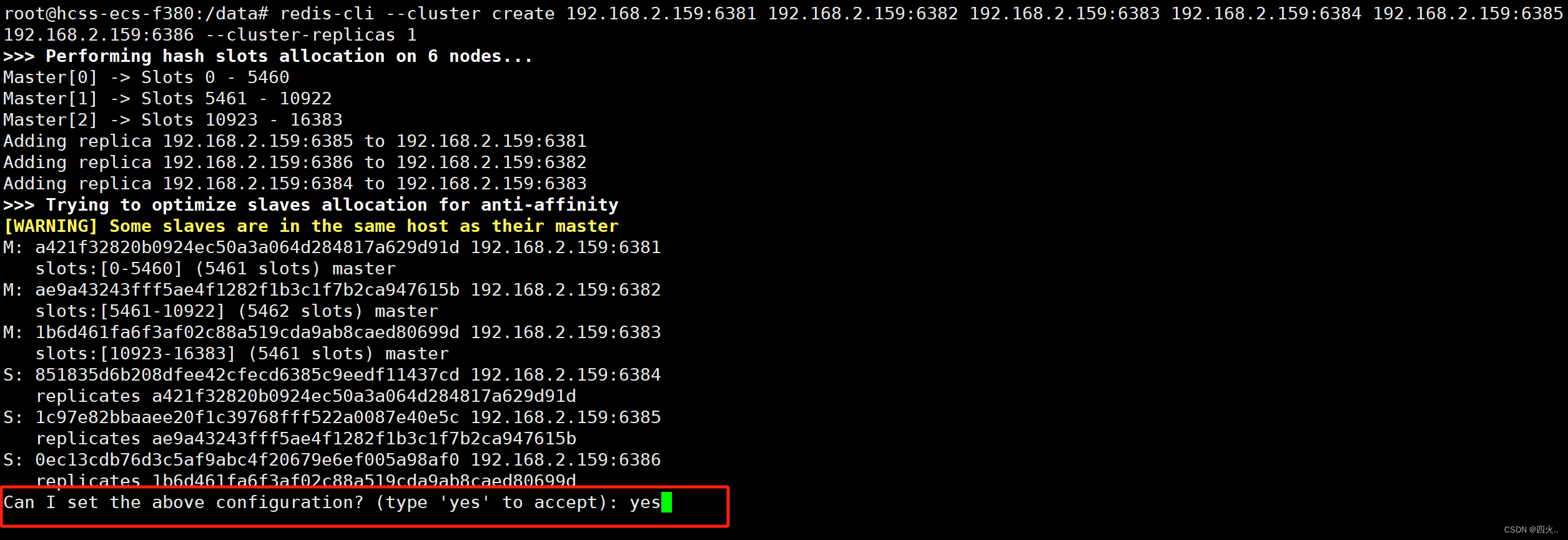
成功配置并运行,所有 16384 个哈希槽已被正确分配并覆盖
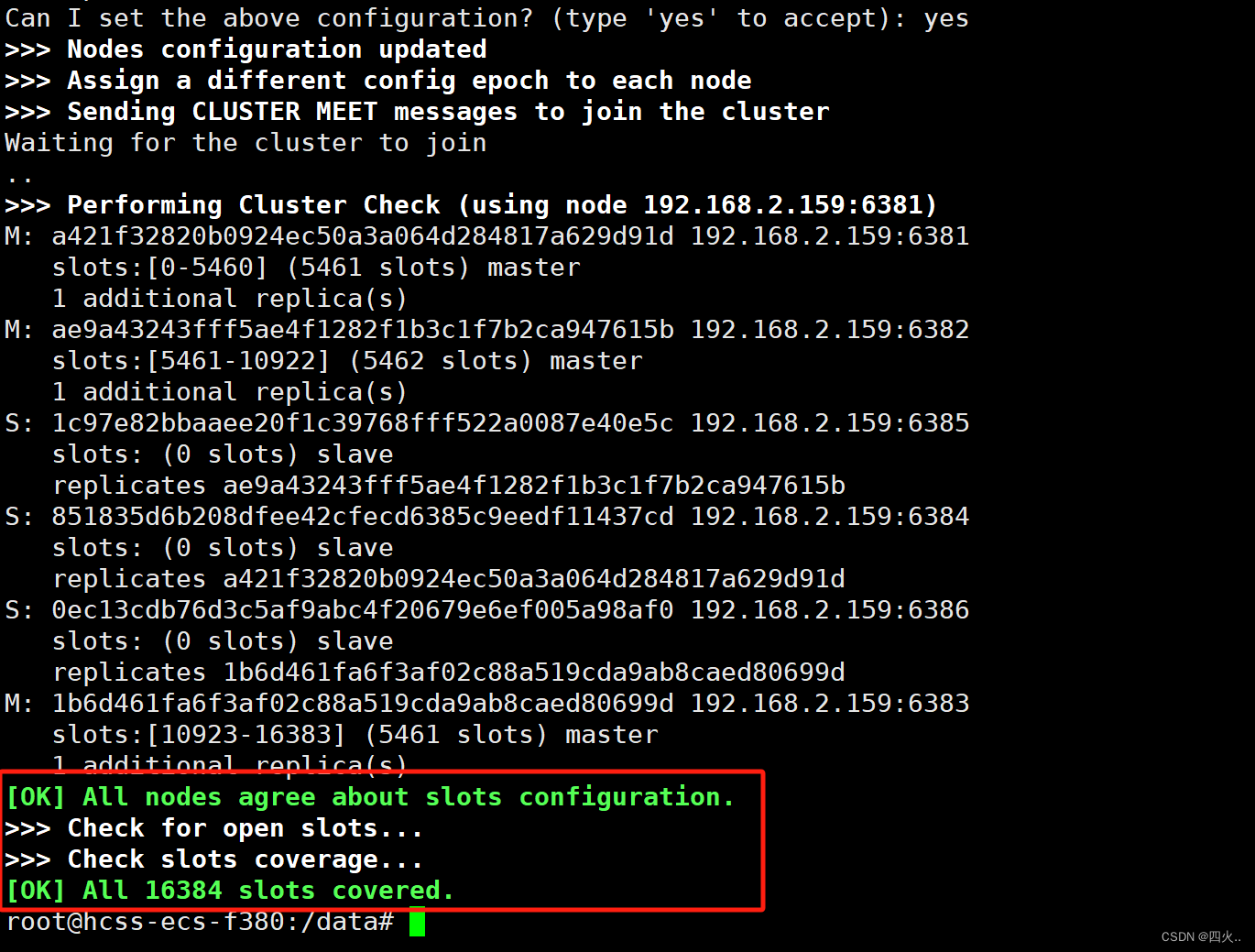
4、查看集群状态
1、连接redis客户端(redis-node-1为例)
redis-cli -p 6381

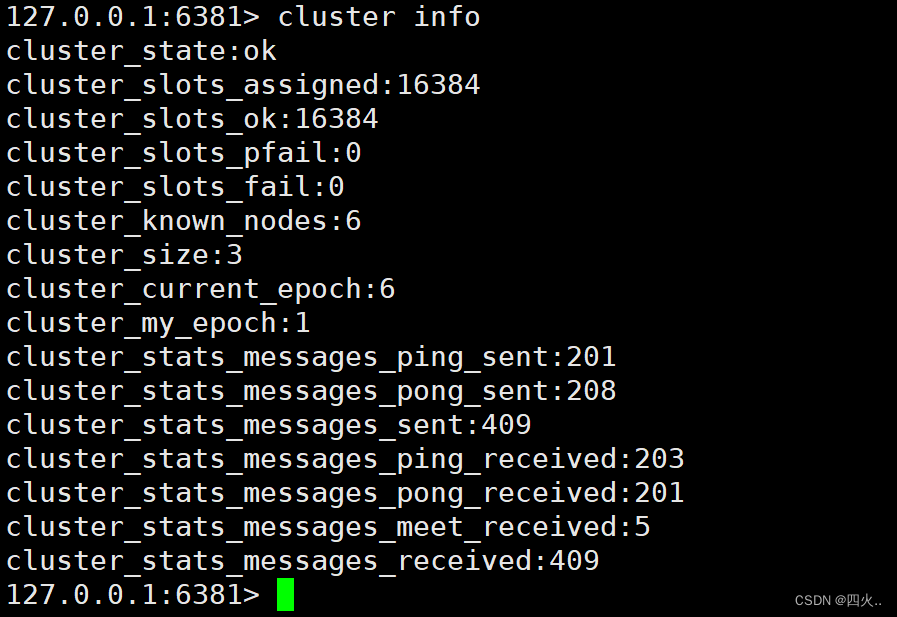
127.0.0.1:6381> cluster info
cluster_state:ok
# 集群状态:ok 表示集群状态正常。
cluster_slots_assigned:16384
# 分配的哈希槽数量:16384 表示所有槽都已分配。
cluster_slots_ok:16384
# 正常的哈希槽数量:16384 表示所有槽都正常。
cluster_slots_pfail:0
# 潜在失效的哈希槽数量:0 表示没有潜在失效的槽。
cluster_slots_fail:0
# 失效的哈希槽数量:0 表示没有失效的槽。
cluster_known_nodes:6
# 已知的节点数量:6 表示集群中共有 6 个节点(3 个主节点,3 个从节点)。
cluster_size:3
# 集群大小:3 表示集群中有 3 个主节点。
cluster_current_epoch:6
# 当前纪元:6 表示当前集群的配置纪元。
cluster_my_epoch:1
# 当前节点的纪元:1 表示当前查询的节点的配置纪元。
cluster_stats_messages_ping_sent:201
# 发送的 PING 消息数量:201 表示集群中已发送了 201 条 PING 消息,用于节点之间的心跳检测。
cluster_stats_messages_pong_sent:208
# 发送的 PONG 消息数量:208 表示集群中已发送了 208 条 PONG 消息,用于响应 PING 消息。
cluster_stats_messages_sent:409
# 发送的总消息数量:409 表示集群中已发送了 409 条消息(包括 PING 和 PONG 消息)。
cluster_stats_messages_ping_received:203
# 接收到的 PING 消息数量:203 表示集群中已接收到 203 条 PING 消息。
cluster_stats_messages_pong_received:201
# 接收到的 PONG 消息数量:201 表示集群中已接收到 201 条 PONG 消息。
cluster_stats_messages_meet_received:5
# 接收到的 MEET 消息数量:5 表示集群中已接收到 5 条 MEET 消息,用于节点加入集群时的通信。
cluster_stats_messages_received:409
# 接收到的总消息数量:409 表示集群中已接收到 409 条消息(包括 PING、PONG 和 MEET 消息)。
127.0.0.1:6381> cluster nodes
ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b 192.168.2.159:6382@16382 master - 0 1716360075833 2 connected 5461-10922
# 节点ID:ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b
# 节点地址:192.168.2.159:6382
# 节点角色:主节点(master)
# 状态:connected
# 哈希槽范围:5461-10922
# 配置纪元:2
1c97e82bbaaee20f1c39768fff522a0087e40e5c 192.168.2.159:6385@16385 slave ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b 0 1716360074000 2 connected
# 节点ID:1c97e82bbaaee20f1c39768fff522a0087e40e5c
# 节点地址:192.168.2.159:6385
# 节点角色:从节点(slave)
# 主节点ID:ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b
# 状态:connected
# 配置纪元:2
851835d6b208dfee42cfecd6385c9eedf11437cd 192.168.2.159:6384@16384 slave a421f32820b0924ec50a3a064d284817a629d91d 0 1716360074832 1 connected
# 节点ID:851835d6b208dfee42cfecd6385c9eedf11437cd
# 节点地址:192.168.2.159:6384
# 节点角色:从节点(slave)
# 主节点ID:a421f32820b0924ec50a3a064d284817a629d91d
# 状态:connected
# 配置纪元:1
0ec13cdb76d3c5af9abc4f20679e6ef005a98af0 192.168.2.159:6386@16386 slave 1b6d461fa6f3af02c88a519cda9ab8caed80699d 0 1716360074000 3 connected
# 节点ID:0ec13cdb76d3c5af9abc4f20679e6ef005a98af0
# 节点地址:192.168.2.159:6386
# 节点角色:从节点(slave)
# 主节点ID:1b6d461fa6f3af02c88a519cda9ab8caed80699d
# 状态:connected
# 配置纪元:3
1b6d461fa6f3af02c88a519cda9ab8caed80699d 192.168.2.159:6383@16383 master - 0 1716360074000 3 connected 10923-16383
# 节点ID:1b6d461fa6f3af02c88a519cda9ab8caed80699d
# 节点地址:192.168.2.159:6383
# 节点角色:主节点(master)
# 状态:connected
# 哈希槽范围:10923-16383
# 配置纪元:3
a421f32820b0924ec50a3a064d284817a629d91d 192.168.2.159:6381@16381 myself,master - 0 1716360072000 1 connected 0-5460
# 节点ID:a421f32820b0924ec50a3a064d284817a629d91d
# 节点地址:192.168.2.159:6381
# 节点角色:主节点(master)
# 自己标识:myself
# 状态:connected
# 哈希槽范围:0-5460
# 配置纪元:1

