







大数据集群踩过的坑
前言(必看)
如果你遇到了和我一样的问题并通过搜索引擎进入这篇文章,请善用Ctrl+F键搜索
该自检手册仅用于自己学习使用,记录所有自己遇到的问题。如果你没有检索到你的问题,请使用Bing或Google进行搜索
该自检手册严格按照以下模板标准编写:
## 主要出错集中点标题
### 该错误的具体分支错误
报错信息
code
==原因:(若分点则另起一行)==

> 提示信息:(若有则写,没有就不写)
==解决方法:(若分点则另起一行)==

> 提示信息:(若有则写,没有就不写)
关键词:xxx、xxx
参考资料:(若分点则另起一行)
补充:
1. 若需要编写注意事项,统一使用<font size=5 color=red>标签编写
目录
1. HDFS
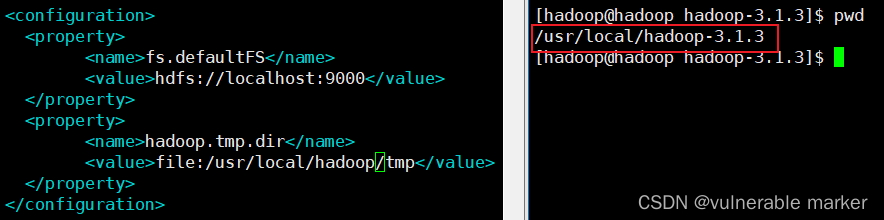
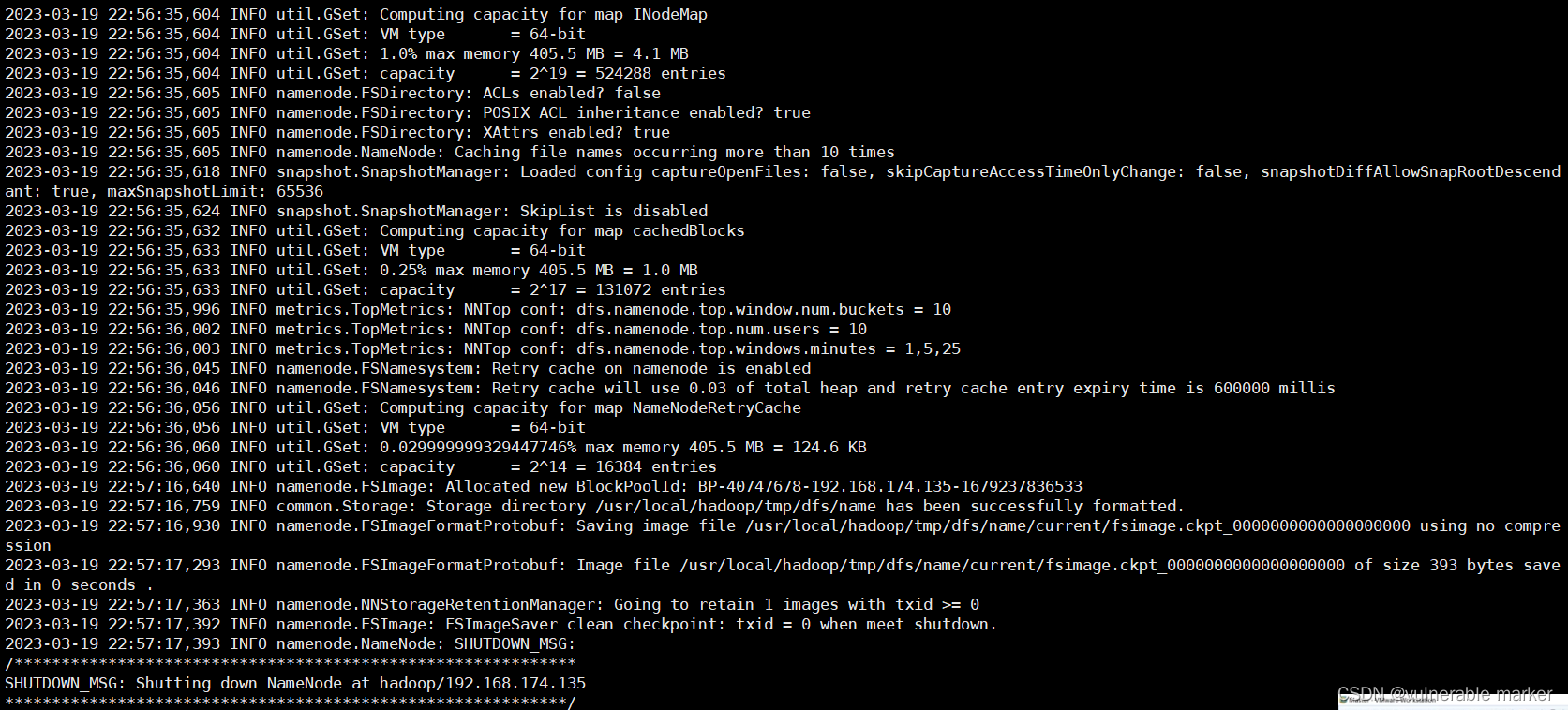
1.1 hdfs namenode -format 格式化错误
报错信息
java.io.IOException: Cannot create directory /usr/local/hadoop/tmp/dfs/name/current
原因:
- 在
core-site.xml文件中hadoop.tmp.dir的 value 标签参数值设置错误 - 在
hdfs-site.xml文件中dfs.namenode.name.dir或dfs.datanode.data.dir的 value 标签参数值设置错误 - 当前登录的用户不具有
hadoop文件夹的访问与写入权限
解决方法(对应上面的1、2、3点):
-
修改
core-site.xml存放临时文件夹的路径,这里我的目录名是hadoop-3.1.3 -
修改
hdfs-site.xml存放 name 和 data 文件夹的路径,这里我的目录名是hadoop-3.1.3 -
