







一:数据收集
| 变量名 | 含义 |
|---|---|
| fixed acidity | 固定酸度 |
| volatile acidity | 挥发性酸度 |
| citric acidity | 柠檬酸 |
| residual sugar | 剩余糖 |
| chlorides | 氧化物 |
| free sulfur dioxide | 游离的二氧化碳 |
| total sulfur dioxide | 总二氧化硫 |
| density | 密度 |
| PH | 值 |
| sulphates | 酸碱盐 |
| alcohol | 酒精 |
| quality | 品质 |
完整数据
实训之前我们需要先下载数据,我这里是下载完之后文件名是:white_wine.csv
二:读取数据
1:显示前5行数据
import csv
f = open("white_wine.csv",'r')
reader = csv.reader(f)
data = []
for row in reader:
data.append(row)
for i in range(5):
print(data[i])
f.close()

三:数据处理
1:查看白葡萄酒总共分为几种品质等级
import csv
f = open("white_wine.csv",'r')
reader = csv.reader(f)
data = []
for row in reader:
data.append(row)
quality_list = []
for row in data[1:]:
quality_list.append(int(row[ -1]))
quality_count = set(quality_list)
print("白葡萄酒共有%s种等级, 分别为:%r"
%(len(quality_count), quality_count))
白葡萄酒共有7种等级, 分别为:{3, 4, 5, 6, 7, 8, 9}
2:统计等级及其数量
import csv
f = open("white_wine.csv",'r')
reader = csv.reader(f)
data = []
for row in reader:
data.append(row)
content_dict = {}
for row in data[1:]:
quality = int(row[-1])
if quality not in content_dict.keys():
content_dict[quality] = [row]
else:
content_dict[quality].append(row)
for key in content_dict:
print('等级为%d, 数量为%d' %(key, len(content_dict[key])))
f.close()
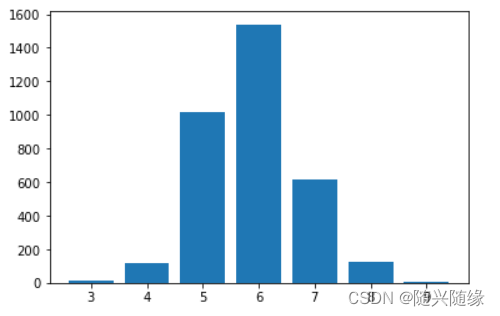
等级为6, 数量为1539
等级为5, 数量为1020
等级为7, 数量为616
等级为8, 数量为123
等级为4, 数量为115
等级为3, 数量为14
等级为9, 数量为4
条形图展示
import csv
import numpy as np
import matplotlib.pyplot as plt
f = open("white_wine.csv",'r')
reader = csv.reader(f)
data = []
for row in reader:
data.append(row)
content_dict = {}
for row in data[1:]:
quality = int(row[-1])
if quality not in content_dict.keys():
content_dict[quality] = [row]
else:
content_dict[quality].append(row)
x = []
y = []
for key in content_dict:
x.append(key)
y.append(len(content_dict[key]))
plt.bar(x, y)
plt.show()
3:计算每个数据集中fixed acidity的均值
import csv
f = open("white_wine.csv",'r')
reader = csv.reader(f)
data = []
for row in reader:
data.append(row)
content_dict = {}
for row in data[1:]:
quality = int(row[-1])
if quality not in content_dict.keys():
content_dict[quality] = [row]
else:
content_dict[quality].append(row)
mean_list = []
for key,value in content_dict.items():
sum = 0
for row in value:
sum += float(row[0])
mean_list.append((key, sum / len(value)))
for item in mean_list:
print(item[0],",", item[1])
6 : 6.812085769980511
5 : 6.907843137254891
7 : 6.755844155844158
8 : 6.708130081300811
4 : 7.052173913043476
3 : 7.535714285714286
9 : 7.5



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