三、主从容错迁移
1、数据读写存储
①、数据读写注意项
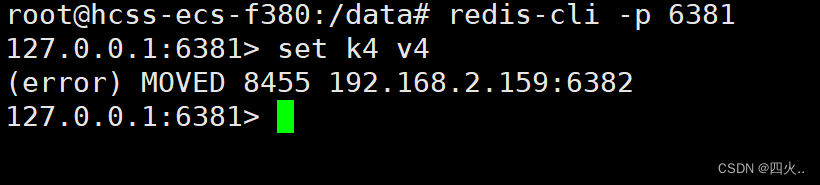
开启哈希槽集群模式后防止路由失效,连接redis客户端时需要带上-c选项
未加-c选项,报错无法存储数据
redis-cli -p 6381
127.0.0.1:6381> set k4 v4
(error) MOVED 8455 192.168.2.159:6382
127.0.0.1:6381>
哈希槽号是 8455。
目标节点是 192.168.2.159:6382。
这意味着键 k4 应该存储在负责哈希槽 8455 的节点 192.168.2.159:6382 上。
加入-c选项,启动 CLI 的集群模式,这样 CLI 会自动处理重定向
redis-cli -p 6381 -c
127.0.0.1:6381> set k4 v4
-> Redirected to slot [8455] located at 192.168.2.159:6382
OK
192.168.2.159:6382>
由于 k4 的哈希槽号为 8455,Redis 将请求重定向到负责该槽的节点 192.168.2.159:6382。

②、查看数据信息
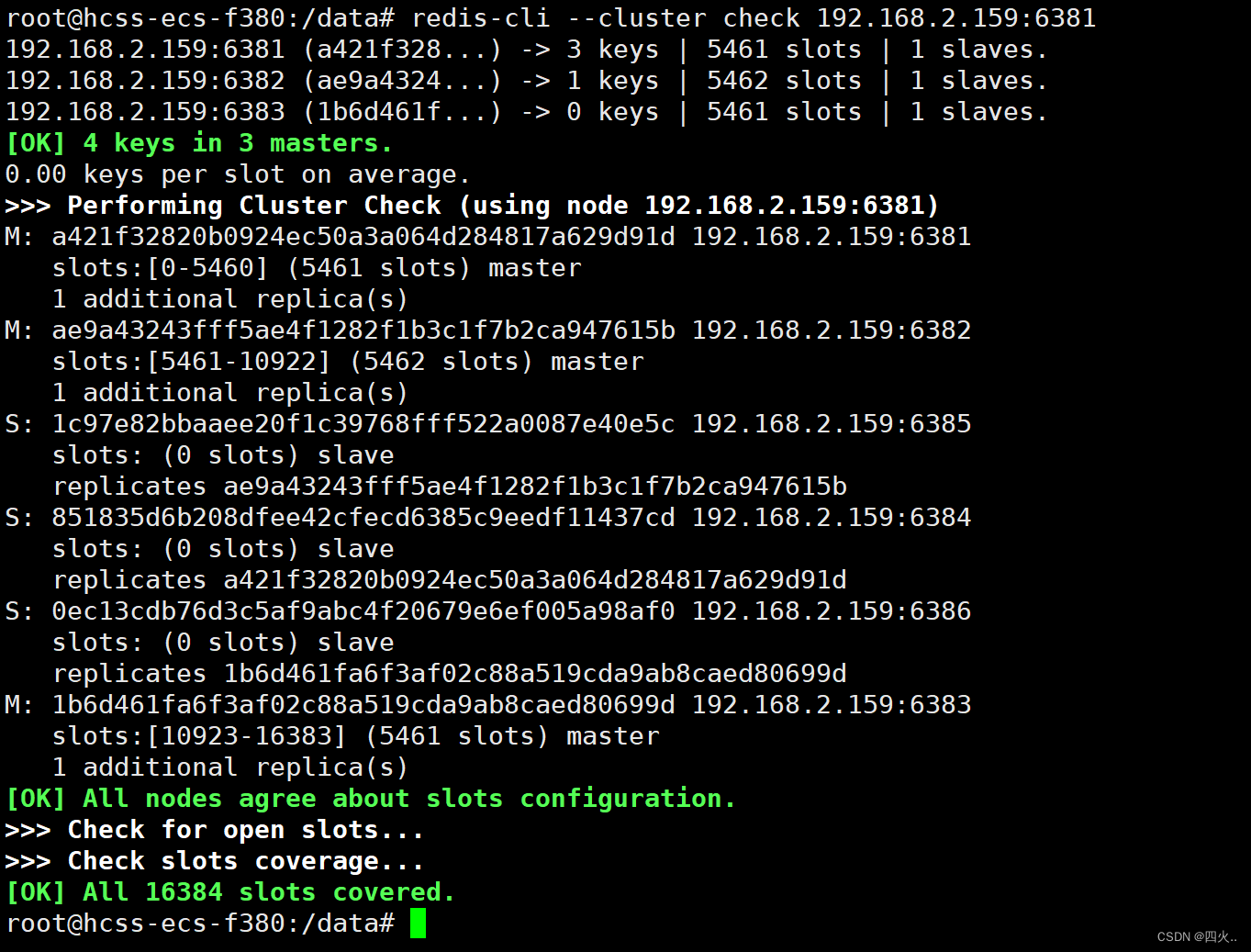
redis-cli --cluster check 192.168.2.159:6381
#节点 192.168.2.159:6381 的 ID 为 a421f328...,负责 5461 个插槽,当前存储 3 个键,有一个从节点。
192.168.2.159:6381 (a421f328...) -> 3 keys | 5461 slots | 1 slaves.
#节点 192.168.2.159:6382 的 ID 为 ae9a4324...,负责 5462 个插槽,当前存储 1 个键,有一个从节点。
192.168.2.159:6382 (ae9a4324...) -> 1 keys | 5462 slots | 1 slaves.
#节点 192.168.2.159:6383 的 ID 为 1b6d461f...,负责 5461 个插槽,当前没有存储键,有一个从节点。
192.168.2.159:6383 (1b6d461f...) -> 0 keys | 5461 slots | 1 slaves.
#集群中总共有 4 个键,分布在 3 个主节点上。
[OK] 4 keys in 3 masters.
#每个插槽平均分配的键数为 0.00(因为大多数插槽目前是空的)。
0.00 keys per slot on average.
#使用节点 192.168.2.159:6381 执行集群检查。
>>> Performing Cluster Check (using node 192.168.2.159:6381)
#M 表示这是一个主节点。a421f32820b0924ec50a3a064d284817a629d91d 是节点的 ID。slots:[0-5460] (5461 slots) 表示这个主节点负责插槽 0 到 5460,共 5461 个插槽。1 additional replica(s) 表示这个节点有一个从节点。
M: a421f32820b0924ec50a3a064d284817a629d91d 192.168.2.159:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b 192.168.2.159:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 1c97e82bbaaee20f1c39768fff522a0087e40e5c 192.168.2.159:6385
slots: (0 slots) slave
replicates ae9a43243fff5ae4f1282f1b3c1f7b2ca947615b
S: 851835d6b208dfee42cfecd6385c9eedf11437cd 192.168.2.159:6384
slots: (0 slots) slave
replicates a421f32820b0924ec50a3a064d284817a629d91d
S: 0ec13cdb76d3c5af9abc4f20679e6ef005a98af0 192.168.2.159:6386
slots: (0 slots) slave
replicates 1b6d461fa6f3af02c88a519cda9ab8caed80699d
M: 1b6d461fa6f3af02c88a519cda9ab8caed80699d 192.168.2.159:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
#所有节点关于插槽配置一致。
[OK] All nodes agree about slots configuration.
#检查打开的插槽(没有未覆盖的插槽)。
>>> Check for open slots...
>>> Check slots coverage...
#检查插槽覆盖情况,所有 16384 个插槽都被覆盖。
[OK] All 16384 slots covered.
2、容错切换迁移
①、主从切换验证
目前主从分布情况如下(根据实际情况而定):
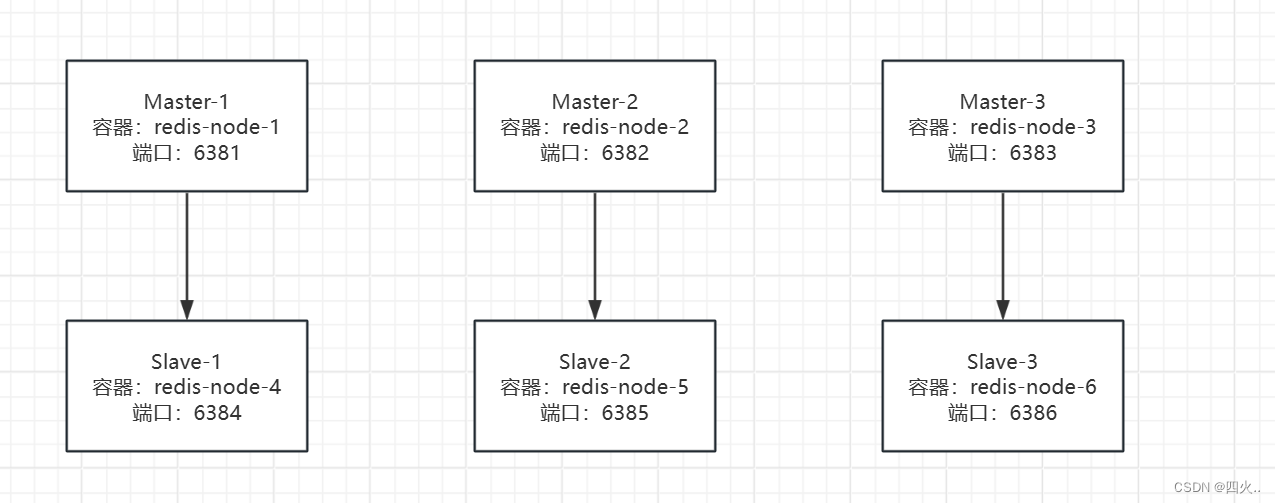
停止Master-1运行
docker stop redis-node-1