使用
sudo chown -R 用户名:用户名 存放hadoop的文件路径命令对文件夹提权例如:sudo chown -R hadoop:hadoop /usr/local/hadoop
注意:格式化的操作在你成功格式化之后就不要再执行了!不要好奇,除非你想再体验一次集群的搭建。再次执行格式化,成功
提示:其实最正确的做法是文件名需要改成
hadoop而不是hadoop-3.1.3,这样便于管理与执行
关键词:java.io.IOException: Cannot create directory、hdfs namenode -format、格式化错误、CentOS7、Linux
参考资料:
- Hadoop格式化namenode错误:java.io.IOException: Cannot create directory_cannot create directory /opt/cloudera/parcels/sche
- directory - hadoop java.io.IOException: while running namenode -format - Stack Overflow
2. HBase
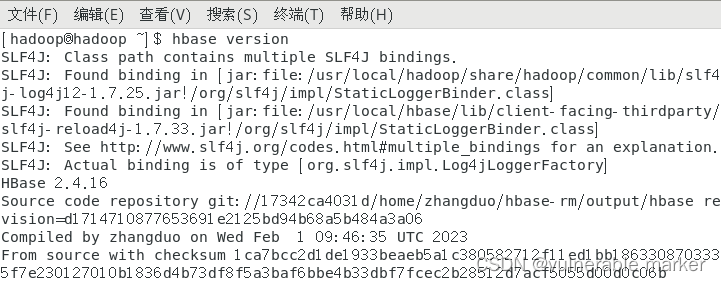
2.1 使用 HBase 命令显示 jar 包冲突
报错信息
SLF4J: Found binding in
[jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar!/org/slf4j/impl/StaticLoggerBinder.class]
原因:
- 由于在 HBase 中使用了两个不同版本的 SLF4J 日志框架的 StaticLoggerBinder 类,分别来自 Hadoop 的 slf4j-log4j12-1.7.25.jar 和 HBase 的 slf4j-reload4j-1.7.33.jar。这导致了类版本冲突,因为相同类的不同版本无法同时存在,从而导致了类加载失败和错误提示的出现