进入Slave-4容器
docker exec -it redis-node-4 bash

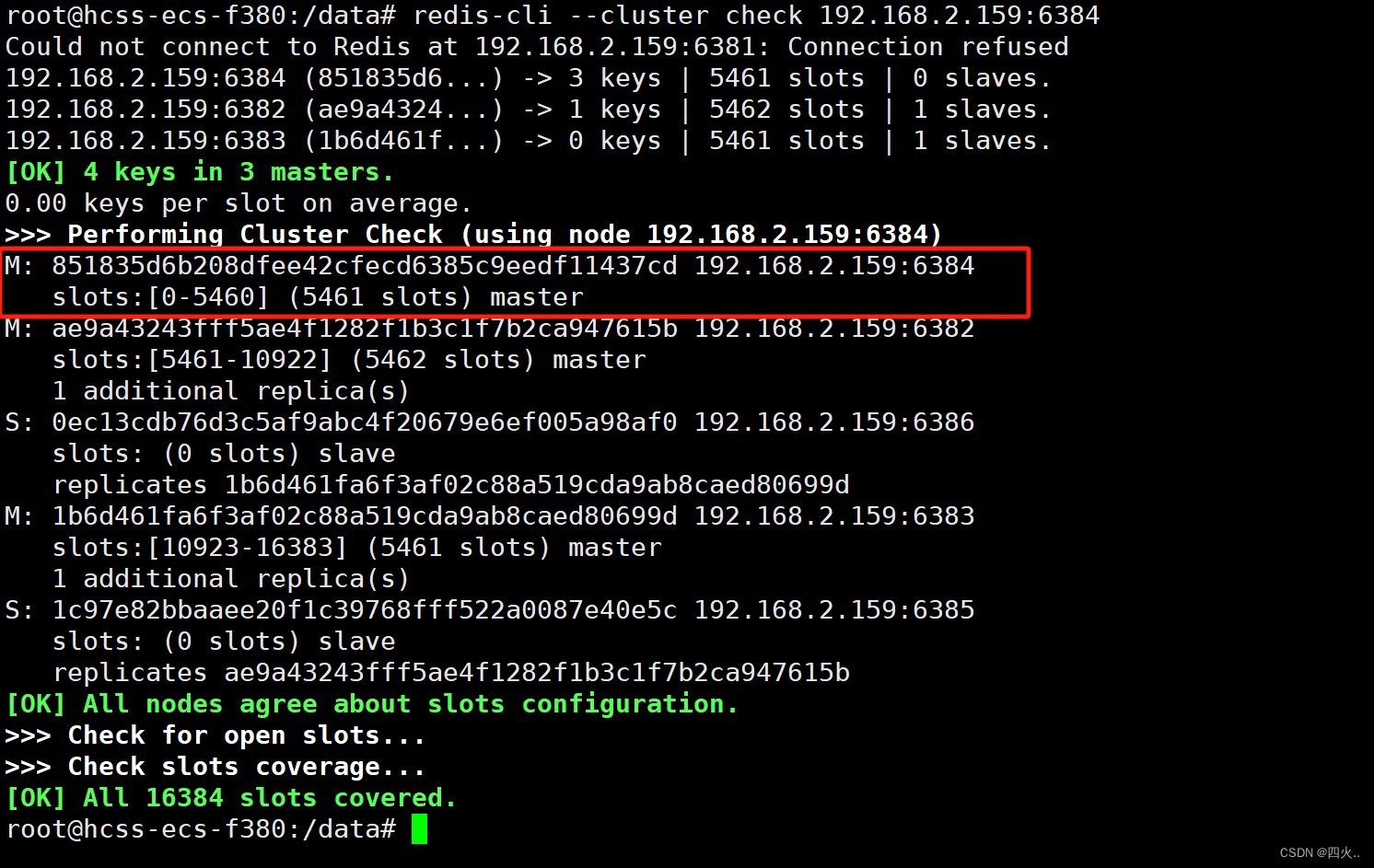
查看集群状态
redis-cli --cluster check 192.168.2.159:6384
②、还原主从
启动Master-1
docker start redis-node-1

停止Slave-4
docker stop redis-node-4

启动Slave-4(需要等几秒钟,等待心跳发送)
docker start redis-node-4
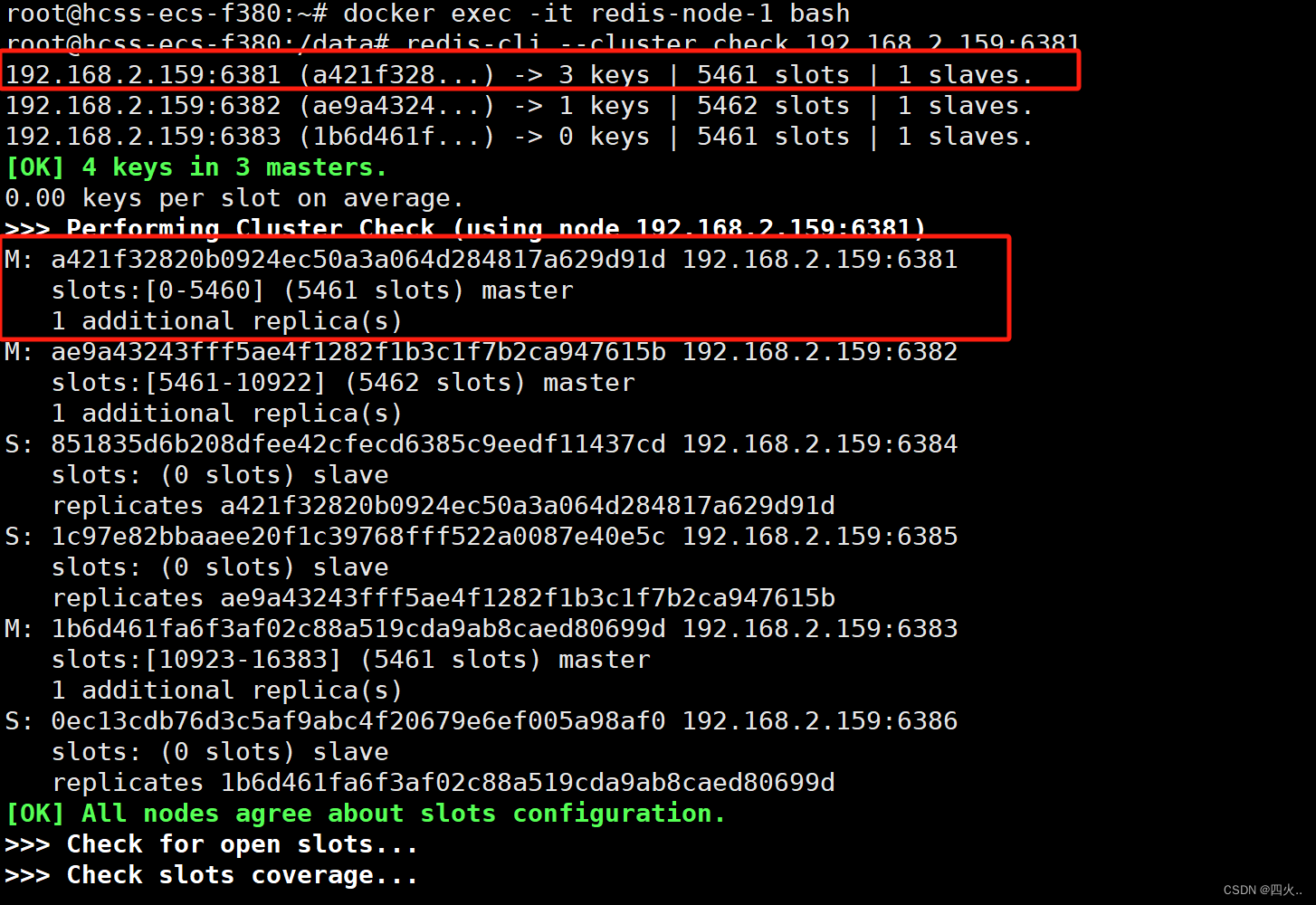
进入Master-1
docker exec -it redis-node-1 bash
查看集群信息
docker exec -it redis-node-1 bash
四、主从扩容
创建两个新redis容器7、8
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388

查看容器运行状态
docker ps -a

进入7号机容器内部
docker exec -it redis-node-7 bash

让7号作为master加入原集群
redis-cli --cluster add-node 192.168.2.159:6387 192.168.2.159:6381
将新增的6387作为master节点加入集群,
redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387就是将作为master新增节点
6381就是原来集群节点里面的领路人,相当于6387拜6381的码头从而找到组织加入集群
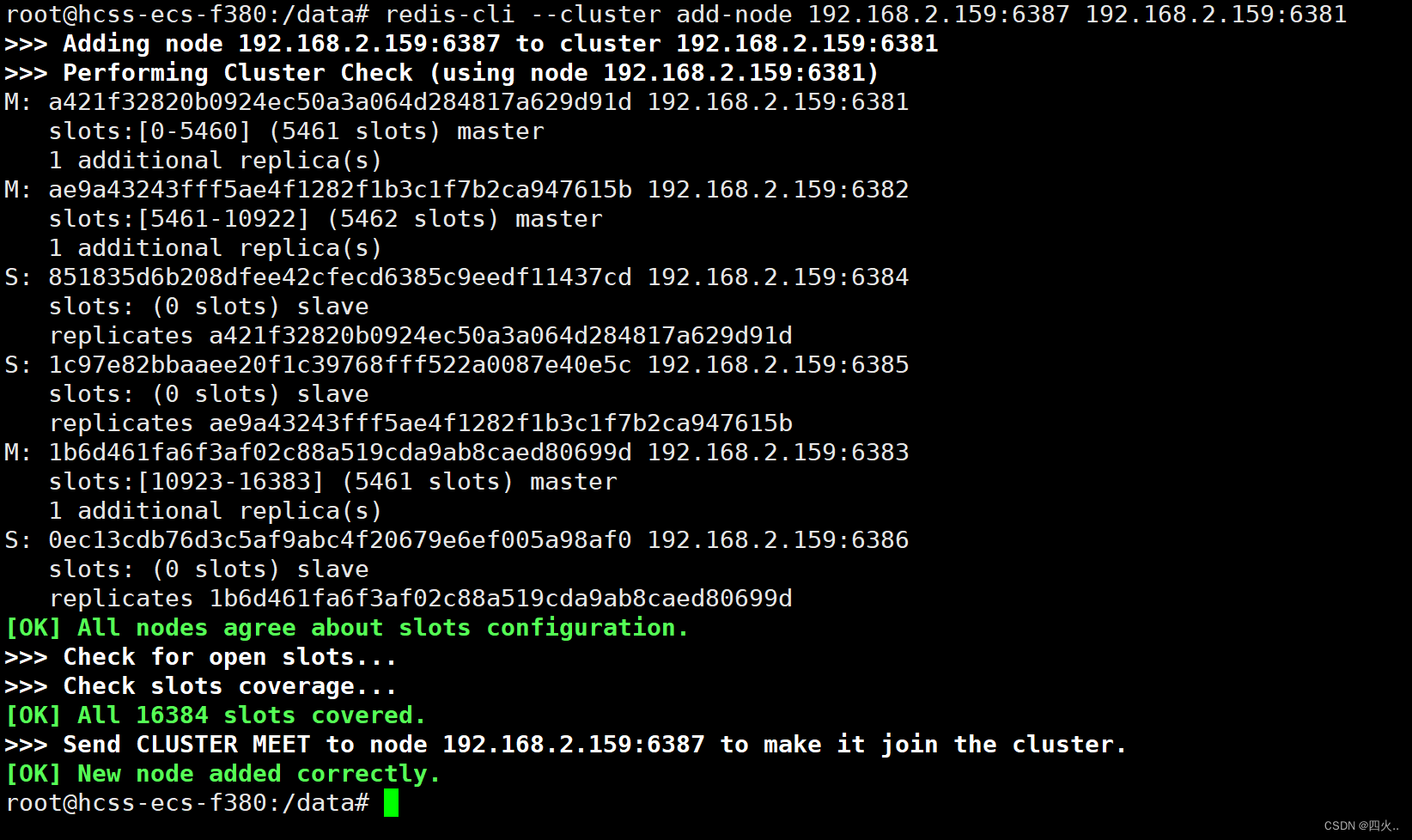
检查集群情况
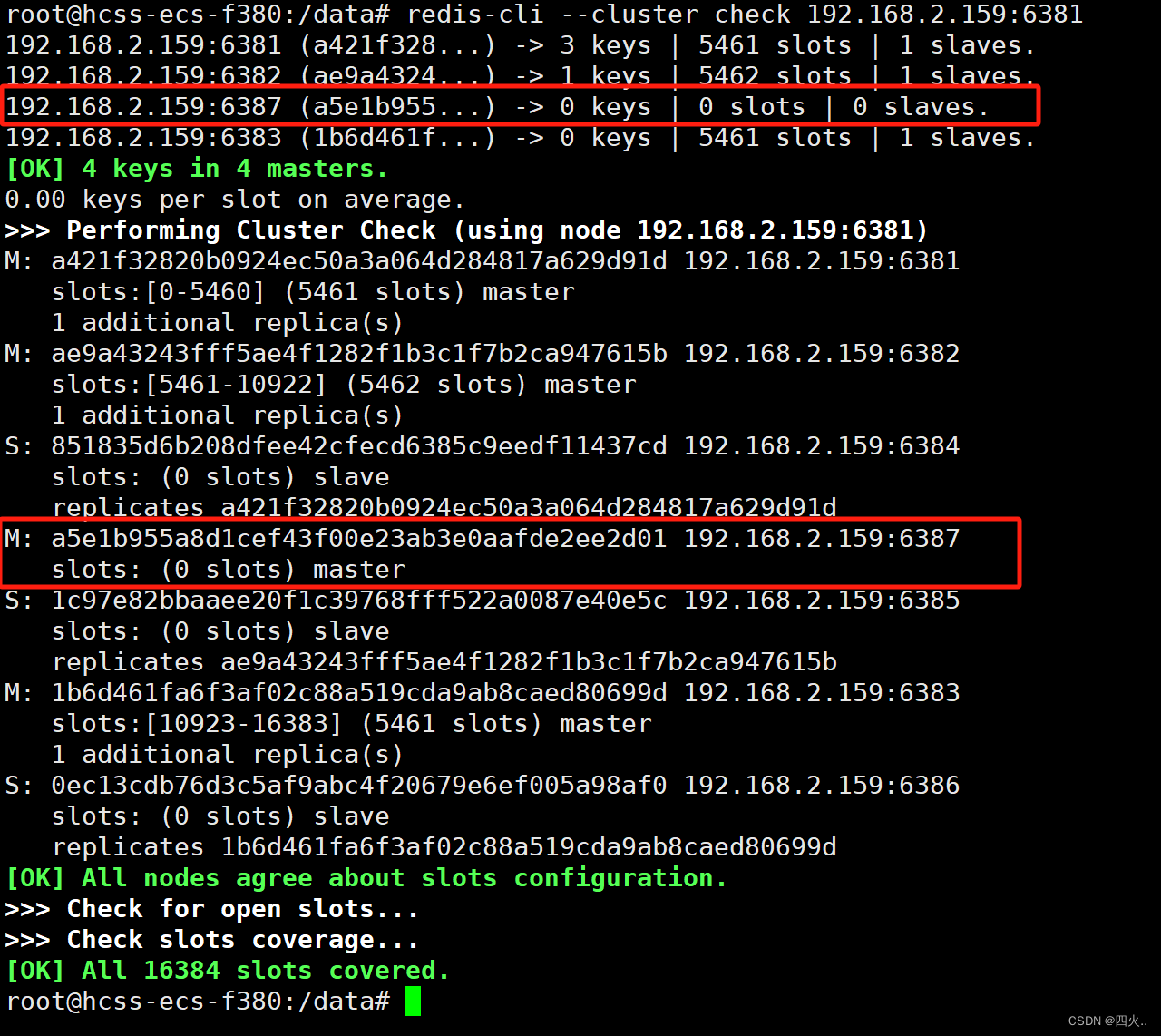
redis-cli --cluster check 192.168.2.159:6381
分配槽号
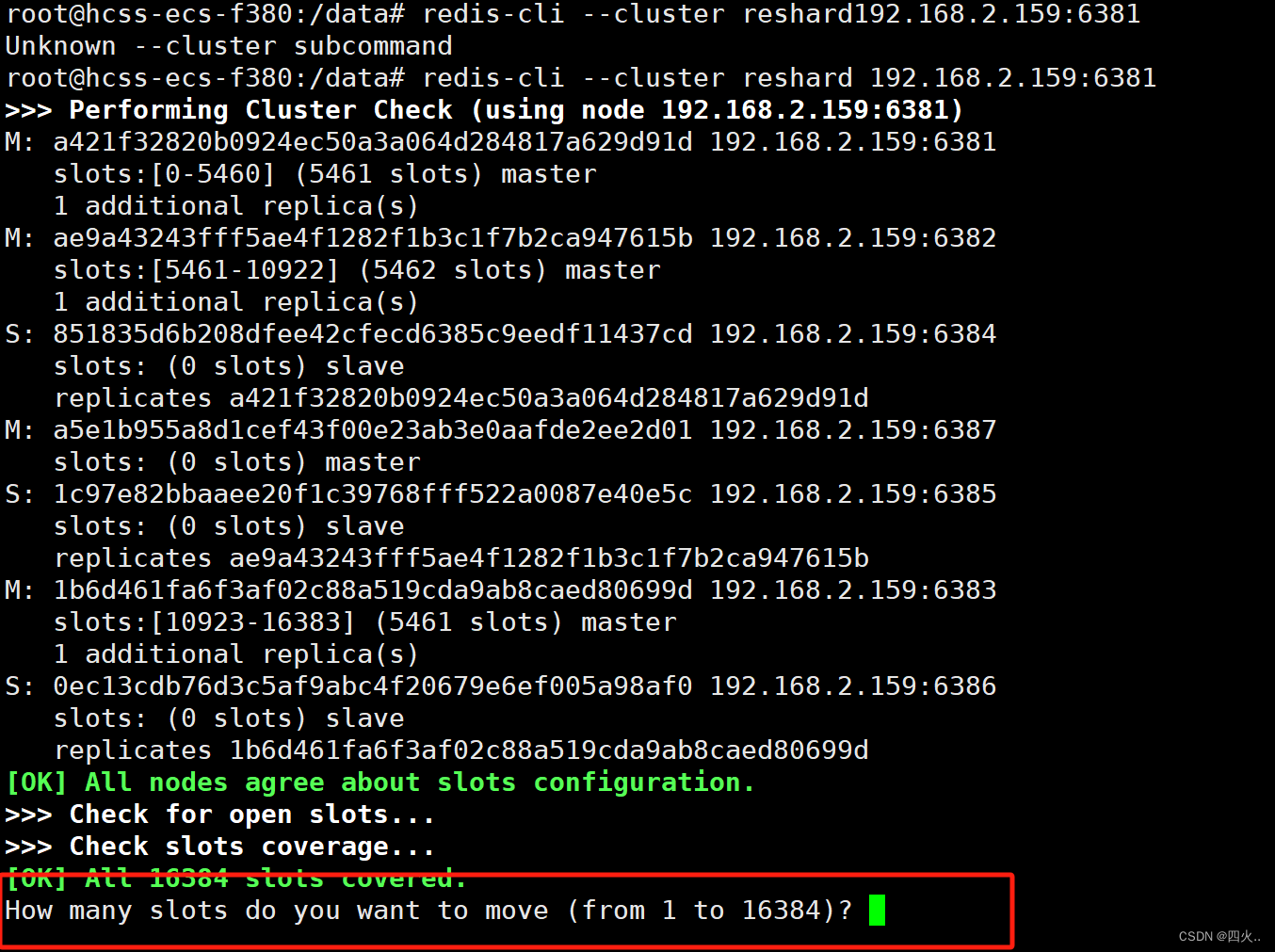
redis-cli --cluster reshard192.168.2.159:6381
分配每个槽位数量(根据16384/Master数量)
How many slots do you want to move (from 1 to 16384)?