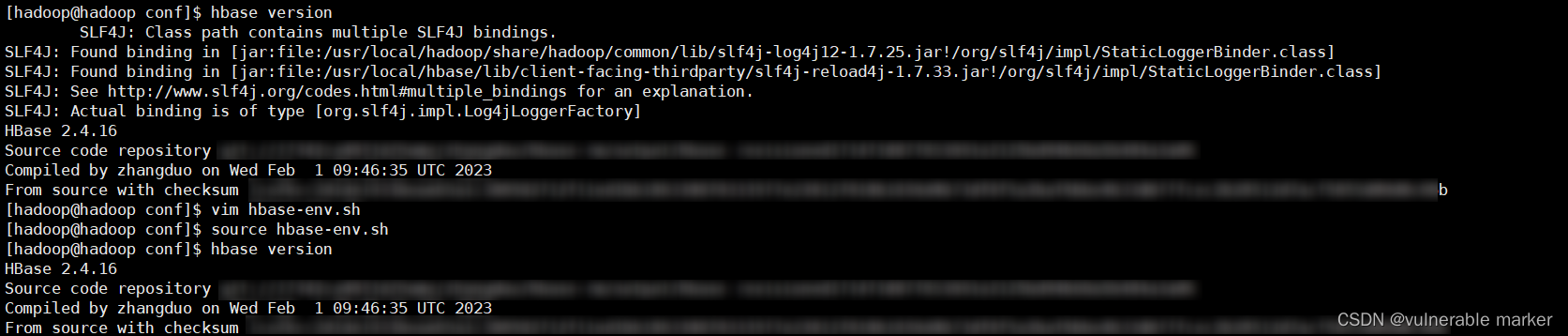
解决方法:
-
✅推荐 在
hbase-env.sh中添加export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" 添加完成后退出编辑界面,在bash命令窗口输入 source hbase-env.sh原理是告诉 HBase 不要使用 Hadoop 的 classpath 来加载依赖项。这可以确保 HBase 使用自己的 classpath,避免与 Hadoop 中的库发生冲突
-
⚠️不推荐 删除
hadoop或hbase其中一个 jar 包,原则上删除版本较低的那一个注意:执行删除操作之前建议先备份,备份后再执行。rm命令需要精准指向该jar包
例如:sudo rm /usr/local/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar再次查看是否会出现 jar 包的冲突信息,冲突信息消失,成功解决
关键词:Hbase启动、jar包冲突、SLF4J、HBase、CentOS7、Linux
参考资料:
- [HBASE-11408] “multiple SLF4J bindings” warning messages when running HBase shell - ASF JIRA (apache.org)
- HBase(Hadoop3.1.2 HBase2.2.4) 伪分布式安装与配置
- jar包冲突:Found binding in jar:file:/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar
2.2 使用 Hbase shell 时出现 ConnectionLoss for /hbase/master
报错信息
hbase:001:0> create 'student','Sname','Ssex','Sage','Sdept','course'
ERROR: KeeperErrorCode = ConnectionLoss for /hbase/master
For usage try 'help' 'create'
Took 33.9493 seconds
原因:
-
✅我遇到的 我没有安装 Zookeeper,但是在
hbase-site.xml中错误的配置了有关Zookpeer的标签,导致Hbase shell无法找到Zookeeper文件夹,从而无法操作有关Hbase shell的任何命令<configuration> ... <property> <name>hbase.zookeeper.quorum</name> <value>zk1.example.com,zk2.example.com,zk3.example.com</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> ... </configuration>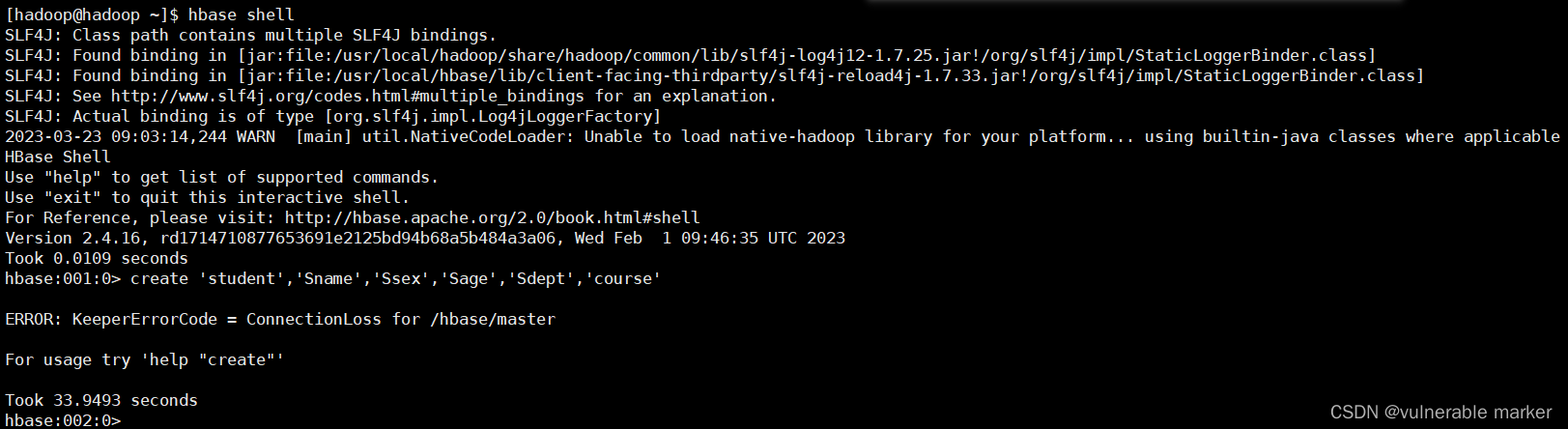
-
HBase Master 和 ZooKeeper 在不同的节点上运行,防火墙或网络安全组阻止了它们之间的通信
-
没有启动
HBase的相关服务
解决方法(对应上面的1、2、3点):
- 删除
hbase-site.xml对应文件里有关于 Zookpeer的标签 - 需要关闭防火墙
先使用systemctl status firewalld查看防火墙的状态,如果是开着的请使用systemctl stop firewalld

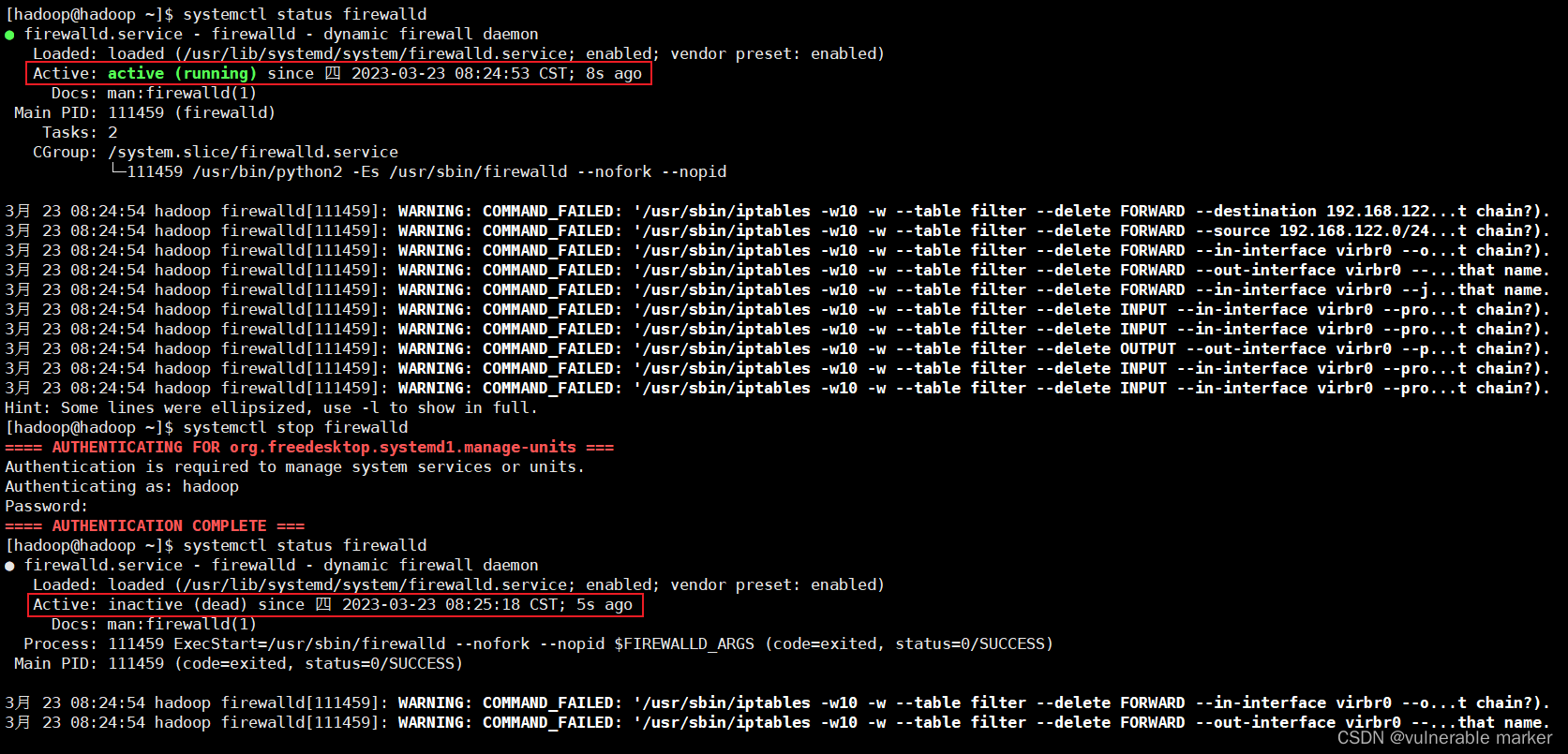