槽位给予新增Master
M: a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01 192.168.2.159:6387
slots: (0 slots) master
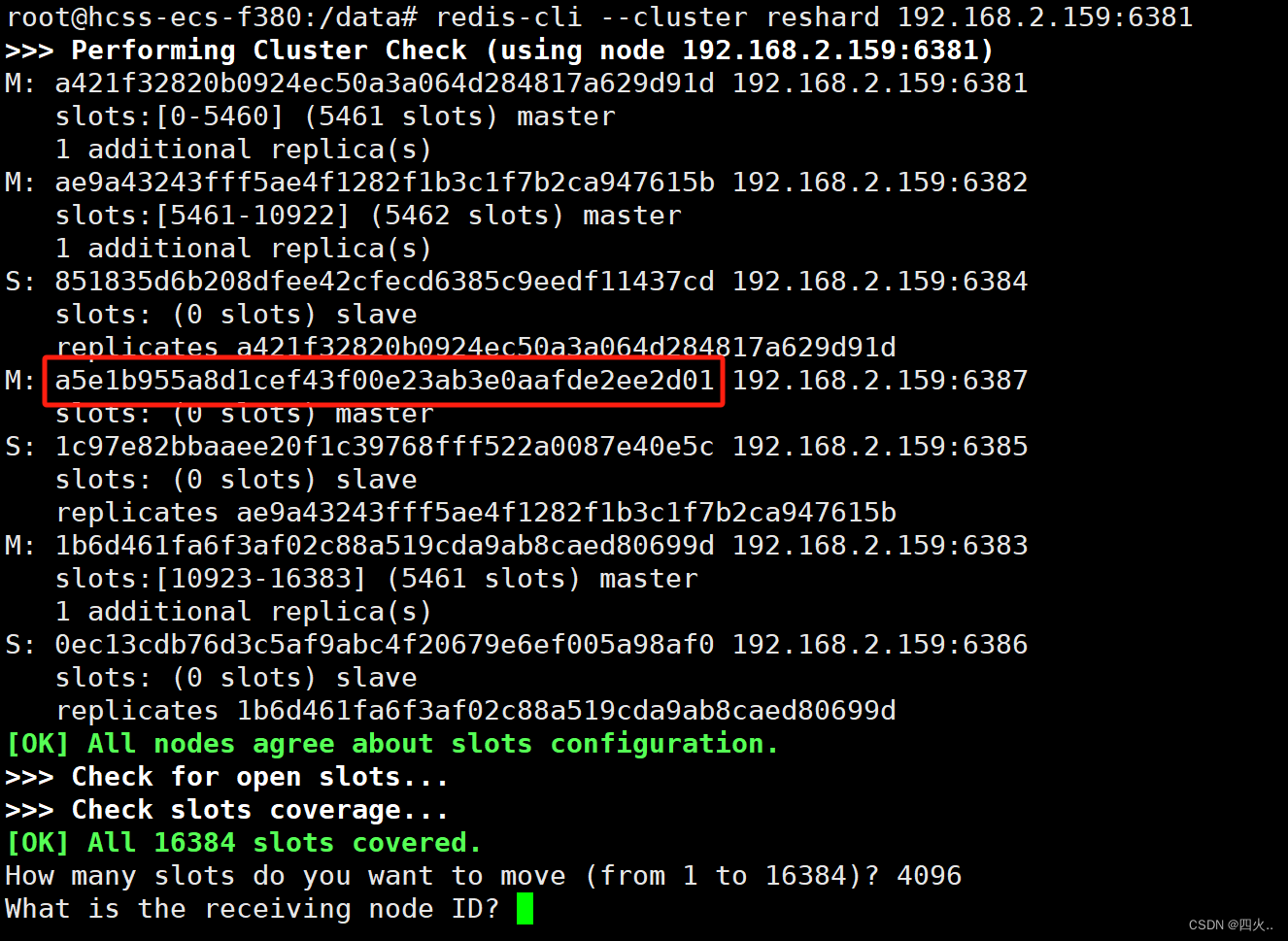
What is the receiving node ID? a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01
选择Master节点(由哪些节点分配出槽位给予新增master)
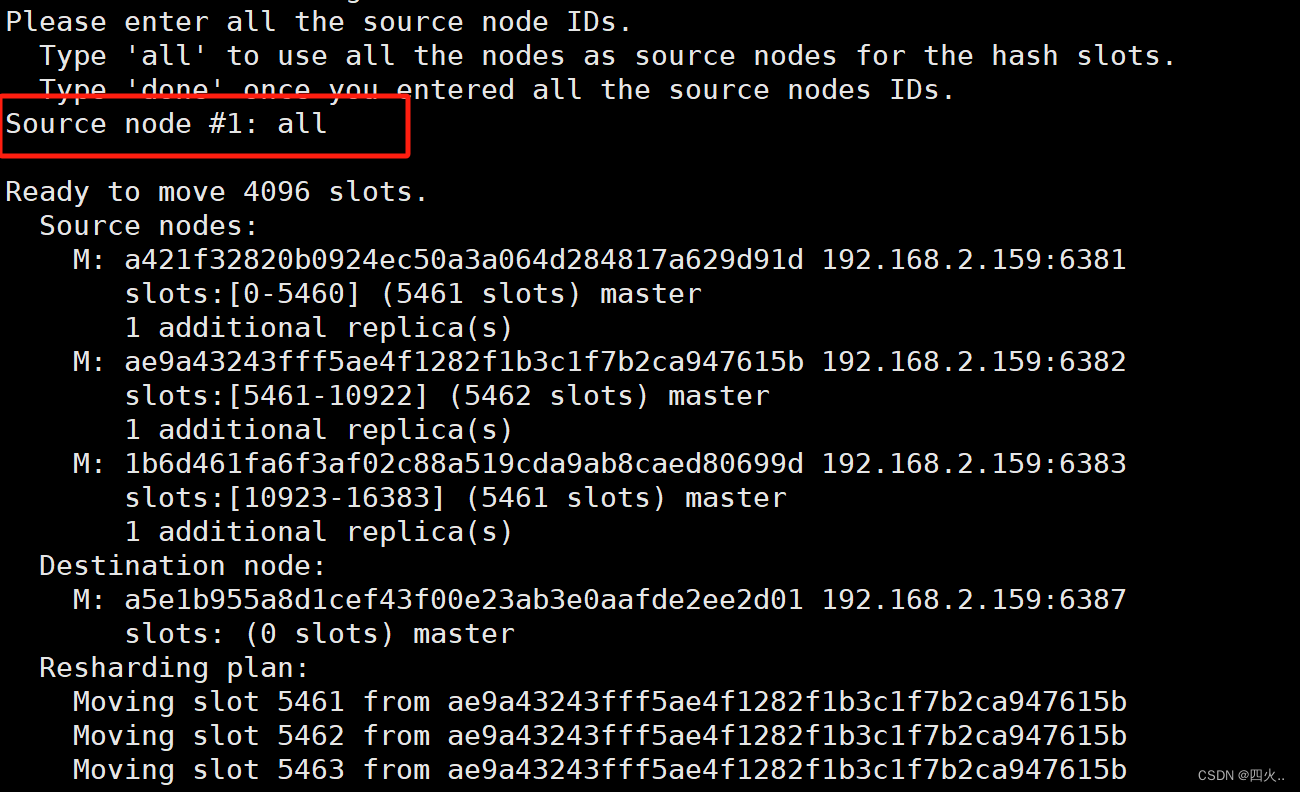
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
所有Master节点进行重新分配,输入all
指定节点进行分配,则输入ID,然后输入done
执行提议的重新分配插槽计划
Do you want to proceed with the proposed reshard plan (yes/no)?

查看集群情况
新增的槽位是原本3台Master分配给新增的Master,这是由于重新分配成本太高
redis-cli --cluster check 192.168.2.159:6387
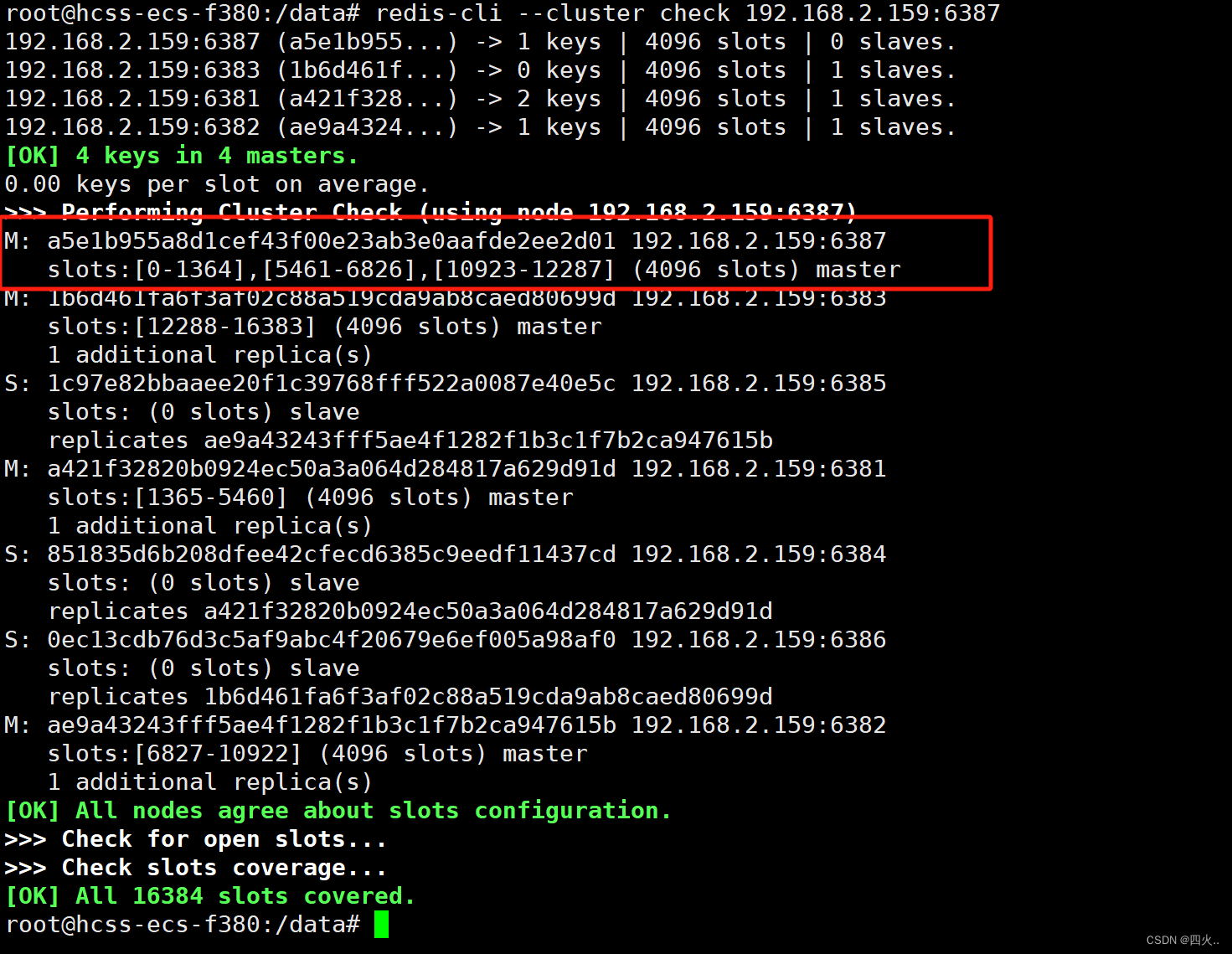
添加从节点
redis-cli --cluster add-node 192.168.2.159:6388 192.168.2.159:6387 --cluster-slave --cluster-master-id a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01
a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01根据实际情况替换新增的masterID
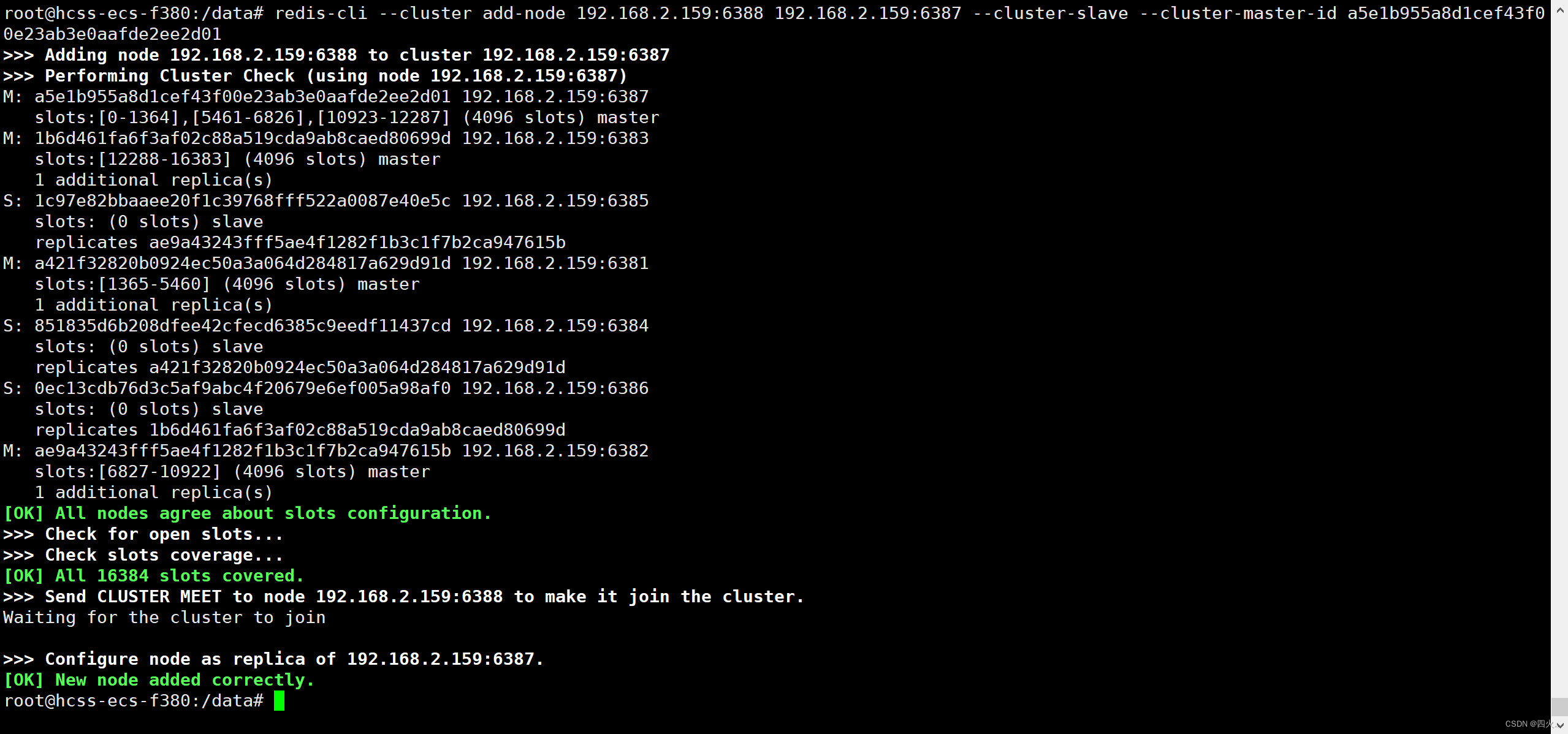
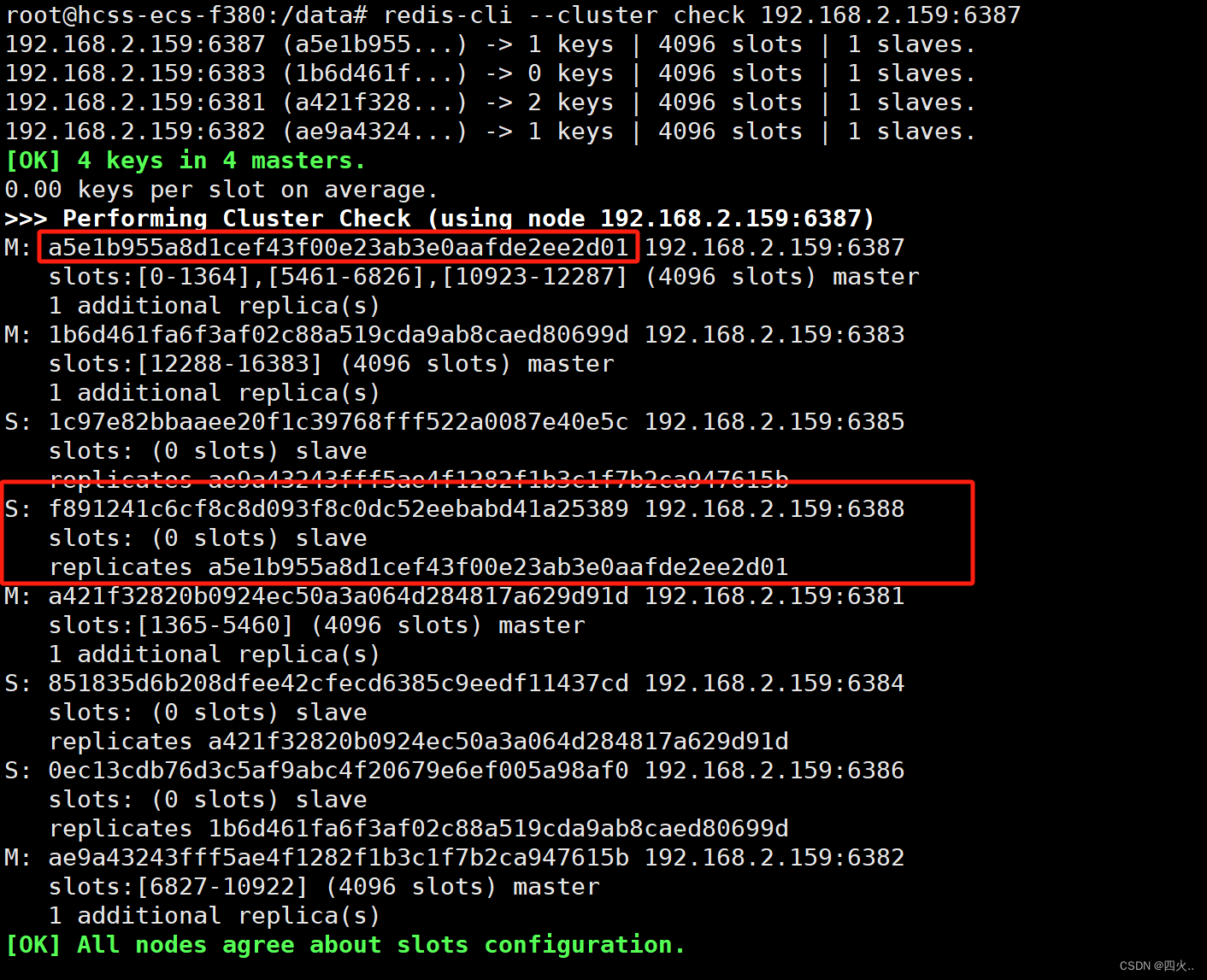
检查集群情况
redis-cli --cluster check 192.168.2.159:6387
五、主从缩容
查看集群环境获取节点ID
redis-cli --cluster check 192.168.2.159:6387
192.168.2.159:6387ID:a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01
192.168.2.159:6388ID:f891241c6cf8c8d093f8c0dc52eebabd41a25389
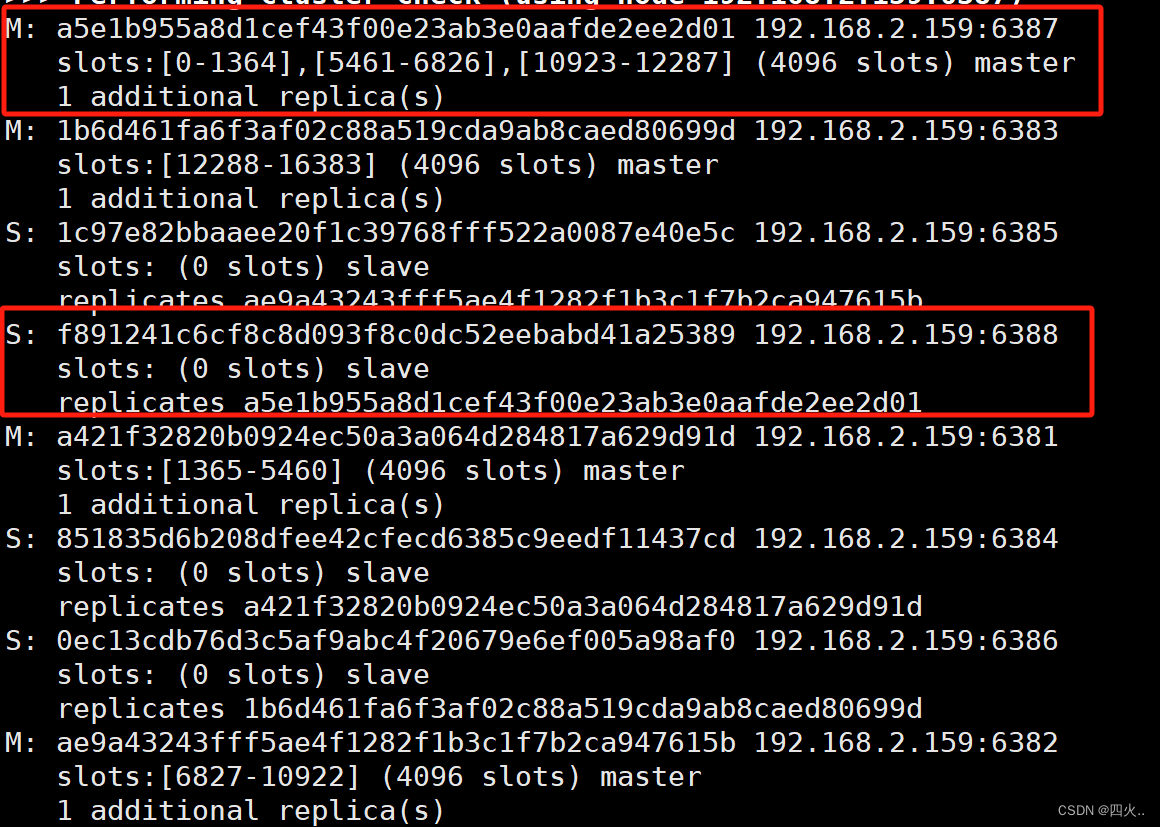
删除从节点
redis-cli --cluster del-node 从节点ID:从节点端口 从节点ID
redis-cli --cluster del-node 192.168.2.159:6388 f891241c6cf8c8d093f8c0dc52eebabd41a25389