关闭防火墙后,使用命令service firewalld status检查防火墙服务是否开启,如果是开启的使用命令service firewalld stop停止防火请的服务进程
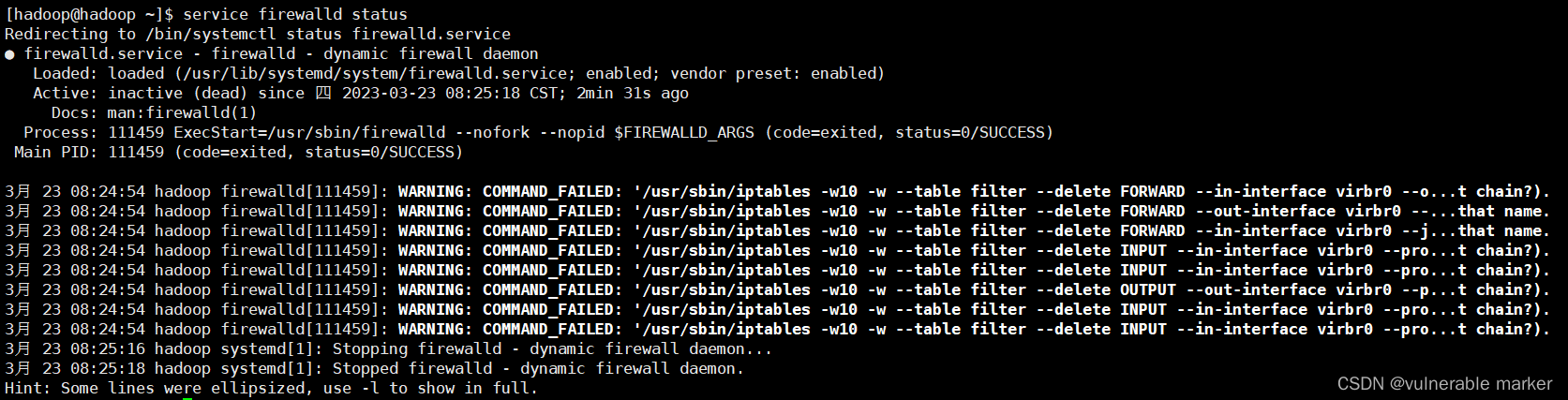
- 使用命令
start-hbase.sh开启hbase的相关服务
参考资料:
- HBase:Error:KeeperErrorCode=ConnectionLoss for /hbase/master For usage try ‘help‘ ‘disable‘_error: keepererrorcode = connectionloss for /hbase
- KeeperErrorCode = ConnectionLoss for /hbase/master - Cloudera Community - 134130
3. 网络问题
3.1 service network restart 启动失败
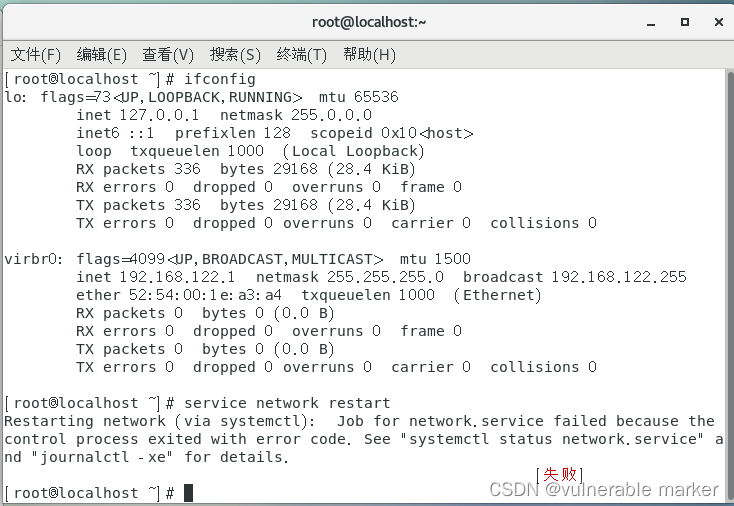
报错信息:
Restarting network (via systemctl): Job for network.service failed because the control process exited with error code. See "systemctl status network.service" and "journalctl -xe" for details
原因:
- 一个可能的原因是与 NetworkManager 服务冲突,NetworkManager 是一个用于管理网络连接的程序,它可以帮助您自动配置网络接口并管理网络连接。但是,在某些情况下,NetworkManager 可能会与网络服务冲突,导致网络服务无法正常启动
- 另一个原因可能是由于路由表中存在冲突条目造成的
解决方法:
-
在终端中输入