检查集群情况
redis-cli --cluster check 192.168.2.159:6387
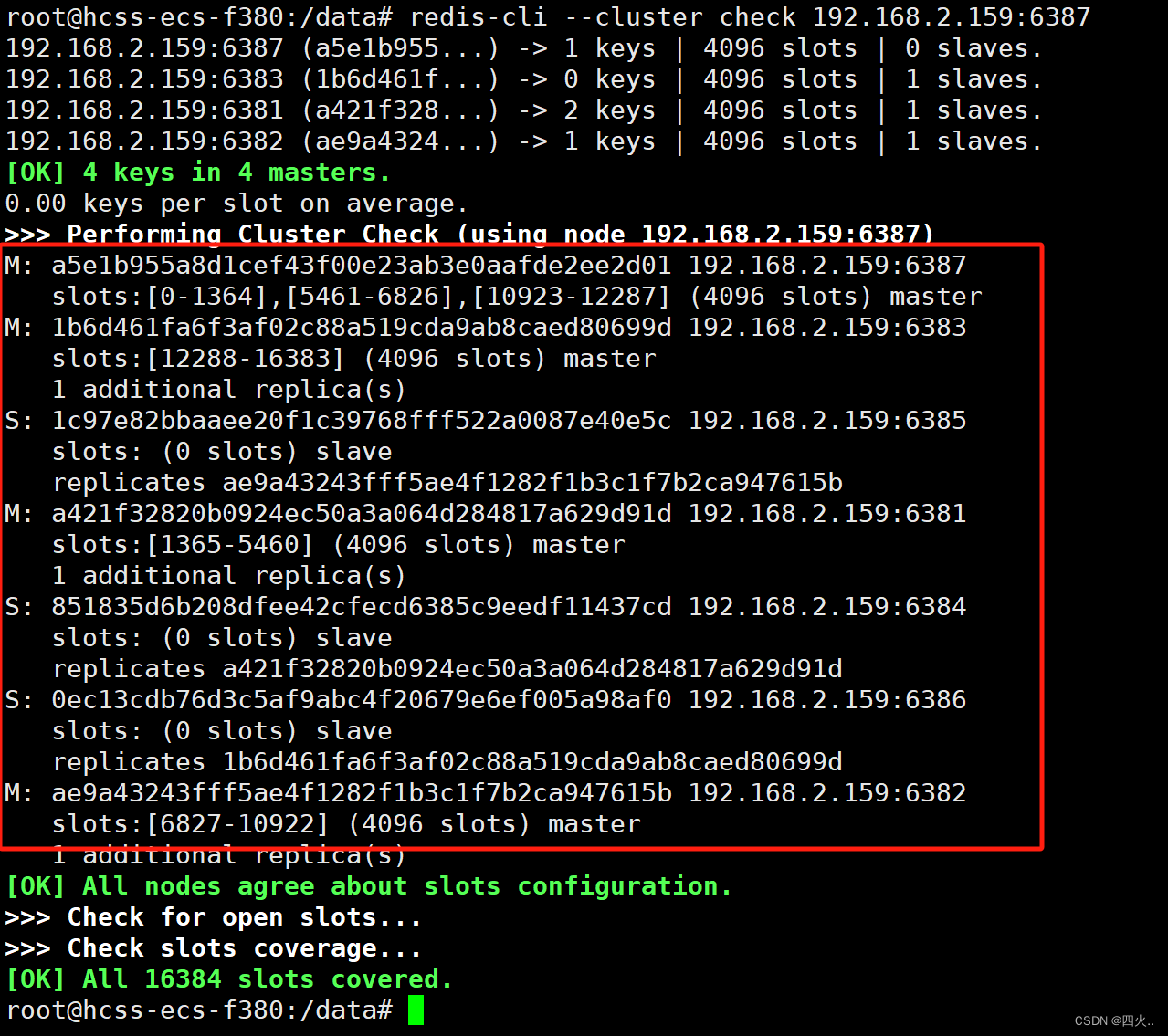
清空主机槽号
redis-cli --cluster reshard 192.168.2.159:6381
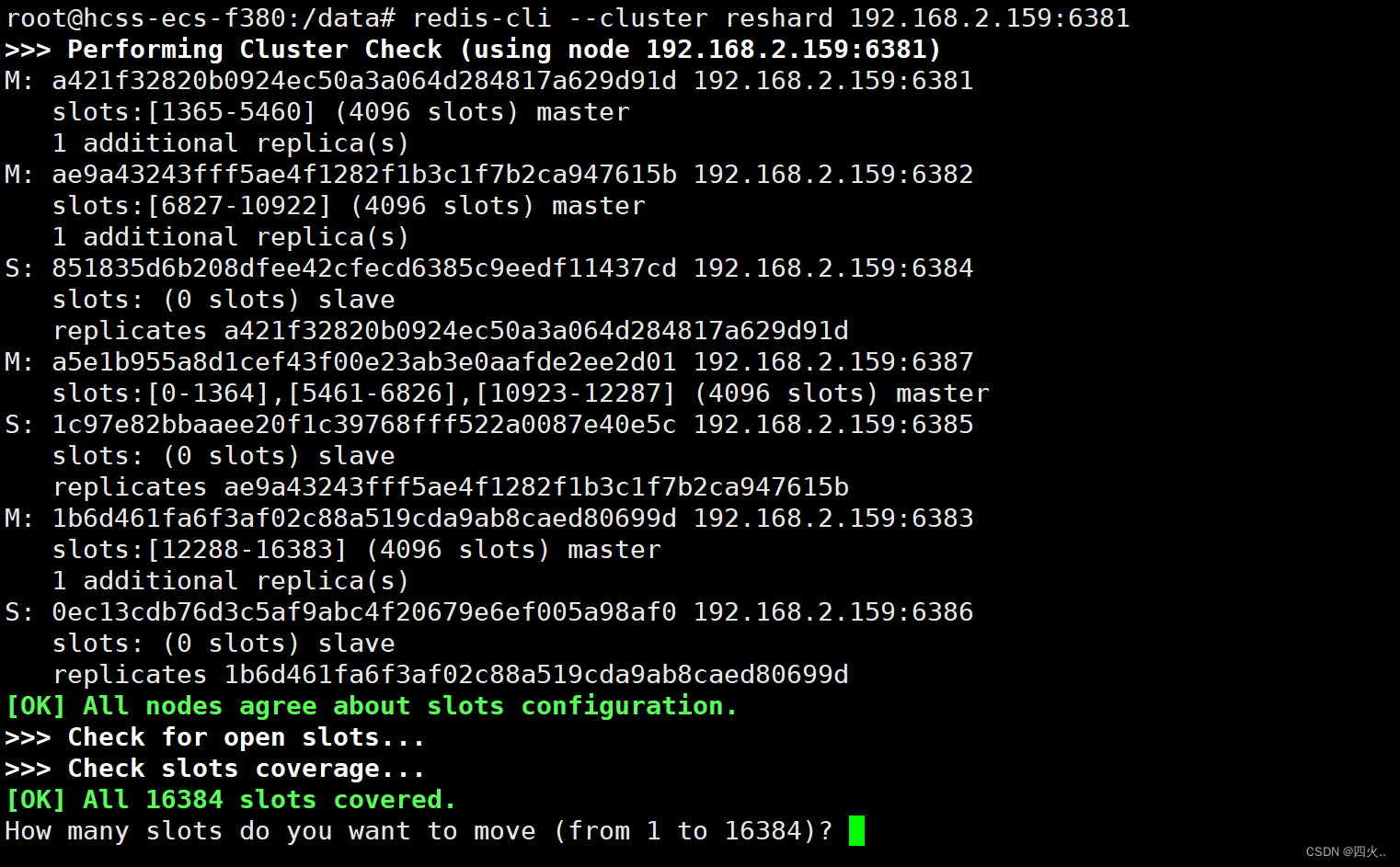
槽位分配
由于新增master6387删除,所有多出来4096个槽位,
也可以分多次分配平均分配到多台master,一次分配1000也可以