journalctl -xe或systemctl status network.service命令查看错误日志[root@localhost network-scripts]# systemctl status network.service ● network.service - LSB: Bring up/down networking Loaded: loaded (/etc/rc.d/init.d/network; bad; vendor preset: disabled) Active: failed (Result: exit-code) since 四 2023-05-04 10:55:49 CST; 22s ago Docs: man:systemd-sysv-generator(8) Process: 4536 ExecStart=/etc/rc.d/init.d/network start (code=exited, status=1/FAILURE) 5月 04 10:55:49 localhost.localdomain network[4536]: RTNETLINK answers: File... 5月 04 10:55:49 localhost.localdomain network[4536]: RTNETLINK answers: File... 5月 04 10:55:49 localhost.localdomain network[4536]: RTNETLINK answers: File... 5月 04 10:55:49 localhost.localdomain network[4536]: RTNETLINK answers: File... 5月 04 10:55:49 localhost.localdomain network[4536]: RTNETLINK answers: File... 5月 04 10:55:49 localhost.localdomain network[4536]: RTNETLINK answers: File... 5月 04 10:55:49 localhost.localdomain systemd[1]: network.service: control p... 5月 04 10:55:49 localhost.localdomain systemd[1]: Failed to start LSB: Bring... 5月 04 10:55:49 localhost.localdomain systemd[1]: Unit network.service enter... 5月 04 10:55:49 localhost.localdomain systemd[1]: network.service failed. Hint: Some lines were ellipsized, use -l to show in full.“RTNETLINK answers: File exists”。这表明在尝试激活网络接口时出现了问题
可以尝试使用以下命令停止 NetworkManager 服务并禁止其在启动时启动:
service NetworkManager stop chkconfig NetworkManager off service network restart //重启网络服务
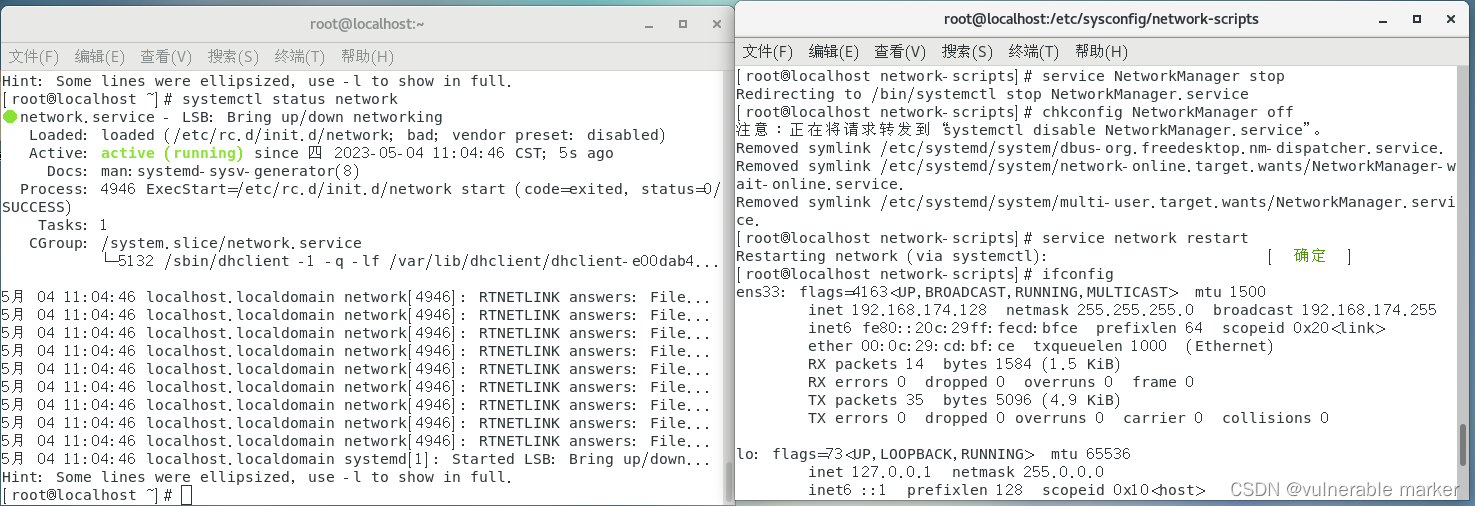
- 可以尝试使用
ip route命令查看路由表,并使用ip route del命令删除冲突的条目
关键词:ens33、网络错误、NetworkManager冲突,网络服务启动失败、ifconfig、CentOS 7
参看资料:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