6381接收槽位
M: a421f32820b0924ec50a3a064d284817a629d91d 192.168.2.159:6381
slots:[1365-5460] (4096 slots) master
1 additional replica(s)

6387释放槽位
M: a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01 192.168.2.159:6387
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master

执行分配计划

查看集群情况
redis-cli --cluster check 192.168.2.159:6387
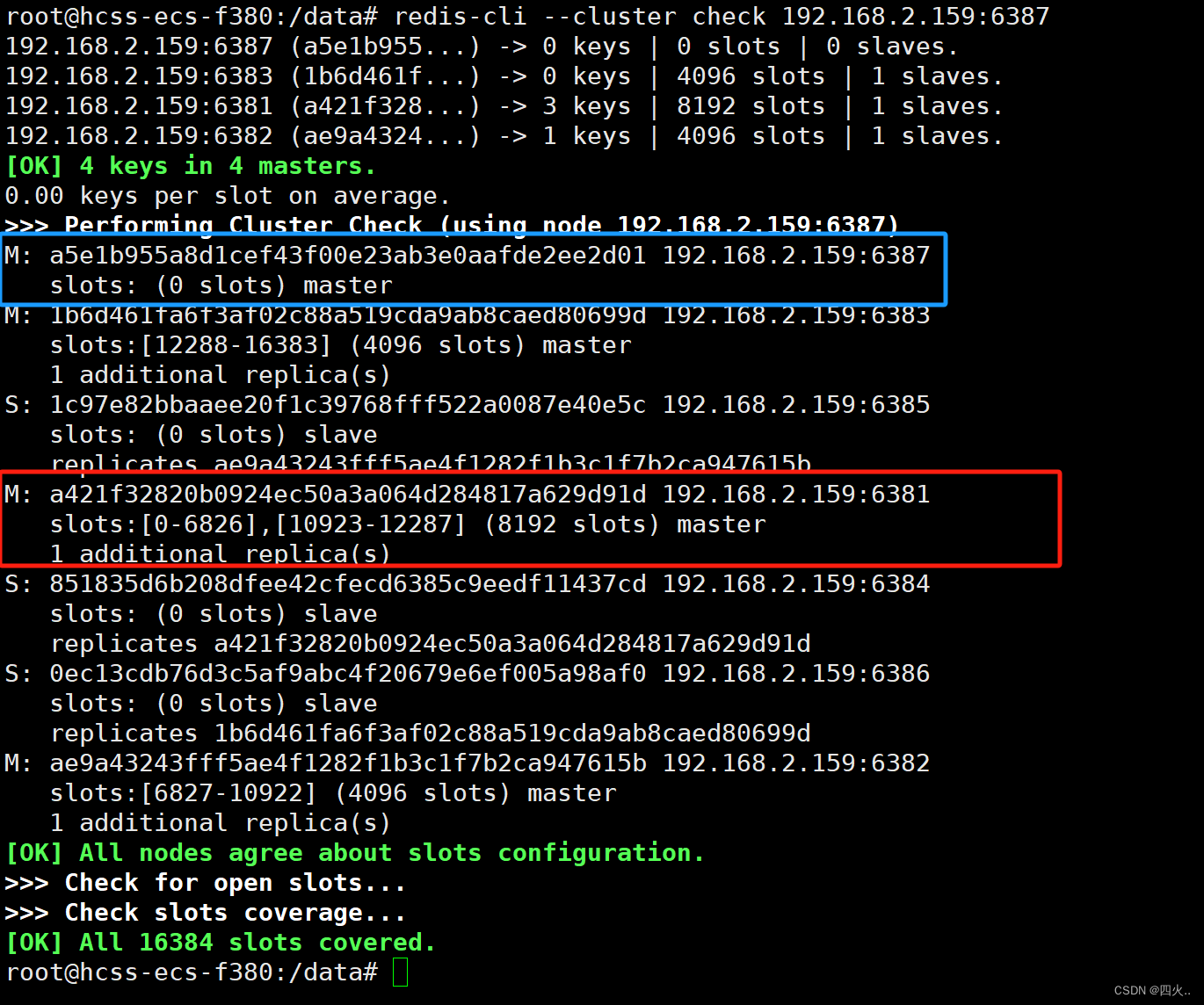
删除6387节点
M: a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01 192.168.2.159:6387
slots: (0 slots) master
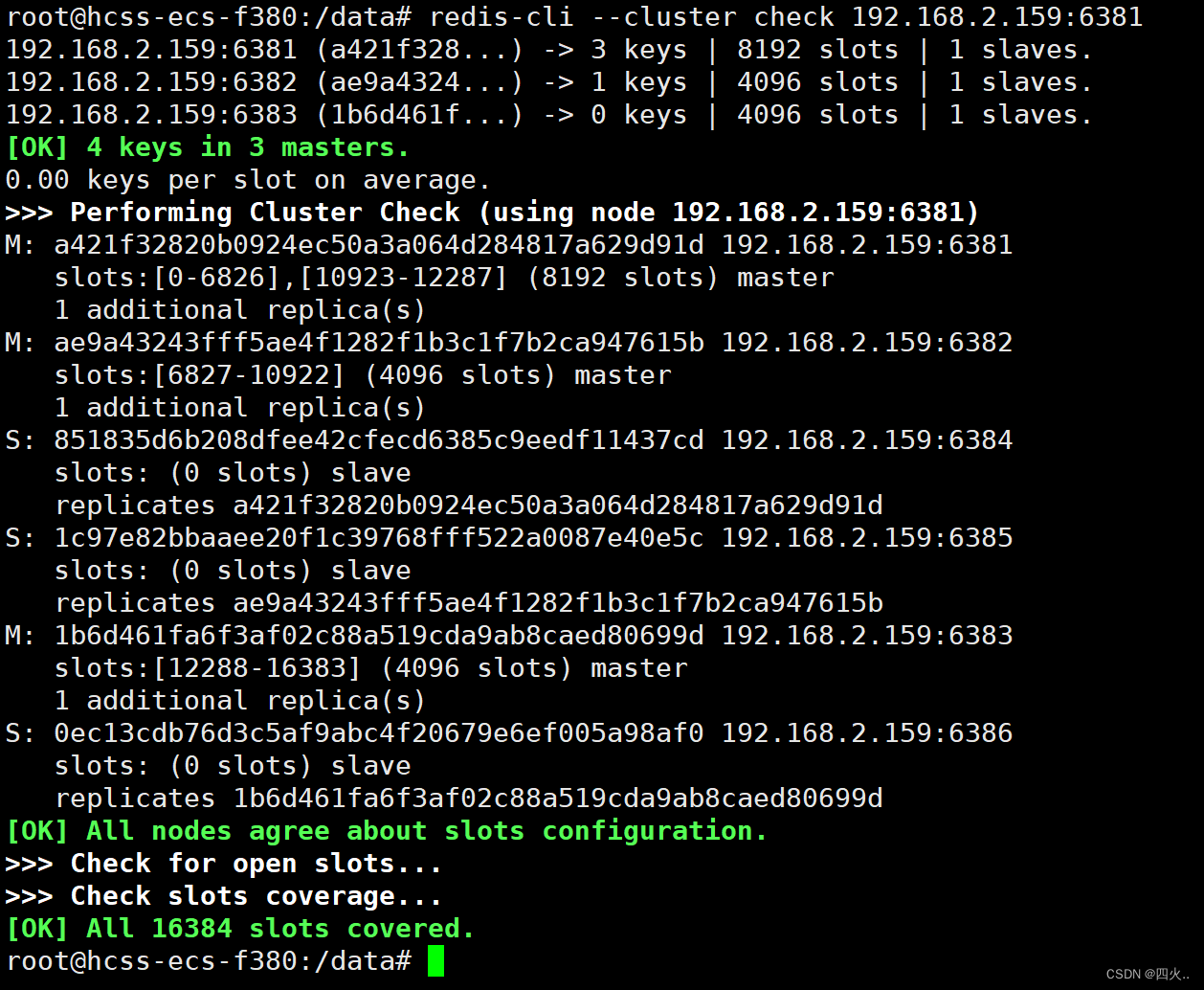
redis-cli --cluster del-node 192.168.2.159:6387 a5e1b955a8d1cef43f00e23ab3e0aafde2ee2d01

检查集群
redis-cli --cluster check 192.168.2.159:6381
















 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









